Downloaded 161 times





![@maasg #EUstr2
12
def print(num: Int): Unit = ssc.withScope {
def foreachFunc: (RDD[T], Time) => Unit = {
(rdd: RDD[T], time: Time) => {
val firstNum = rdd.take(num + 1)
// scalastyle:off println
println("-------------------------------------------")
println(s"Time: $time")
println("-------------------------------------------")
firstNum.take(num).foreach(println)
if (firstNum.length > num) println("...")
println()
// scalastyle:on println
}
}
foreachRDD(context.sparkContext.clean(foreachFunc), displayInnerRDDOps = false)
}
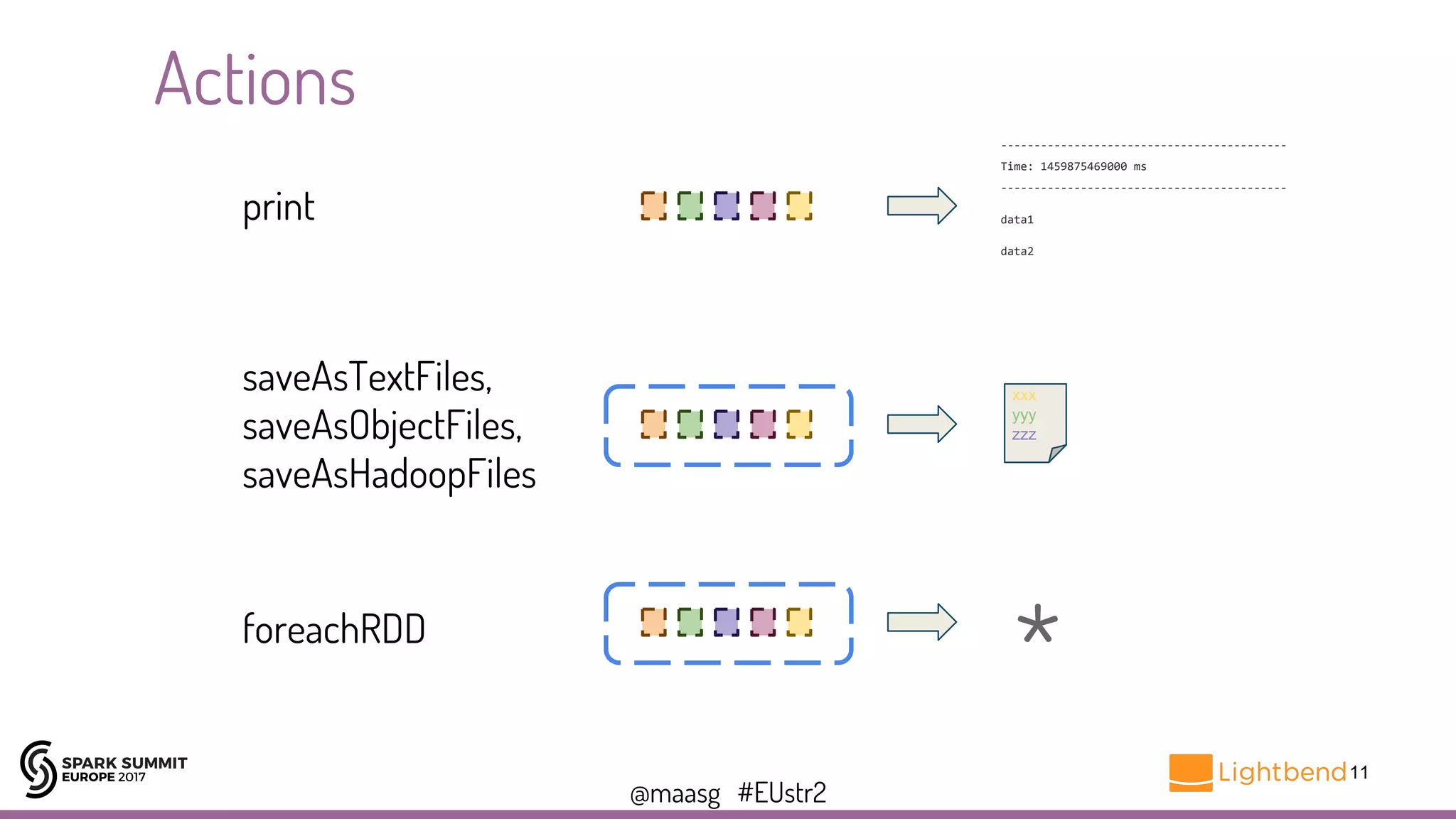
Actions](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-12-2048.jpg)

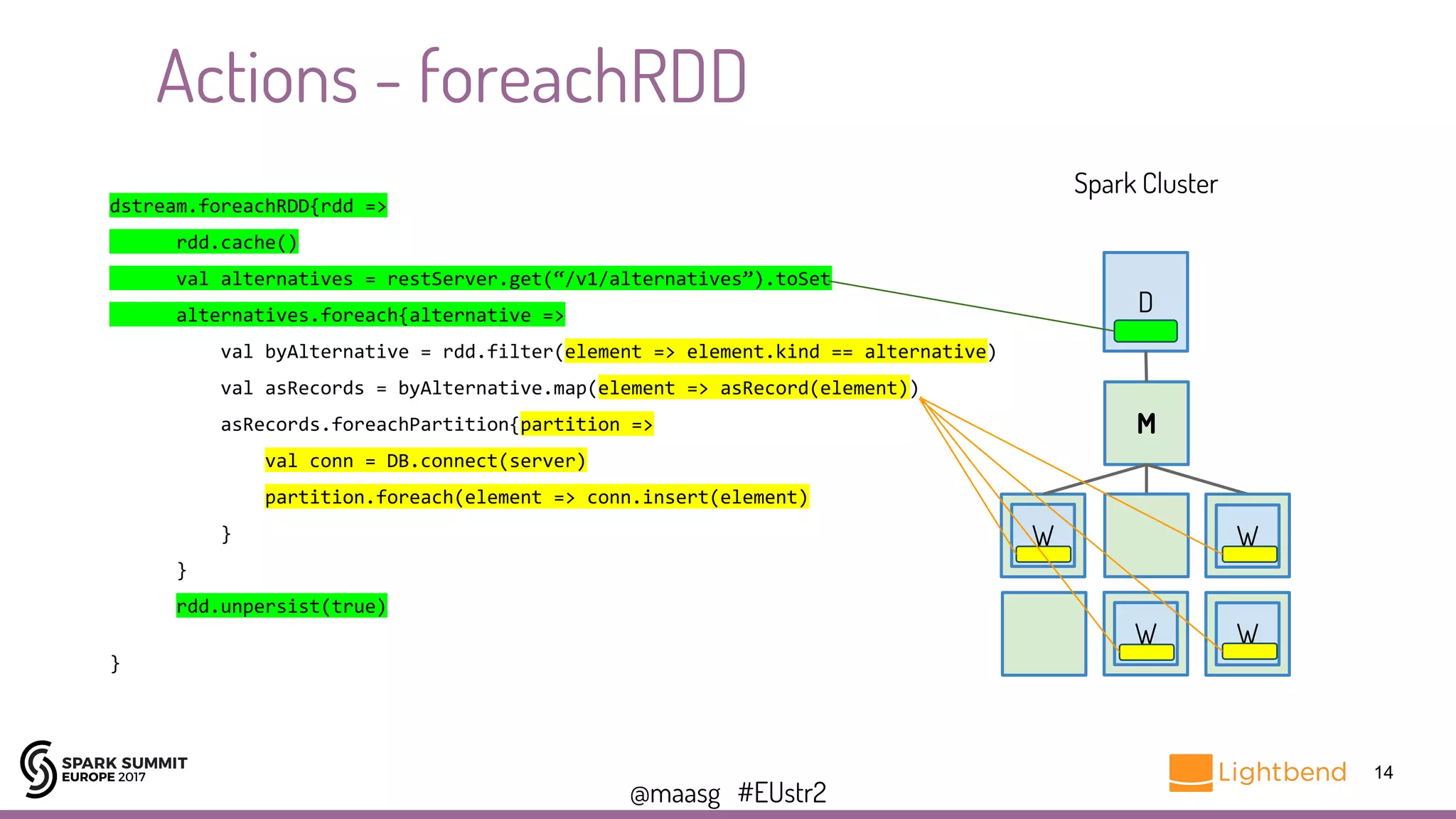


// Usage
val constantDStream = new ConstantInputDStream(streamingContext, rdd)](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-17-2048.jpg)
