Download as PDF, PPTX





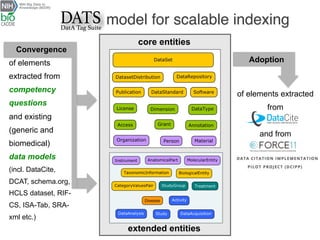


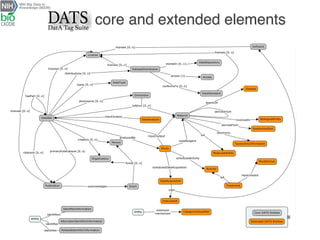

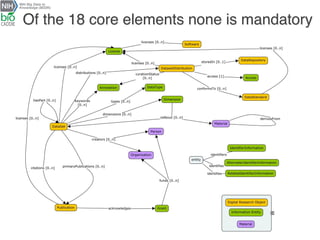



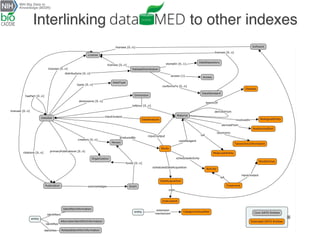
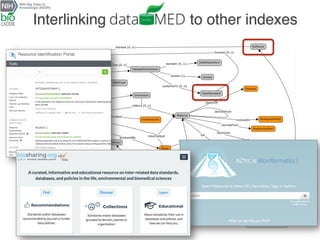


The document describes the DATS (Data Tag Suite) model, which aims to provide a standardized way to index datasets through a community effort. The DATS model was developed by combining use cases and existing data schemas, and represents datasets and their metadata in a scalable way. It focuses on key descriptors like authors, datasets, publications, and funding to enable discoverability. The DATS model is serialized in JSON and JSON-LD using schema.org to increase visibility, accessibility, and search engine ranking. It is being adopted by databases and aligned with other bioscience metadata efforts.

























![Valen Metadata and the [Data] Repository](https://cdn.slidesharecdn.com/ss_thumbnails/valen-2-feb23-170223194717-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)


