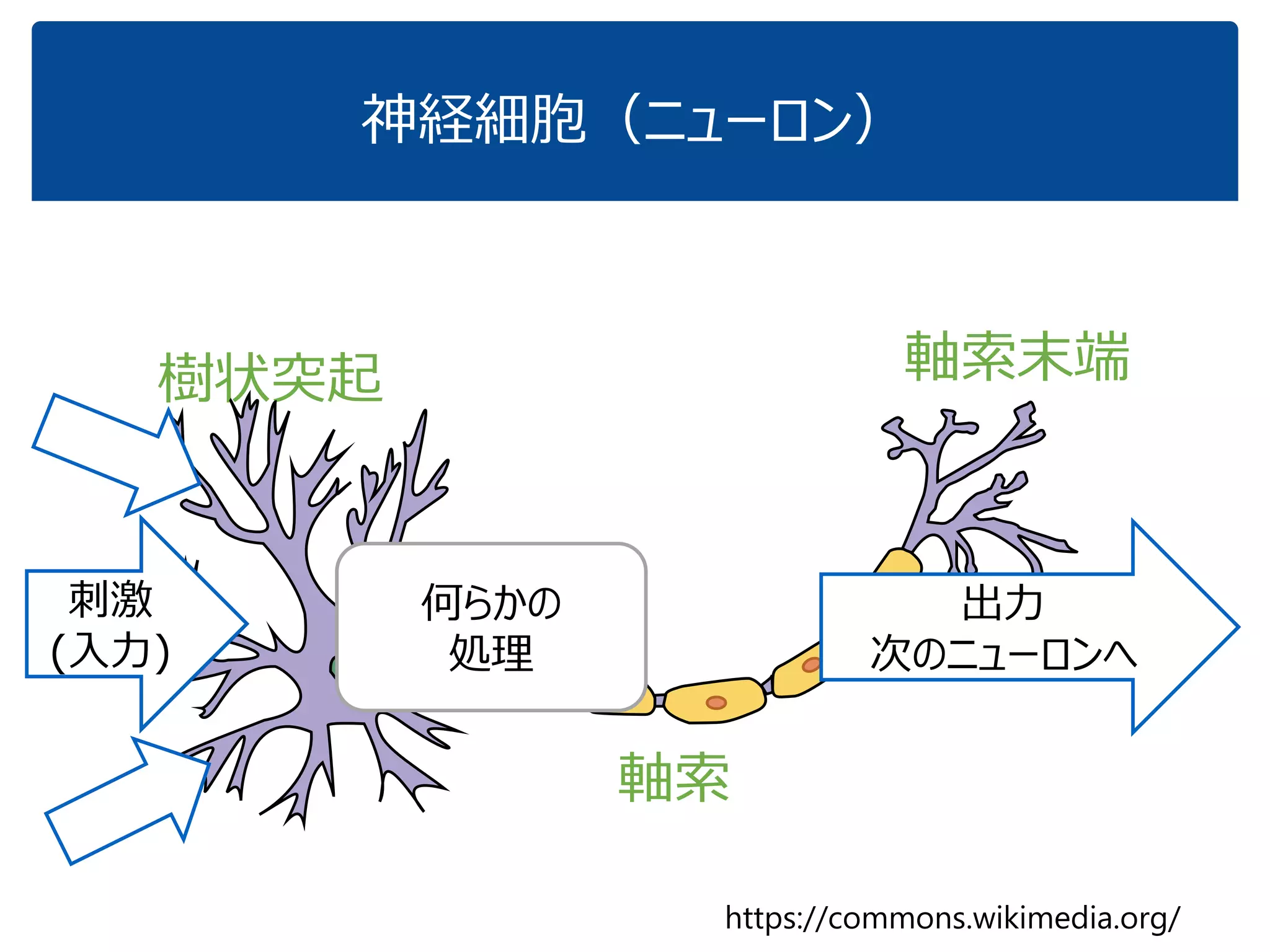