![@maasg #EUstr2
ConstantInputDStream: Generate Data
18
import scala.util.Random
val sensorId: () => Int = () => Random.nextInt(sensorCount)
val data: () => Double = () => Random.nextDouble
val timestamp: () => Long = () => System.currentTimeMillis
// Generates records with Random data
val recordFunction: () => String = { () =>
if (Random.nextDouble < 0.9) {
Seq(sensorId().toString, timestamp(), data()).mkString(",")
} else {
// simulate 10% crap data as well… real world streams are seldom clean
"!!~corrupt~^&##$"
}
}
val sensorDataGenerator = sparkContext.parallelize(1 to n).map(_ => recordFunction)
val sensorData = sensorDataGenerator.map(recordFun => recordFun())
val rawDStream = new ConstantInputDStream(streamingContext, sensorData)
RDD[() => Record]](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-18-2048.jpg)
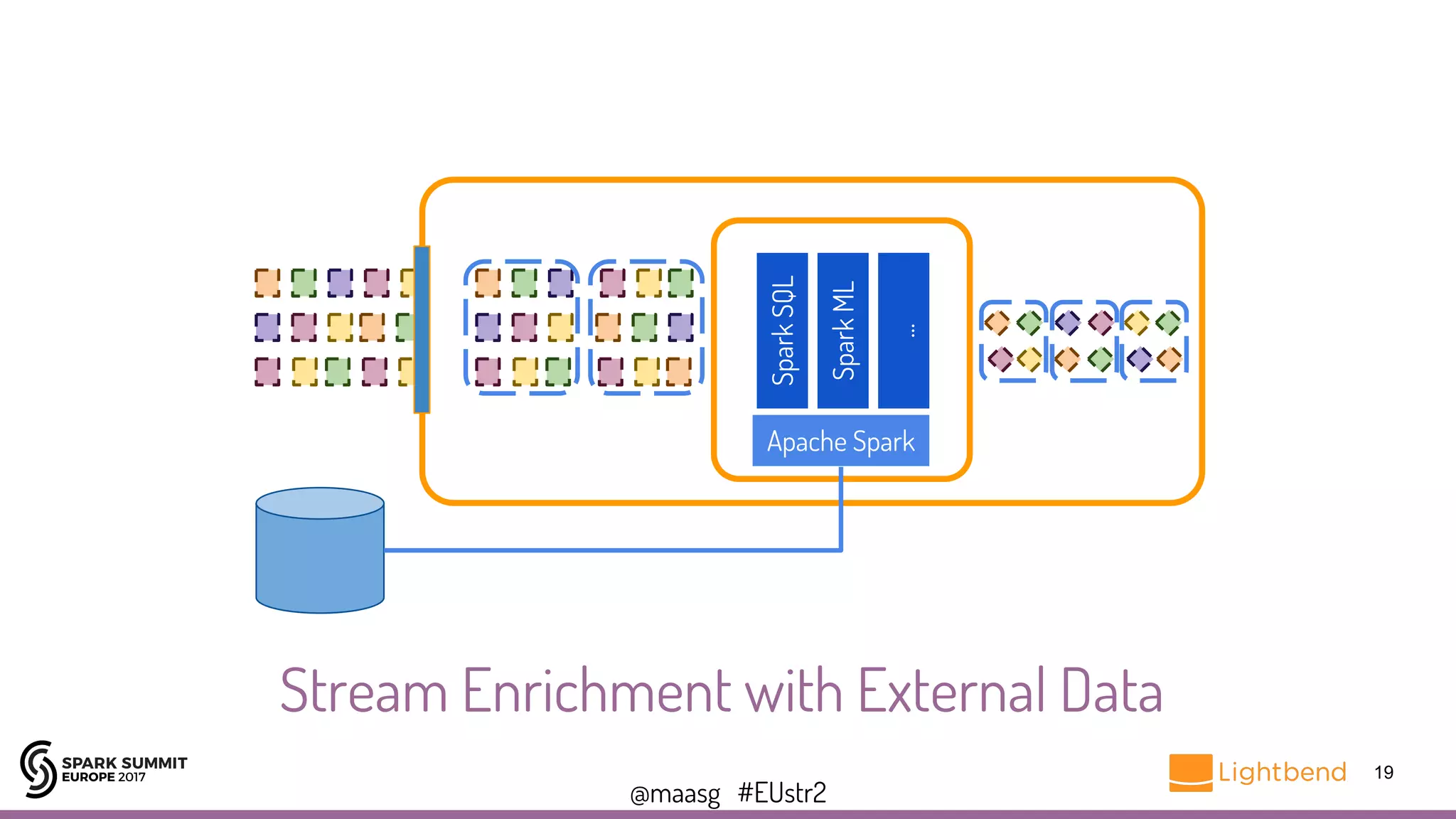
![@maasg #EUstr2
ConstantInputDStream + foreachRDD=
Reload External Data Periodically
20
var sensorReference = sparkSession.read.parquet(s"$referenceFile")
sensorRef.cache()
val refreshDStream = new ConstantInputDStream(streamingContext, sparkContext.emptyRDD[Int])
// Refresh data every 5 minutes
val refreshIntervalDStream = refreshDStream.window(Seconds(300), Seconds(300))
refreshIntervalDStream.foreachRDD{ _ =>
sensorRef.unpersist(false)
sensorRef = sparkSession.read.parquet(s"$referenceFile")
sensorRef.cache()
}](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-20-2048.jpg)


![@maasg #EUstr2
ForeachRDD + Datasets + Functional =
Structured Streaming Portability
23
val parse: Dataset[String] => Dataset[Record] = ???
