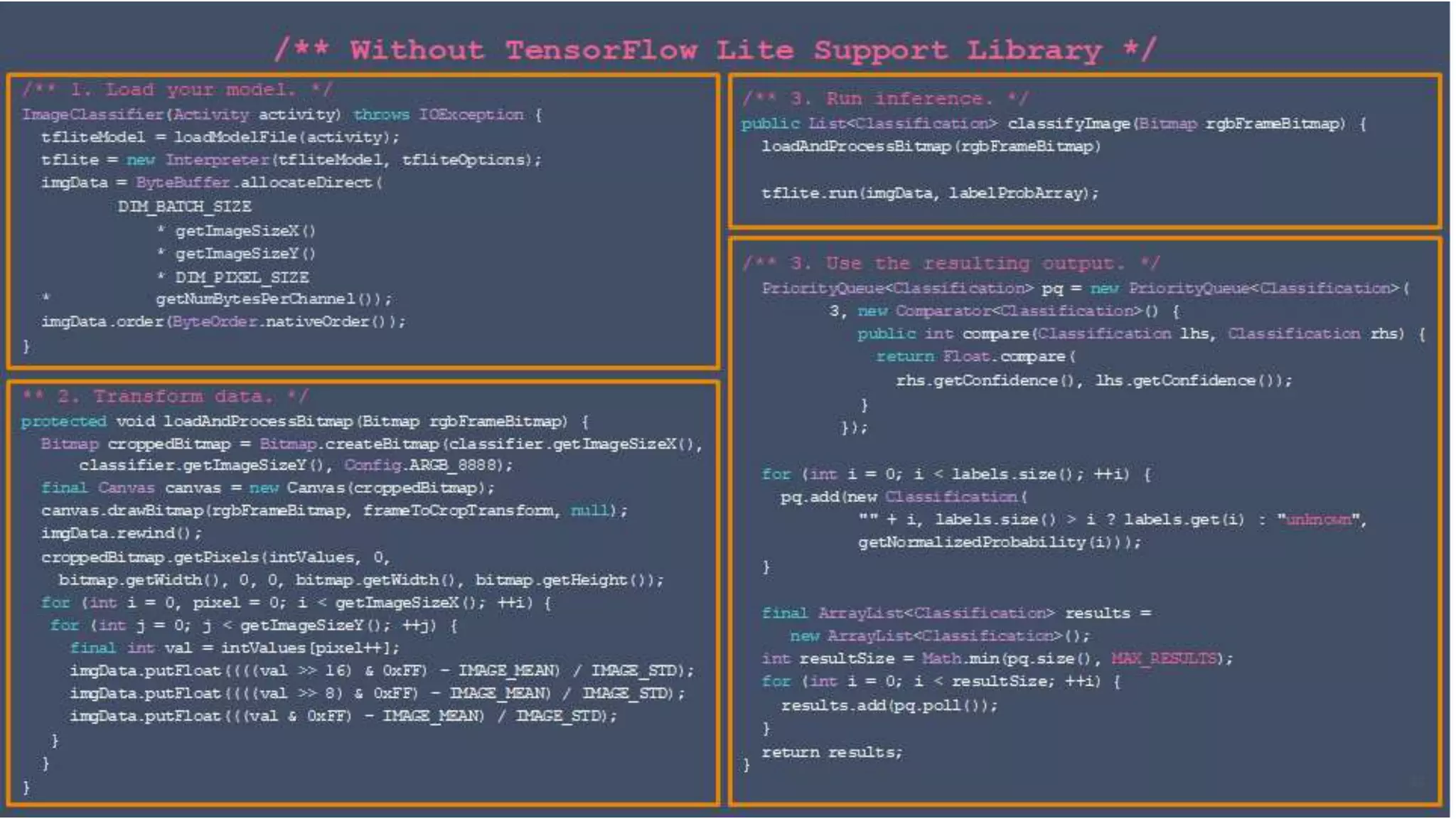
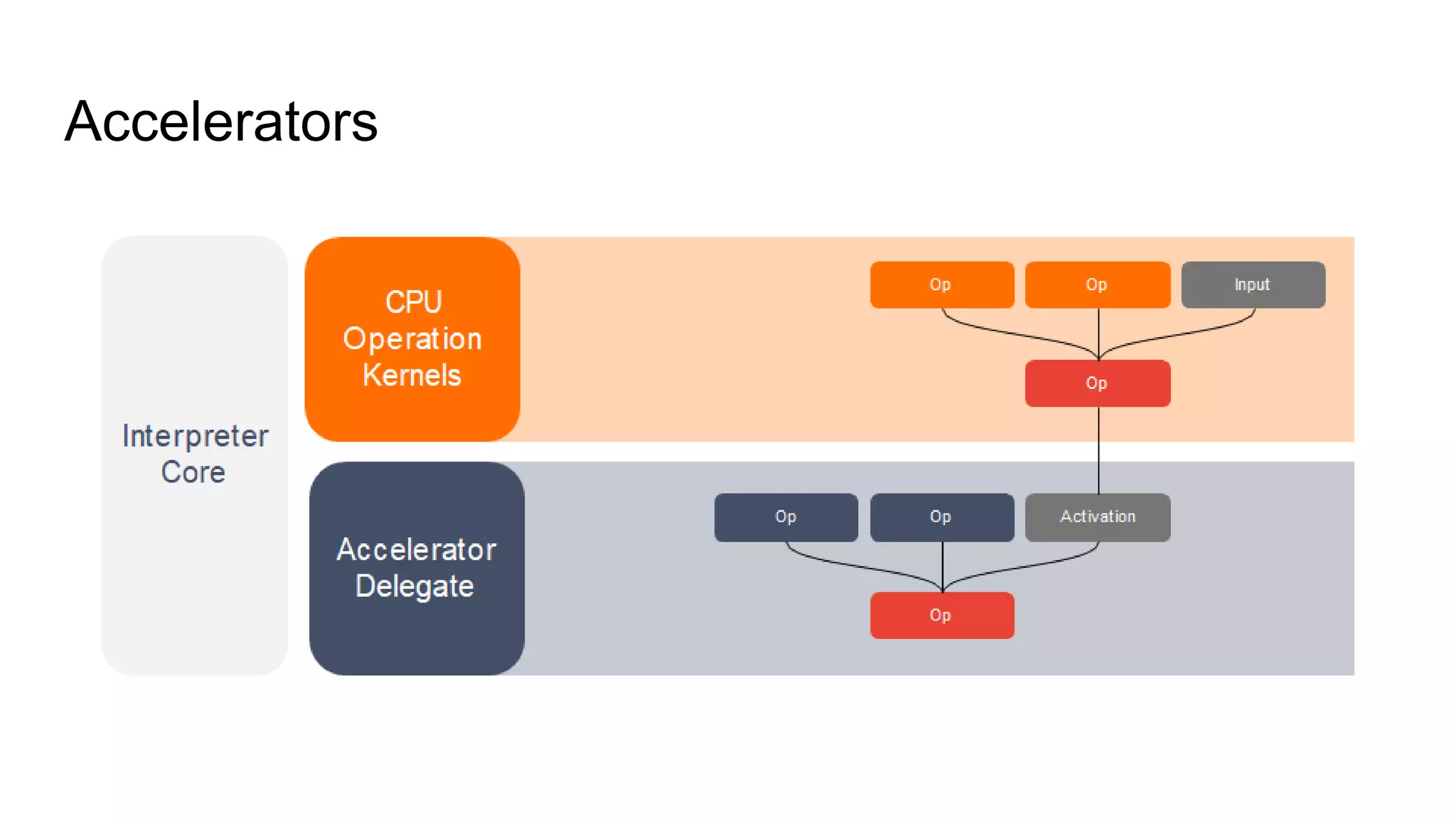
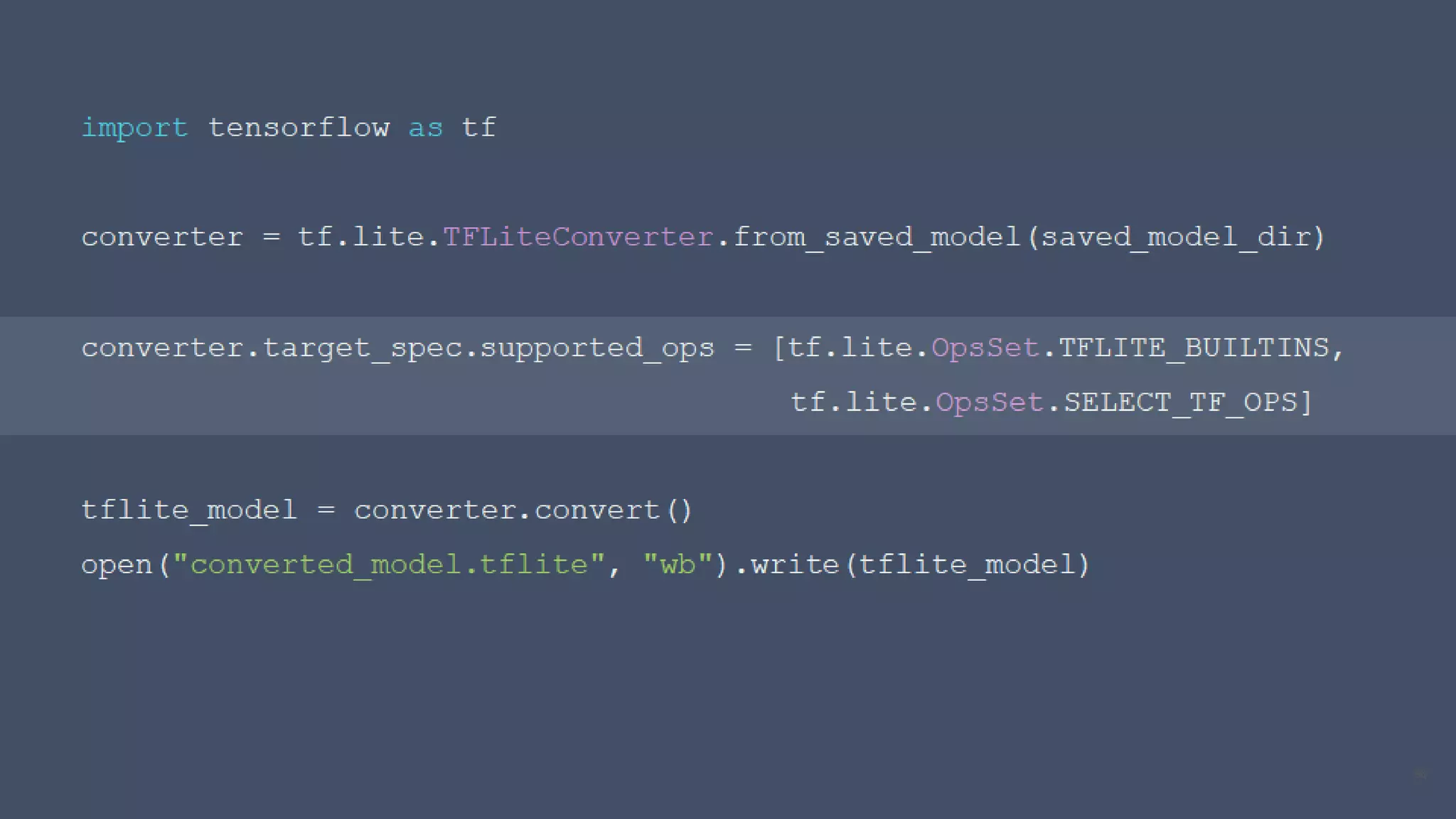
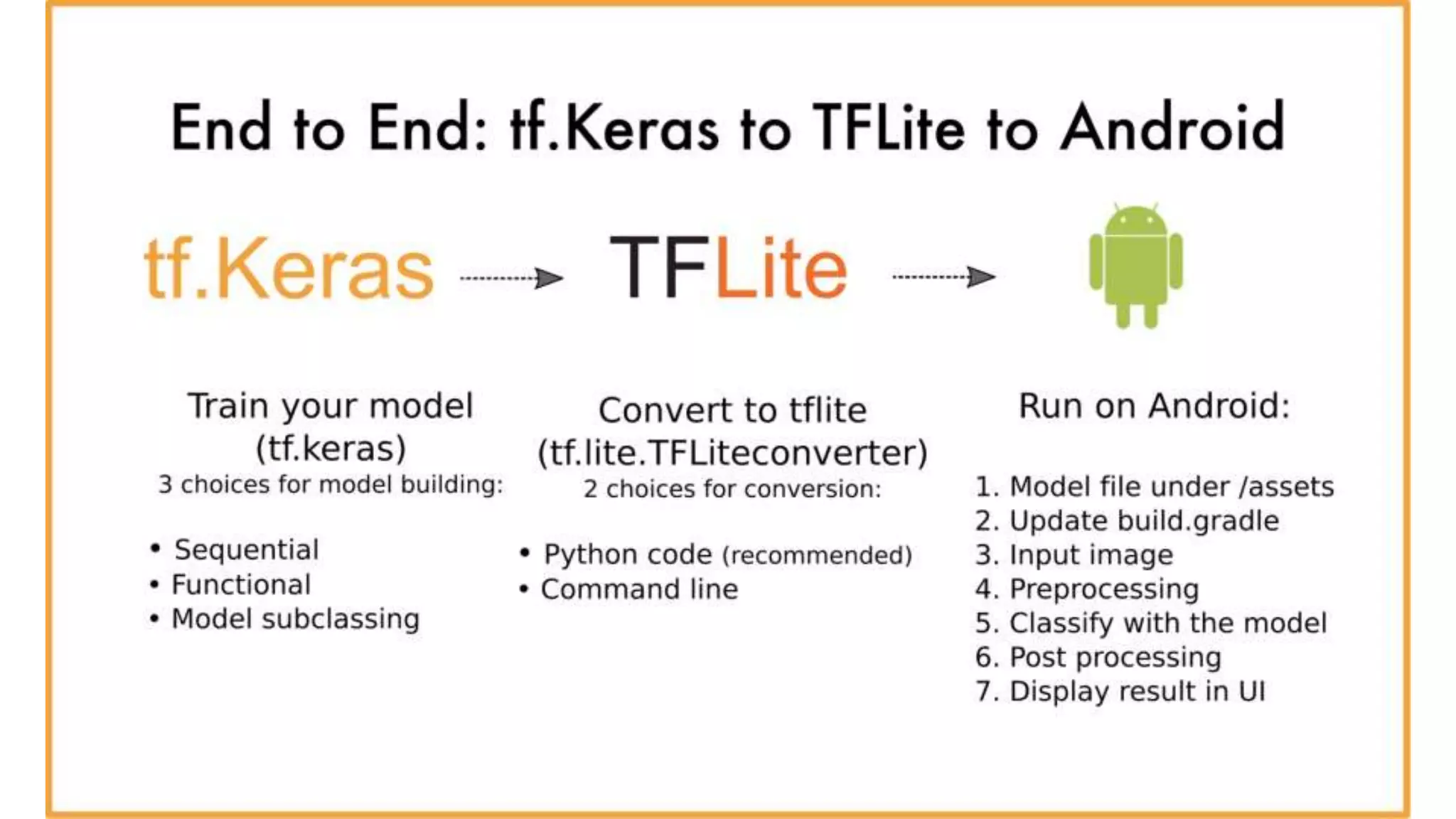