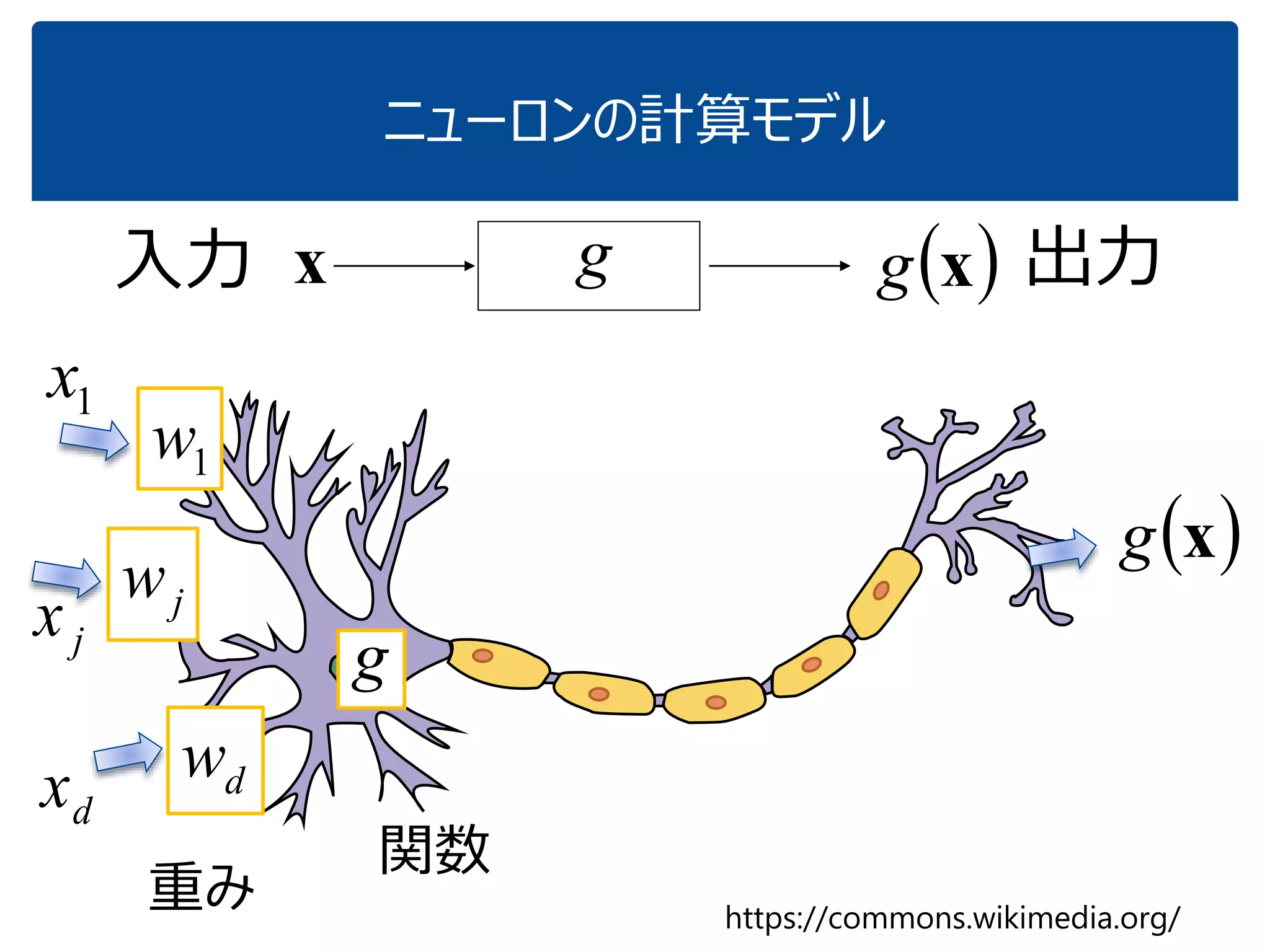