val process: Dataset[Record] => Dataset[Result] = ???
val serialize: Dataset[Result] => Dataset[String] = ???
val kafkaStream = spark.readStream…
val f = parse andThen process andThen serialize
val result = f(kafkaStream)
result.writeStream
.format("kafka")
.option("kafka.bootstrap.servers",bootstrapServers)
.option("topic", writeTopic)
.option("checkpointLocation", checkpointLocation)
.start()
val dstream = KafkaUtils.createDirectStream(...)
dstream.map{rdd =>
val ds = sparkSession.createDataset(rdd)
val f = parse andThen process andThen serialize
val result = f(ds)
result.write.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("topic", writeTopic)
.option("checkpointLocation", checkpointLocation)
.save()
}
Structured StreamingSpark Streaming](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-23-2048.jpg)
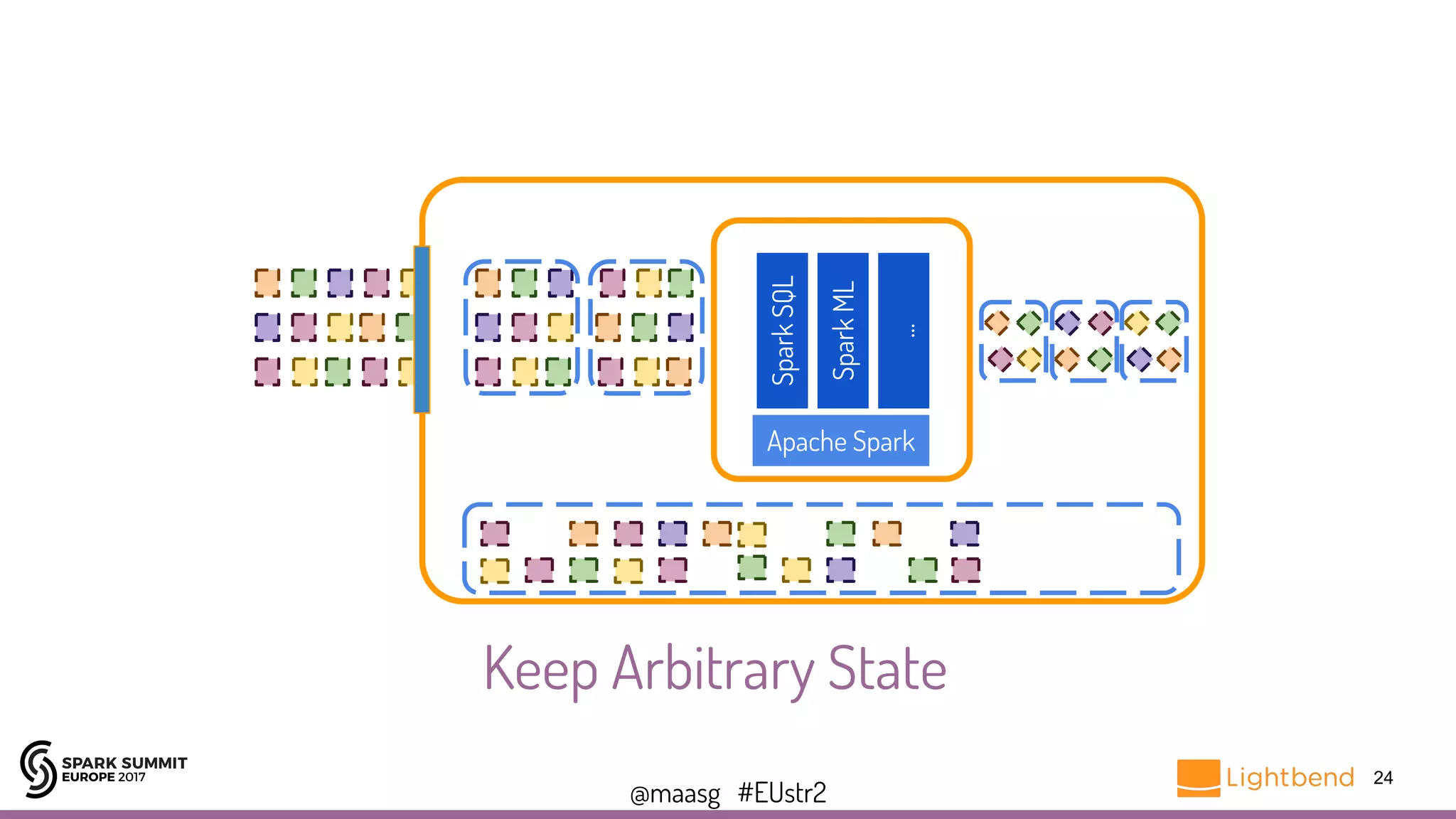
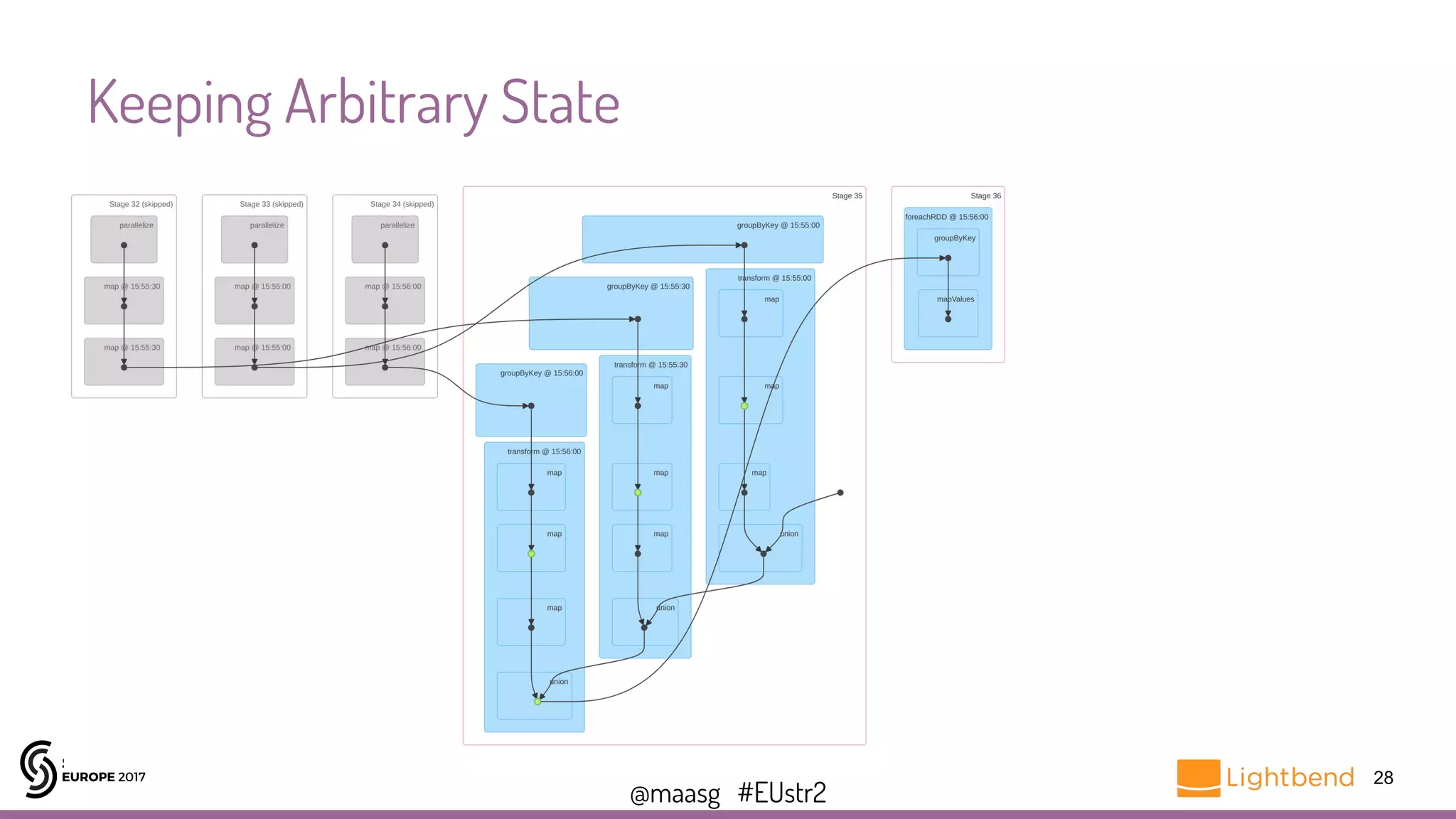
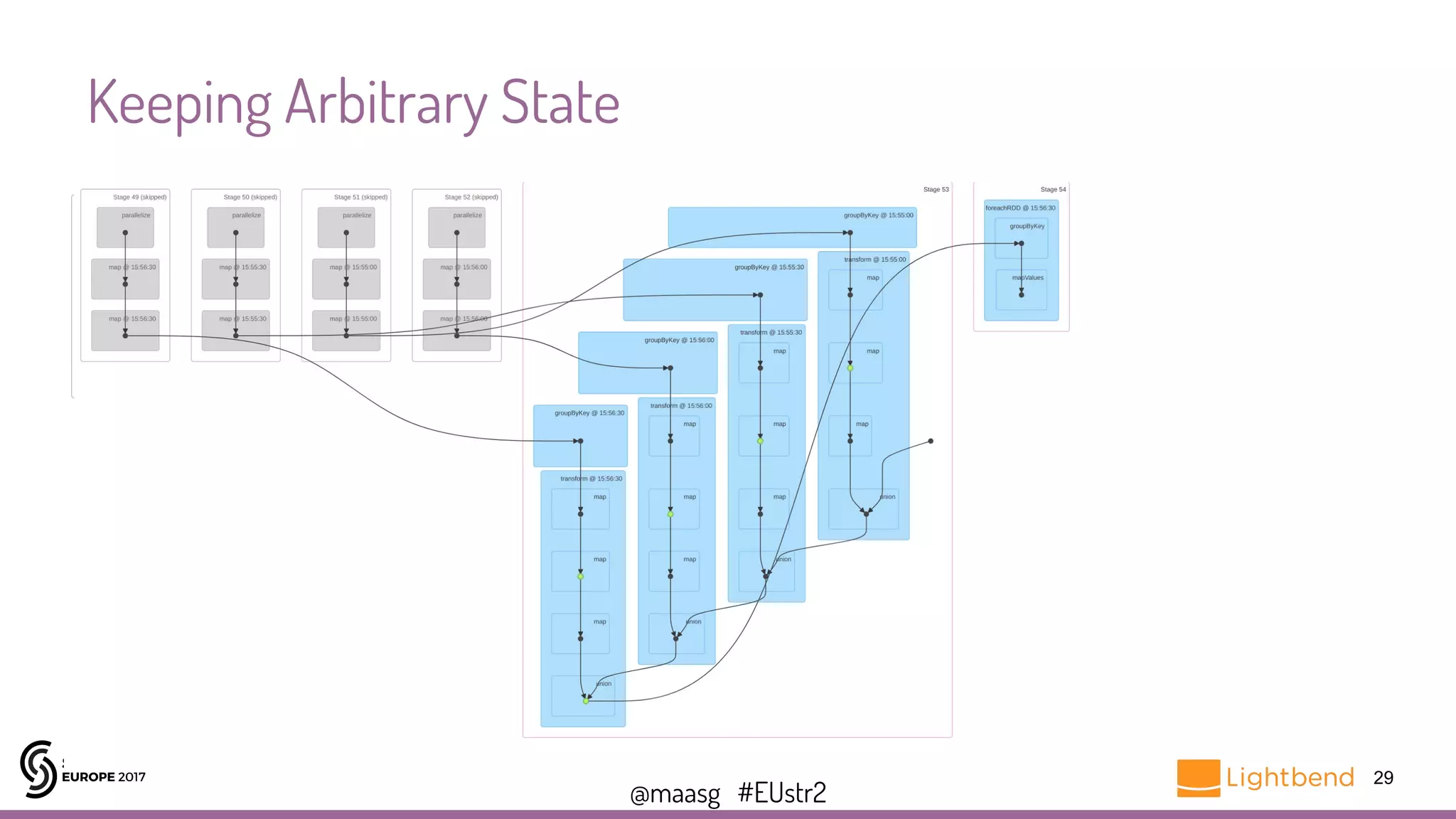
![@maasg #EUstr2
Keeping Arbitrary State
25
var baseline: Dataset[Features] = sparkSession.read.parquet(targetFile).as[Features]
…
stream.foreachRDD{ rdd =>
val incomingData = sparkSession.createDataset(rdd)
val incomingFeatures = rawToFeatures(incomingData)
val analyzed = compare(incomingFeatures, baseline)
// store analyzed data
baseline = (baseline union incomingFeatures).filter(isExpired)
}
https://gist.github.com/maasg/9d51a2a42fc831e385cf744b84e80479](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-25-2048.jpg)
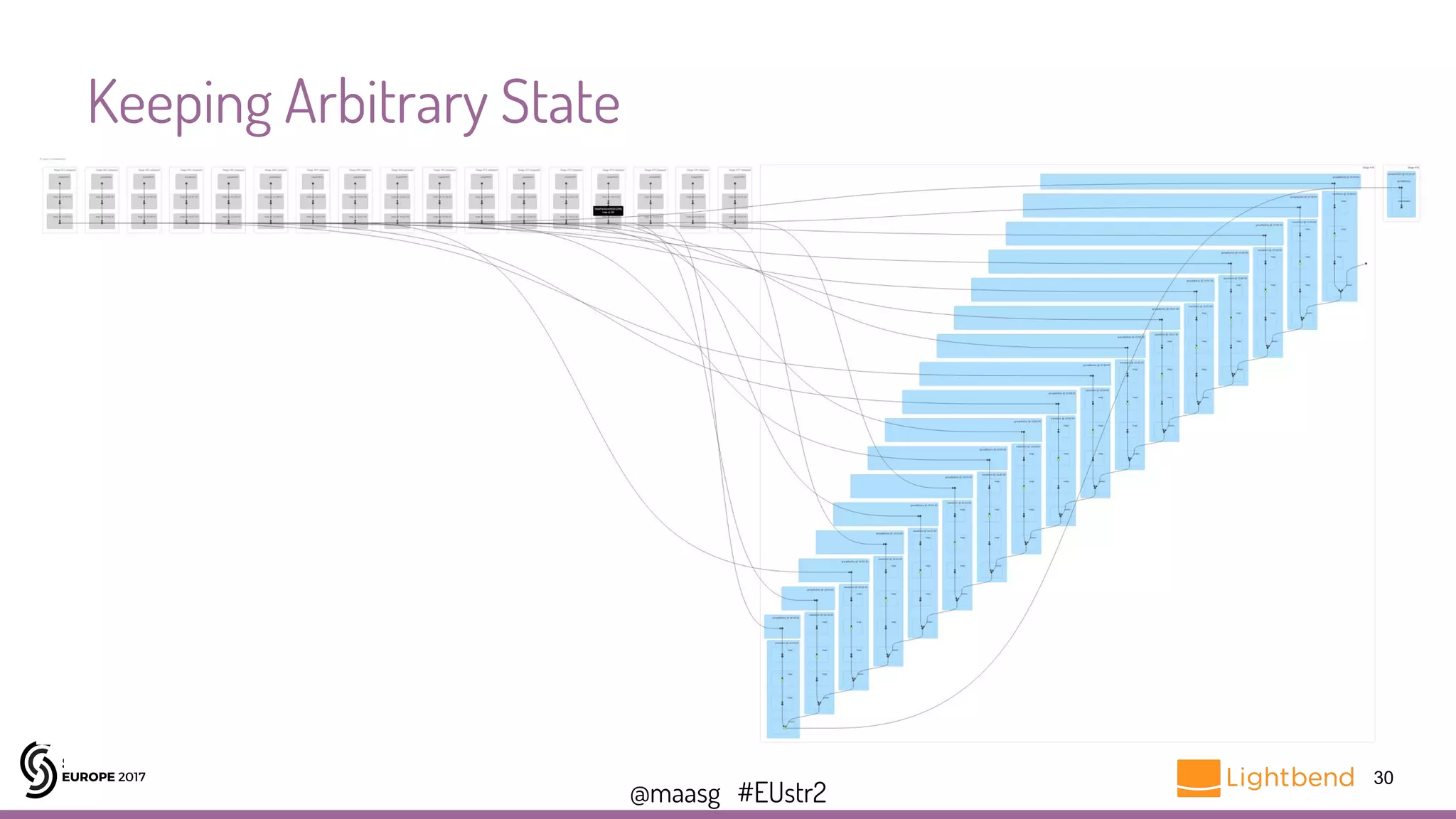
