Download as PDF, PPTX









![Cython
In [1]: %load_ext cython
In [2]: def py_fibonacci(n):
...: a, b = 0.0, 1.0
...: for i in range(n):
...: a, b = a + b, a
...: return a
In [2]: %%cython
...: def cy_fibonacci(int n):
...: cdef int i
...: cdef double a = 0.0, b = 1.0
...: for i in range(n):
...: a, b = a + b, a
...: return a
In [4]: %timeit py_fibonacci(10)
582 ns ± 3.72 ns per loop (...)
In [5]: %timeit cy_fibonacci(10)
43.4 ns ± 0.14 ns per loop (...)
An optimising static compiler for both
the Python and Cython](https://image.slidesharecdn.com/pyconapac2021masashishibata-211122111304/75/MLOps-Case-Studies-Building-fast-scalable-and-high-accuracy-ML-systems-at-PyCon-APAC-2021-11-2048.jpg)




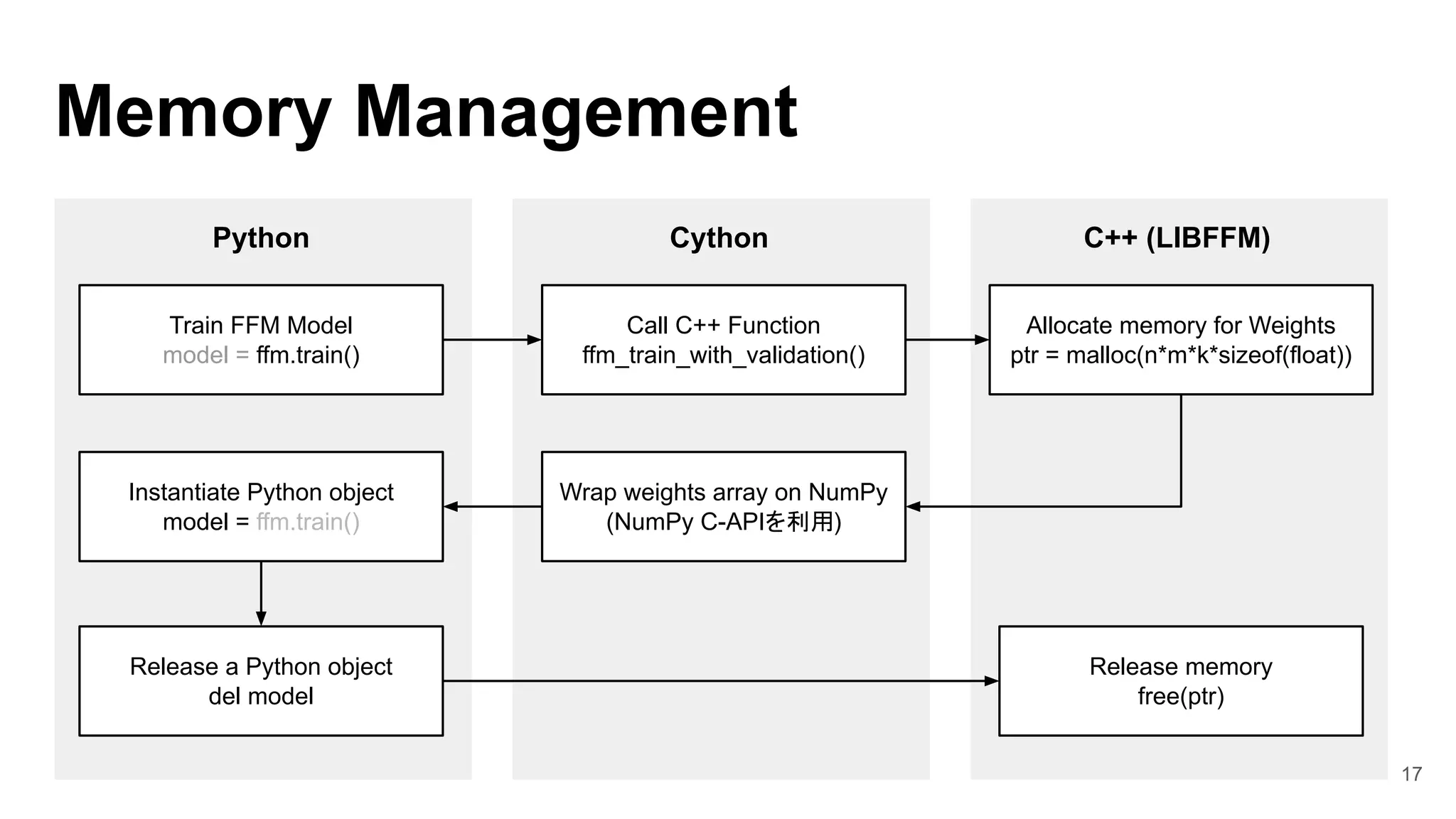
![16
Wrapping LIBFFM
1. Declare C++ functions and structs by
cdef extern from keyword
2. Initialize C++ structs by
PyMem_Malloc※1
3. Calling C++ functions
4. Release a memory by PyMem_Free
# cython: language_level=3
from cpython.mem cimport PyMem_Malloc, PyMem_Free
cdef extern from "ffm.h" namespace "ffm" nogil:
struct ffm_problem:
ffm_data* data
ffm_model *ffm_train_with_validation(...)
cdef ffm_problem* make_ffm_prob(...):
cdef ffm_problem* prob
prob = <ffm_problem *> PyMem_Malloc(sizeof(ffm_problem))
if prob is NULL:
raise MemoryError("Insufficient memory for prob")
prob.data = ...
