12
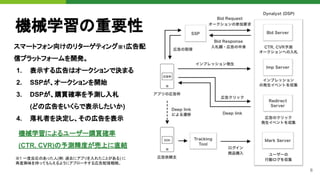
Cythonとは
PythonとC/C++の静的型システムを融合したプ
ログラミング言語。
● Cythonのソースコードを入力に、効率的な
C拡張モジュールを生成 ※1
●Pythonのスーパーセットな言語。静的型情
報を与えるほど高速なコードを生成
● C/C++とPythonとのインターフェイスとして
も利用可能
In [1]: %load_ext cython
In [2]: def py_fibonacci(n):
...: a, b = 0.0, 1.0
...: for i in range(n):
...: a, b = a + b, a
...: return a
In [2]: %%cython
...: def cy_fibonacci(int n):
...: cdef int i
...: cdef double a = 0.0, b = 1.0
...: for i in range(n):
...: a, b = a + b, a
...: return a
In [4]: %timeit py_fibonacci(10)
582 ns ± 3.72 ns per loop (...)
In [5]: %timeit cy_fibonacci(10)
43.4 ns ± 0.14 ns per loop (...)
※1 手書きのCコードより高速になることも珍しくない。また移植性も高く、多く
のPythonバージョンやCコンパイラをサポートする。
45
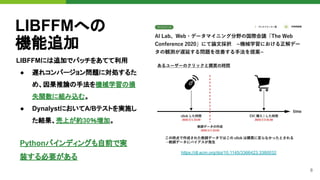
機械学習システムの開発の難しさ
“In an MLproject, the team usually includes data scientists or ML researchers,
who focus on exploratory data analysis, model development, and
experimentation. These members might not be experienced software
engineers who can build production-class services.”
ー MLOps: Continuous delivery and automation... (cloud.google.com)
開発初期の頃、Flaskで実装したWebSocketサーバーが
特定の条件下で固まって動かなくなると相談を受ける。
結構ややこしく、わかりやすい資料もないためハマる人が多そうな問題。








![12
Cythonとは
PythonとC/C++の静的型システムを融合したプ
ログラミング言語。
● Cythonのソースコードを入力に、効率的な
C拡張モジュールを生成 ※1
● Pythonのスーパーセットな言語。静的型情
報を与えるほど高速なコードを生成
● C/C++とPythonとのインターフェイスとして
も利用可能
In [1]: %load_ext cython
In [2]: def py_fibonacci(n):
...: a, b = 0.0, 1.0
...: for i in range(n):
...: a, b = a + b, a
...: return a
In [2]: %%cython
...: def cy_fibonacci(int n):
...: cdef int i
...: cdef double a = 0.0, b = 1.0
...: for i in range(n):
...: a, b = a + b, a
...: return a
In [4]: %timeit py_fibonacci(10)
582 ns ± 3.72 ns per loop (...)
In [5]: %timeit cy_fibonacci(10)
43.4 ns ± 0.14 ns per loop (...)
※1 手書きのCコードより高速になることも珍しくない。また移植性も高く、多く
のPythonバージョンやCコンパイラをサポートする。](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-12-320.jpg)
![13
Cythonによる
高速化
必要なステップは主に次の5つ
1. Cythonファイルの用意 (拡張子は .pyx)
2. cdefキーワードによる静的な型宣言
3. コードアノテーションの確認 ※1
4. setuptoolsスクリプトを用意
5. C拡張モジュールのコンパイル
from setuptools import setup, Extension
from Cython.Build import cythonize
setup(
...,
ext_modules=cythonize([
Extension("foo", sources=["foo.pyx"]),
]),
)
※1 cythonコマンド(cython -a foo.pyx)や、cythonize(..., annotate=True)オプ
ション、IPythonマジックコマンド(%%cython -a)で生成可能。
# cython: language_level=3
def predict(float[:, :, :] weights, float[:, :] x):
cdef float result
...
return result
# Cレベル関数宣言
cdef float sigmoid(float x):
return 1.0 / (1.0 + e ** (-x))
$ python setup.py build_ext --inplace](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-13-320.jpg)


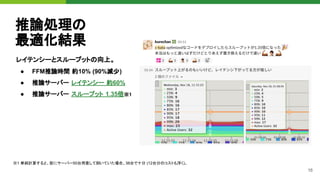

![18
C++ライブラリを
ラップする
1. cdef extern from による宣言。
2. PyMem_Malloc※1でC++構造体初期化。
3. C++コードの呼び出し。
4. 確保したメモリ領域を、PyMem_Freeで解
放。
# cython: language_level=3
from cpython.mem cimport PyMem_Malloc, PyMem_Free
cdef extern from "ffm.h" namespace "ffm" nogil:
struct ffm_problem:
ffm_data* data
ffm_model *ffm_train_with_validation(...)
cdef ffm_problem* make_ffm_prob(...):
cdef ffm_problem* prob
prob = <ffm_problem *> PyMem_Malloc(sizeof(ffm_problem))
if prob is NULL:
raise MemoryError("Insufficient memory for prob")
prob.data = ...
return prob
def train(...):
cdef ffm_problem* tr_ptr = make_ffm_prob(...)
try:
tr_ptr = make_ffm_prob(tr[0], tr[1])
model_ptr = ffm_train_with_validation(tr_ptr, ...)
finally:
free_ffm_prob(tr_ptr)
return weights, best_iteration
※1 from libc.stdlib cimport malloc も利用できますが、PyMem_Mallocは
CPythonのヒープからメモリ領域を確保するため、システムコールの発行回数を抑え
ることができる。特に小さな領域はこちらから確保するほうが効率的](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-18-320.jpg)

