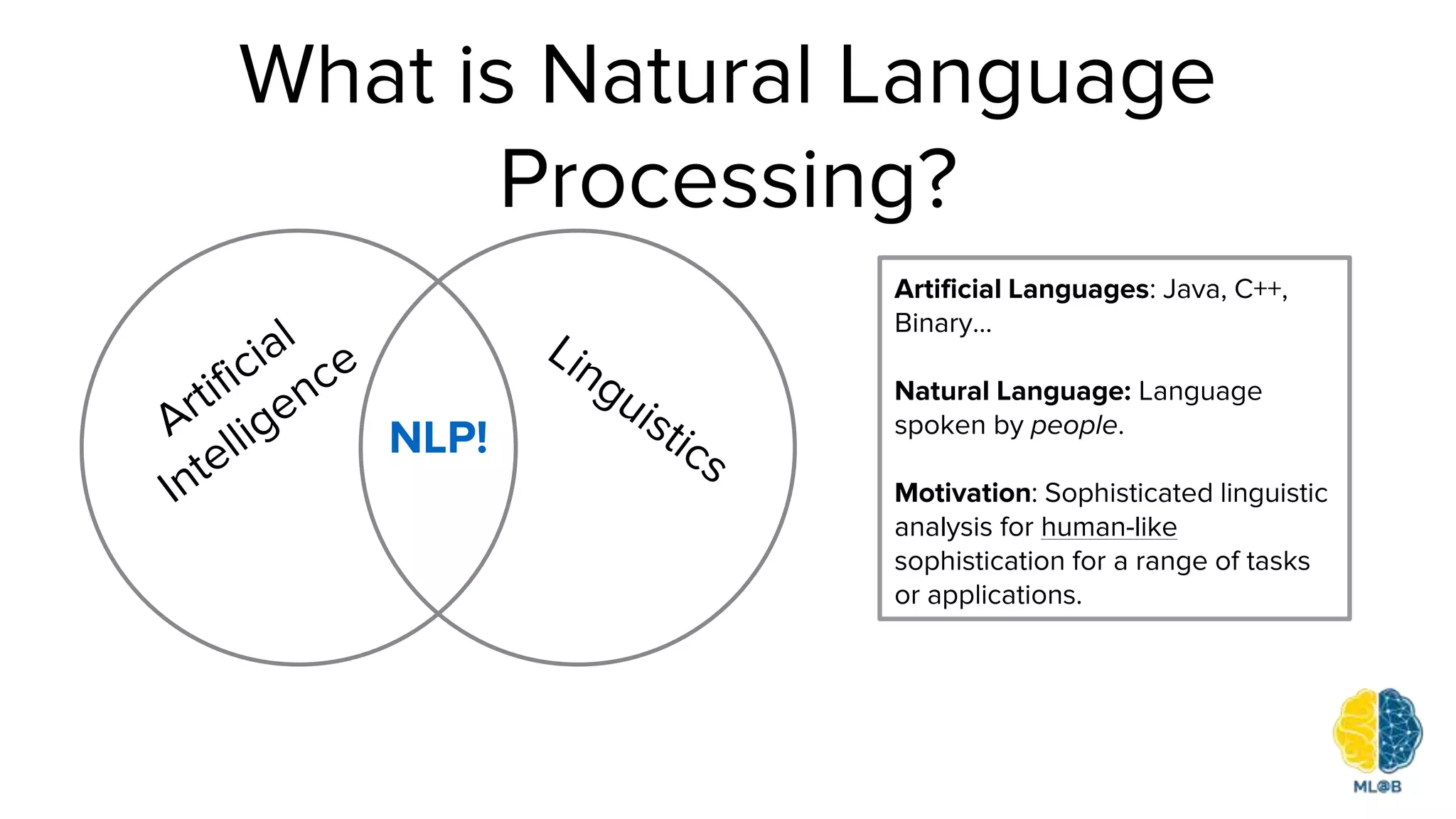
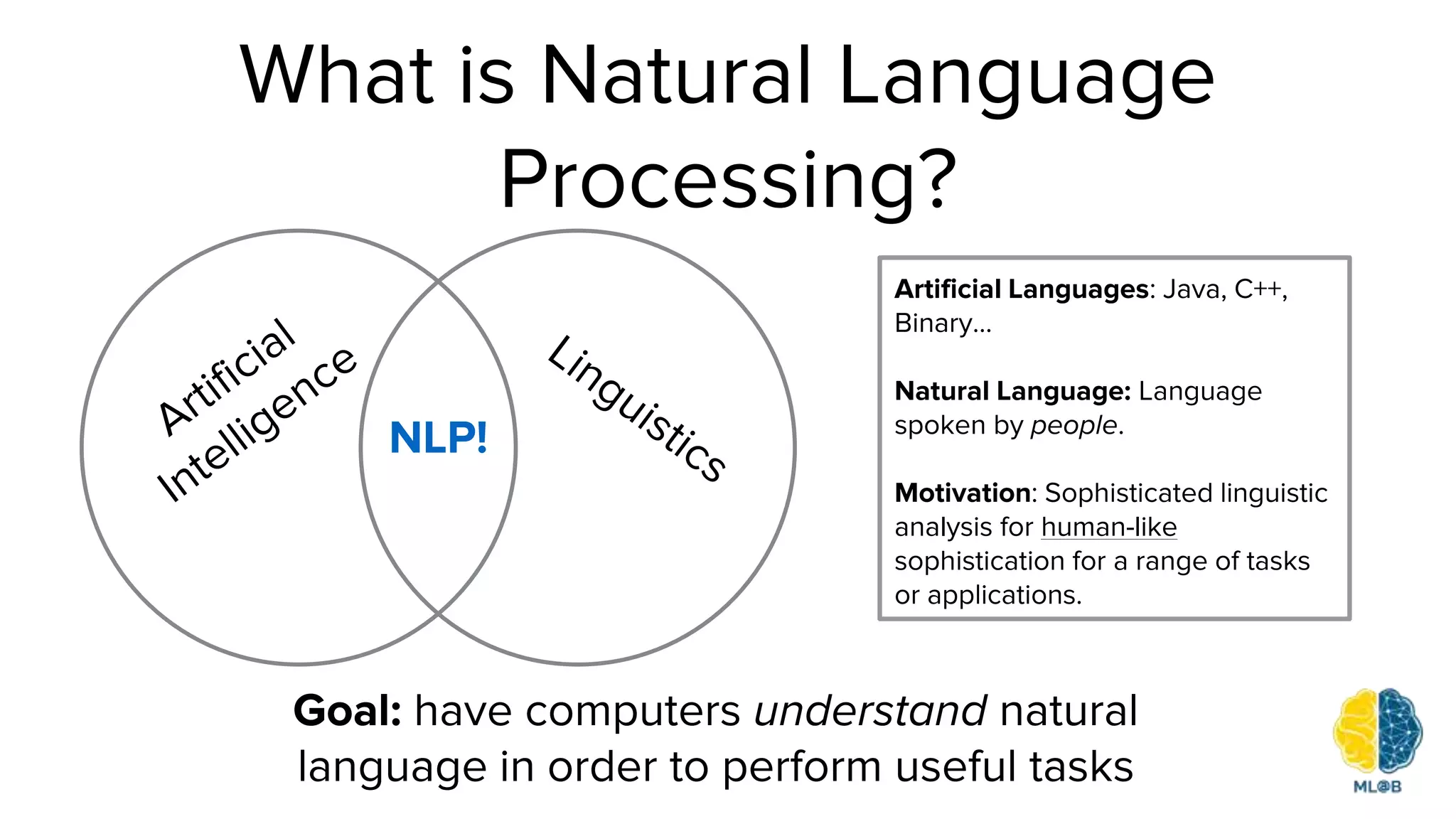
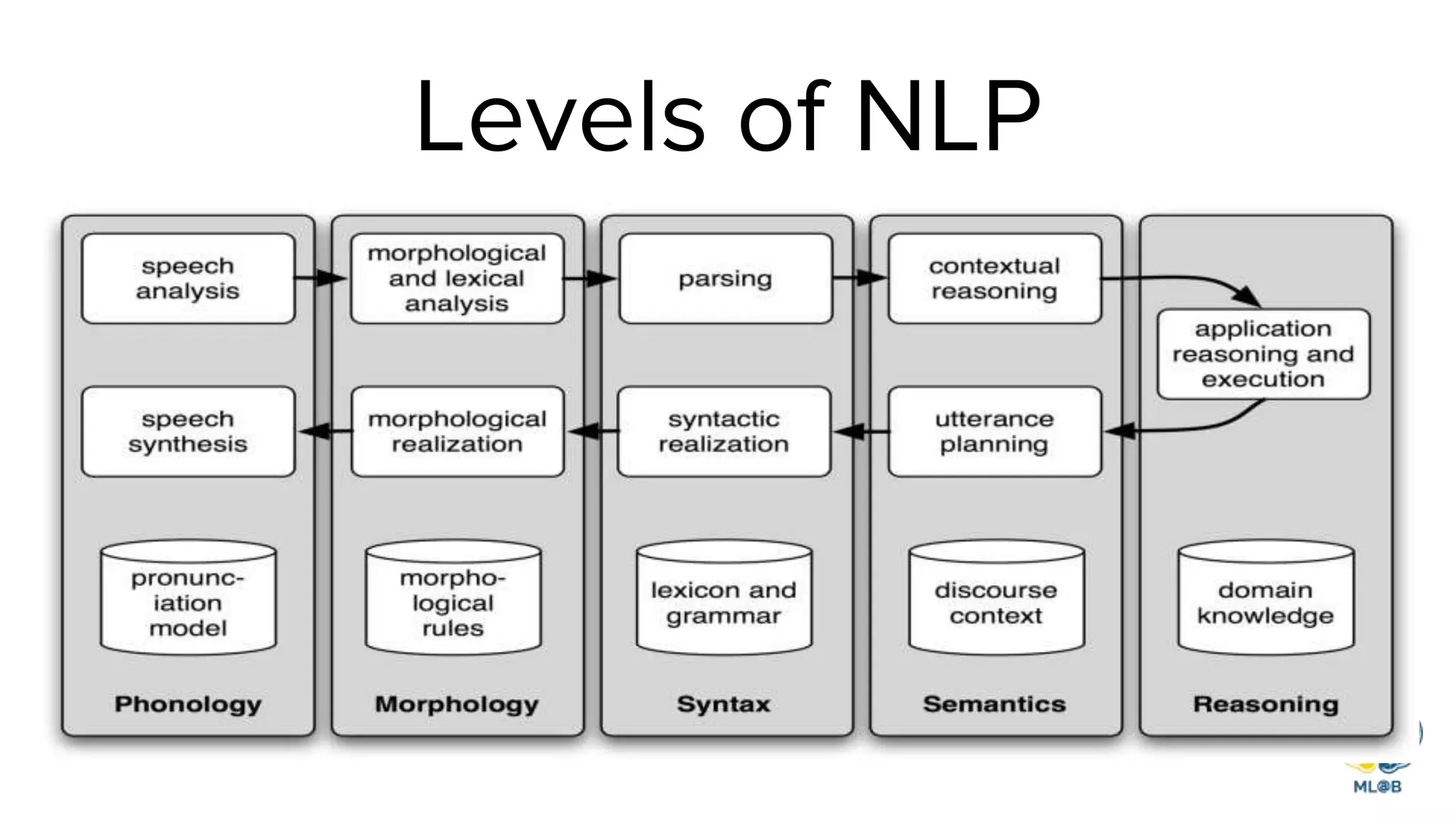
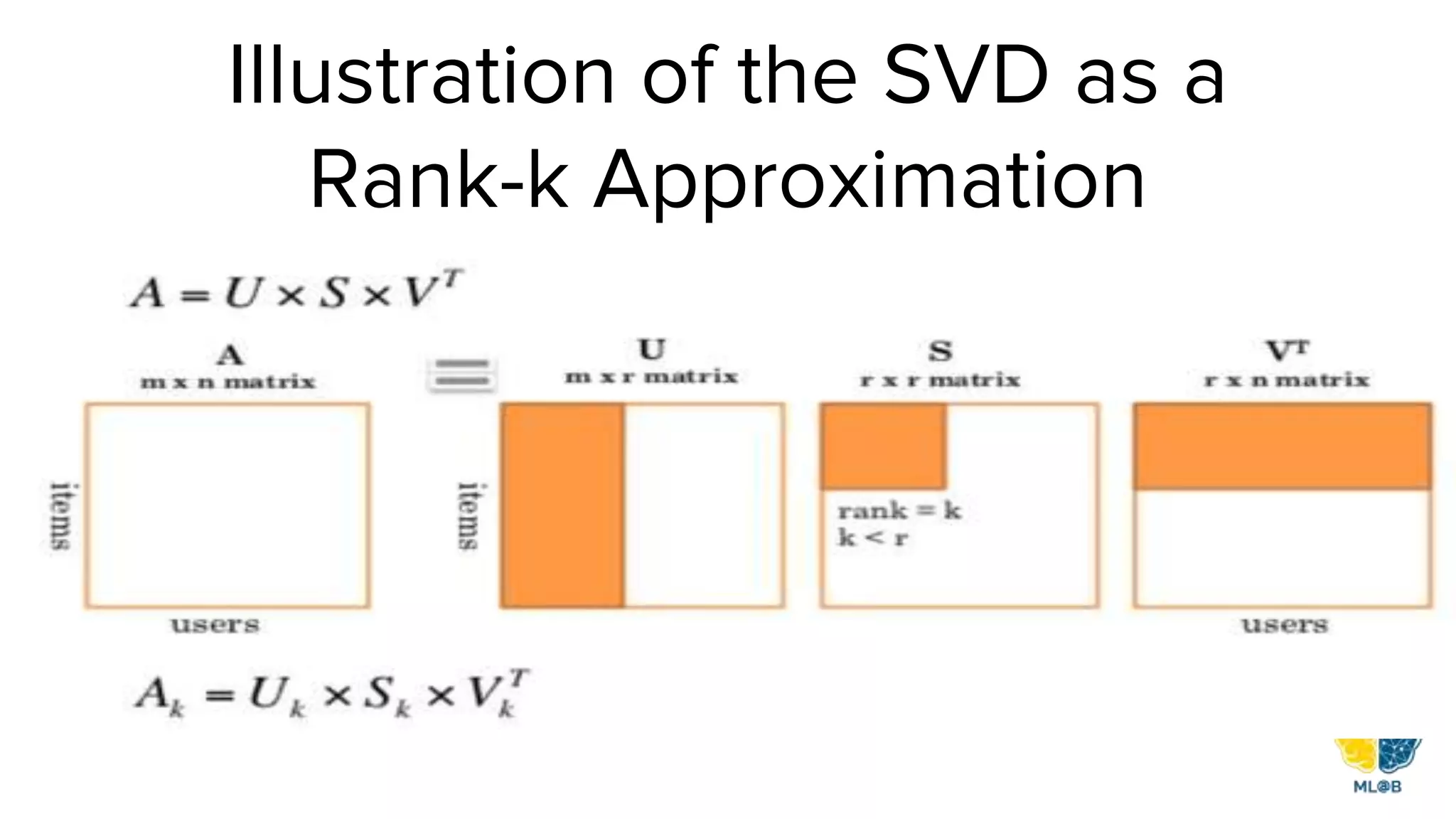
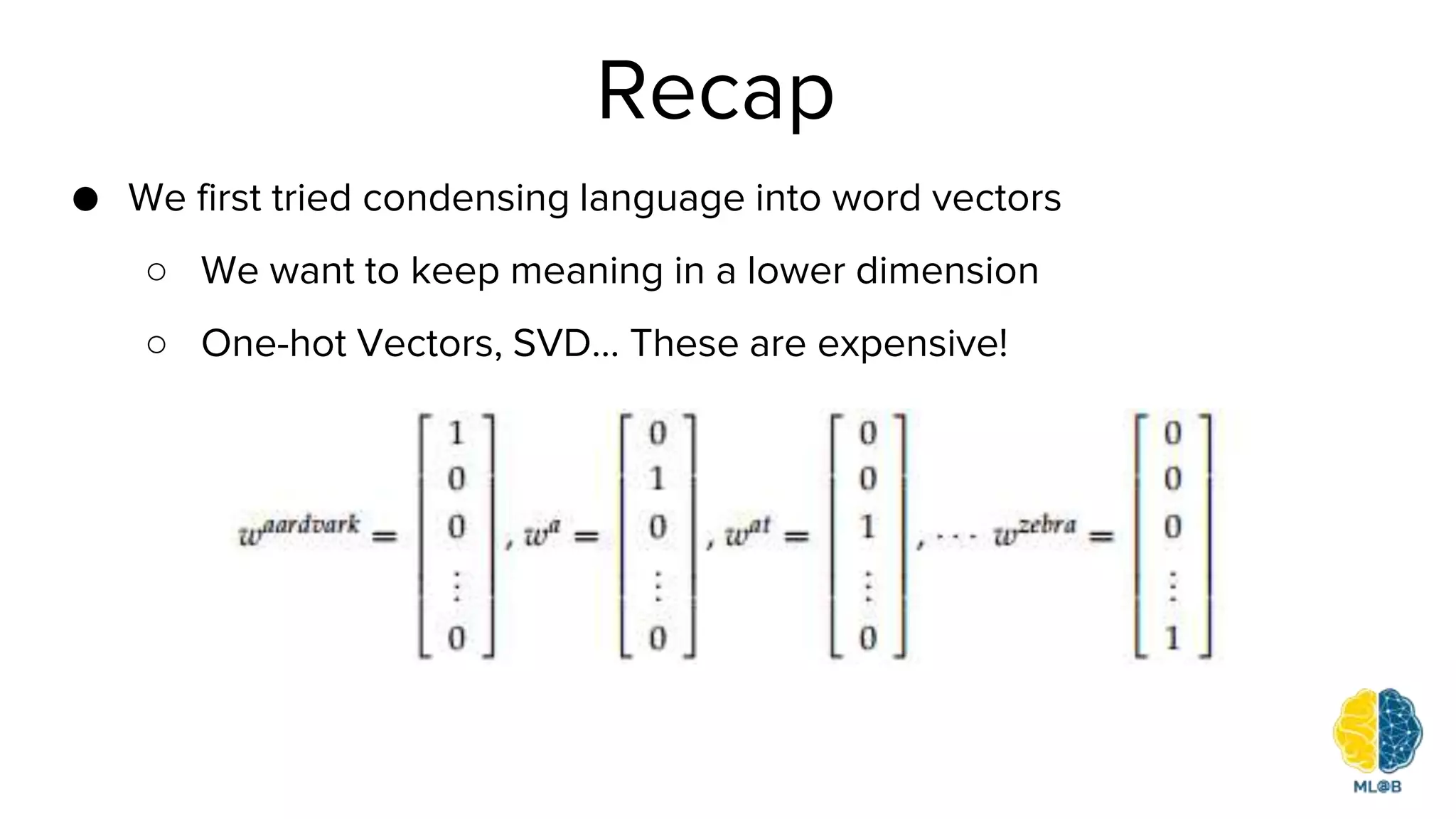