return prob
def train(...):
cdef ffm_problem* tr_ptr = make_ffm_prob(...)
try:
tr_ptr = make_ffm_prob(tr[0], tr[1])
model_ptr = ffm_train_with_validation(tr_ptr, ...)
finally:
free_ffm_prob(tr_ptr)
return weights, best_iteration
※1 from libc.stdlib cimport malloc can also be used, but PyMem_Malloc
allocates memory area from the CPython heap, so the number of system call
issuance can be reduced. It is more efficient to allocate a particularly small area.](https://image.slidesharecdn.com/pyconapac2021masashishibata-211122111304/75/MLOps-Case-Studies-Building-fast-scalable-and-high-accuracy-ML-systems-at-PyCon-APAC-2021-16-2048.jpg)





![25
Optuna
Python library for hyperparameter
optimization.
● Define-by-Run style API
● Various state-of-the-art
algorithms support
● Pluggable storage backend
● Easy distributed optimization
● Web Dashboard
https://github.com/optuna/optuna
import optuna
def objective(trial):
regressor_name = trial.suggest_categorical(
'classifier', ['SVR', 'RandomForest']
)
if regressor_name == 'SVR':
svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True)
regressor_obj = sklearn.svm.SVR(C=svr_c)
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32)
regressor_obj = RandomForestRegressor(max_depth=rf_max_depth)
X_train, X_val, y_train, y_val = ...
regressor_obj.fit(X_train, y_train)
y_pred = regressor_obj.predict(X_val)
return sklearn.metrics.mean_squared_error(y_val, y_pred)
study = optuna.create_study()
study.optimize(objective, n_trials=100)](https://image.slidesharecdn.com/pyconapac2021masashishibata-211122111304/75/MLOps-Case-Studies-Building-fast-scalable-and-high-accuracy-ML-systems-at-PyCon-APAC-2021-25-2048.jpg)



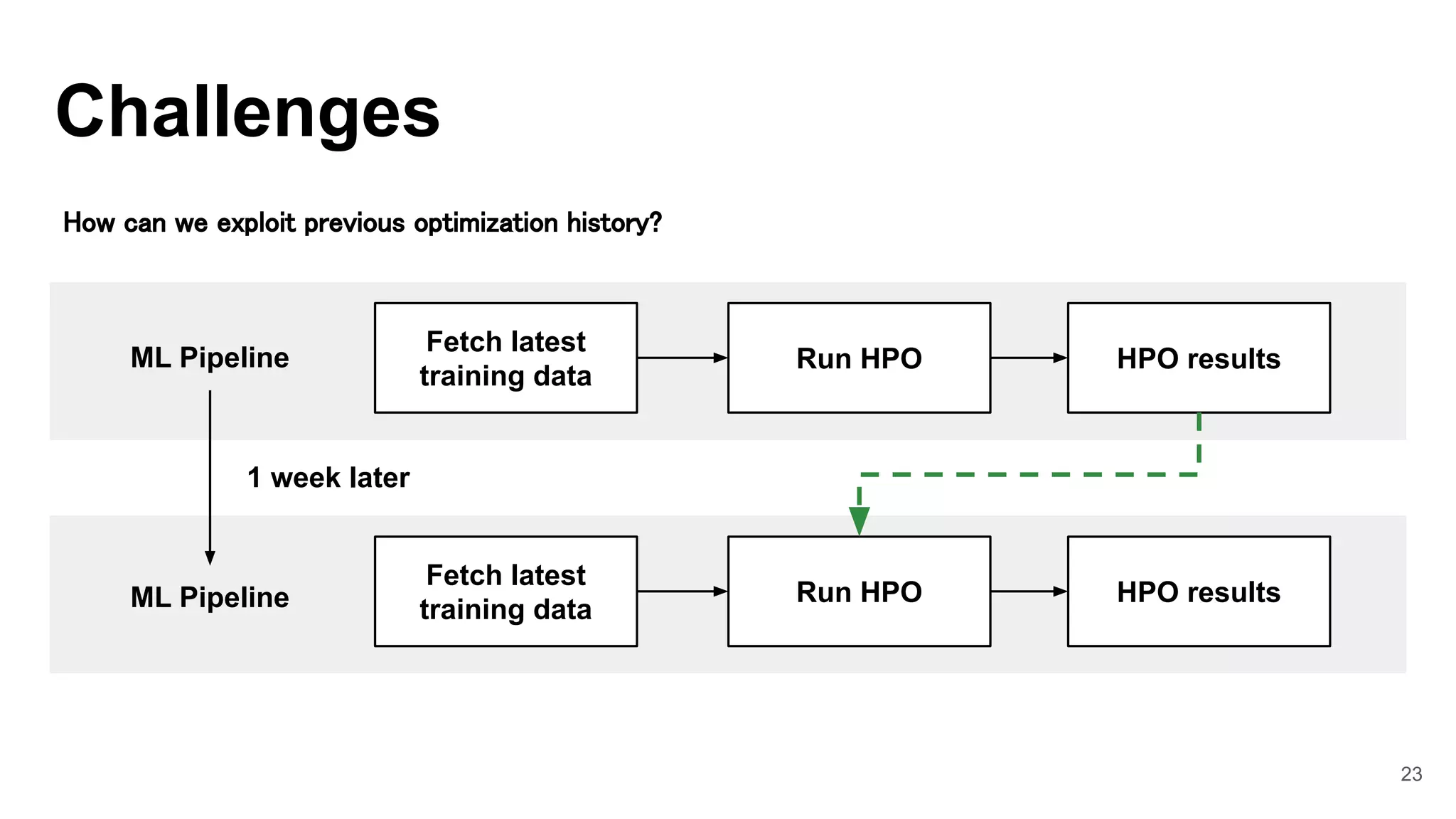
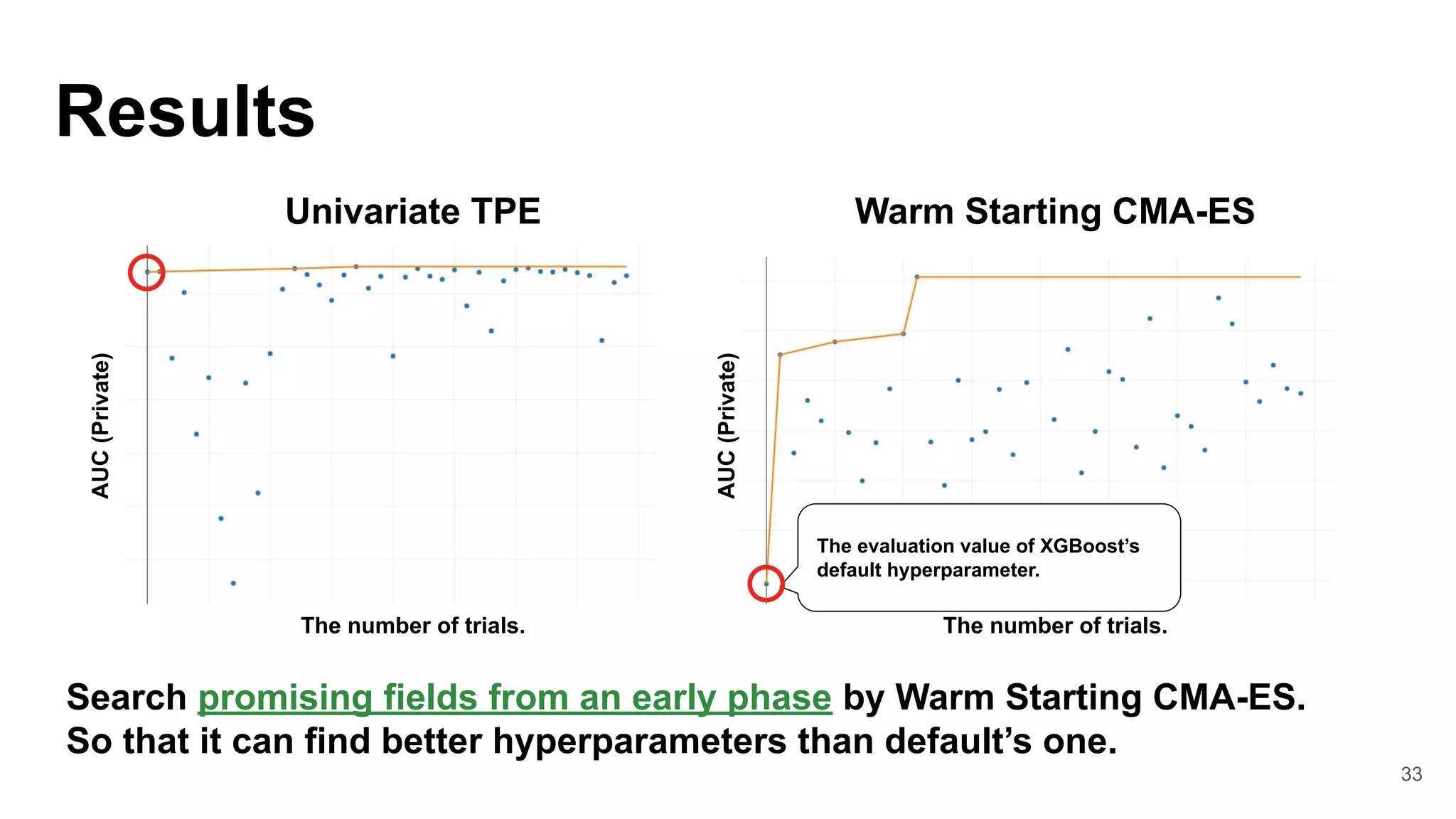
![31
Integrate Optuna
with MLflow
1. Retrieve source trials for
Warm-Starting CMA-ES.
2. Evaluate a default hyperparameter.
3. Collect metrics of HPO.
4. Save Optuna trials(SQLite3 file) in
MLflow Artifacts.
mlflow.set_experiment("train_foo_model")
with mlflow.start_run(run_name="...") as run:
# Retrieve source trials for Warm-Starting CMA-ES
source_trials = ...
