Downloaded 272 times






![@PRACTICALDLBOOK
Latency Is Expensive!
7
100 milliseconds 1% loss
[Amazon 2008]](https://image.slidesharecdn.com/deeplearningonmobile-2019guide-190618172215/75/Deep-learning-on-mobile-2019-Practitioner-s-Guide-7-2048.jpg)
![@PRACTICALDLBOOK@PRACTICALDLBOOK
Latency Is Expensive!
8
>3 sec
load time
53%
bounce
Mobile Site Visits
[Google Research, Webpagetest.org]](https://image.slidesharecdn.com/deeplearningonmobile-2019guide-190618172215/75/Deep-learning-on-mobile-2019-Practitioner-s-Guide-8-2048.jpg)
![@PRACTICALDLBOOK@PRACTICALDLBOOK
Power of 10
9
0.1s
Seamless Uninterrupted
flow of thought
1s 10s
Limit of
attention
[Miller 1968; Card et al. 1991; Nielsen 1993]](https://image.slidesharecdn.com/deeplearningonmobile-2019guide-190618172215/75/Deep-learning-on-mobile-2019-Practitioner-s-Guide-9-2048.jpg)




















![@PRACTICALDLBOOK
AR Hand Puppets
Hart Woolery from 2020CV
Object Detection (Hand) + Key Point Estimation
47
[https://twitter.com/2020cv_inc/status/1093219359676280832]
AR Hand Puppets, Hart Woolery from 2020CV, Object Detection (Hand) + Key Point Estimation](https://image.slidesharecdn.com/deeplearningonmobile-2019guide-190618172215/75/Deep-learning-on-mobile-2019-Practitioner-s-Guide-47-2048.jpg)
![@PRACTICALDLBOOK 49
[HomeCourt.ai]Object Detection (Ball, Hoop, Player) + Body Pose + Perspective Transformation](https://image.slidesharecdn.com/deeplearningonmobile-2019guide-190618172215/75/Deep-learning-on-mobile-2019-Practitioner-s-Guide-49-2048.jpg)





![@PRACTICALDLBOOK
Pruning in Keras
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
59
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
prune.Prune(tf.keras.layers.Dense(512, activation=tf.nn.relu)),
tf.keras.layers.Dropout(0.2),
prune.Prune(tf.keras.layers.Dense(10, activation=tf.nn.softmax))
])](https://image.slidesharecdn.com/deeplearningonmobile-2019guide-190618172215/75/Deep-learning-on-mobile-2019-Practitioner-s-Guide-59-2048.jpg)





![@PRACTICALDLBOOK
On-Device Training in Core ML
69
let updateTask = try MLUpdateTask(
forModelAt: modelUrl,
trainingData: trainingData,
configuration: configuration,
completionHandler: { [weak self]
self.model = context.model
context.model.write(to: newModelUrl)
})
⁻ Core ML 3 introduced on device learning
⁻ Never have to send training data to the server with the
help of MLUpdateTask.
⁻ Schedule training when device is charging to save power](https://image.slidesharecdn.com/deeplearningonmobile-2019guide-190618172215/75/Deep-learning-on-mobile-2019-Practitioner-s-Guide-69-2048.jpg)







This document provides an overview of deep learning on mobile devices. It discusses why deep learning is important for mobile, including issues like privacy, reliability and latency. It then covers topics like how to train models for mobile using techniques like transfer learning and fine-tuning. The document also discusses frameworks for running models efficiently on mobile like Core ML, TensorFlow Lite and Google's ML Kit. It explores how hardware impacts performance and how to optimize models. Finally, it touches on applications of deep learning on mobile and techniques like federated learning.
Overview of the guide on deep learning focused on mobile applications.
Addresses privacy, reliability, cost, latency issues, and the significant impact of latency on user experience.
Discusses creating efficient mobile inference engines and fine-tuning existing models for improved mobile application performance.
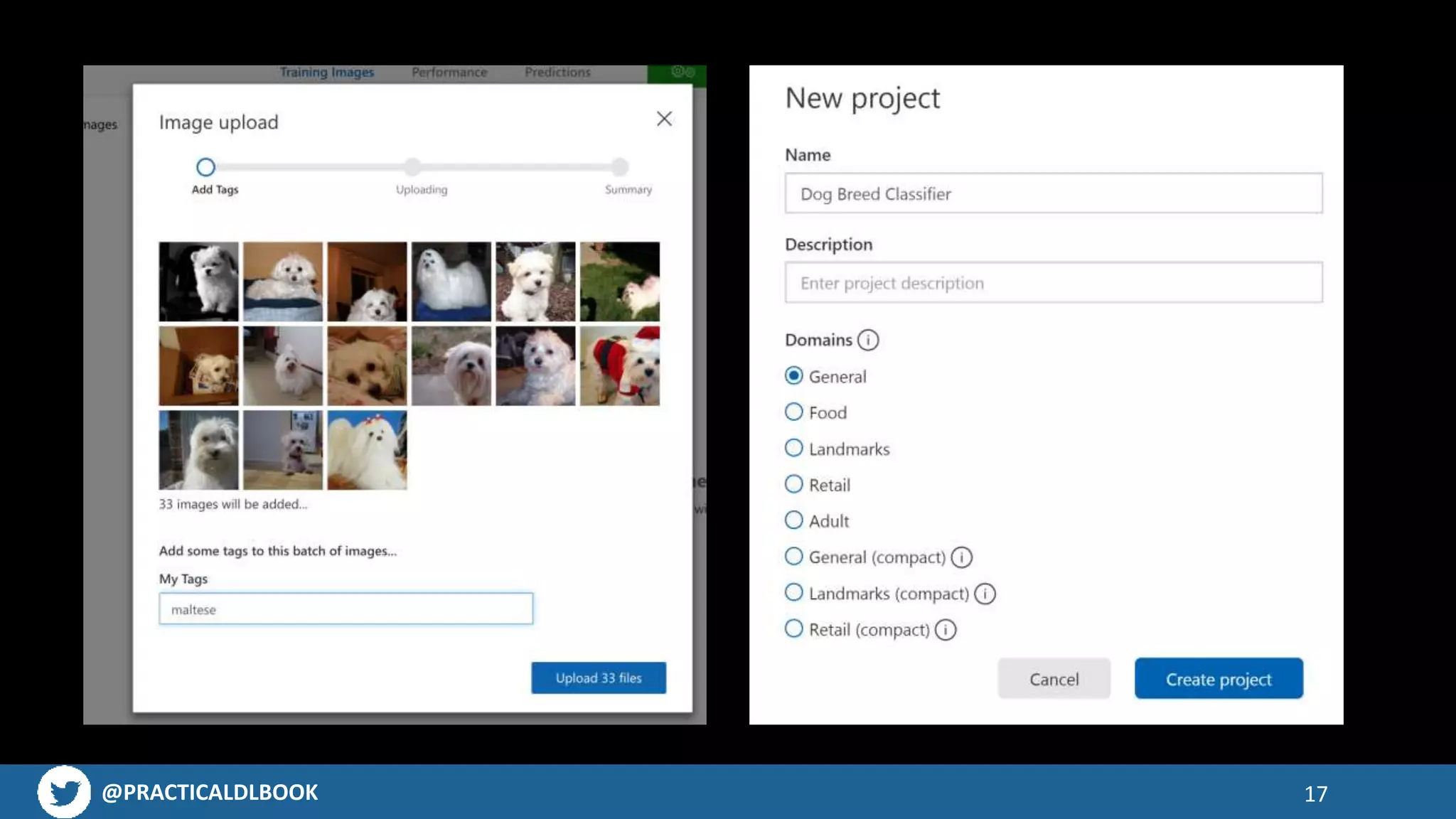
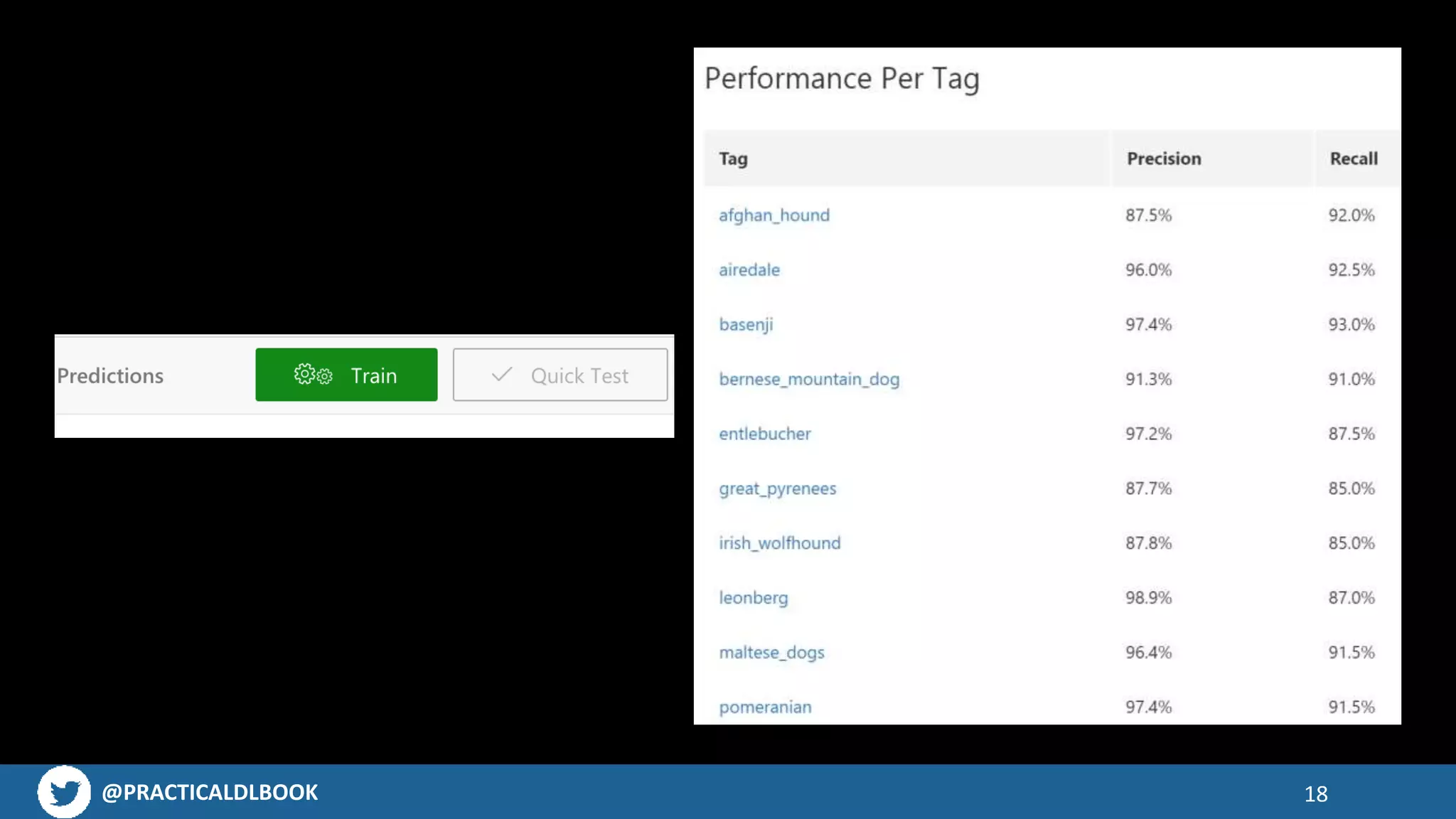
Guidance on collecting images for training models, emphasizing tools like Fatkun Browser Extension.