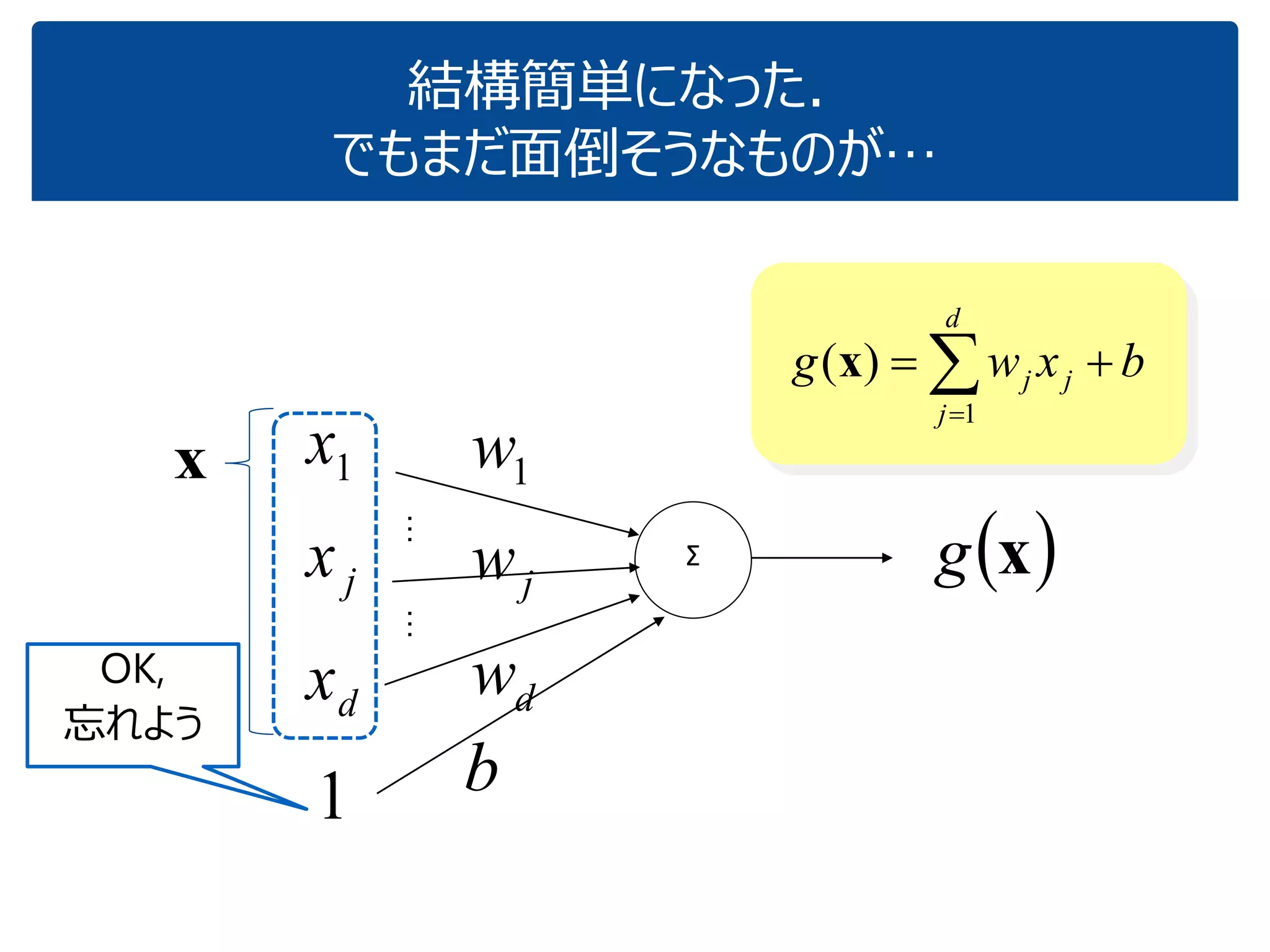