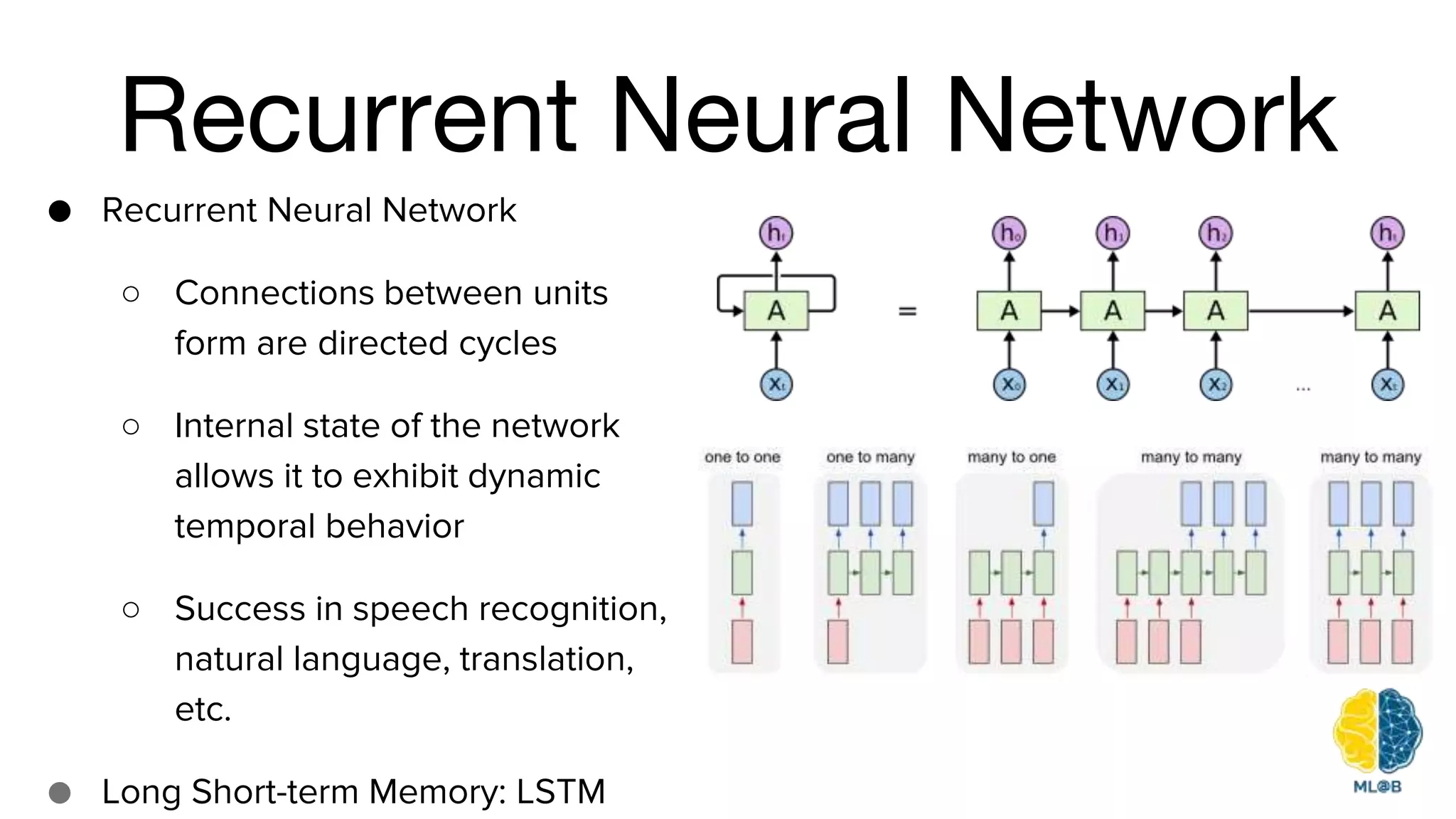
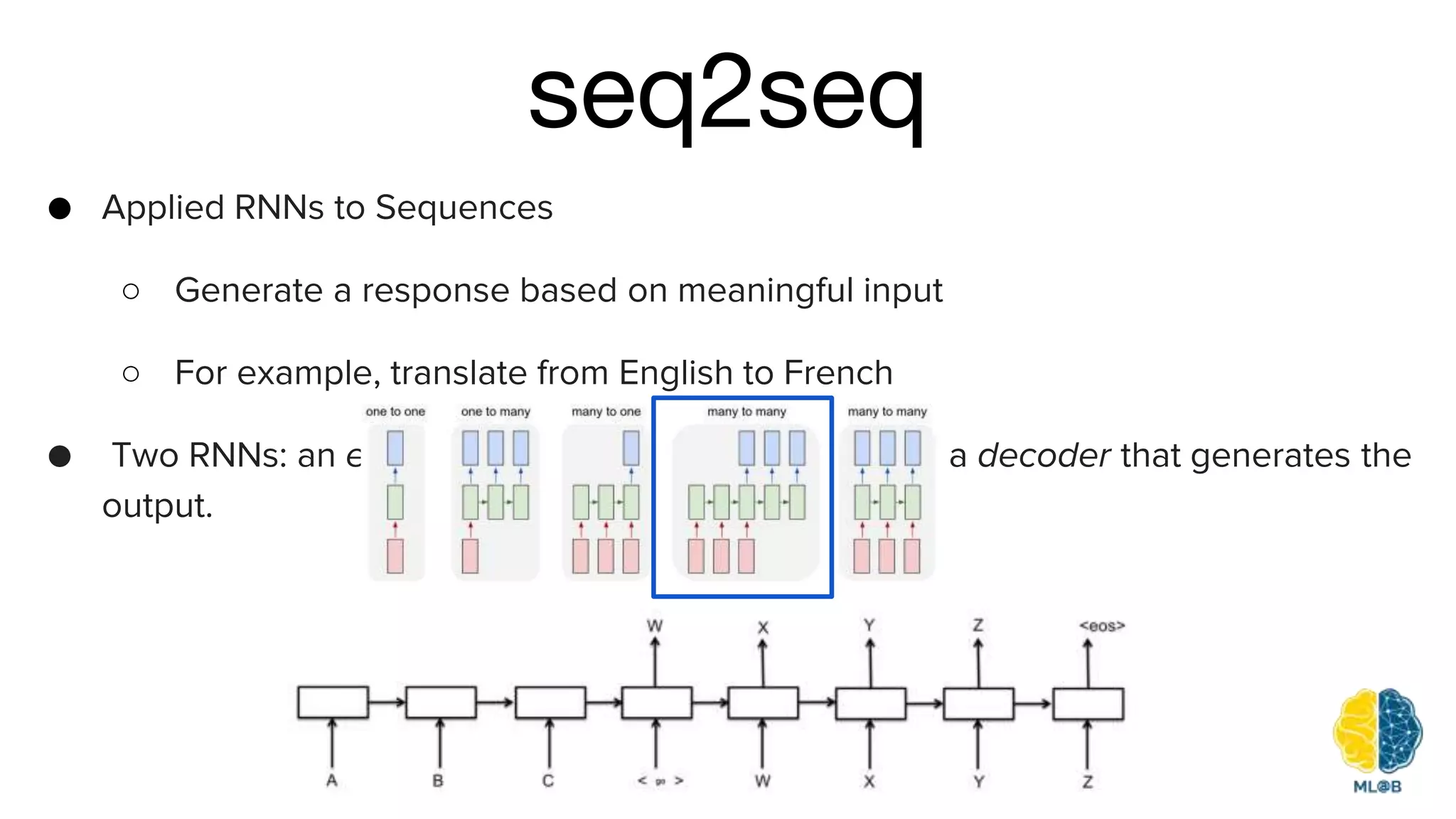
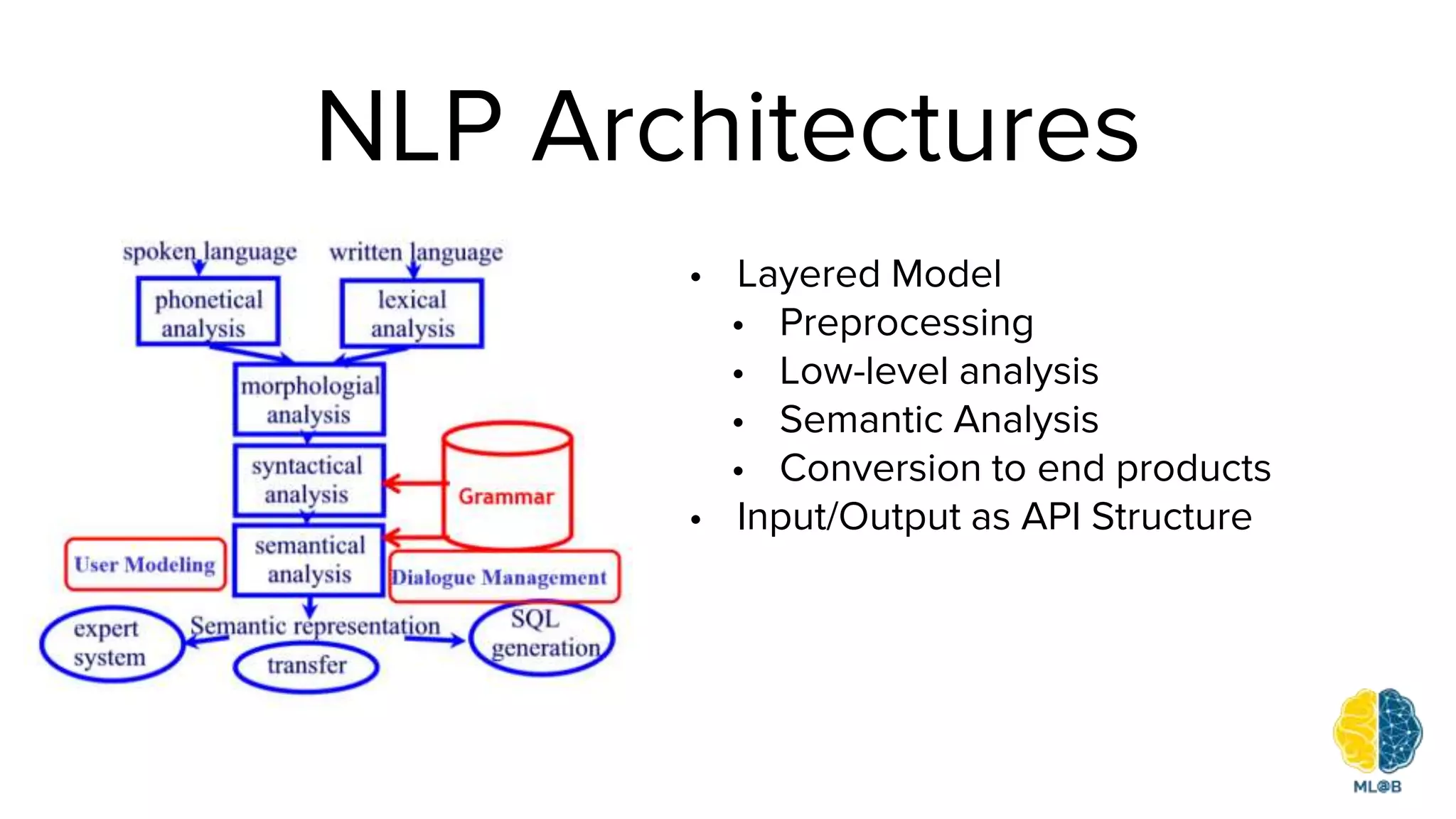
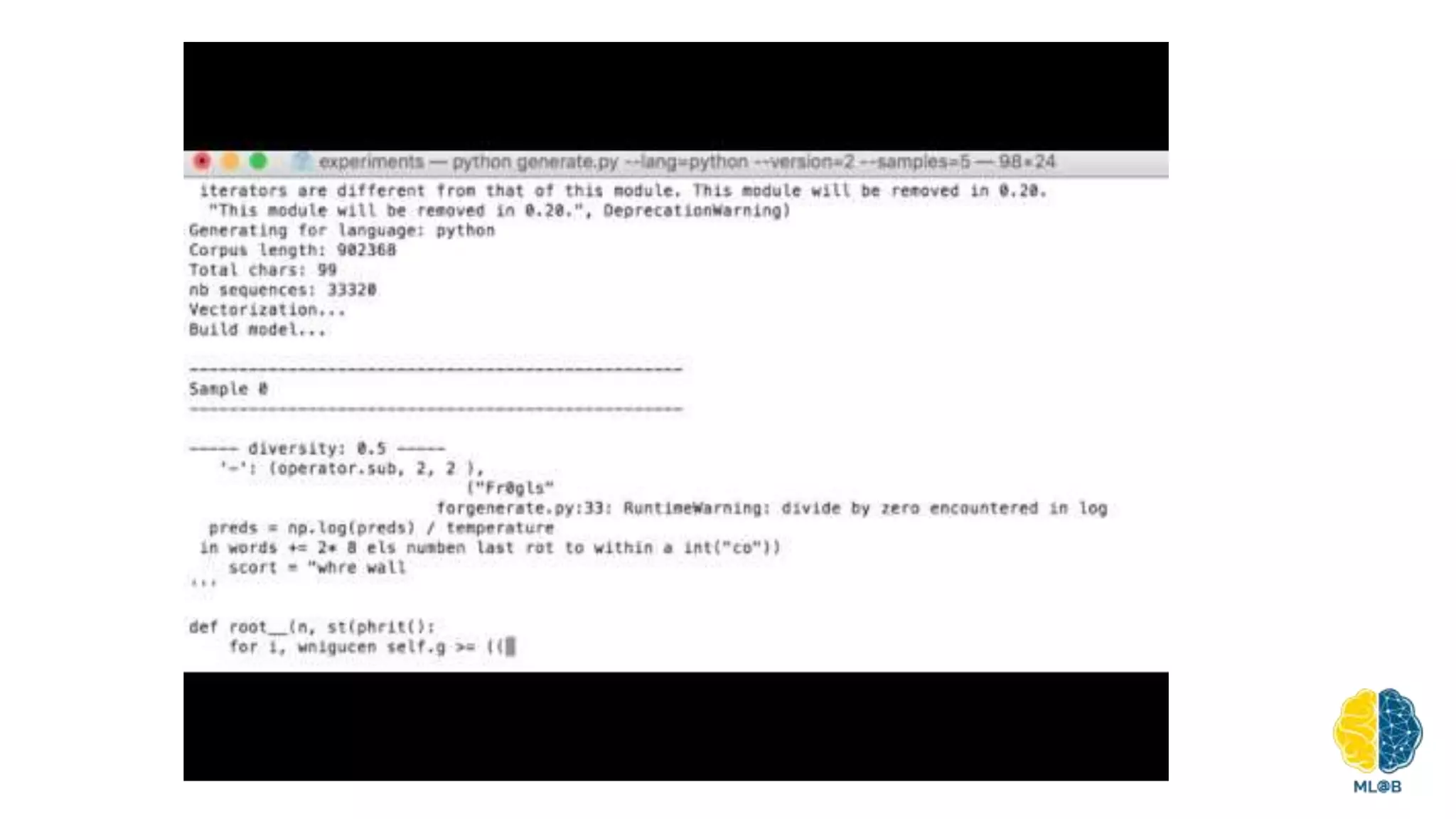
The document provides a comprehensive overview of natural language processing (NLP), including its background, task types, challenges, and advancements such as machine translation and conversation agents. It discusses various techniques for word representation, including one-hot vectors, singular value decomposition, and modern deep learning methods like word2vec. The future of NLP is highlighted with emphasis on improved user interaction, analyzing unstructured information, and the increasing role of AI in industry applications.


















































































































































![[DSC Europe 25] Velibor Ilic - Autonomous Driving - How AI Shapes Technical ...](https://cdn.slidesharecdn.com/ss_thumbnails/gwu9aqths9ovngsrhidc-3-velibor-ilic-autonomous-driving-how-ai-shapes-technical-challenges-251219150035-7436923a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Petrovic - Is it really that expensive to build an AI sy...](https://cdn.slidesharecdn.com/ss_thumbnails/ybqhdwvusbg7jms3doxh-9-251216105605-7aab5a10-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Maria Kokiasmenos - AI Governance US Perspective.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/eszqnbzlsqa2vch6dmci-6-251215095918-6fcdf45f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)