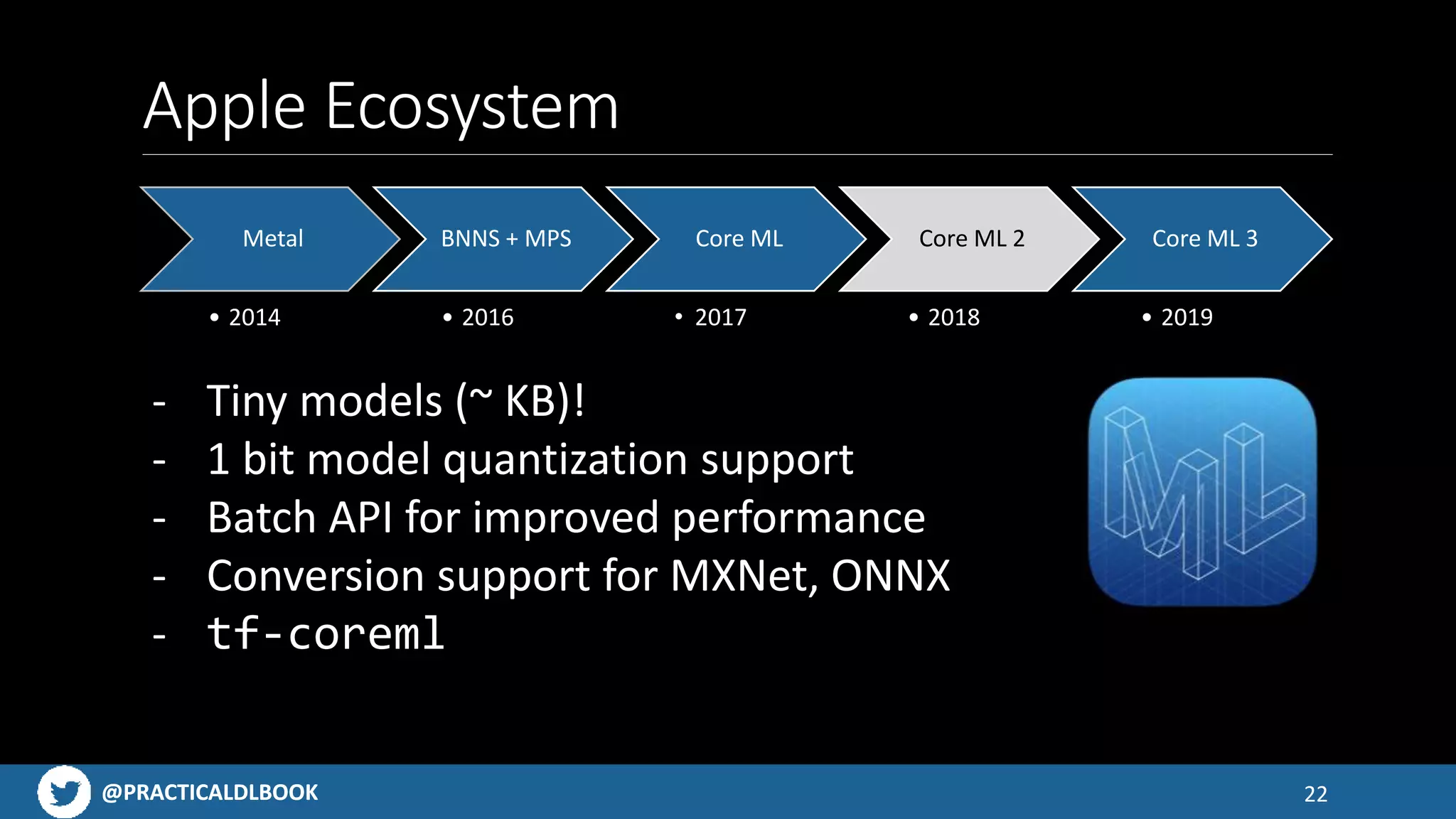
Explains how to run models on devices using Core ML, TensorFlow Lite, and ML Kit in the Apple ecosystem.
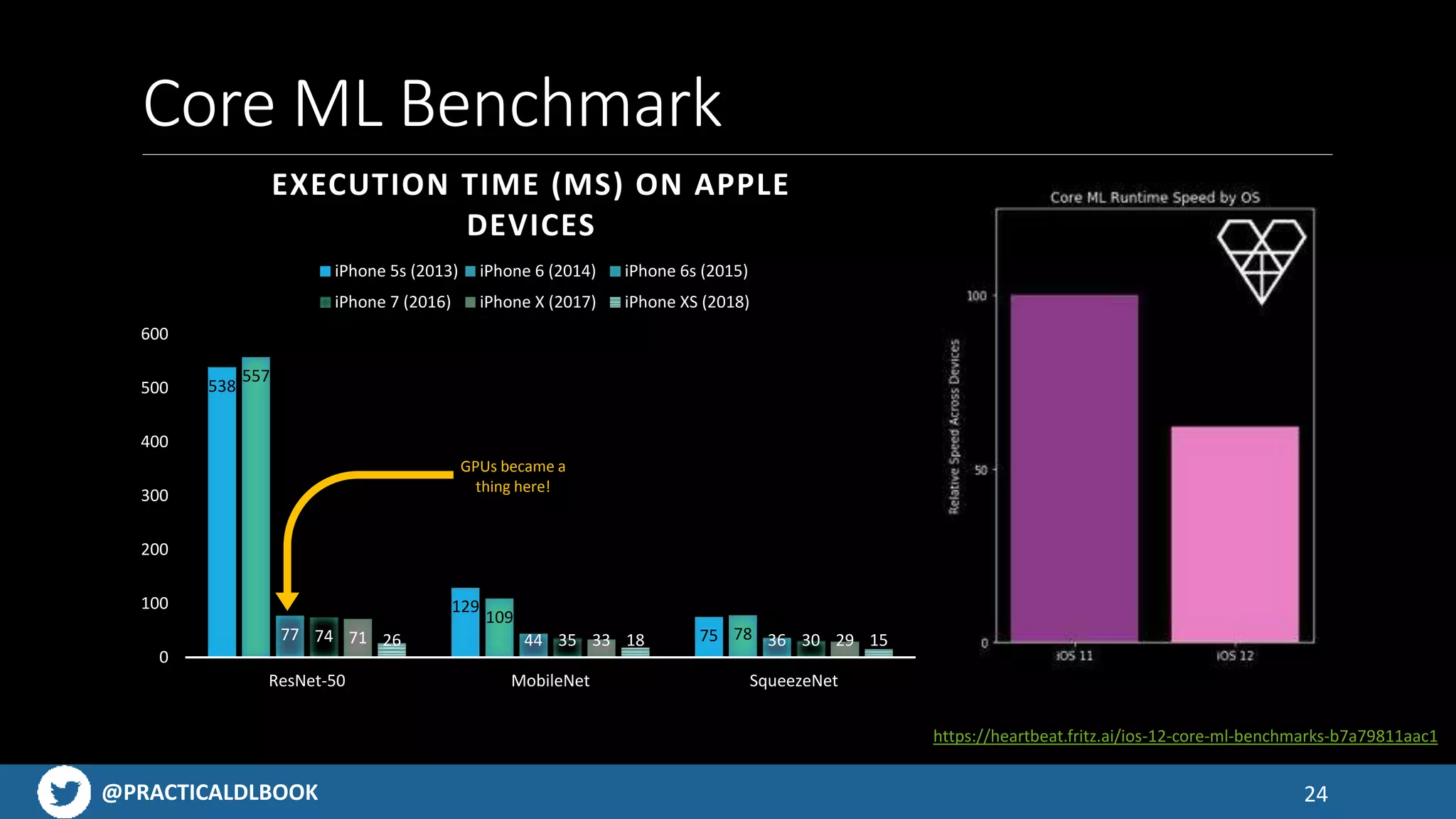
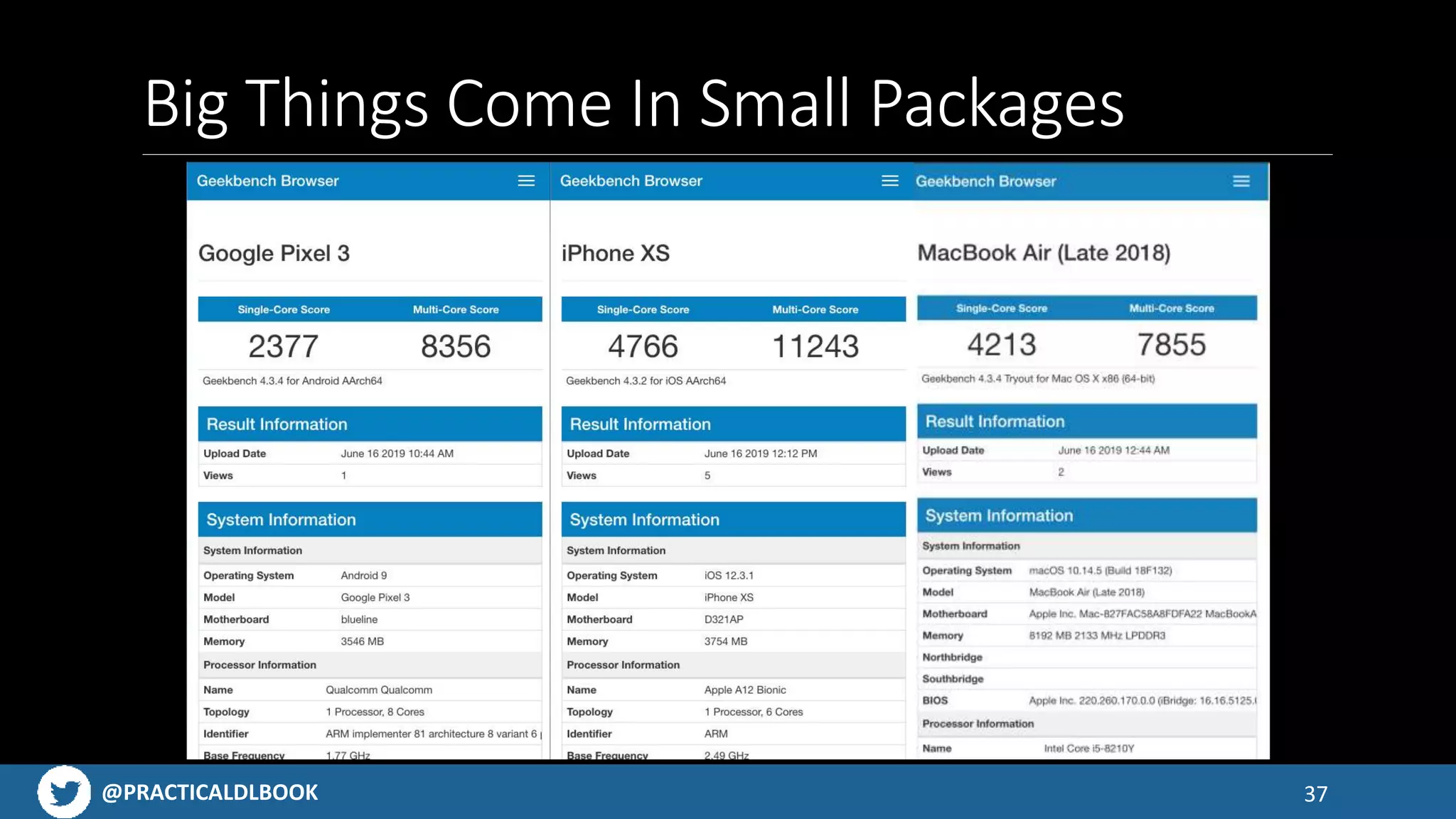
Benchmarks showing performance of various models on Apple devices, illustrating improvements in execution times.