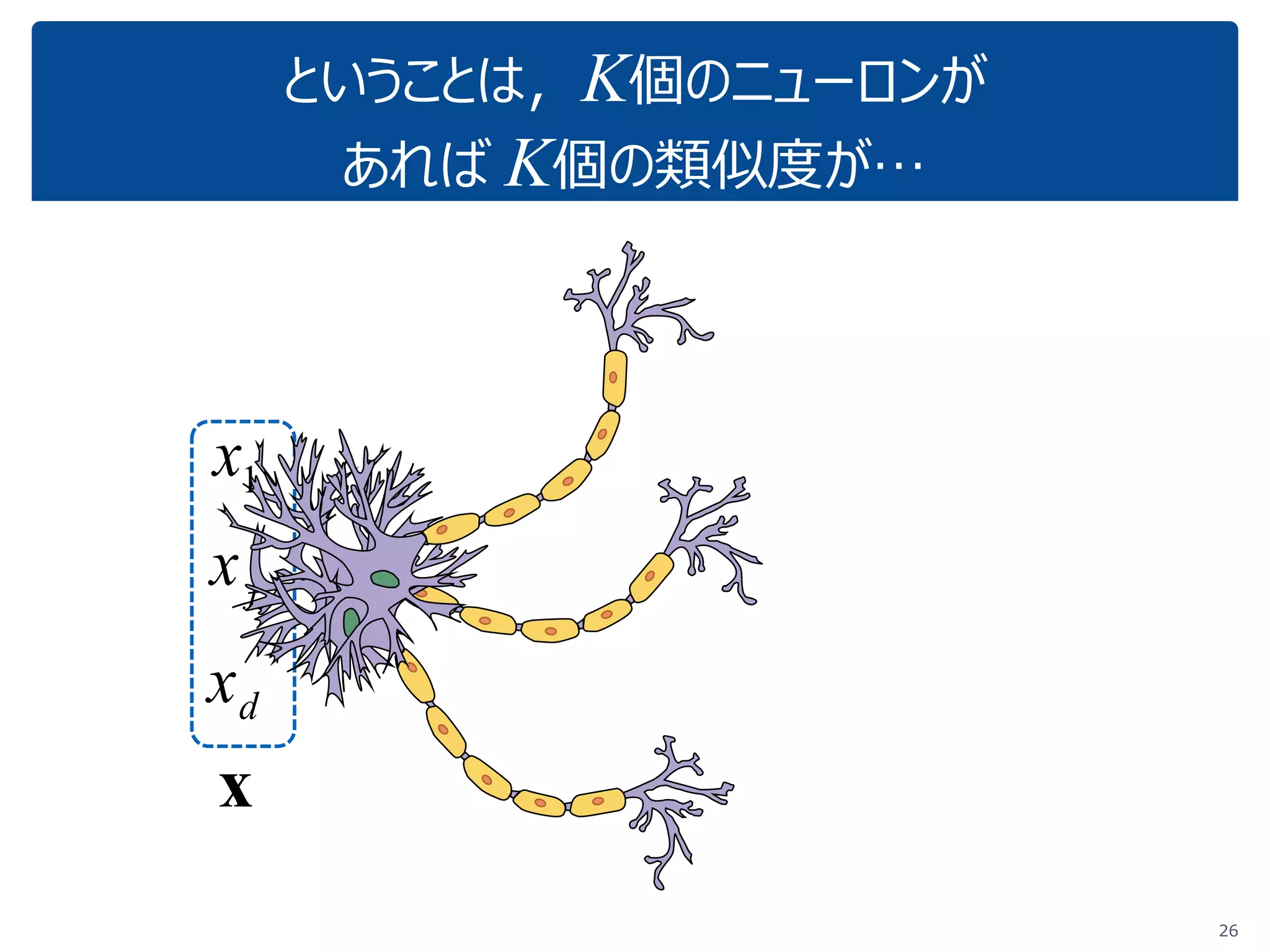