![@maasg #EUstr2
Keeping Arbitrary State: Roll your own checkpoints !
31
var baseline: Dataset[Features] = sparkSession.read.parquet(targetFile).as[Features]
var cycle = 1
var checkpointFile = 0
stream.foreachRDD{ rdd =>
val incomingData = sparkSession.createDataset(rdd)
val incomingFeatures = rawToFeatures(incomingData)
val analyzed = compare(incomingFeatures, baseline)
// store analyzed data
baseline = (baseline union incomingFeatures).filter(isOldFeature)
cycle = (cycle + 1) % checkpointInterval
if (cycle == 0) {
checkpointFile = (checkpointFile + 1) % 2
baseline.write.mode(“overwrite”).parquet(s”$targetFile_$checkpointFile“)
baseline = baseline.read(s”$targetFile_$checkpointFile“)
}
}](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-31-2048.jpg)

 extends AccumulatorV2[T, Long] {
private def instance(): HyperLogLogPlus = new HyperLogLogPlus(precisionValue, 0)
override def add(v: T): Unit = hll.offer(v)
override def merge(other: AccumulatorV2[T, Long]): Unit = other match {
case otherHllAcc: HLLAccumulator[T] => hll.addAll(otherHllAcc.hll)
case _ => throw new UnsupportedOperationException(
s"Cannot merge ${this.getClass.getName} with ${other.getClass.getName}")
}
}](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-35-2048.jpg)

sc.register(uniqueVisitorsAccumulator, "unique-visitors")
…
clickStream.foreachRDD{rdd =>
rdd.foreach{
case BlogHit(ts, user, url) => uniqueVisitorsAccumulator.add(user)
}
...
val currentUniqueVisitors = uniqueVisitorsAccumulator.value
...