![21
多次元配列のメモリレイアウト
>>> x = np.arange(12).reshape((3, 4), order='C')
>>> x
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> x.flatten()
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> x = np.arange(12).reshape((3, 4), order='F')
>>> x
array([[ 0, 3, 6, 9],
[ 1, 4, 7, 10],
[ 2, 5, 8, 11]])
>>> x.flatten()
array([ 0, 3, 6, 9, 1, 4, 7, 10, 2, 5, 8, 11])
● Numpy配列作成関数(np.ones, np.empty等)のデフォルトレイアウトはすべてC連続。
● Fortran連続なNumPy配列は、np.ones(..., order=’F’) のようにorder引数を指定。
C連続 (C contiguous)
バッファがメモリの連続領域にまとまっていて、
最後の次元がメモリ内で連続
。
Fortran連続 (Fortran contiguous)
バッファがメモリの連続領域にまとまっていて、
最初の次元がメモリ内で連続
。](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-21-320.jpg)

![23
【余談】型付きメモリビュー
Cythonの中で扱うだけなら、型付きメモリビュー(Typed Memoryview)の利用を推奨。
# model_ptr.W は、C連続なshape=(n, m, k) の多次元配列
cdef ffm_problem* model_ptr
model_ptr = train_with_validation(...)
# 最後の次元のストライドを 1に(最後の次元が連続 )、それ以外をコロン 1つに設定する ※1
cdef ffm_float[:, :, ::1] mv = <ffm_float[:model_ptr.n, :model_ptr.m, :model_ptr.k]> model_ptr.W
print("配列のsize:", mv.size)
print("配列のshape:", mv.shape)
print("weights[0, 0, 0] の値:", mv[0, 0, 0])
※1 Fortran連続(最初の次元が連続)な配列の型付きメモリービューは、 cdef ffm_float[::1, :, :] mv のように宣言する。他のレイアウトにも対応できるが、C連続 or Fortran連
続にしておくとCythonはストライドアクセスを計算に入れないより効率的なコードを生成できる。
● memoryview風のインターフェイスを提供。Cレベルでバッファを直接操作するより簡単。
● Pythonのオーバーヘッドがかからない(Python/C APIを呼び出さない)。GILも解除可能。](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-23-320.jpg)




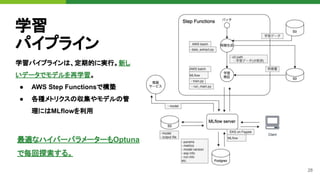


![31
Optuna
PFN社が開発・公開しているハイパーパ
ラメータ最適化ライブラリ
● Define-by-Runスタイルによる柔
軟な探索空間の定義
● 豊富なアルゴリズムのサポート
● プラガブルなストレージバックエンド
● シンプルな分散最適化機構
● リッチなWeb Dashboard
https://github.com/optuna/optuna
import optuna
def objective(trial):
regressor_name = trial.suggest_categorical(
'classifier', ['SVR', 'RandomForest']
)
if regressor_name == 'SVR':
svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True)
regressor_obj = sklearn.svm.SVR(C=svr_c)
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32)
regressor_obj = RandomForestRegressor(max_depth=rf_max_depth)
X_train, X_val, y_train, y_val = ...
regressor_obj.fit(X_train, y_train)
y_pred = regressor_obj.predict(X_val)
return sklearn.metrics.mean_squared_error(y_val, y_pred)
study = optuna.create_study()
study.optimize(objective, n_trials=100)](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-31-320.jpg)