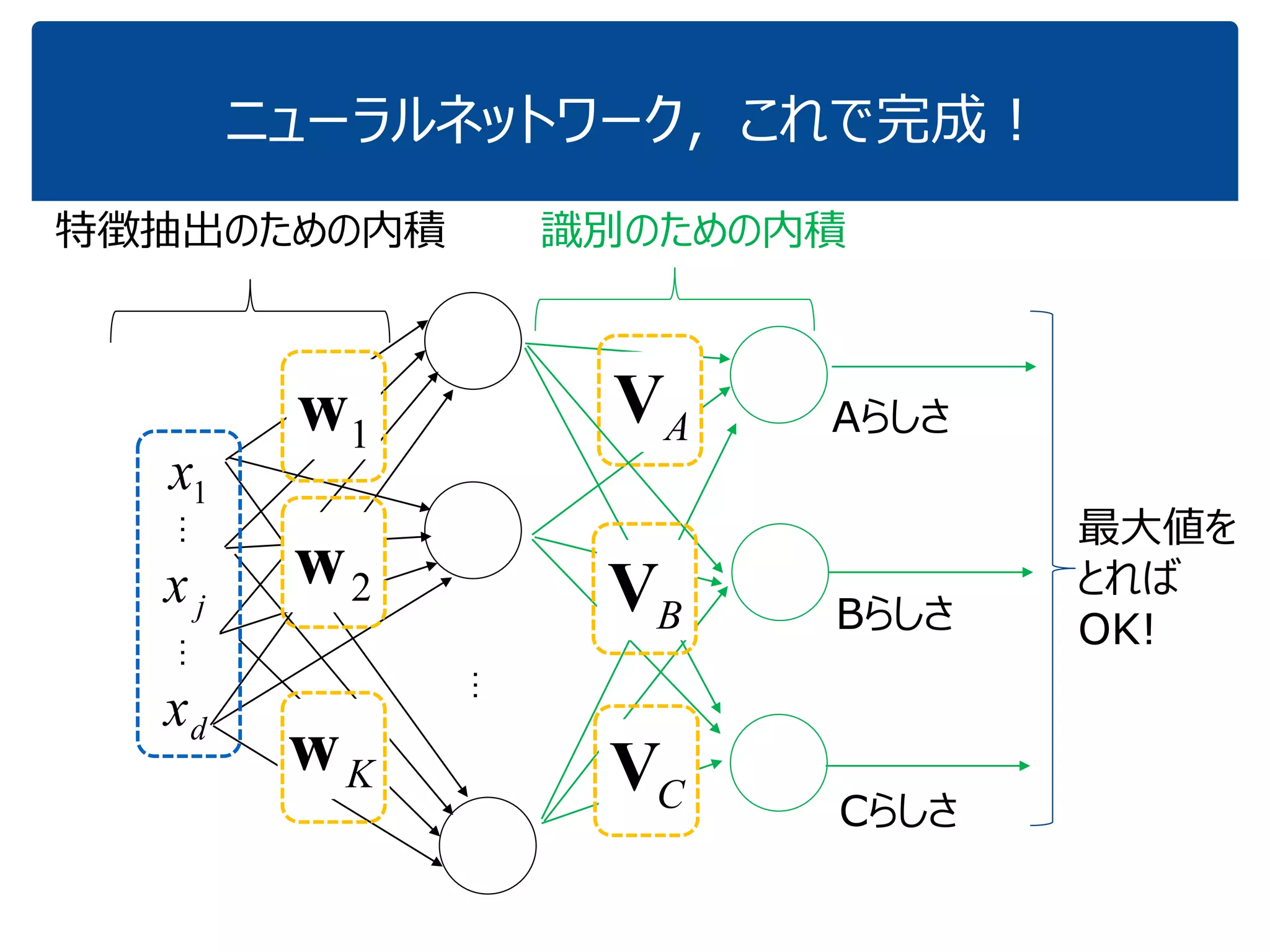