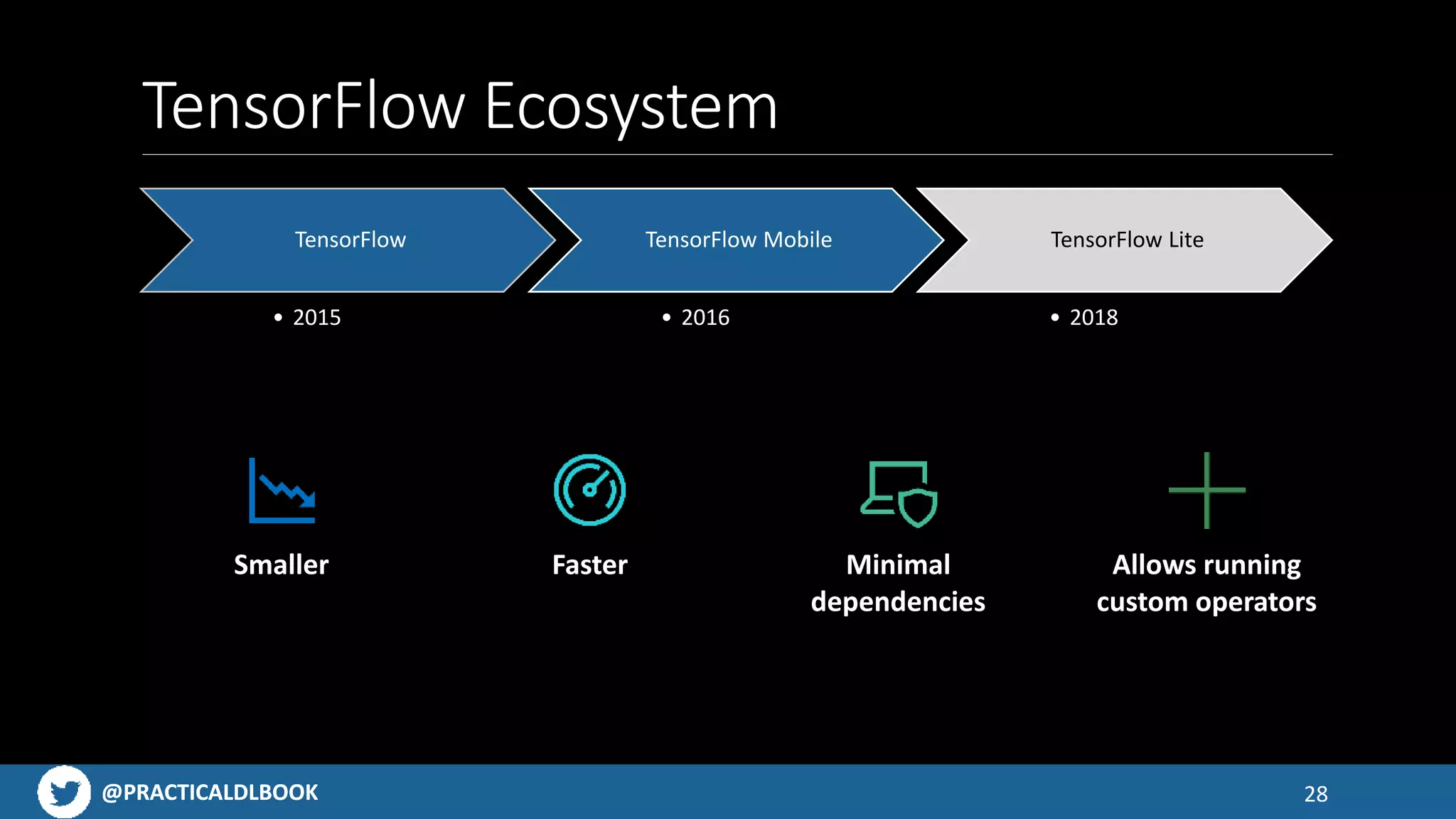
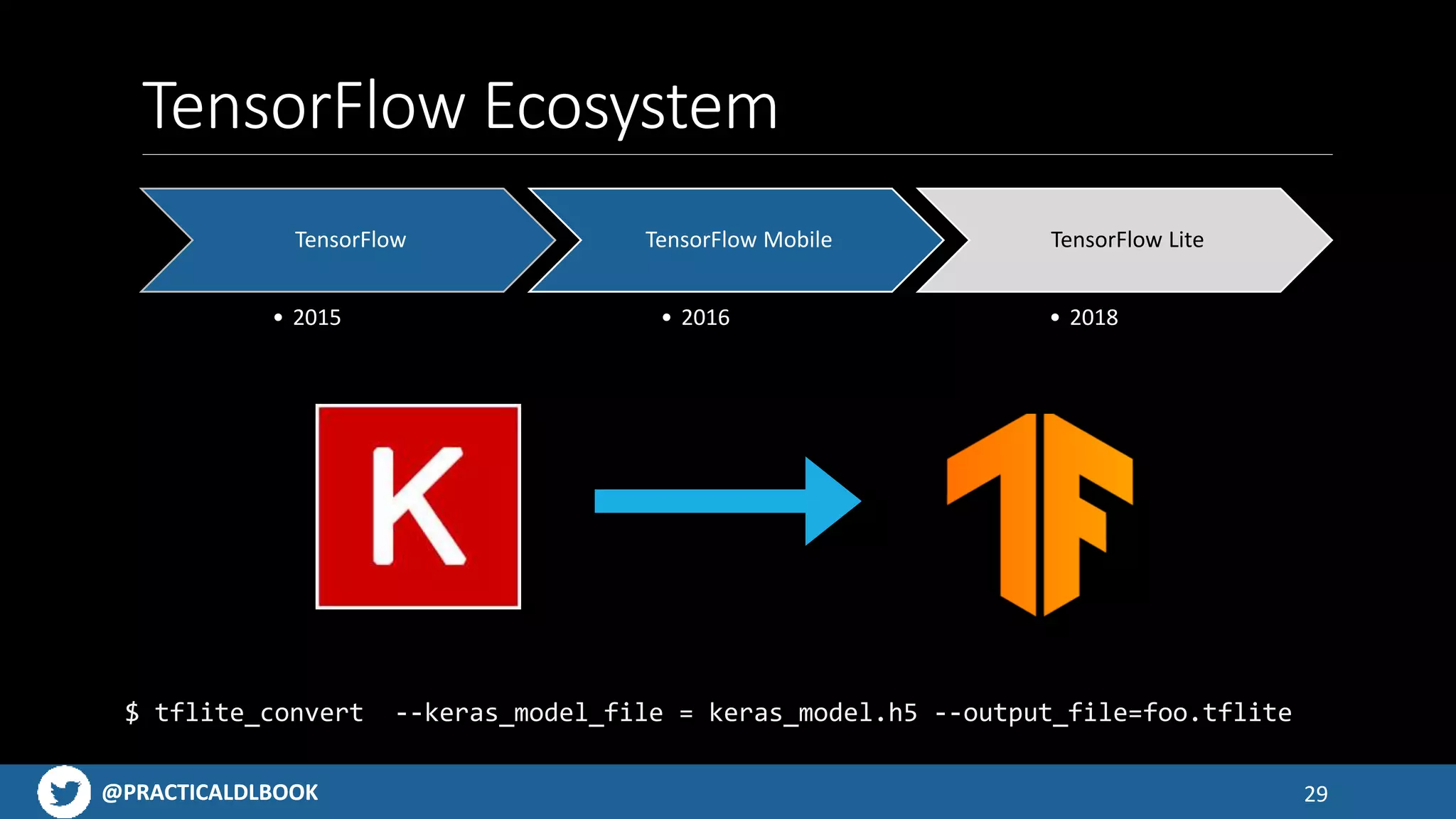
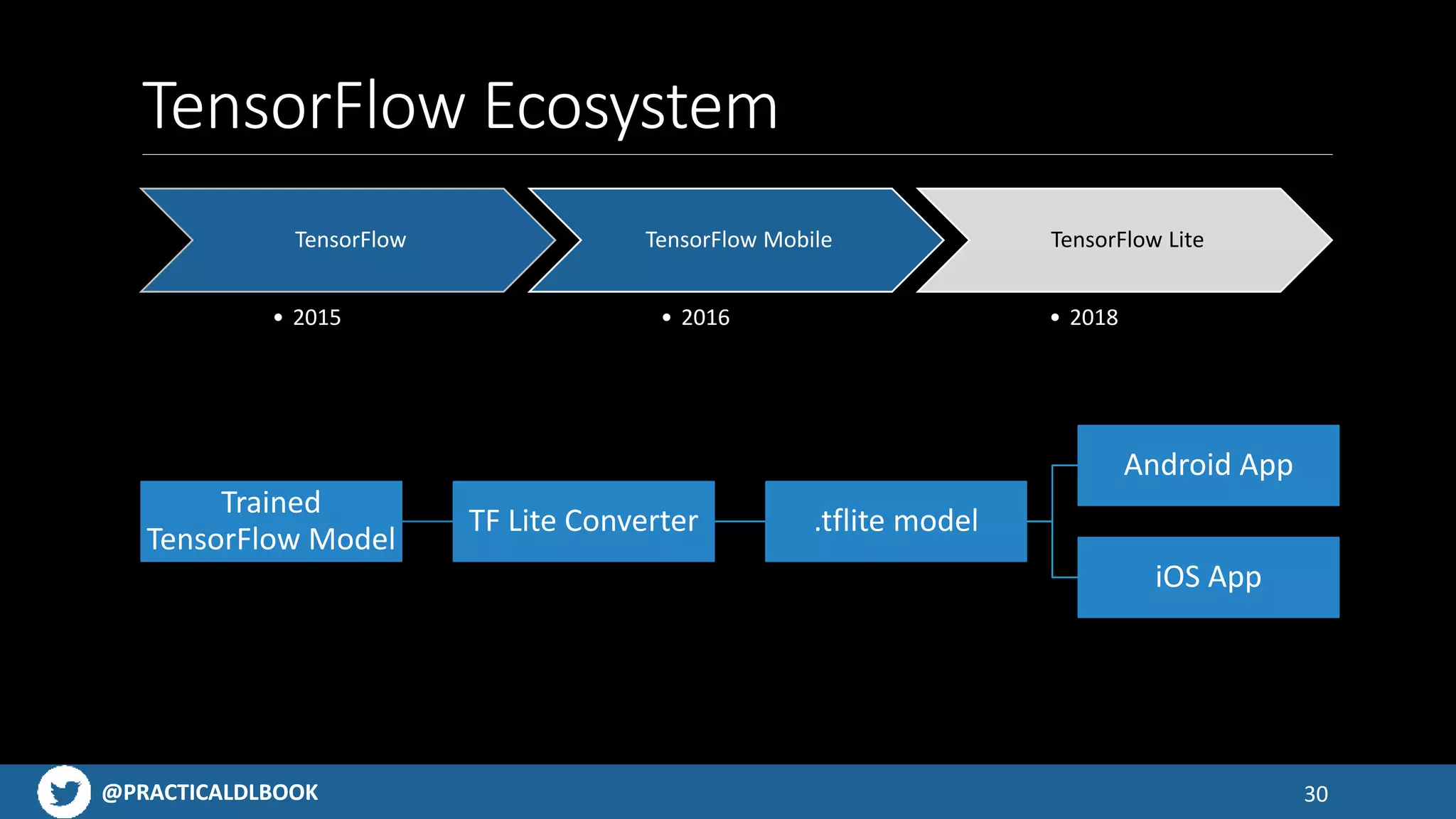
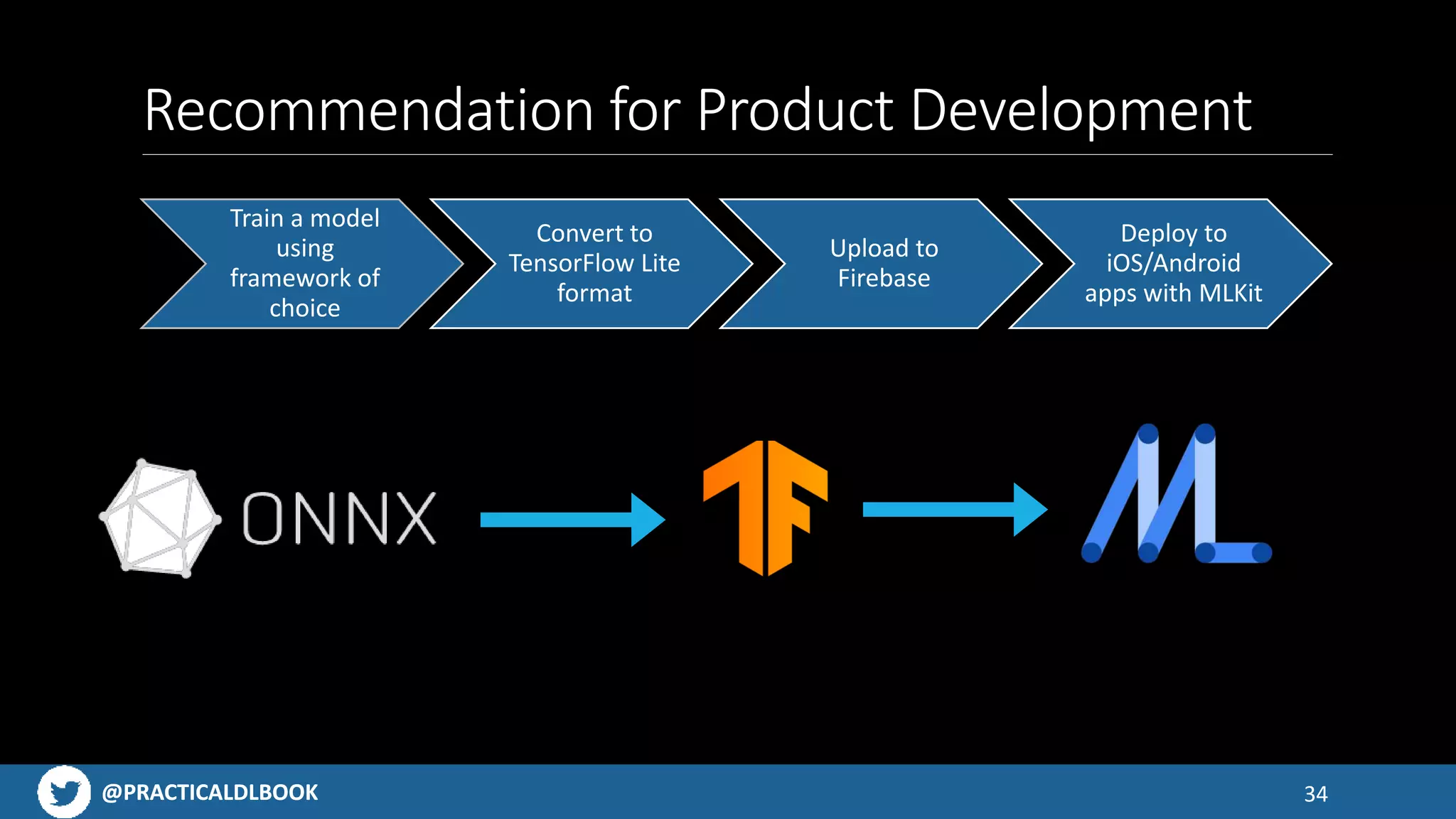
An overview of the TensorFlow ecosystem, highlighting tools like TensorFlow Lite and model conversion processes.