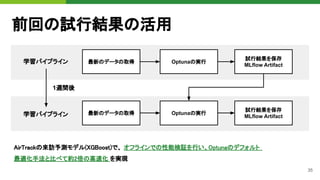

![37
Optunaと
MLflowの連携
Optunaの試行結果(SQLite3)は、MLflowの
アーティファクトとして保存
1. 事前情報として利用する試行結果の
取り出し(後述)
2. デフォルトパラメータの評価
3. メトリクスの収集
4. 試行結果のアップロード
mlflow.set_experiment("train_foo_model")
with mlflow.start_run(run_name="...") as run:
# 事前情報として利用する試行結果を取り出す(後述)
source_trials = ...
sampler = CmaEsSampler(source_trials=source_trials)
# 最初にXGBoostのデフォルトパラメーターを挿入
# (デフォルトよりも悪くならないことを保証する
)
study.enqueue_trial({"alpha": 0.0, ...})
study.optimize(optuna_objective, n_trials=20)
# 最適化にまつわるメトリクスの保存
mlflow.log_params(study.best_params)
mlflow.log_metric("default_trial_auc", study.trials[0].value)
mlflow.log_metric("best_trial_auc", study.best_value)
# 探索空間の変化に対応するためのタグ
mlflow.set_tag("optuna_objective_ver", optuna_objective_ver)
# Optunaの最適化結果(db.sqlite3)をアーティファクトに保存
mlflow.log_artifacts(dir_name)](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-37-320.jpg)
![38
前回の試行結果
の取得
先週のHPO試行結果を取り出す。
1. Model Registryから本番で利用して
いるモデルの情報を取得
2. Model InfoからRun IDを取得
3. RunのArtifactsからSQLite3ファイ
ルを取得
4. Optunaの探索空間が変化していな
いことは、タグで識別
def load_optuna_source_storage():
client = MlflowClient()
try:
model_infos = client.get_latest_versions(
model_name, stages=["Production"])
except mlflow_exceptions.RestException as e:
if e.error_code == "RESOURCE_DOES_NOT_EXIST":
# 初回実行時は、ここに到達する。
return None
raise
if len(model_infos) == 0:
return None
run_id = model_infos[0].run_id
run = client.get_run(run_id)
if run.data.tags.get("optuna_obj_ver") != optuna_obj_ver:
return None
filenames = [a.path for a client.list_artifacts(run_id)]
if optuna_storage_filename not in filenames:
return None
client.download_artifacts(run_id, path=..., dst_path=...)
return RDBStorage(f"sqlite:///path/to/optuna.db")](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-38-320.jpg)
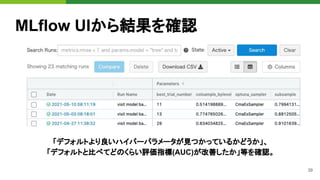
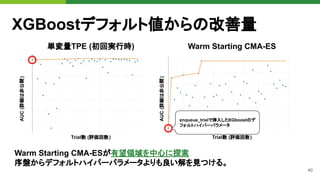



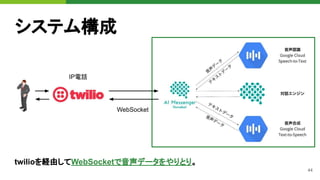


![47
Web Server Gateway Interface (PEP 3333)
● WSGIアプリケーションの実体は、callableなオブ
ジェクト (関数など)
● WebSocketのような双方向リアルタイム通信の実
現には工夫が必要 ※1
● WSGIアプリケーションを呼び出したスレッドは、通
信が終わるまで処理を離せない
● Websocketの接続数分のスレッドが必要
WSGIの制限
※1 AI Messanger Voicebotの開発初期に使われていた
Flask-sockets
(Kenneth Reitz作)では、事前に生成した
WebsocketオブジェクトをWSGI
environmentから渡してFlaskから使えるようにしている。
def application(env, start_response):
start_response('200 OK', [
('Content-type', 'text/plain; charset=utf-8')
])
return [b'Hello World']](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-47-320.jpg)


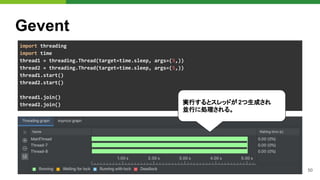
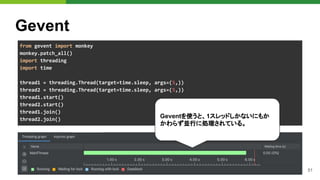
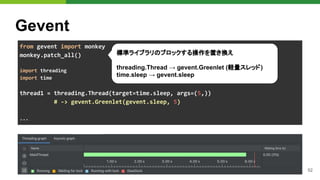
![53
WebSocket
Gevent-websocketの仕組み
● Gunicornワーカープロセス生成後に
Monkey patchを呼び出し
● WSGIアプリケーションは、gevent.
Greenlet(軽量スレッド)で呼び出し
● Monkey patchが対応していないものを使
うとブロック
from gevent.pool import Pool
from gevent import hub, monkey, socket, pywsgi
class GeventWorker(AsyncWorker):
def init_process(self):
# プロセス生成後に Monkeypatchをあてる
monkey.patch_all()
...
def run(self):
servers = []
for s in self.sockets:
# Greenlet(軽量スレッド)プールを用意
pool = Pool(self.worker_connections)
environ = base_environ(self.cfg)
environ.update({"wsgi.multithread": True})
server = self.server_class(
s, application=self.wsgi, ...
)
server.start()
servers.append(server)
gunicorn/workers/ggevent.py#L37-L38
このプロダクトでは、Text-to-Speech APIのSDK
が内部でgRPC 双方向ストリーミングを利用して
いたことが原因でした。](https://image.slidesharecdn.com/pydatatokyomlops-210526033304/85/MLOps-at-PyDataTokyo-23-53-320.jpg)









































![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)






