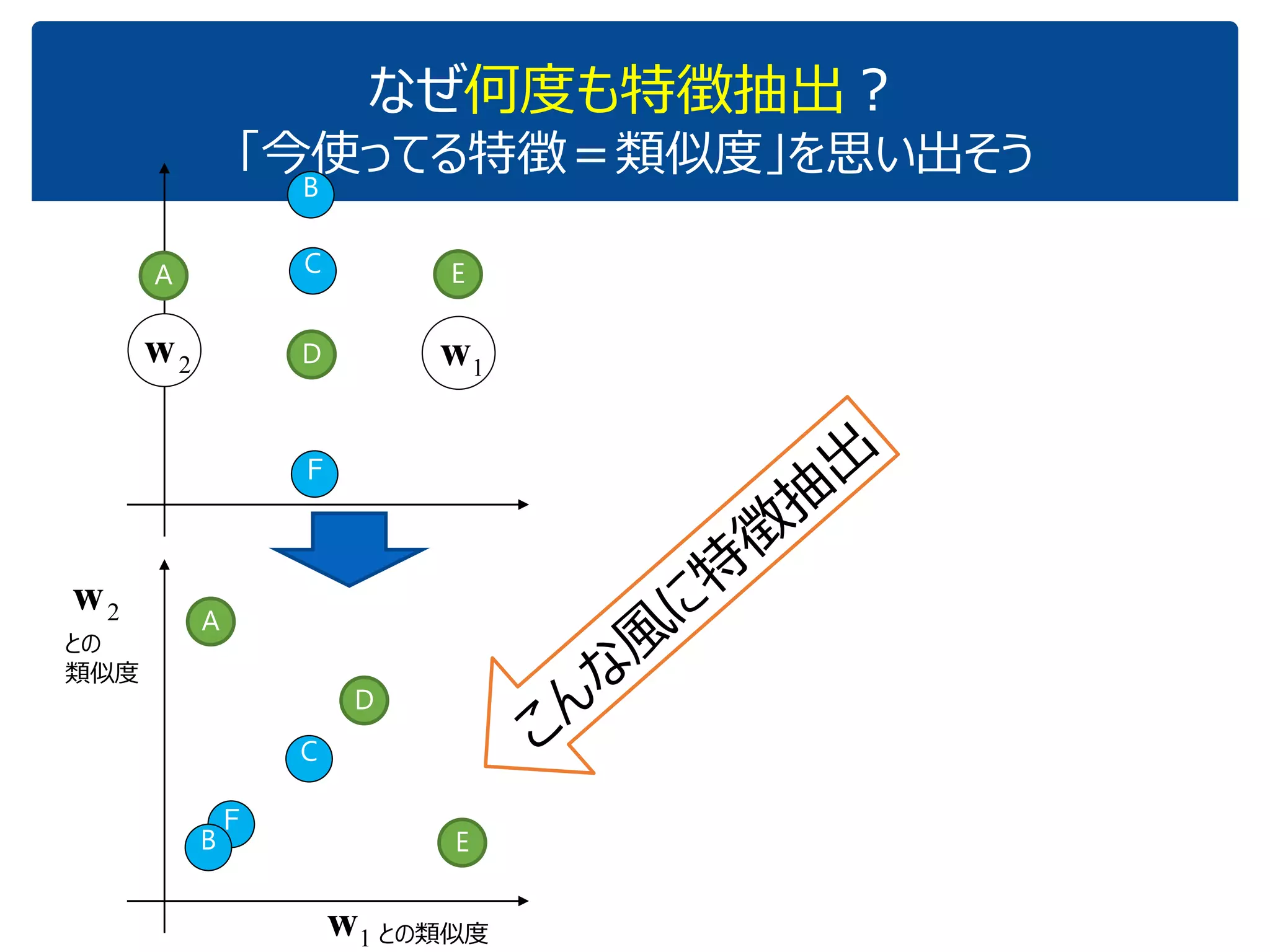
