ICML2015読み会での論文紹介スライドです。 http://connpass.com/event/17641/ ニューラルネットに特徴ハッシュを適用する話です。論文はこちら http://jmlr.org/proceedings/papers/v37/chenc15.html




![省省メモリで⾼高性能をめざす
ニューラルネットを圧縮する話はいろいろある
l いらない重みを取り除く [LeCun+, ʻ‘89]
l 重み共有(ConvNet, tied weights AE)
l 半精度度浮動⼩小数点 [Courbariaux+, ʻ‘14] [Gupta+, ʻ‘15]
l 重み⾏行行列列の低ランク近似 [Denil+, ʻ‘13] [Denton+, ʻ‘14]
l モデル圧縮・蒸留留 [Bucilu+, ʼ’06] [Hinton+, ʻ‘14] [Ba&Caruana, ʻ‘14]
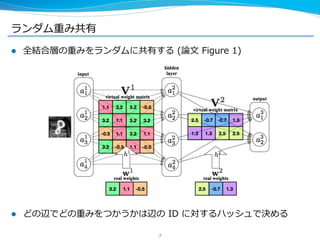
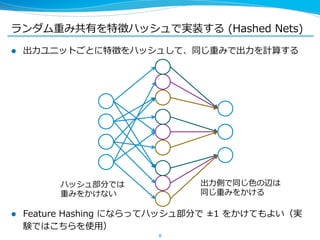
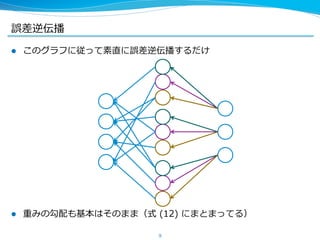
今⽇日紹介する論論⽂文の⼿手法 (Hashed Nets) はこれらと直交するテクニック
で、組み合わせてつかうこともできる
4](https://image.slidesharecdn.com/nn-with-hash-150820085321-lva1-app6891/85/Compressing-Neural-Networks-with-the-Hashing-Trick-4-320.jpg)
![Feature Hashing [Weinberger+, ICMLʼ’09]
l ハッシュ関数を使って、特徴量量を低次元に圧縮する
l 次元の対応とかける +1/-‐‑‒1 をともにハッシュ関数でつくる
5
特徴
Feature
ゲーム
hashing
⾯面⽩白い
おいしい
……
ハッシュ値
0
1
2
3
……
m
+
+
+
-
-
内積 内積
期待値が一致、
分散もバウンドあり](https://image.slidesharecdn.com/nn-with-hash-150820085321-lva1-app6891/85/Compressing-Neural-Networks-with-the-Hashing-Trick-5-320.jpg)
![Hashing Trick
l ハッシュを使って特徴ベクトルを低次元空間に埋め込むことで、カーネ
ルの内積をその低次元空間での線形な内積で表す
– Feature Hashing を使う=線形カーネル
– MinHash を使う=Jaccard 係数カーネル [Li+, NIPSʼ’11]
l Cf.) カーネルトリック
– ⾼高次元空間での内積を、ベクトルを陽に作らずに扱う
l Cf.) ランダム射影
– ⾼高次元空間での内積を、低次元空間での内積で近似する
– FastFood [Le+, ICMLʼ’13], Deep Fried ConvNet [Yang+, ʻ‘14]
l 3年年半前に PFI セミナーでも紹介しました
http://www.slideshare.net/pfi/pfi-‐‑‒seminar-‐‑‒20120315
6](https://image.slidesharecdn.com/nn-with-hash-150820085321-lva1-app6891/85/Compressing-Neural-Networks-with-the-Hashing-Trick-6-320.jpg)









![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Attention is not Explanation (NAACL2019)](https://cdn.slidesharecdn.com/ss_thumbnails/20190412dlhacks-190422080919-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)








