sampler = CmaEsSampler(source_trials=source_trials)
# Enqueue a default hyperparameter of XGBoost. This means that
# we can find better hyperparameters than default at least.
study.enqueue_trial({"alpha": 0.0, ...})
study.optimize(optuna_objective, n_trials=20)
# Collect metrics of HPO
mlflow.log_params(study.best_params)
mlflow.log_metric("default_trial_auc", study.trials[0].value)
mlflow.log_metric("best_trial_auc", study.best_value)
# Set tag to detect search space changes
mlflow.set_tag("optuna_objective_ver", optuna_objective_ver)
# Save Optuna trials(SQLite3 file) in MLflow Artifacts
mlflow.log_artifacts(dir_name)](https://image.slidesharecdn.com/pyconapac2021masashishibata-211122111304/75/MLOps-Case-Studies-Building-fast-scalable-and-high-accuracy-ML-systems-at-PyCon-APAC-2021-31-2048.jpg)
![32
Retrieve previous
executions
1. Get a Model information from
MLflow Model Registry
2. Get Run ID from Model
information
3. Get SQLite3 file from Artifacts
def load_optuna_source_storage():
client = MlflowClient()
try:
model_infos = client.get_latest_versions(
model_name, stages=["Production"])
except mlflow_exceptions.RestException as e:
if e.error_code == "RESOURCE_DOES_NOT_EXIST":
# 初回実行時は、ここに到達する。
return None
raise
if len(model_infos) == 0:
return None
run_id = model_infos[0].run_id
run = client.get_run(run_id)
if run.data.tags.get("optuna_obj_ver") != optuna_obj_ver:
return None
filenames = [a.path for a client.list_artifacts(run_id)]
if optuna_storage_filename not in filenames:
return None
client.download_artifacts(run_id, path=..., dst_path=...)
return RDBStorage(f"sqlite:///path/to/optuna.db")](https://image.slidesharecdn.com/pyconapac2021masashishibata-211122111304/75/MLOps-Case-Studies-Building-fast-scalable-and-high-accuracy-ML-systems-at-PyCon-APAC-2021-32-2048.jpg)

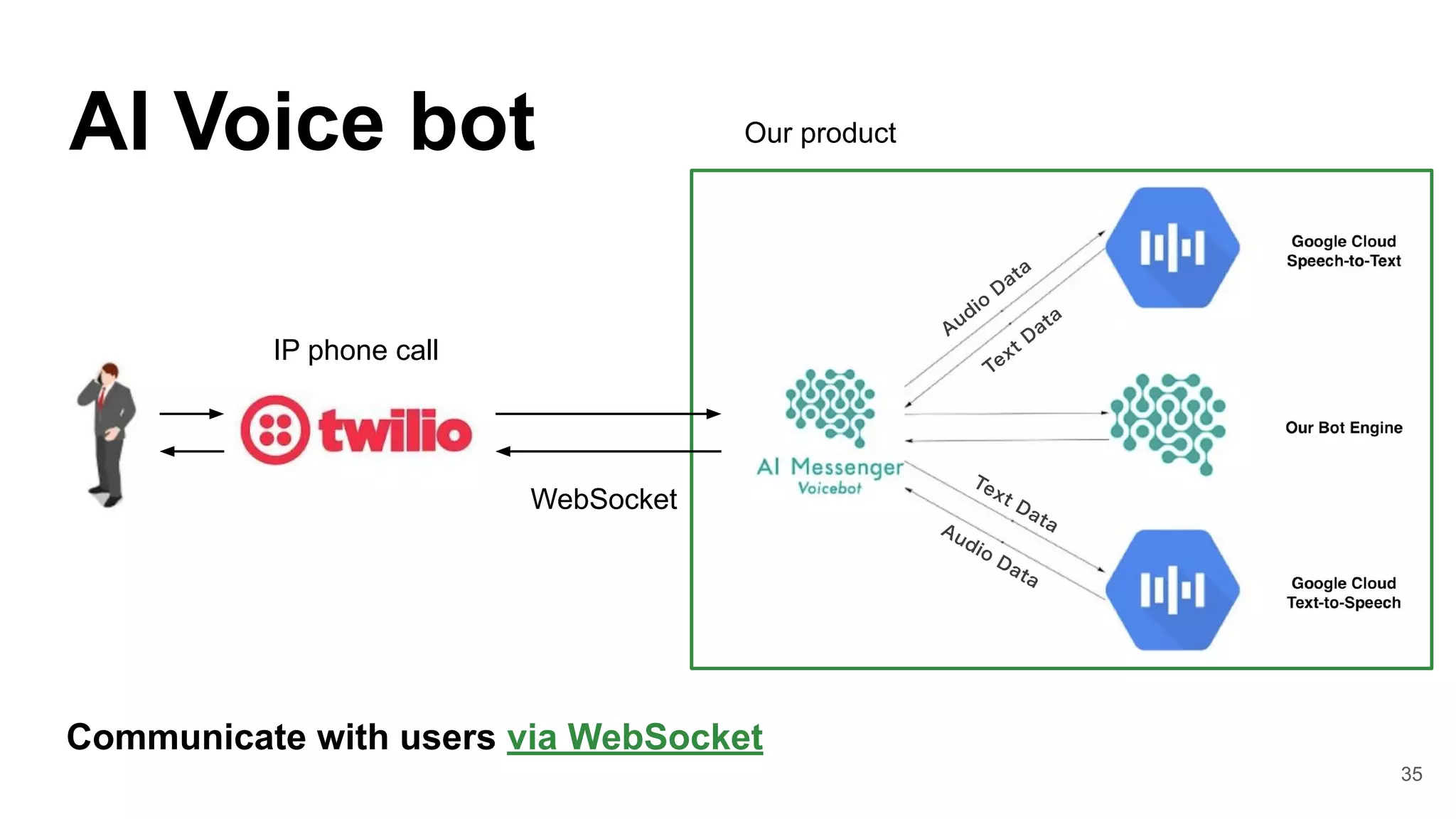


![38
Web Server Gateway Interface (PEP 3333)
● WSGI application is a callable object (e.g.
function)
● Difficult to implement Bidirectional Real-Time
Communication such as WebSocket ※1
● The thread that calls WSGI application cannot be
released until the communication is completed.