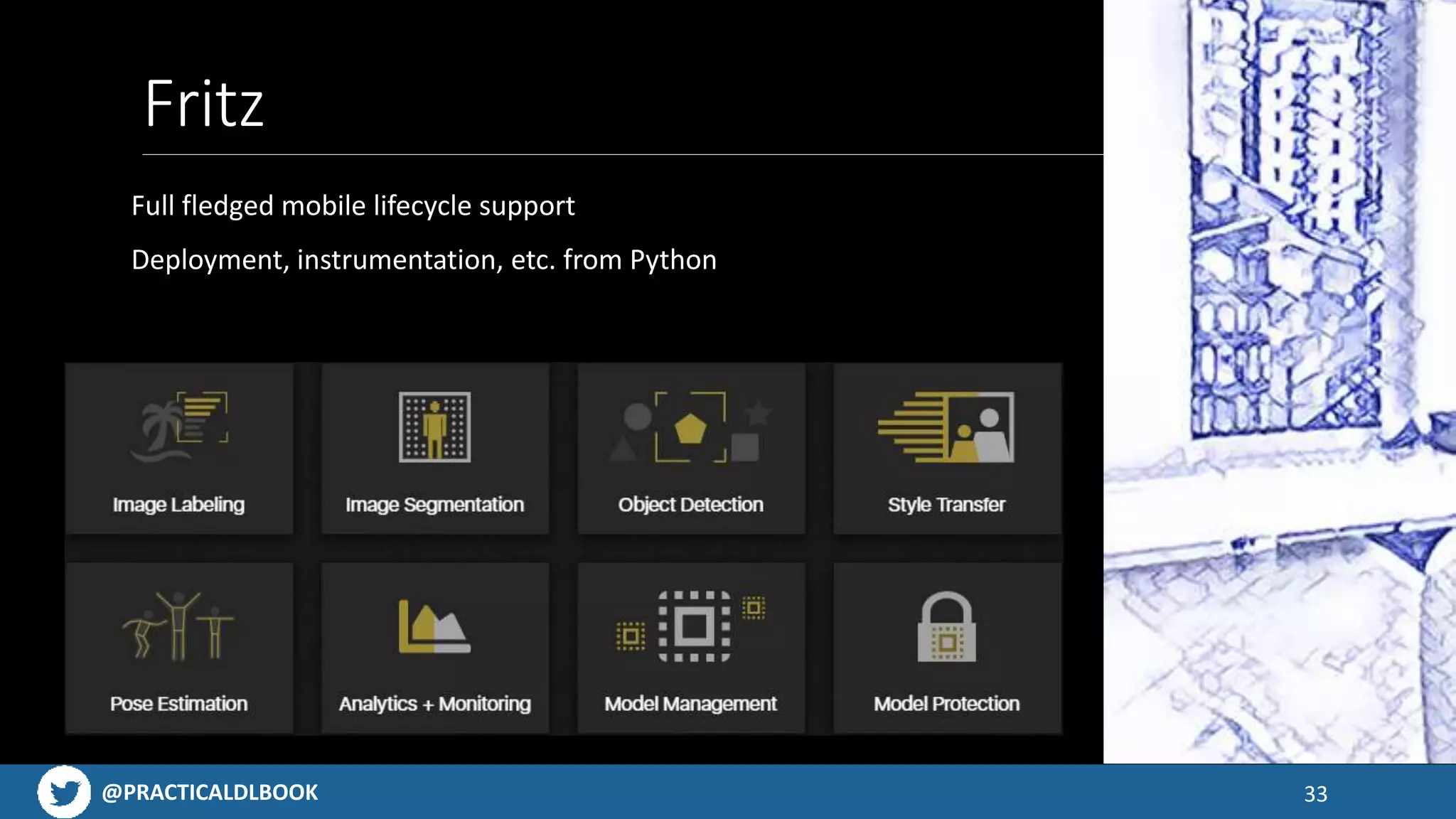
Introduces ML Kit for image processing and model management, emphasizing integration into mobile apps.
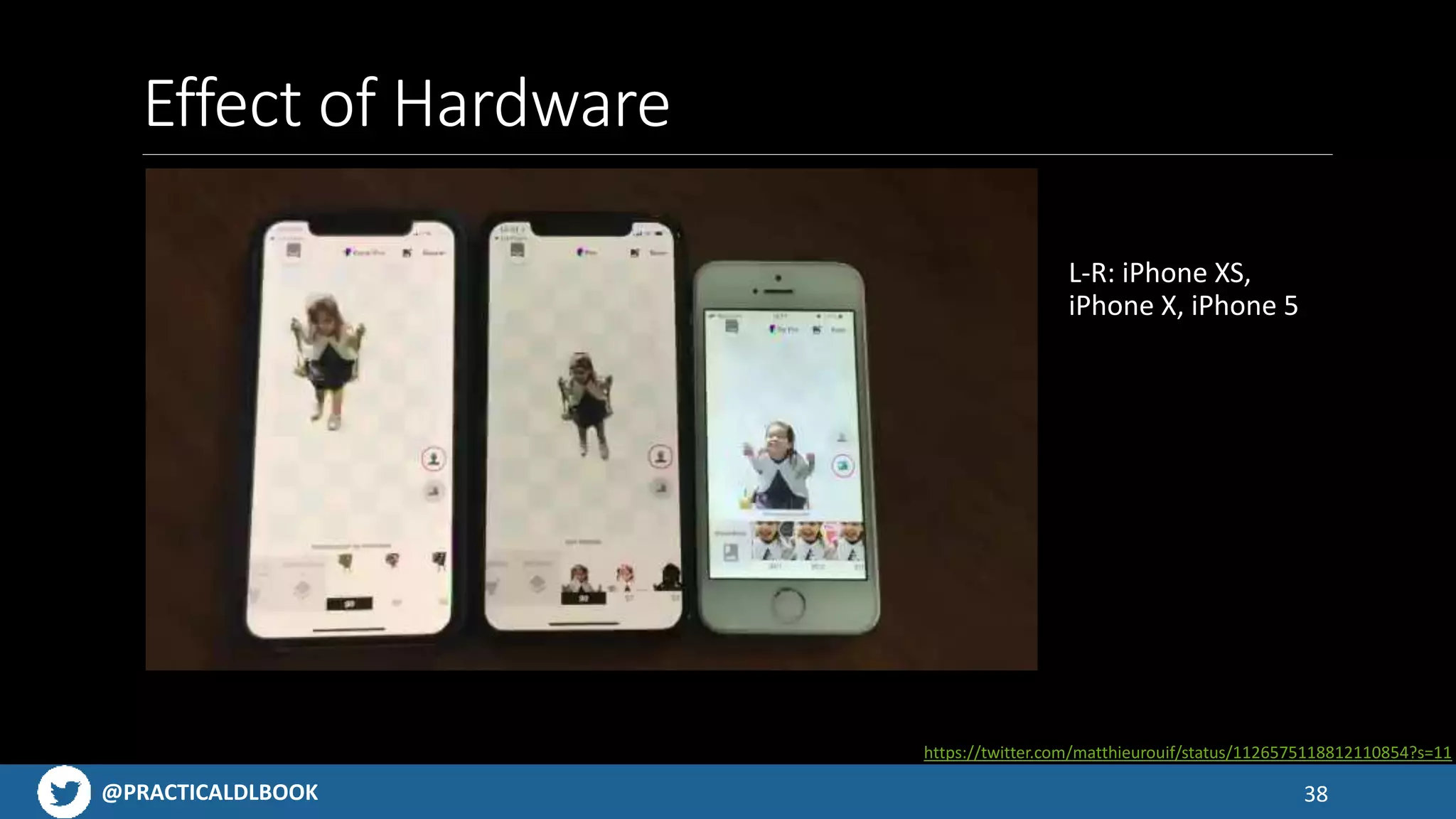
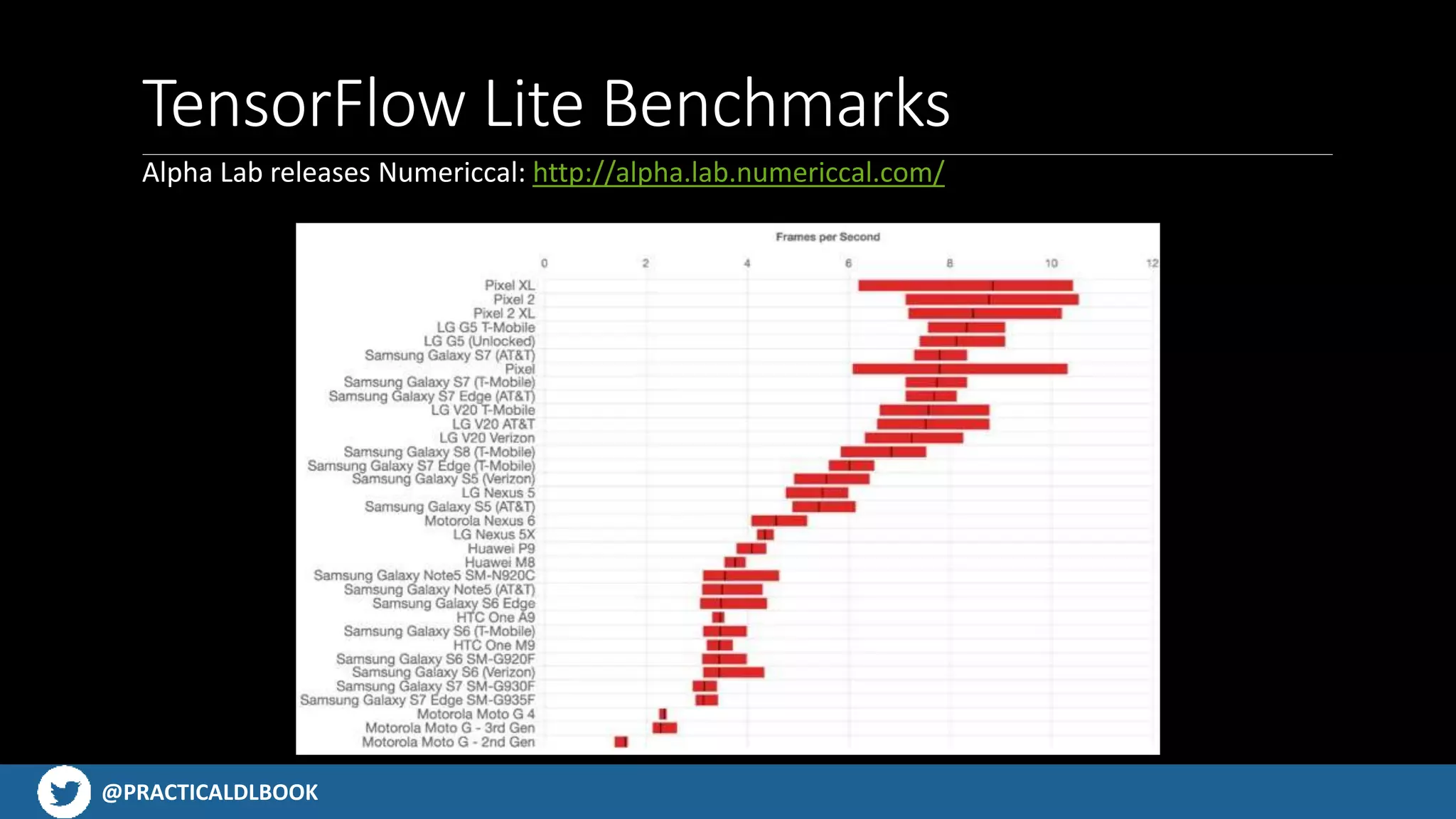
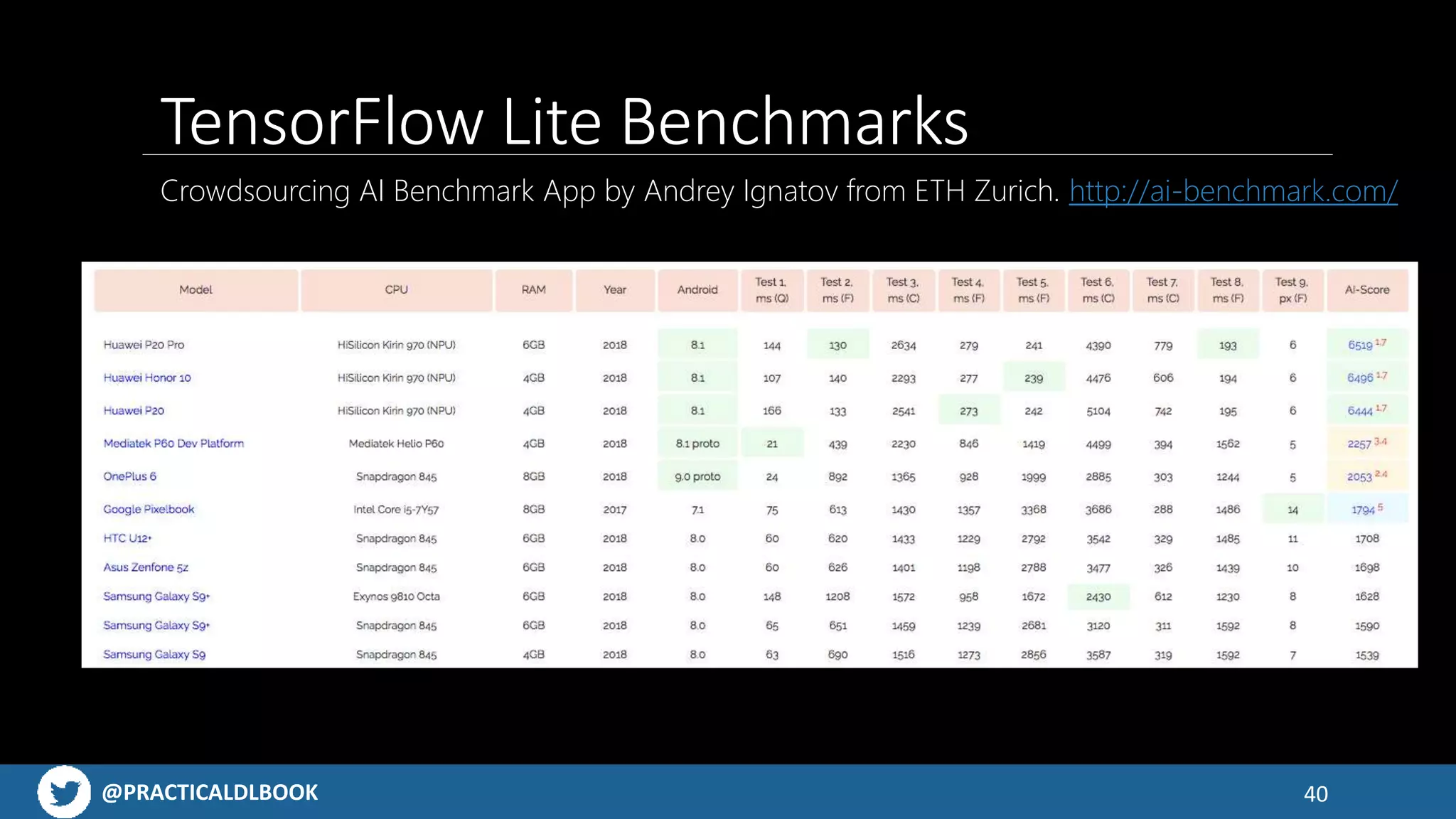
