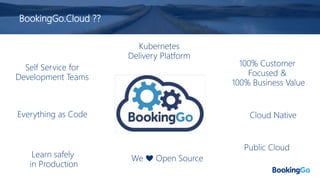
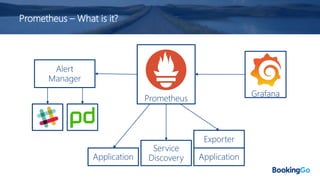
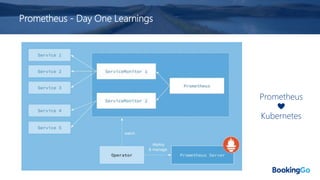
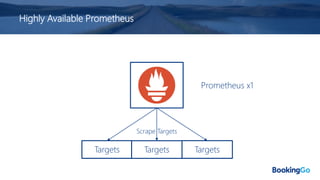
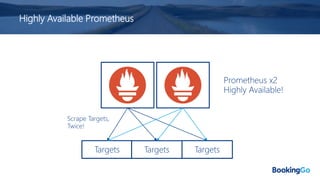
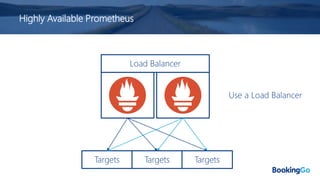
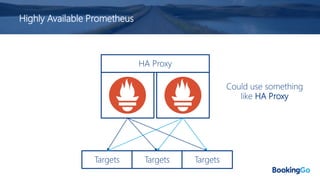
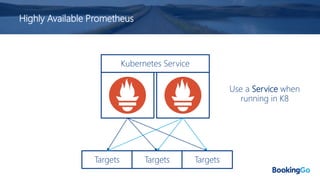
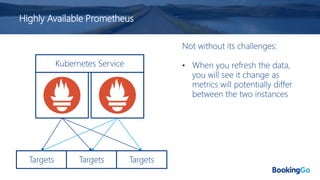
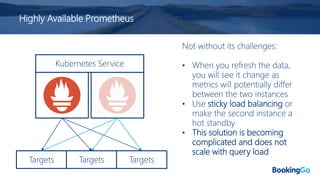
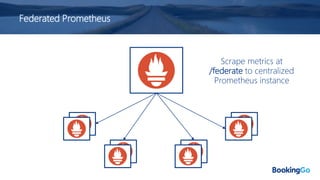
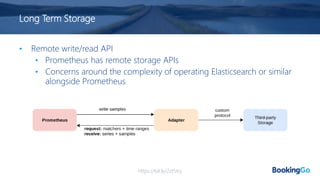
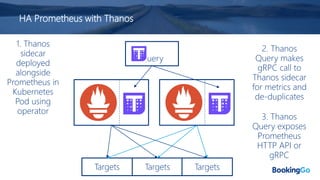
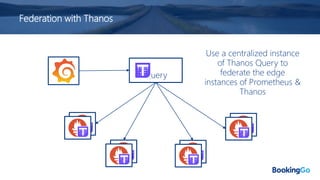
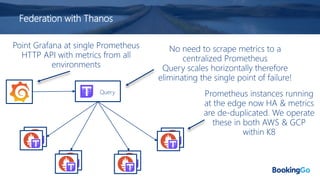
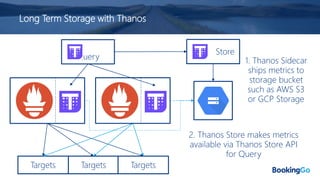
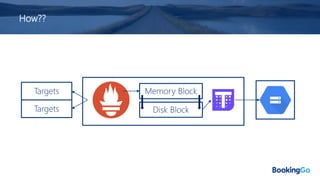
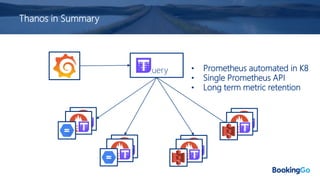
The document discusses the implementation and scaling of Prometheus on Kubernetes at Booking.com, detailing the past, present, and future of observability efforts. It outlines the goals for time-series metrics, challenges faced with running high availability Prometheus, and how Thanos is proposed as a solution for long-term storage and centralized metric querying. The overall focus is on creating a robust observability culture and self-serve metrics management within the development lifecycle.