Limitations
※1 In Flask-sockets (created by Kenneth Reitz), pre-instantiate
WebSocket object is passed via WSGI environment and use it on Flask.
def application(env, start_response):
start_response('200 OK', [
('Content-type', 'text/plain; charset=utf-8')
])
return [b'Hello World']](https://image.slidesharecdn.com/pyconapac2021masashishibata-211122111304/75/MLOps-Case-Studies-Building-fast-scalable-and-high-accuracy-ML-systems-at-PyCon-APAC-2021-38-2048.jpg)


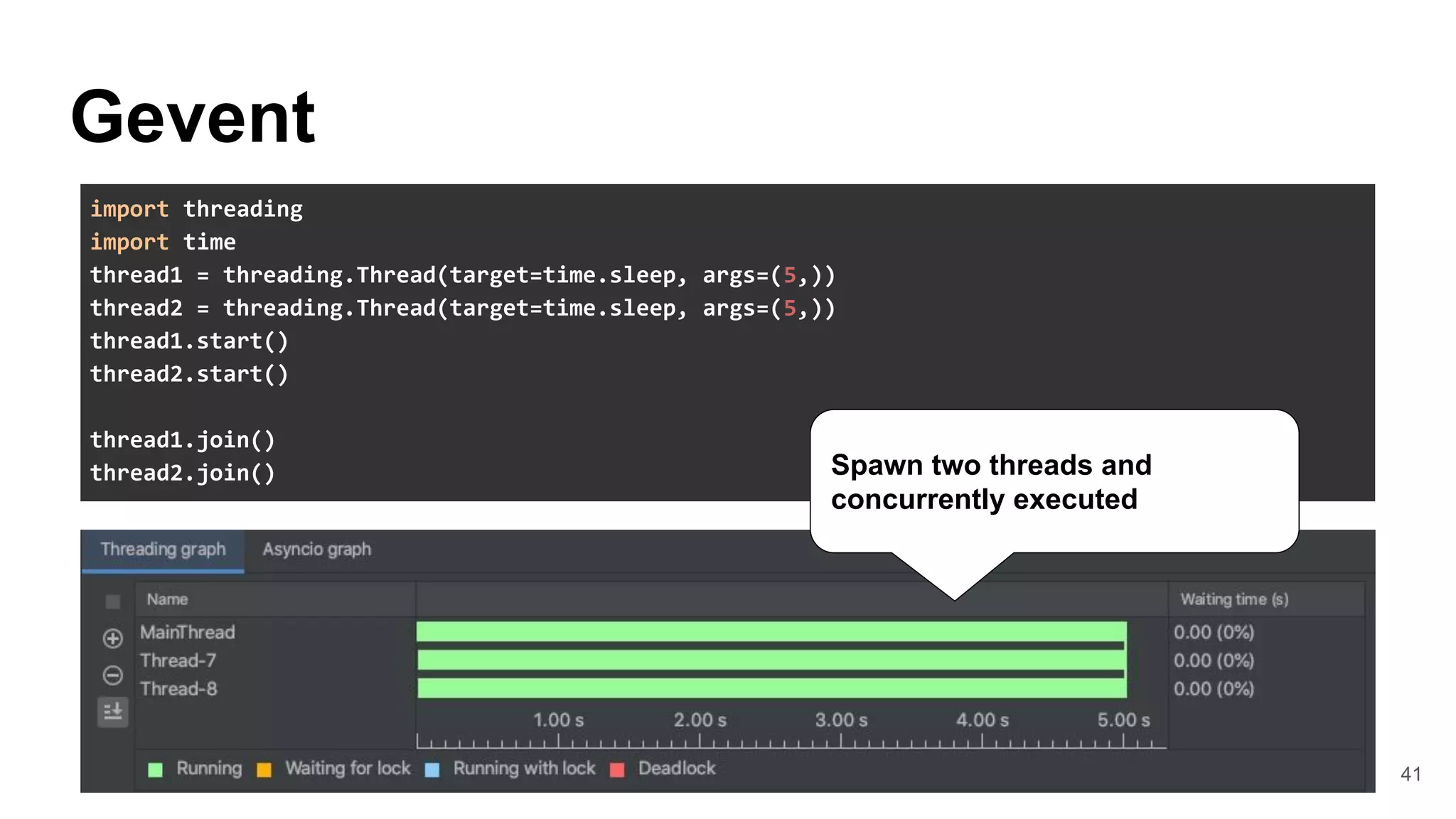
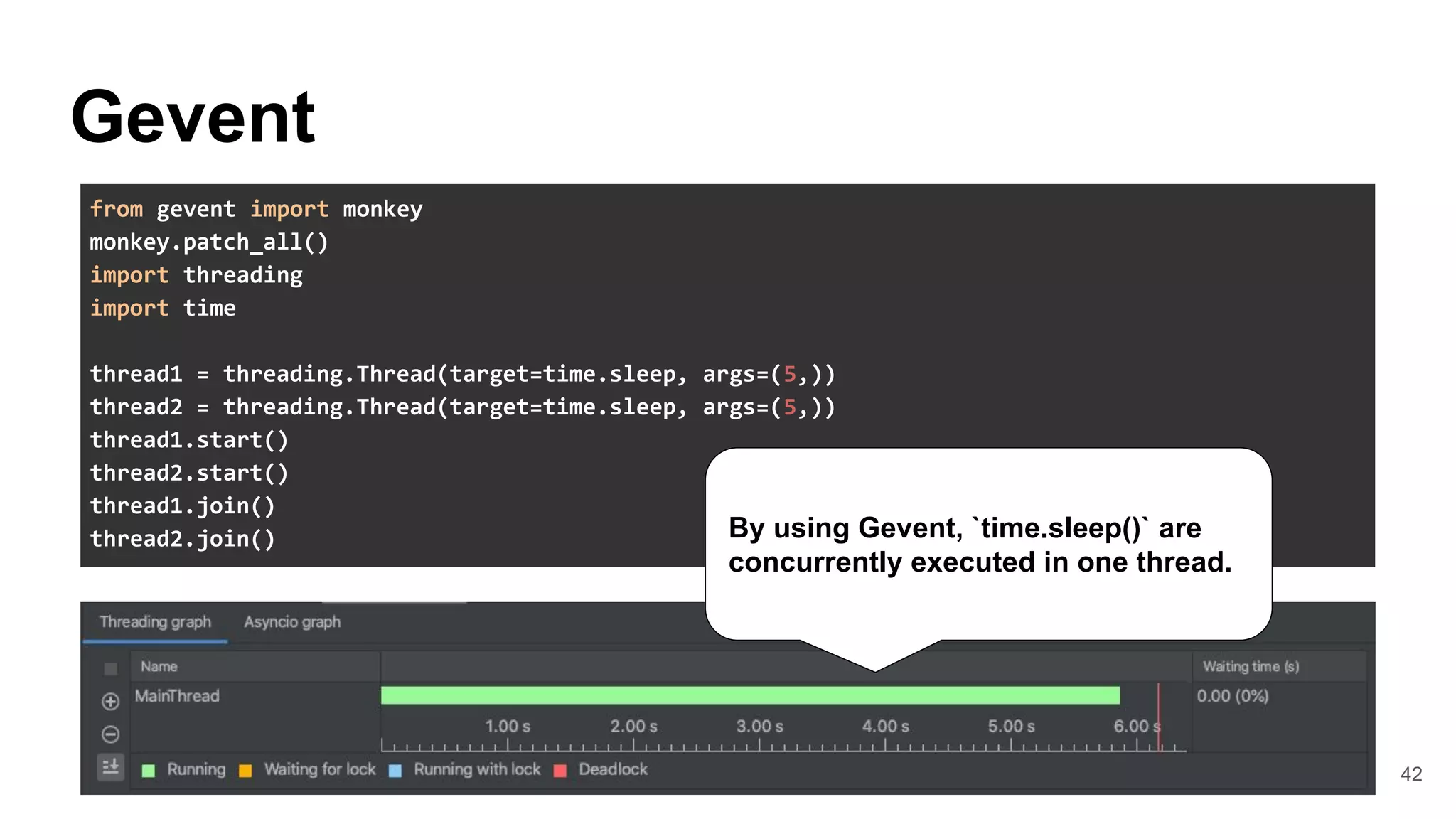
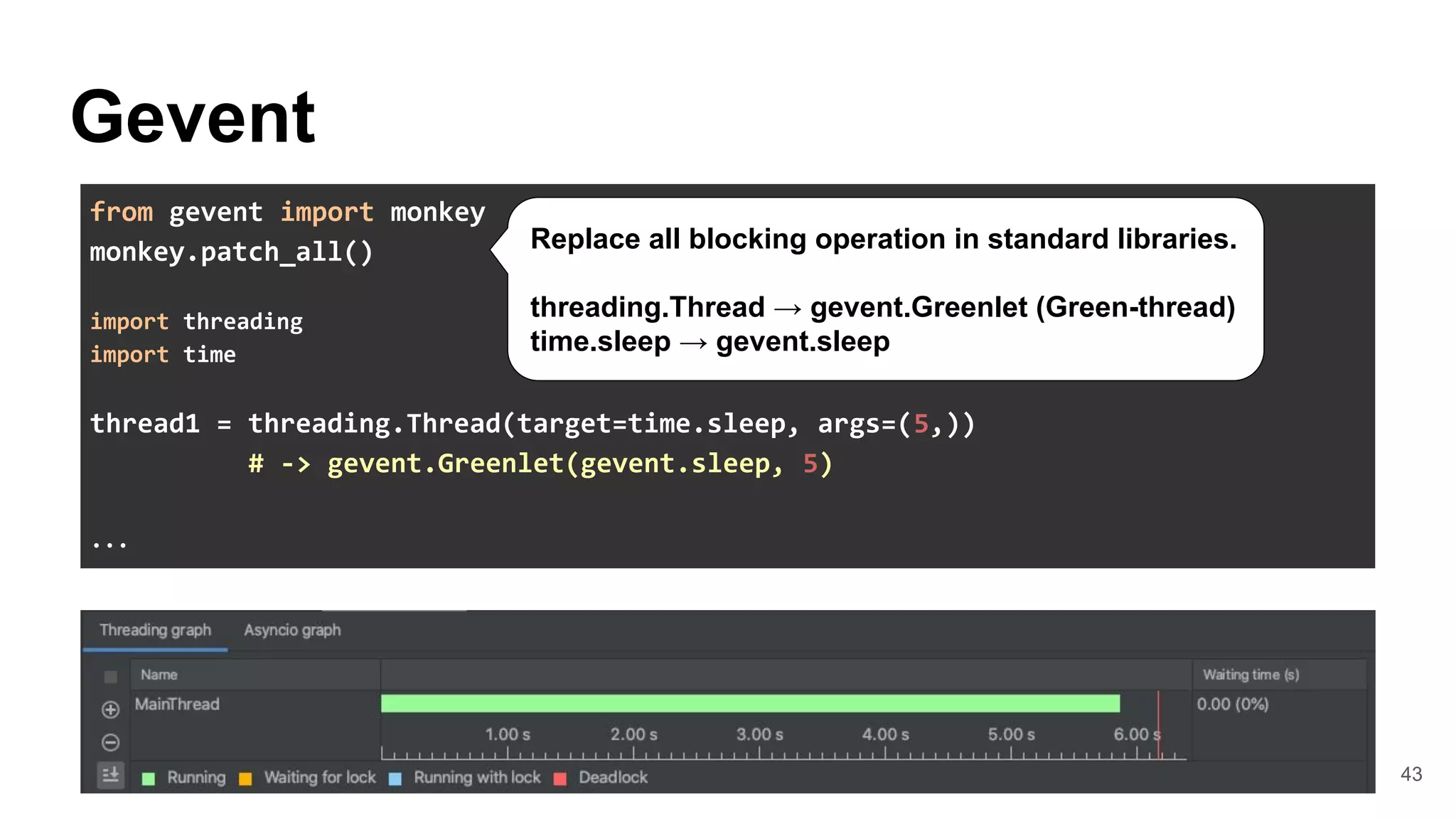
![44
WebSocket
The internal of Gevent-websocket
● Apply Monkey patches after spawned
worker processes.