Discusses challenges with app size limitations, hardware effects on performance, and benchmarks for TensorFlow Lite.
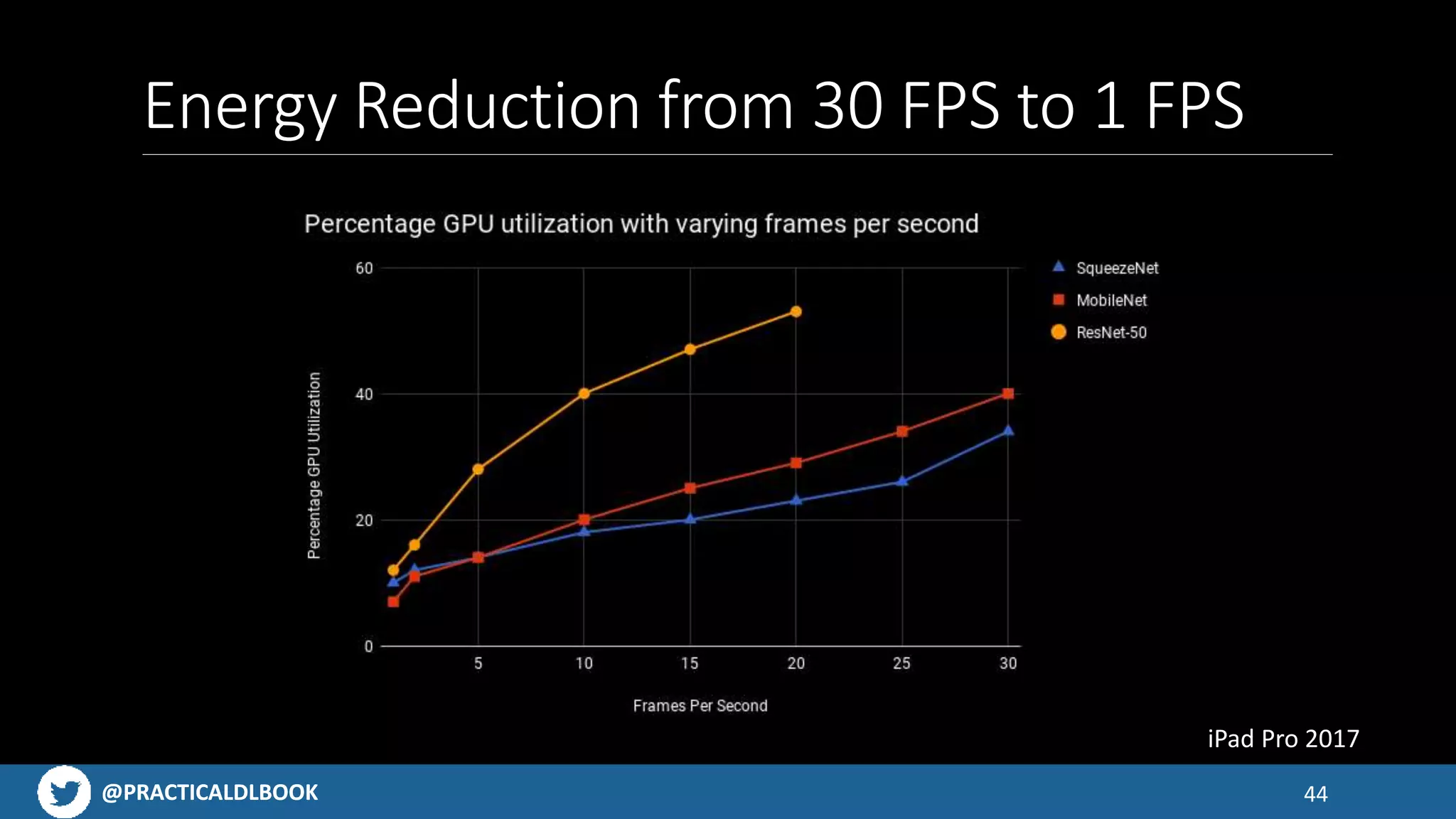
Advice on ensuring broad device support for user coverage and battery management during AI inference.
