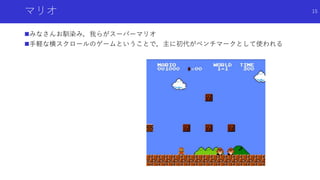
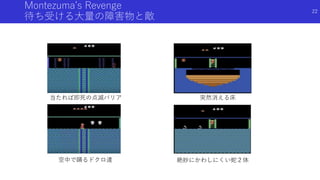
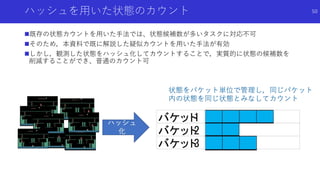
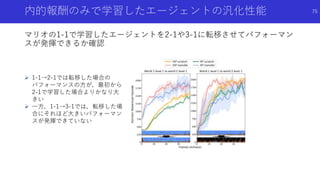
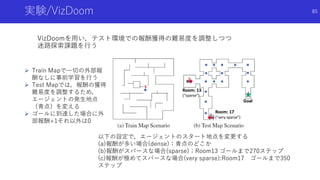
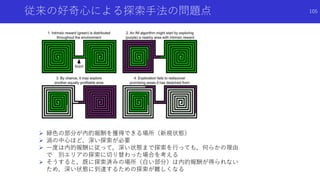
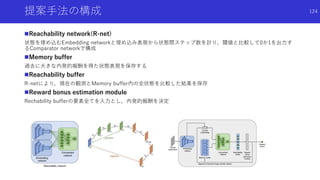
状態のハッシュ化を用いたカウントによる内発的報酬
#Exploration: A Studyof Count-Based Exploration for Deep Reinforcement
Learning[Haoran+]
論文概要
高次元な探索空間でも,疑似カウントではない普通の状態カウントを用いた内発
的報酬を得るため,状態をハッシュ化
状態をハッシュ化する前の良い特徴抽出法についても検討
49
参考文献,サイト,資料 1
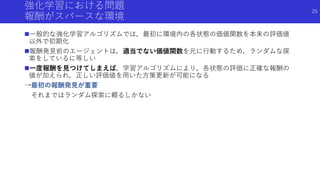
強化学習・深層強化学習の基礎
Richard SSutton and Andrew G Barto. Reinforcement learning: An introduction, volume 1. Bradford, 1998.
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian
Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go
with deep neural networks and tree search. Nature, 529(7587):484–489, 2016.
Hado Van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. In
AAAI, volume 2, page 5. Phoenix, AZ, 2016.
Ziyu Wang, Nando de Freitas, and Marc Lanctot. Dueling network architectures for deep reinforcement
learning. In ICML, 2016.
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David
Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In ICML, pages
1928–1937, 2016.
Arun Nair, Praveen Srinivasan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Vedavyas
Panneershelvam, Mustafa Suleyman, Charles Beattie, Stig Petersen, et al. Massively parallel methods for
deep reinforcement learning. arXiv preprint arXiv:1507.04296, 2015.
J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel, “Trust region policy optimization”, in ICML,
2015.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization
algorithms. CoRR, abs/1707.06347, 2017.
Y. Duan, X. Chen, R. Houthooft, J. Schulman, and P. Abbeel, “Benchmarking deep reinforcement learning for
continous control”, in ICML, 2016.
Bellemare, Marc G, Naddaf, Yavar, Veness, Joel, and Bowling, Michael. The arcade learning environment
130
131.
参考文献,サイト,資料 2
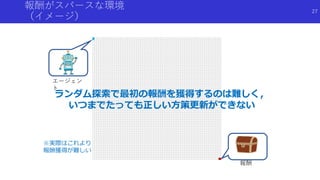
報酬なスパースな環境と好奇心による探索
GregBrockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym,
2016.
Unity ML-agents. https://github.com/Unity-Technologies/ml-agents.
S. P. Singh, A. G. Barto, and N. Chentanez. Intrinsically motivated reinforcement learning. In NIPS, 2005.
Strehl, A. L. and Littman, M. L. (2008). An analysis of model-based interval estimation for Markov decision processes. Journal of
Computer and System Sciences, 74(8):1309 – 1331.
論文紹介
環境から得る情報量を用いた内発的報酬
R. Houthooft, X. Chen, Y. Duan, J. Schulman, F. De Turck, and P. Abbeel. Vime: Variational information maximizing exploration. In
NIPS, 2016.
Stadie, B. C., Levine, S., and Abbeel, P. (2015). Incentivizing exploration in reinforcement learning with deep predictive models. arXiv
preprint arXiv:1507.00814.