}](https://image.slidesharecdn.com/la2gerardmaas-171031195209/75/Spark-Streaming-Programming-Techniques-You-Should-Know-with-Gerard-Maas-36-2048.jpg)
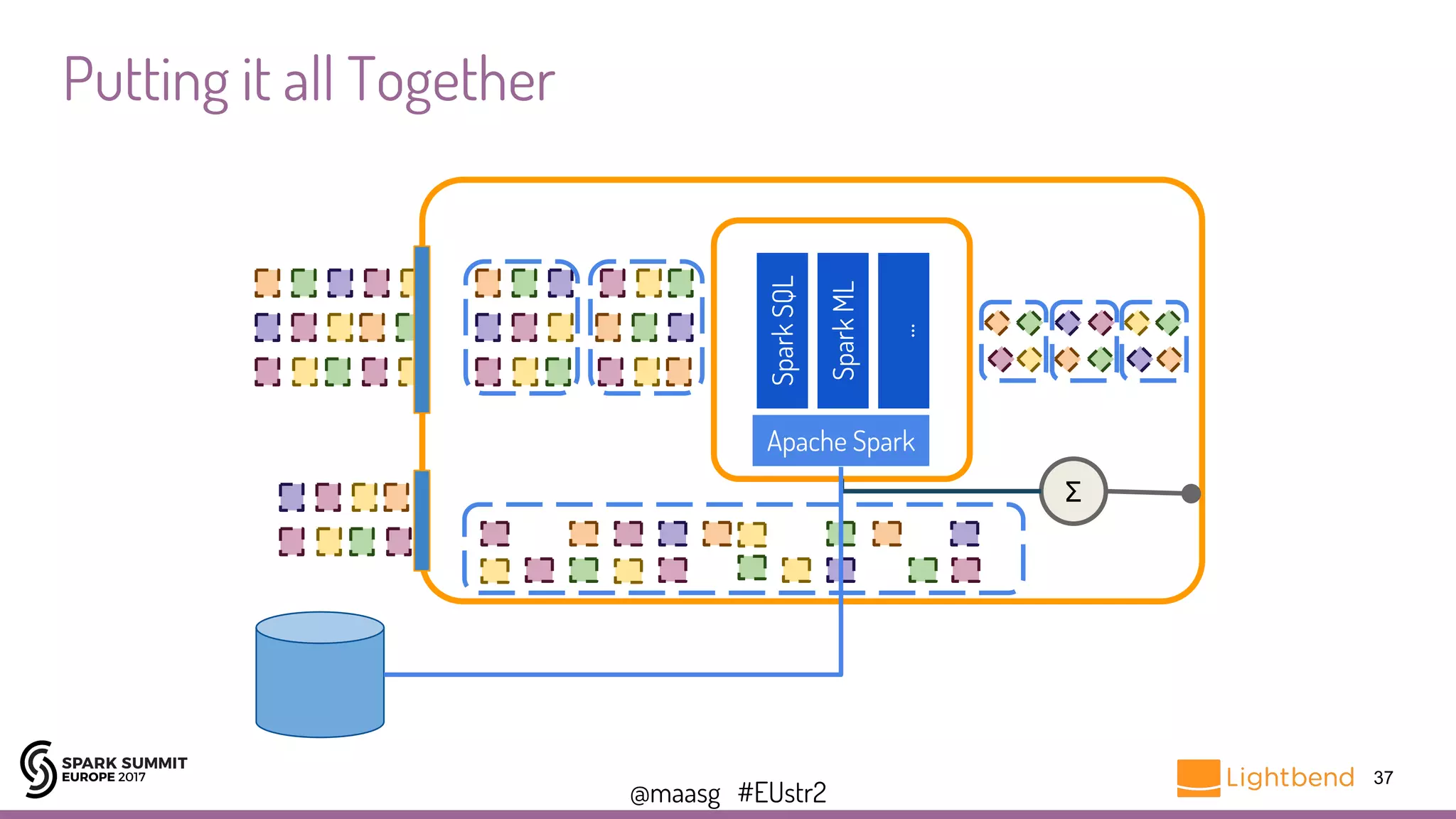



The document presents essential techniques for Spark Streaming, including a refresher on its operations and transformation methods. It discusses the design of streams, the integration of external data, structured streaming capabilities, maintaining state, and using probabilistic accumulators for data analysis. Practical code examples are provided throughout, illustrating how to implement these techniques in various scenarios.






























































































![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