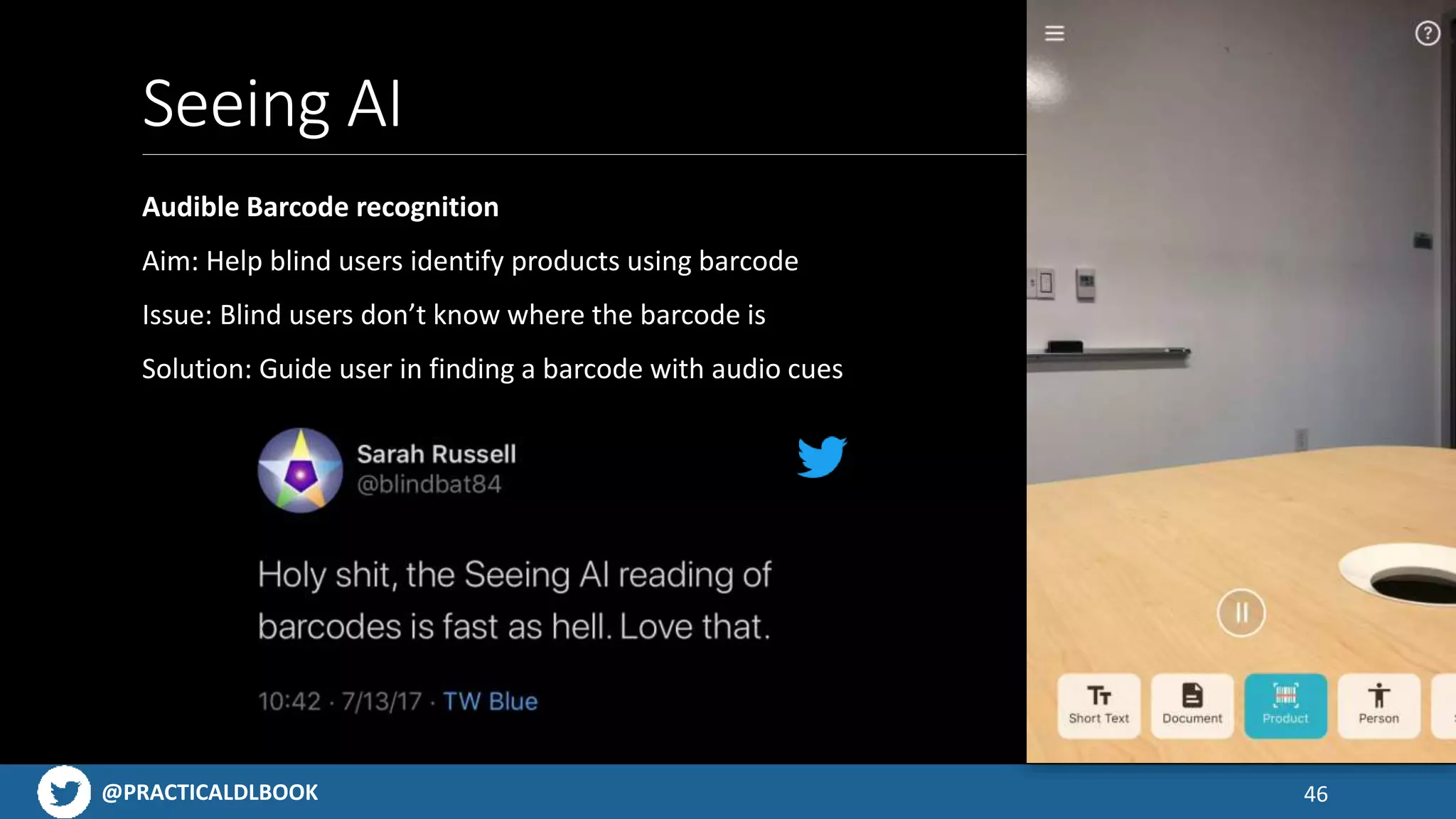
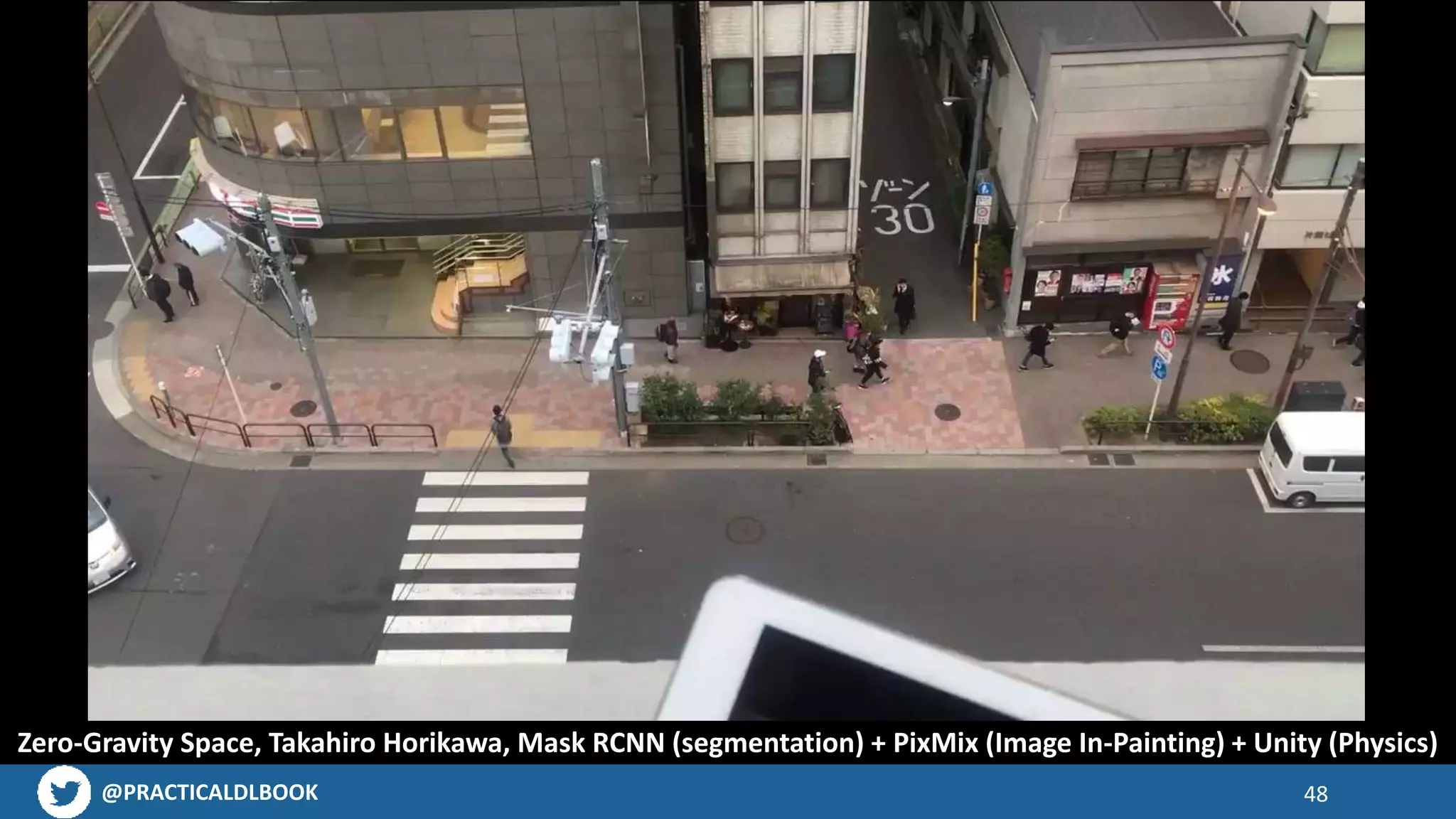
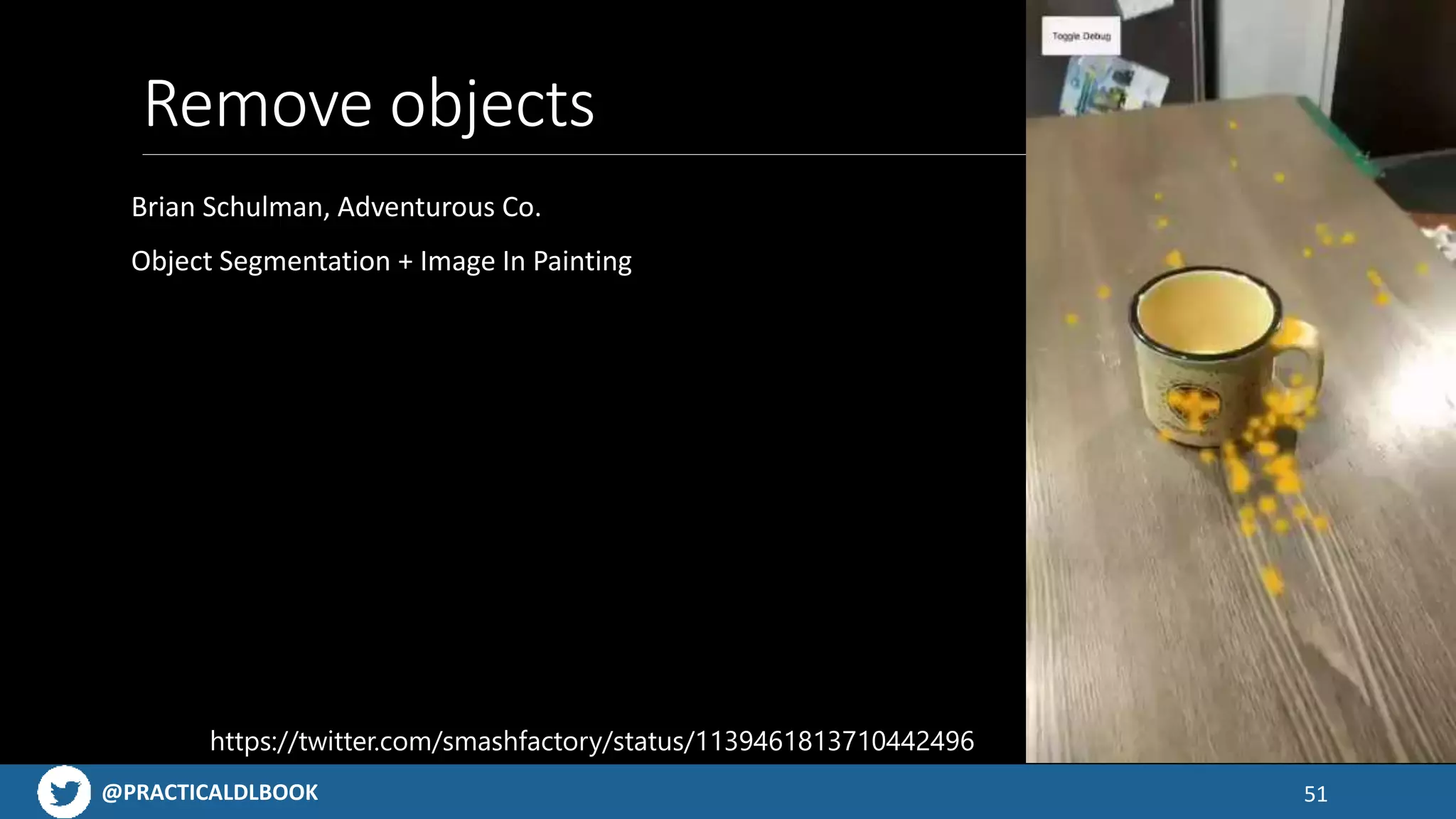
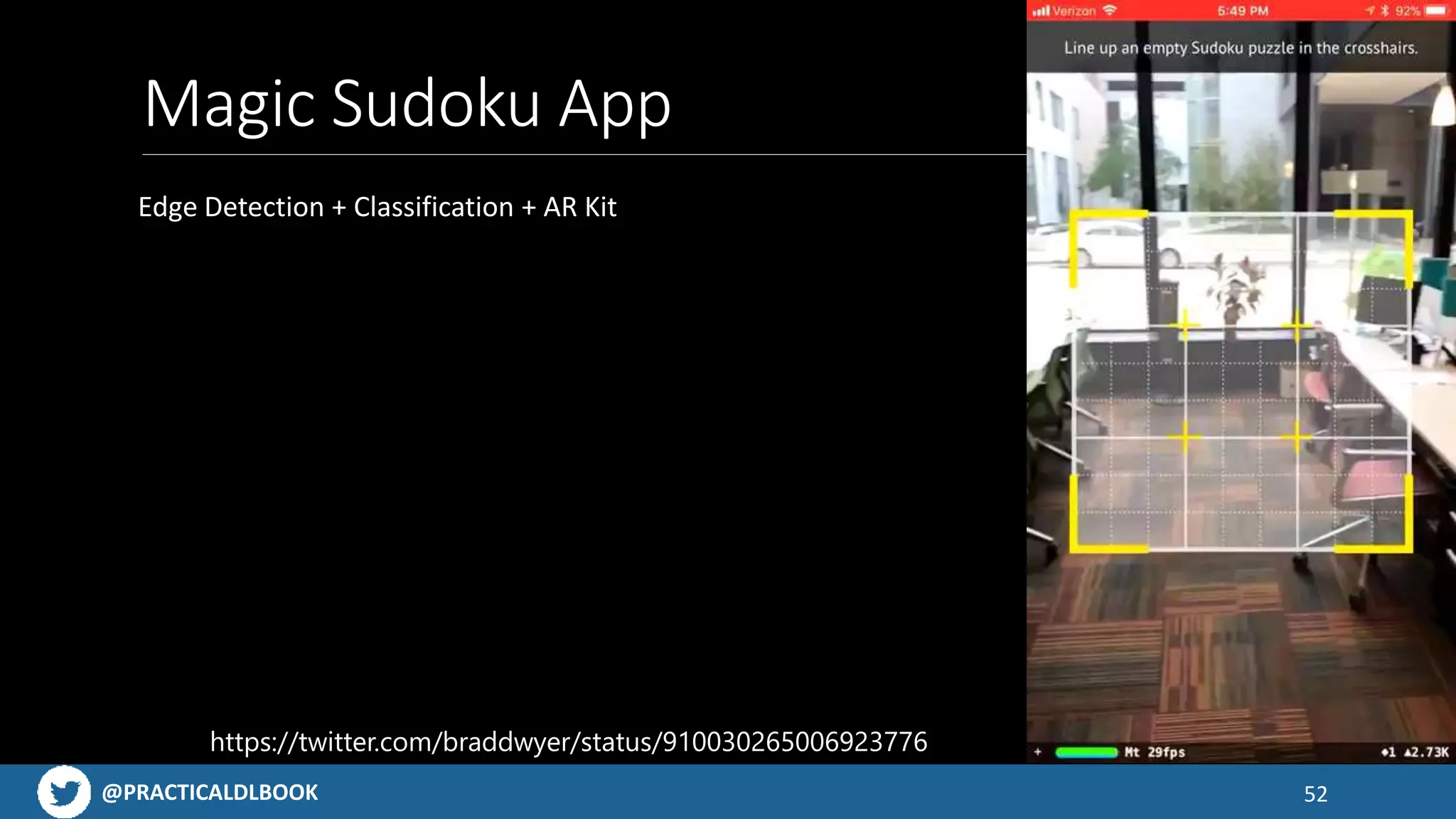
Examples of engaging mobile applications built using AI technologies, from object detection to AR possibilities.