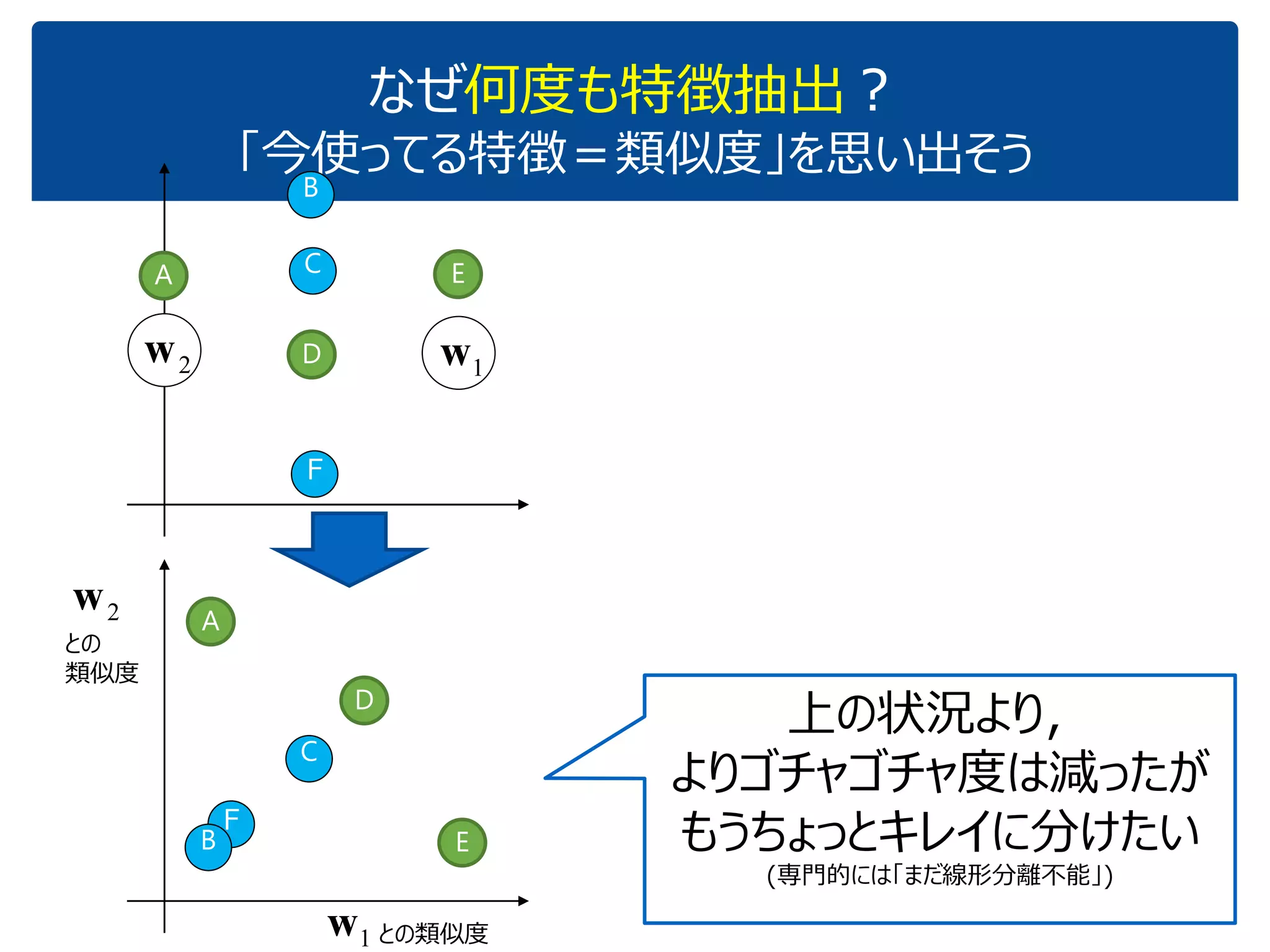