疑似的な状態カウントと内発的報酬を組み合わせた探索
Marc Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. Unifying count-based exploration
and intrinsic motivation. In NIPS, pages 1471–1479, 2016.
Bellemare, M., Veness, J., and Talvitie, E. (2014). Skip context tree switching. In Proceedings of the 31st International Conference on
Machine Learning, pages 1458–1466.
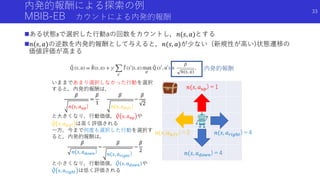
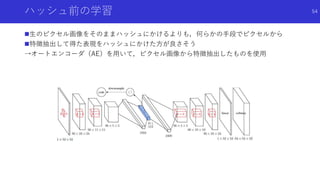
状態のハッシュ化を用いたカウントによる内発的報酬
Haoran Tang, Rein Houthooft, Davis Foote, Adam Stooke, OpenAI Xi Chen, Yan Duan, John Schulman, Filip DeTurck, and Pieter
Abbeel. # exploration: A study of count-based exploration for deep reinforcement learning. In NIPS, pages 2750–2759, 2017.
Charikar, Moses S. Similarity estimation techniques from rounding algorithms. In Proceedings of the 34th Annual ACM Symposium on
Theory of Computing (STOC), pp. 380–388, 2002.
131
132.
参考文献,サイト,資料 3
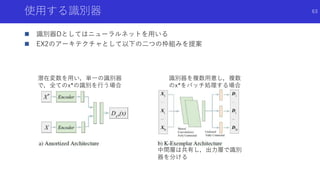
観測の識別器を用いて推定した密度を内発的報酬とする探索
J. Fu,J. D. Co-Reyes, and S. Levine. EX2: Exploration with exemplar models for deep
reinforcement learning. NIPS, 2017.
まったく報酬が与えられない環境における探索
Yuri Burda, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, and Alexei A. Efros. Large-scale
study of curiosity-driven learning. In arXiv:1808.04355, 2018.
自分に関係あるものだけに注目した好奇心による探索
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven exploration by self-
supervised prediction. In ICML, 2017.
ランダム初期化したネットワークの蒸留と予測誤差による内発的報酬
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation.
arXiv preprint arXiv:1810.12894, 2018.
過去に保存した良い状態に戻ってスタート地点とする探索手法
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. 2019. Go-Explore: a New
Approach for Hard-Exploration Problems. arXiv preprint arXiv:1901.10995 (2019)
Tim Salimans and Richard Chen. Learning montezuma’s revenge from a single demonstration. arXiv preprint
arXiv:1812.03381, 2018.
Reinforcement Learning @ NeurIPS2018 https://www.slideshare.net/yukono1/reinforcement-learning-
neurips2018
2018-12-07-NeurIPS-DeepRLWorkshop-Go-Explore
http://www.cs.uwyo.edu/~jeffclune/share/2018_12_07_NeurIPS_DeepRLWorkshop_Go_Explore.pdf
132
133.
参考文献,サイト,資料 4
その他好奇心による探索手法
NikolaySavinov, Anton Raichuk, Raphael Marinier, Damien Vincent, Marc Pollefeys, Timothy Lillicrap, and Sylvain Gelly. Episodic curiosity
through reachability. arXiv preprint arXiv:1810.0227, 2018.
Daniel McDuff and Ashish Kapoor. Visceral Machines: Reinforcement Learning with Intrinsic Rewards that Mimic the Human Nervous System.
arXiv preprint arXiv:1805.09975, 2018.
Sandy H. Huang and Martina Zambelli and Jackie Kay and Murilo F. Martins and Yuval Tassa and Patrick M. Pilarski and Raia Hadsell. Learning
Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning. arXiv preprint arXiv:1903.08542, 2019
133