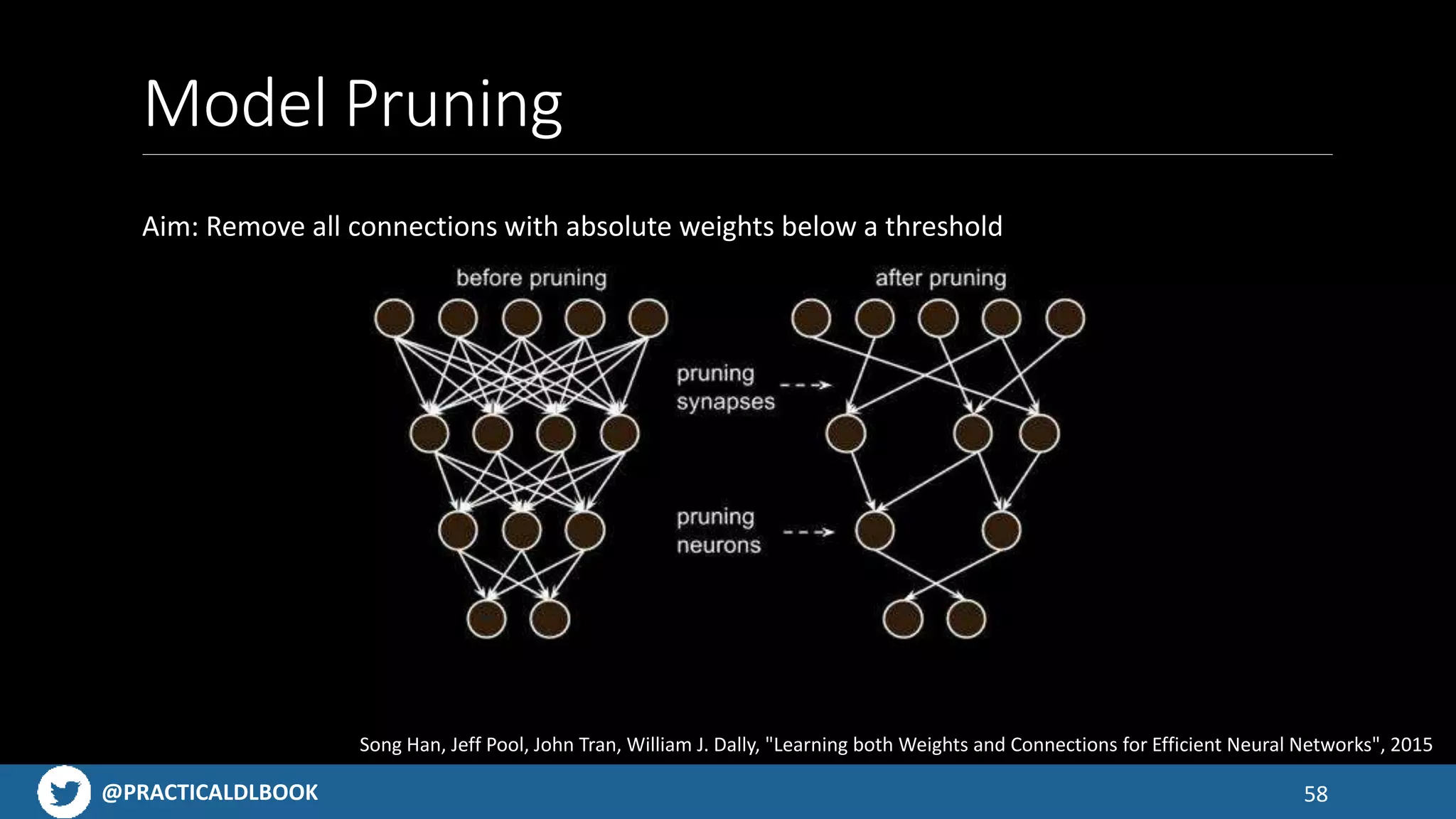
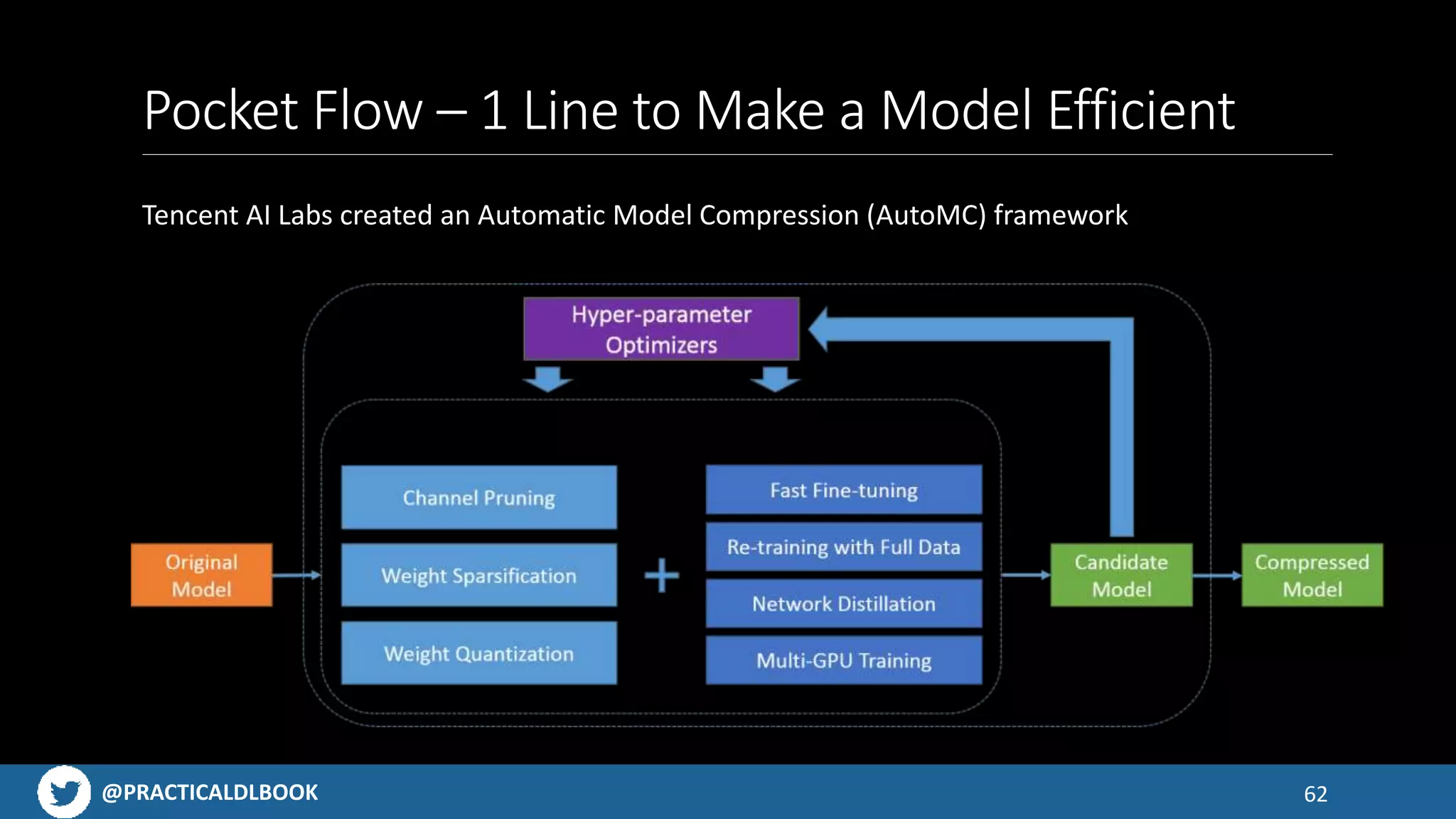
Solutions for improving model efficiency through various techniques like pruning, quantization, and architecture optimization.