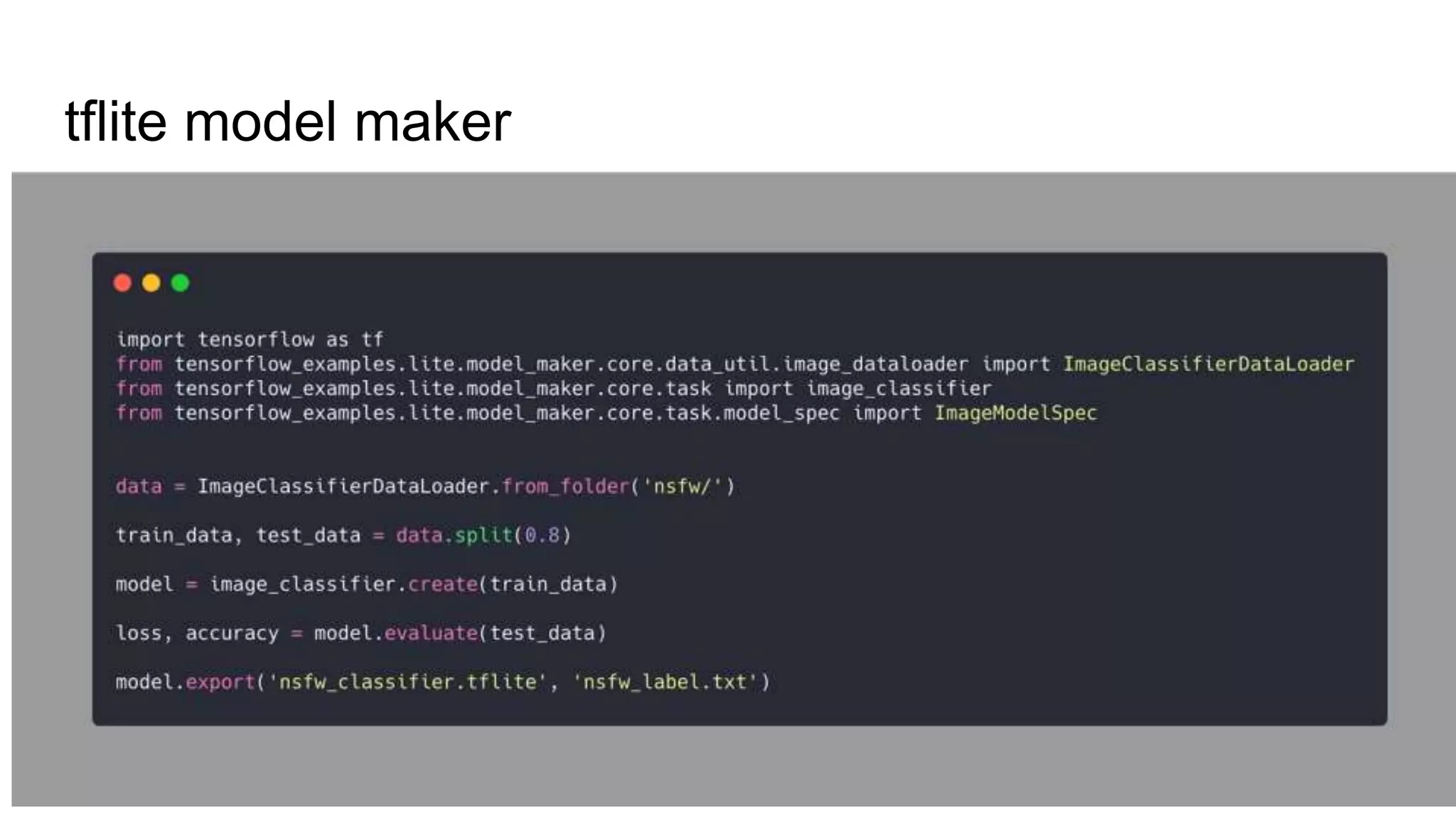
Edge computing and machine learning have several advantages: lower latency for localized interactions, reduced network usage, and improved privacy. However, edge ML also faces challenges like limited computing power, memory, and battery life. TensorFlow Lite helps address these challenges by enabling simple and efficient ML models on edge devices. It provides tools to convert Keras models to TFLite format, optimize models for size and performance, and leverage device-specific accelerators. The document discusses techniques like quantization, pruning, and selecting only required operations to build high-quality edge ML models with TensorFlow Lite.