![強化学習 用語 2
軌道(Trajectory)
- 環境における状態,行動,報酬の列
方策(Policy)
- 状態の入力に対して行動を返す.強化学習における学習対象
• 決定論的方策:𝜋(𝑠) = 𝑎
• 確率的方策:𝜋(𝑎|𝑠) = 𝑃[𝑎|𝑠]
価値関数(Value function)
- ある状態や行動に対する,将来的な報酬和を考慮した評価値
遷移確率
- ある状態𝑠𝑡で行動𝑠𝑡を行った場合にある状態𝑠𝑡+1に遷移する確率P[𝑠𝑡+1|𝑠𝑡, 𝑎 𝑡]
8](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-8-320.jpg)



















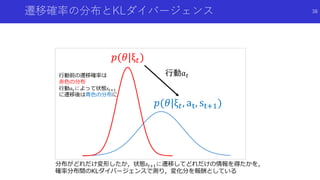
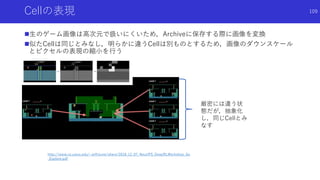
![環境から得る情報量を用いた内発的報酬
VIME: Variational Information Maximizing Exploration[Houthooft+]
論文概要
環境に対する情報量の改善=好奇心とし,情報量が改善されるような状態遷移に対して
多くの内発的報酬を付与
情報量の改善は,状態遷移前後の環境のダイナミクスの分布間のKLダイバージェンス
※非常に数式が多い論文.概念的な部分を中心に話します
36](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-36-320.jpg)


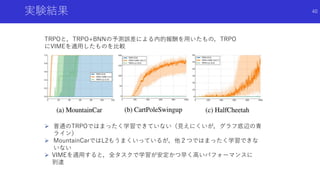
![疑似的な状態カウントと内発的報酬を組み合わせた探索
Unifying Count-Based Exploration and Intrinsic Motivation[Bellemare+]
論文概要
既存のカウントベースによる内発的報酬の 手法を状態候補が極めて多いタスクに応用
するのは難しい
対策として状態の密度推定を用いた疑似的な状態カウントを導入することで,内発的報
酬を生成
41](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-41-320.jpg)



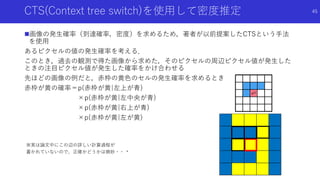


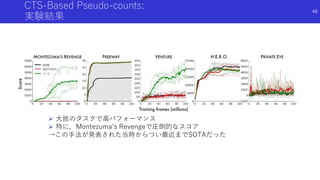
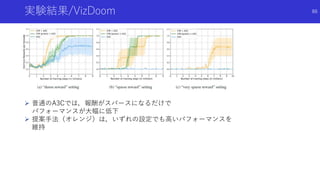
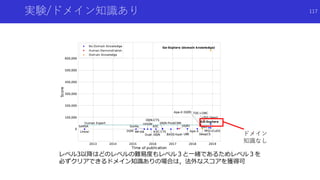
![状態のハッシュ化を用いたカウントによる内発的報酬
#Exploration: A Study of Count-Based Exploration for Deep Reinforcement
Learning[Haoran+]
論文概要
高次元な探索空間でも,疑似カウントではない普通の状態カウントを用いた内発
的報酬を得るため,状態をハッシュ化
状態をハッシュ化する前の良い特徴抽出法についても検討
49](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-49-320.jpg)




