Download as PDF, PPTX


















![28
DataFrames
Similar API to data frames
in R and Pandas
Optimized and compiled to
bytecode by Spark SQL
Read/write to Hive, JSON,
Parquet, ORC, Pandas
df = jsonFile(“tweets.json”)
df[df.user == “matei”]
.groupBy(“date”)
.sum(“retweets”)
0
5
10
Python Scala DataFrame
RunningTime](https://image.slidesharecdn.com/large-scale-spark-talk-150219232451-conversion-gate01/85/Lessons-from-Running-Large-Scale-Spark-Workloads-28-320.jpg)
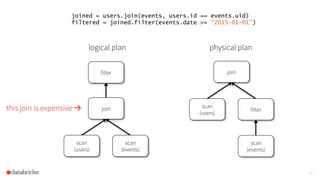
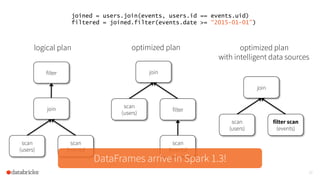


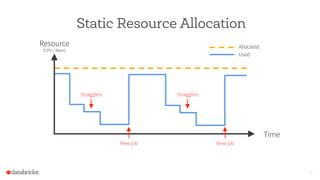
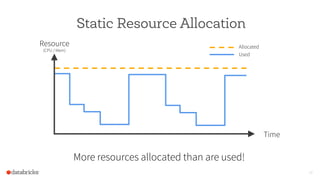
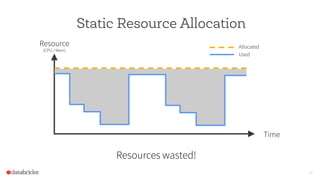
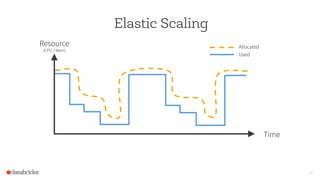
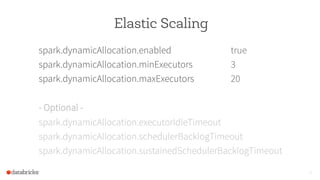
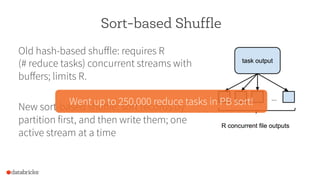
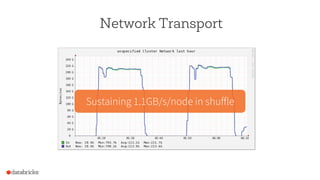
The document discusses the scalability and performance of Apache Spark, highlighting notable use cases from companies like Tencent and Alibaba which utilize Spark for massive data processing tasks. Architectural improvements such as elastic scaling, revamped shuffling, and the introduction of DataFrames are emphasized to enhance resource utilization and optimize data handling. Overall, the presentation showcases the capabilities of Spark in handling large-scale workloads effectively.


































































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)