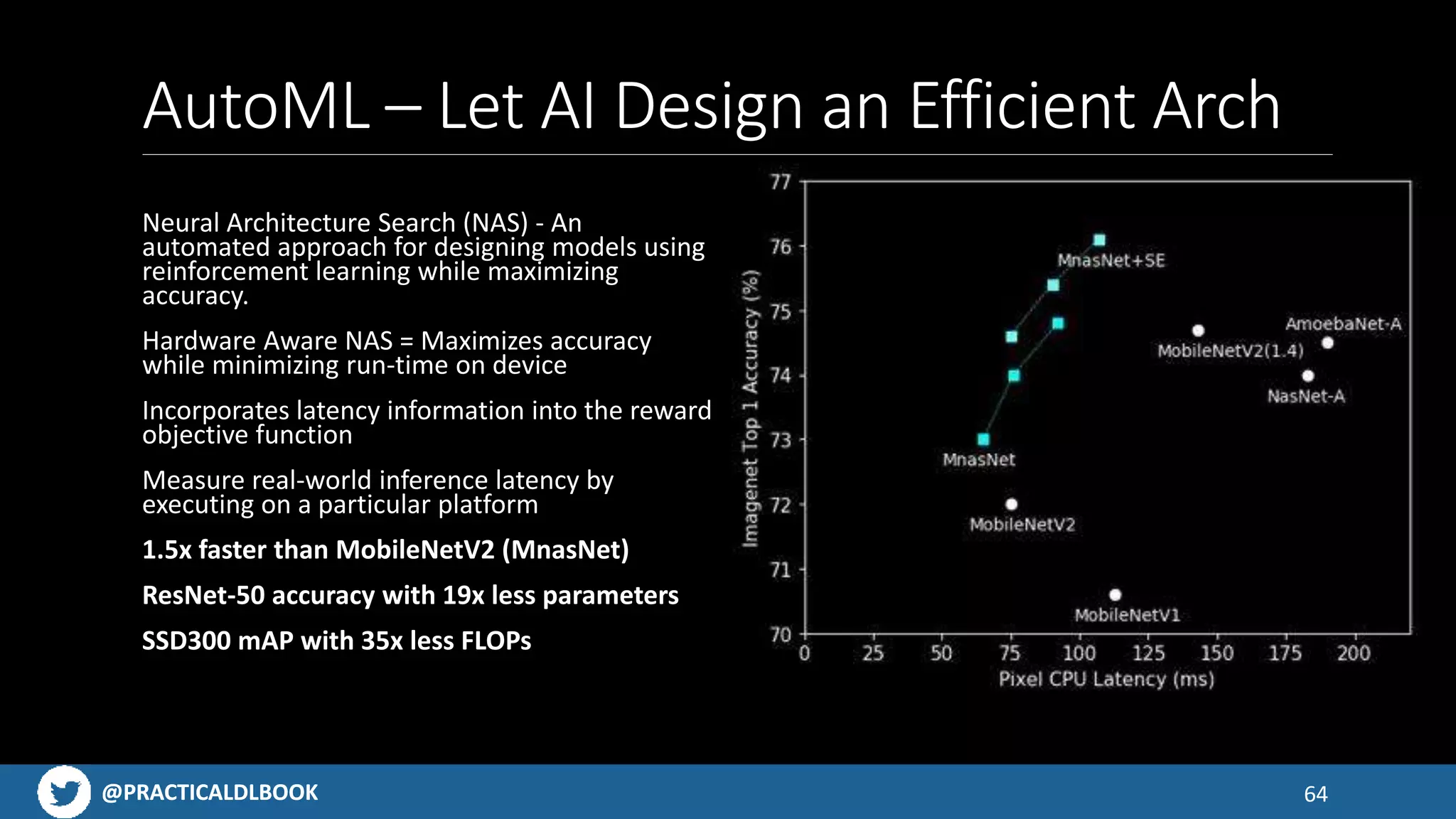
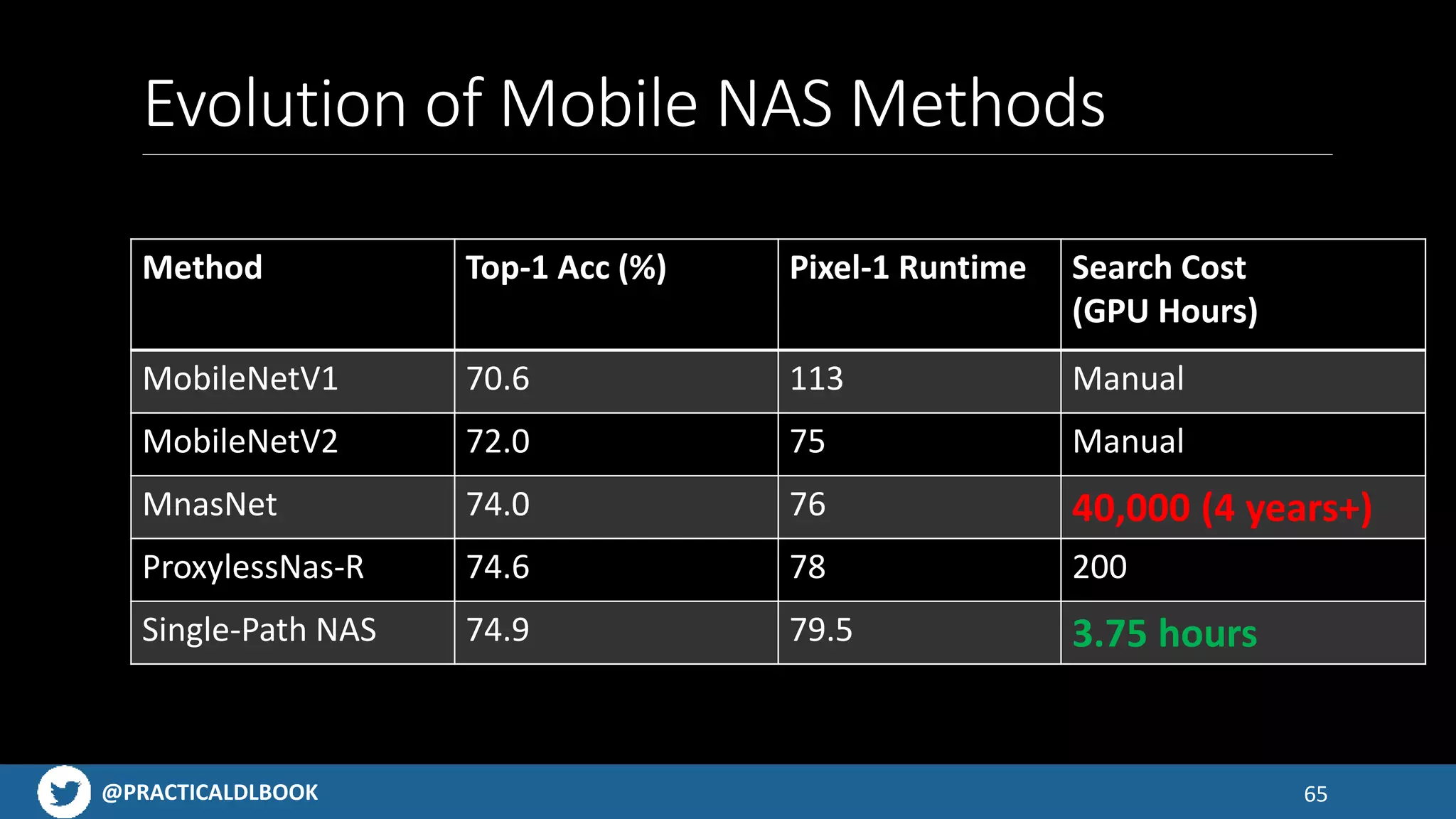
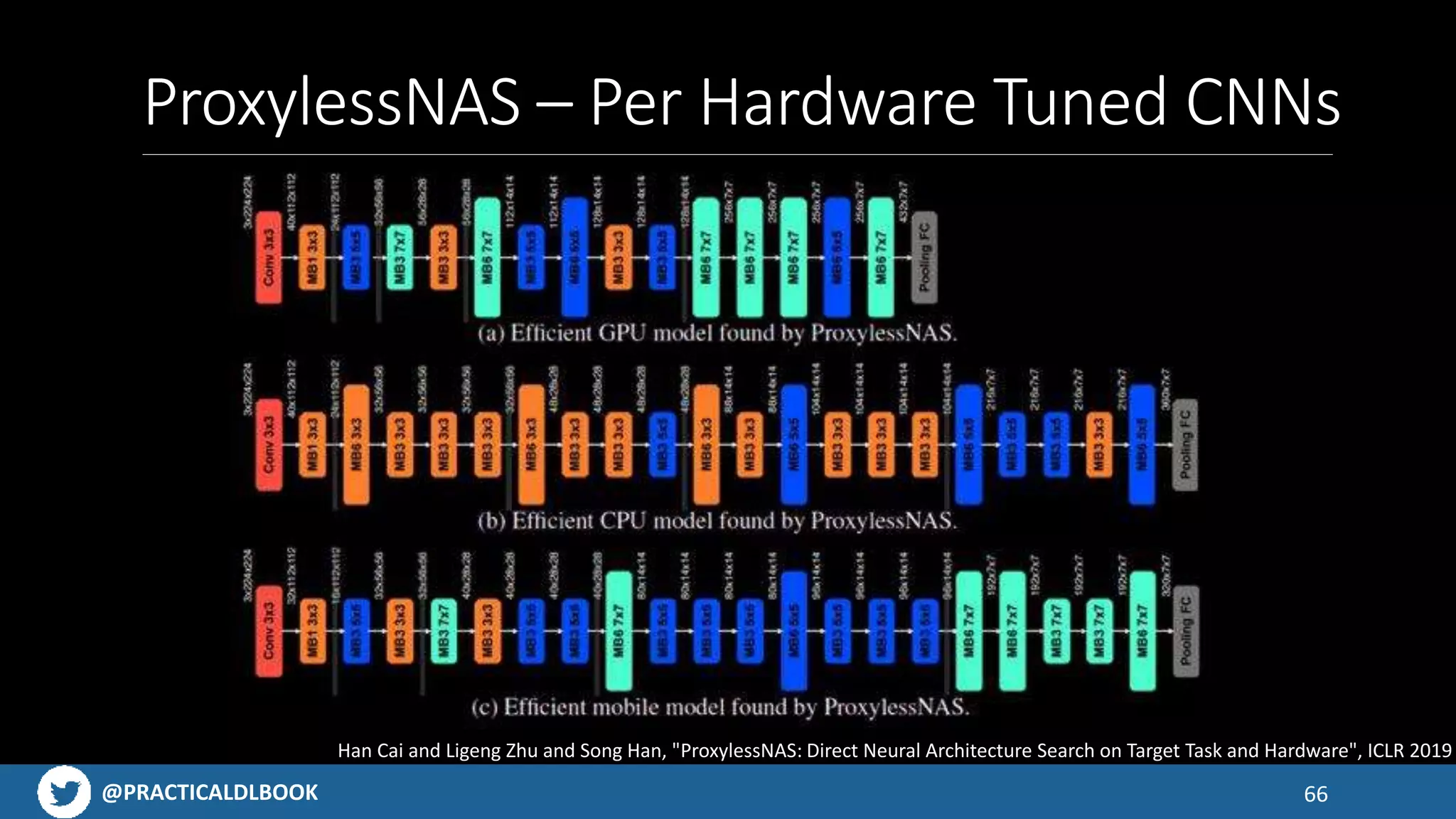
Explains AutoML concepts and the efficiency gains from Neural Architecture Search methods.
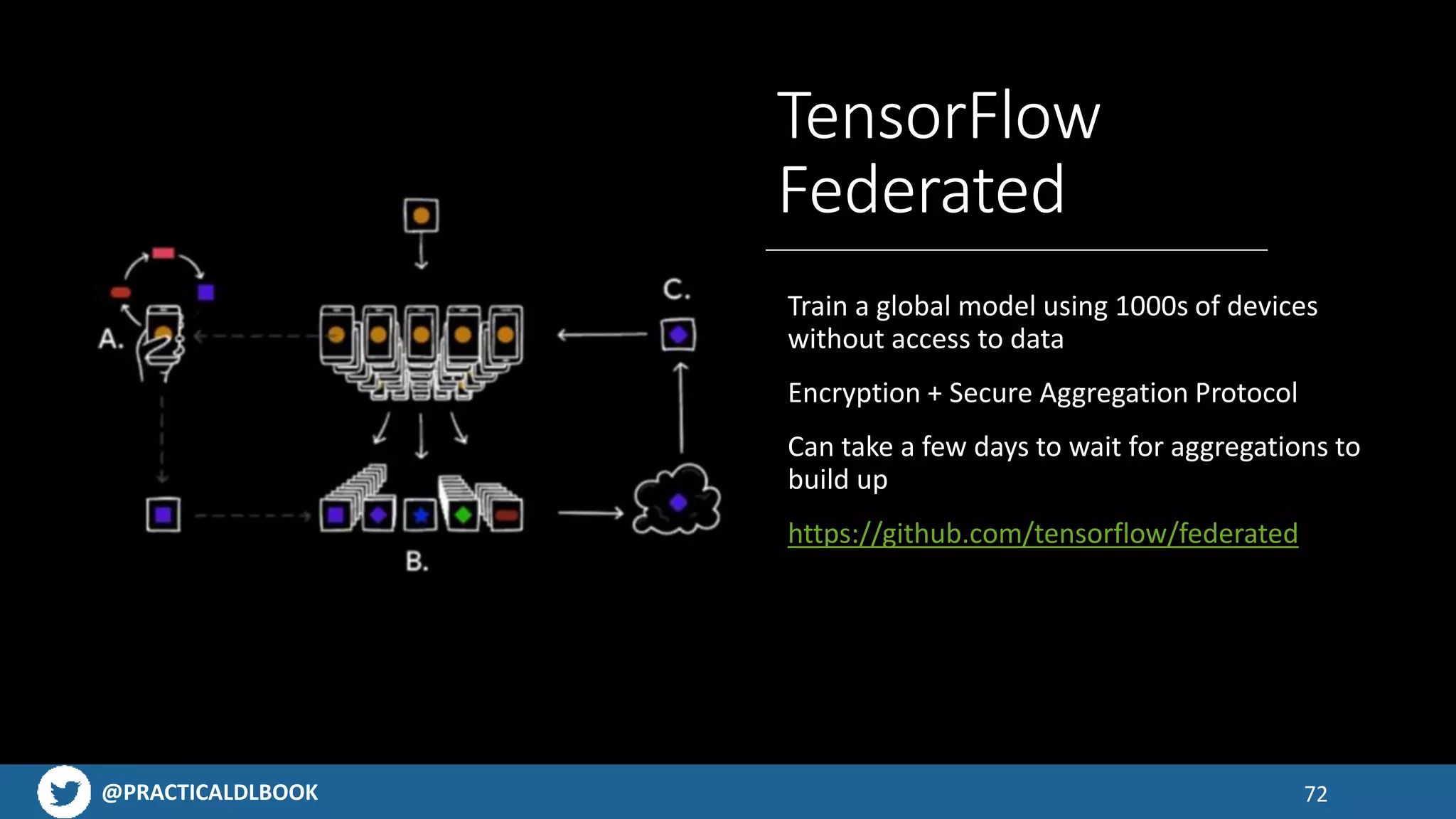
How to train models directly on mobile devices, including federated learning techniques to protect user data.
Summary of key points discussed, emphasizing the importance of mobile deep learning, with access to additional resources.



































