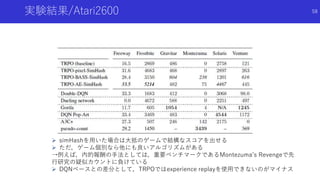
![観測の識別器を用いて推定した密度を内発的報酬とする探索
EX2: Exploration with Exemplar Models for Deep Reinforcement Learning [Fu+]
論文概要
新しい状態は現在までに観測していない明らかに違う状態であるため,あるモデルで他
の状態と簡単に識別可能
簡単に判別できる状態=新しい状態とし,観測した状態を他の状態と識別するモデルの
出力を用いて内発的報酬を生成
59](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-59-320.jpg)






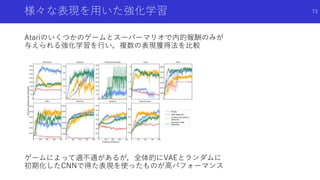
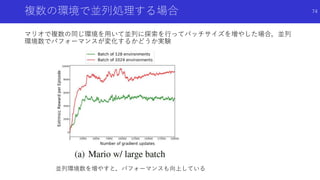
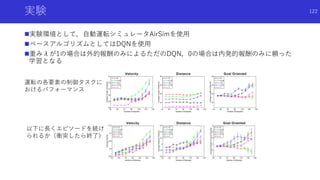
![まったく報酬が与えられない環境における探索
(ICLR2019 Accepted)
Large-Scale Study of Curiosity-Driven Learning [Burda, Edwards, Pathak+]
論文概要
様々なゲームの強化学習で「外的な報酬がまったくない場合にどれくらいパフォーマン
スを発揮できるかを検討した論文
VAEなどを用いた画像からの特徴抽出や学習の様々な工夫を用い,内発的報酬のみで複数
ゲームで高パフォーマンスを確認
67](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-67-320.jpg)





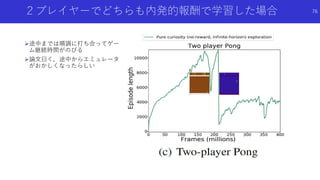

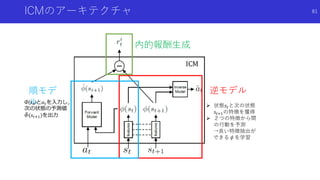
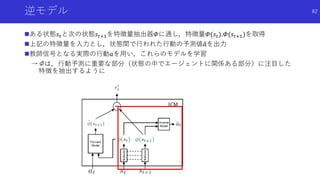
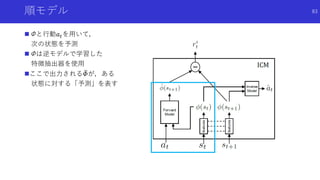
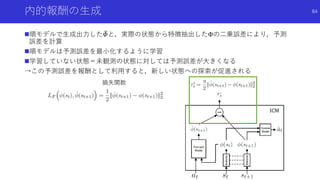
![自分に関係あるものだけに注目した好奇心による探索
Curiosity-driven Exploration by Self-supervised Prediction [Pathak+]
論文概要
エージェントの行動に関係があるもののみに注目するため特徴抽出を行い,予測誤差に
より内発的報酬を生成
特徴抽出のため順モデルと逆モデルを組み合わせた予測を行って報酬を生成する
ICM(Intrinsic Curiosity Module)を提案
79](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-79-320.jpg)


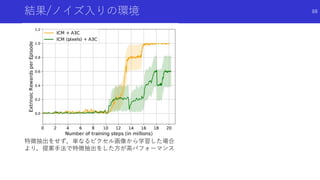




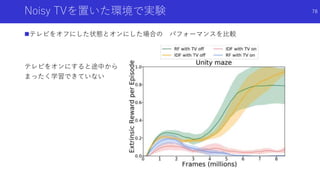
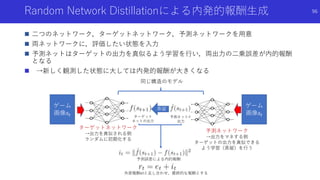
![ランダム初期化したネットワークの蒸留と
予測誤差による内発的報酬
EXPLORATION BY RANDOM NETWORK DISTILLATION [Burda,Edwards+]
論文概要
状態を入力する二つのネットワークとして,ランダムに初期化したネットワークと,
このネットワークの出力を真似るよう蒸留するネットワークを用意
両方のネットワークの出力の誤差を内発的報酬とし,新しい状態に対して探索を促進
RL手法として初めてMontezuma’s Revengeで人間を超えるスコア
94](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-94-320.jpg)