● Call WSGI application on
gevent.Greenlet(Green-thread)
from gevent.pool import Pool
from gevent import hub, monkey, socket, pywsgi
class GeventWorker(AsyncWorker):
def init_process(self):
# Apply Monkey patches after spawned a process
monkey.patch_all()
...
def run(self):
servers = []
for s in self.sockets:
# Create Greenlet(Green Threadds) pool
pool = Pool(self.worker_connections)
environ = base_environ(self.cfg)
environ.update({"wsgi.multithread": True})
server = self.server_class(
s, application=self.wsgi, ...
)
server.start()
servers.append(server)
gunicorn/workers/ggevent.py#L37-L38
If third party library (e.g. gRPC library)
implements blocking operation, Gevent cannot
replace it by default.](https://image.slidesharecdn.com/pyconapac2021masashishibata-211122111304/75/MLOps-Case-Studies-Building-fast-scalable-and-high-accuracy-ML-systems-at-PyCon-APAC-2021-44-2048.jpg)




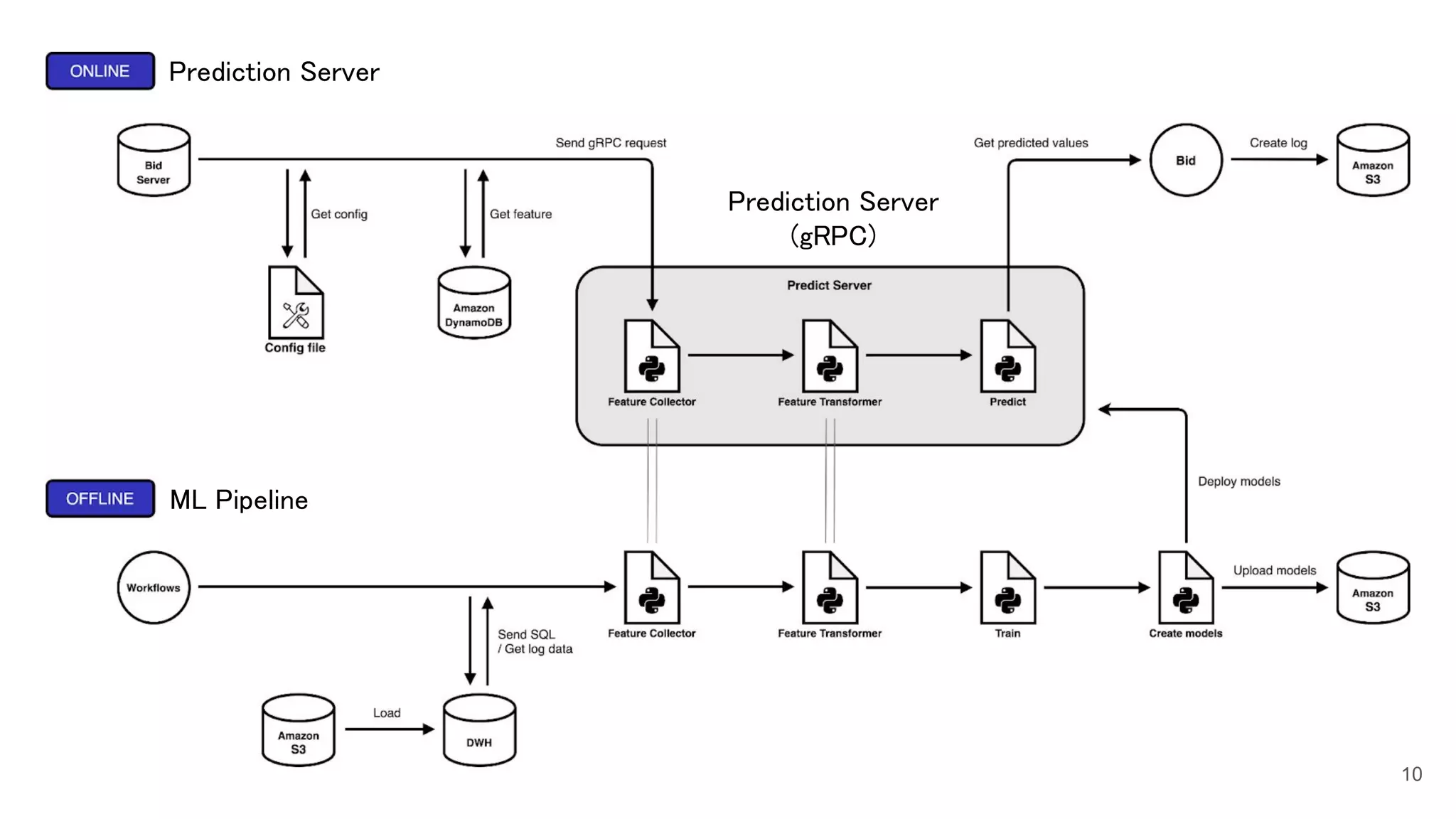
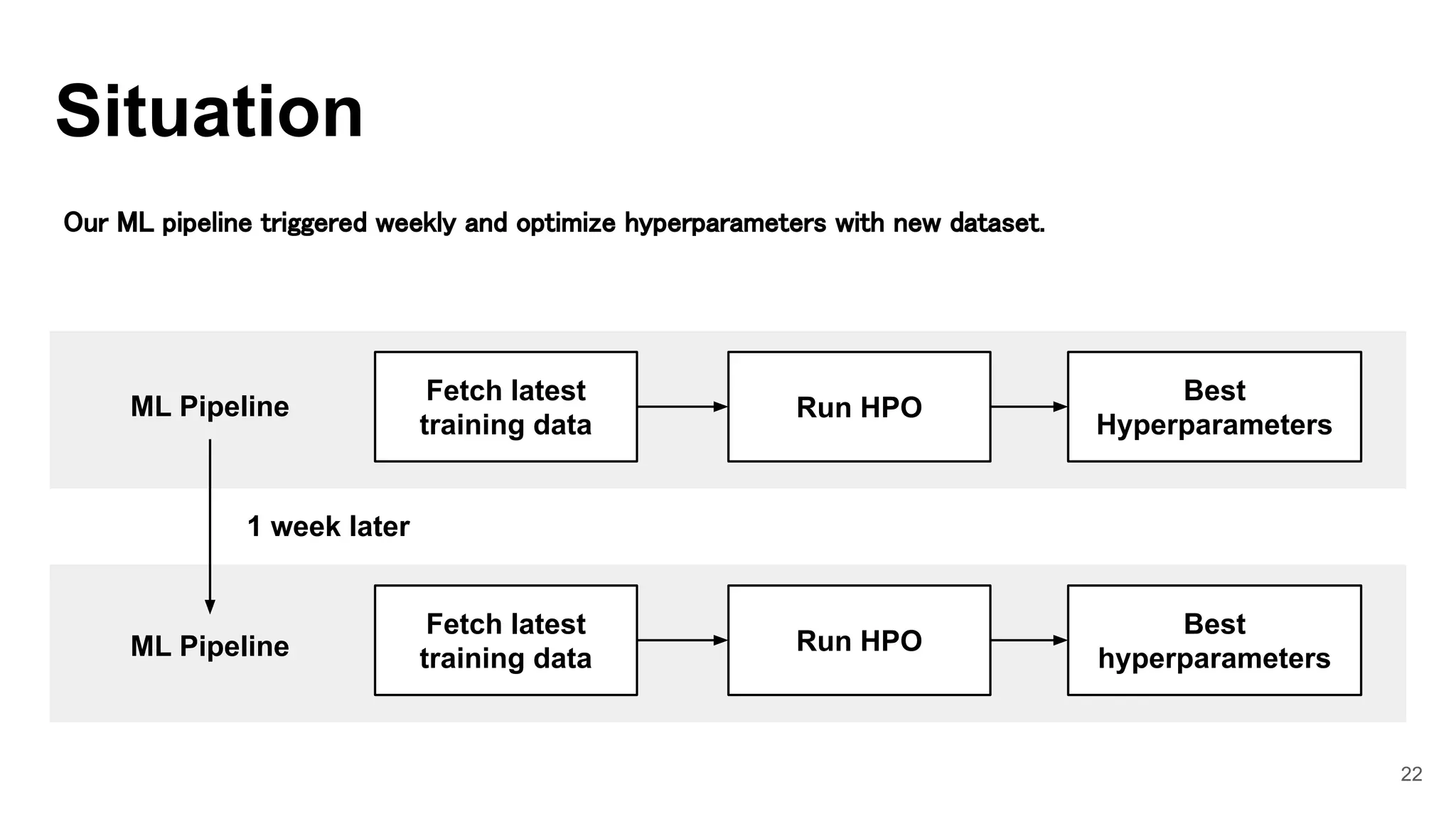
This document discusses three case studies for MLOps: 1. Building a memory-efficient Python binding for LIBFFM using Cython and NumPy C-API to implement their own Python binding. 2. Implementing a transfer learning method for hyperparameter optimization using Optuna and CMA-ES to exploit previous optimization history. 3. Accelerating a prediction server and addressing challenges of high throughput and low latency by using Cython to speed up inference processing, improving throughput by 1.35x and reducing latency by 60%.




































































![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)













![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)