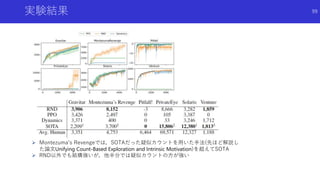

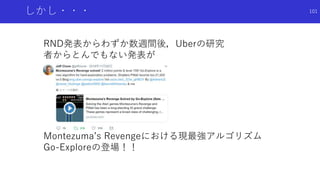
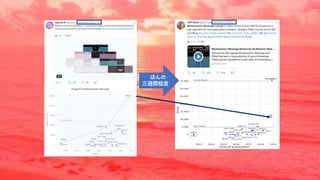

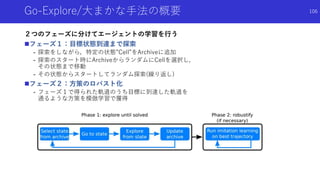
![過去に保存した良い状態に戻ってスタート地点とする
探索手法
Go-Explore: a New Approach for Hard-Exploration Problems [Ecoffet+]
論文概要
報酬がスパースな環境で,従来の好奇心による探索とはまったく違う探索手法を提案
学習を2段階に分け,第1段階で状態の記憶とスタート地点の変更による探索,第2段
階でデモ軌道ロバストな方策を獲得
Montezuma’s RevengeでRNDを超えSOTA
今まで紹介してきた好奇心/内発的報酬に よる探索手法とは異なる枠組みの手法
104](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-104-320.jpg)











![人間の生体反応から学び,危険に対する応答を内発的報酬とす
る手法(ICLR2019 Accepted)
Visceral Machines: Risk-Aversion in Reinforcement Learning with Intrinsic
Physiological Rewards [McDuff+]
論文概要
人間は,危険が近づいたとき,自律神経の働きによる生体反応を元に内発的なフィード
バックを得て行動選択を行っている
運転時の観測画像と,運転者の生体反応パルスを用いて学習したCNNの出力により
内発的報酬を生成
運転タスクで本手法を適用することで,サンプル効率を改善し,エピソード終了
(衝突)までの時間も上昇
120](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-120-320.jpg)

![観測した状態と過去に観測した状態からの離れ具合で内発的報酬
を生成(ICLR2019 Accepted)
EPISODIC CURIOSITY THROUGH REACHABILITY [Savinov, Raichuk, Marinier+]
論文概要
観測の記憶機構を導入し,現在の観測と過去の観測を比較することで,内的報酬を生成
埋め込みにより観測の表現を獲得し,現在の状態と過去の状態の観測がステップ数的に
離れていれば大きな内発的報酬を生成
123](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-123-320.jpg)
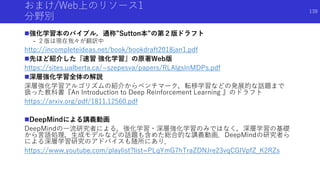
![壊れやすい物体操作のための優しい操作を内発的報酬により
獲得
Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement
Learning [Huang, Zambelli]
論文概要
ロボットによる壊れやすい物体操作には,強すぎる操作をした場合の罰則を与える必要
があるが,これだけでは局所解に陥る
これを回避するため,ペナルティに加えて,環境に対する予測誤差の内発的報酬と,
ペナルティに対する予測誤差の内的報酬を導入
https://sites.google.com/view/gentlemanipulation
126](https://image.slidesharecdn.com/curiosityrl-200831173935/85/slide-126-320.jpg)

















![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)