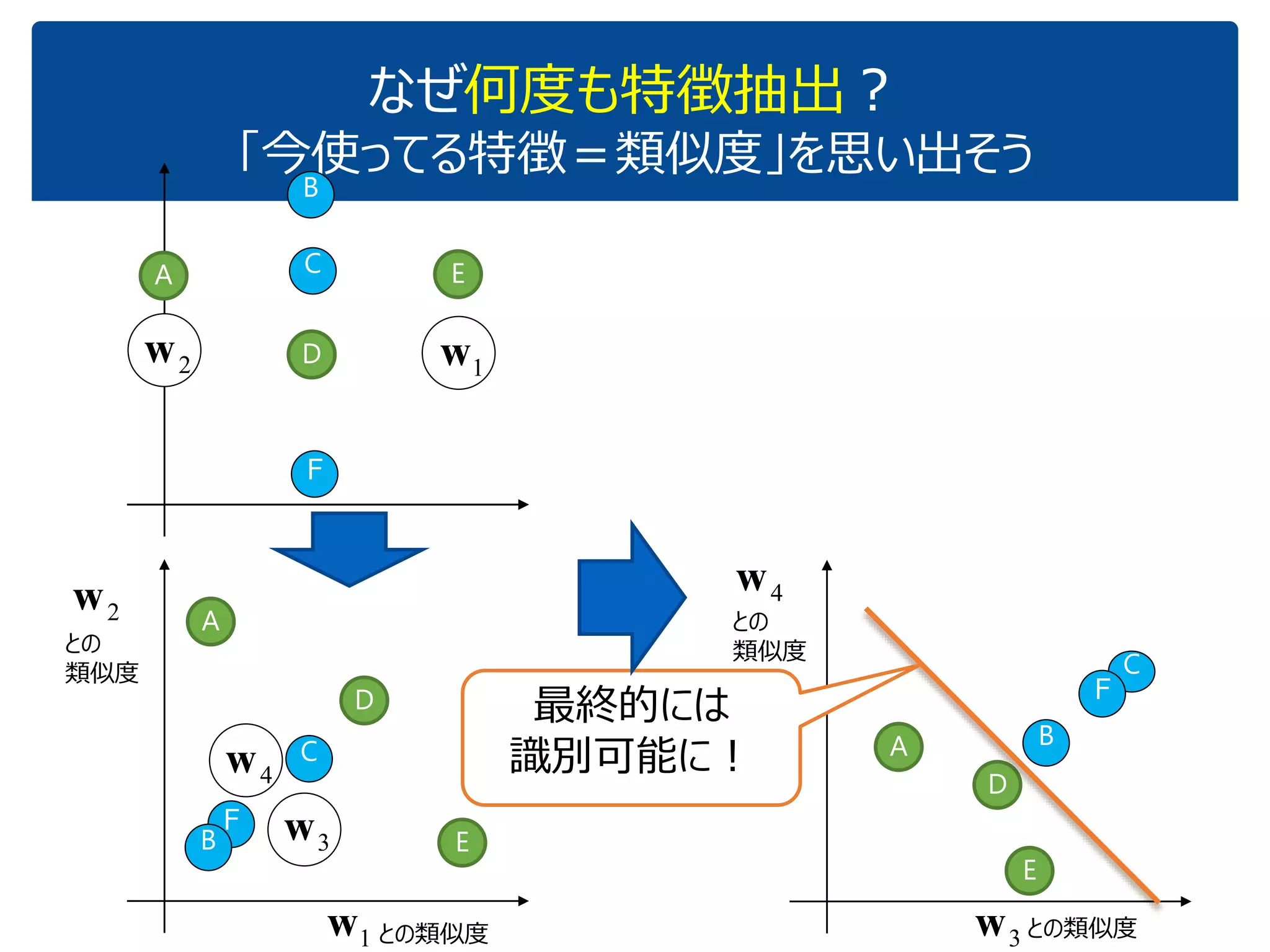
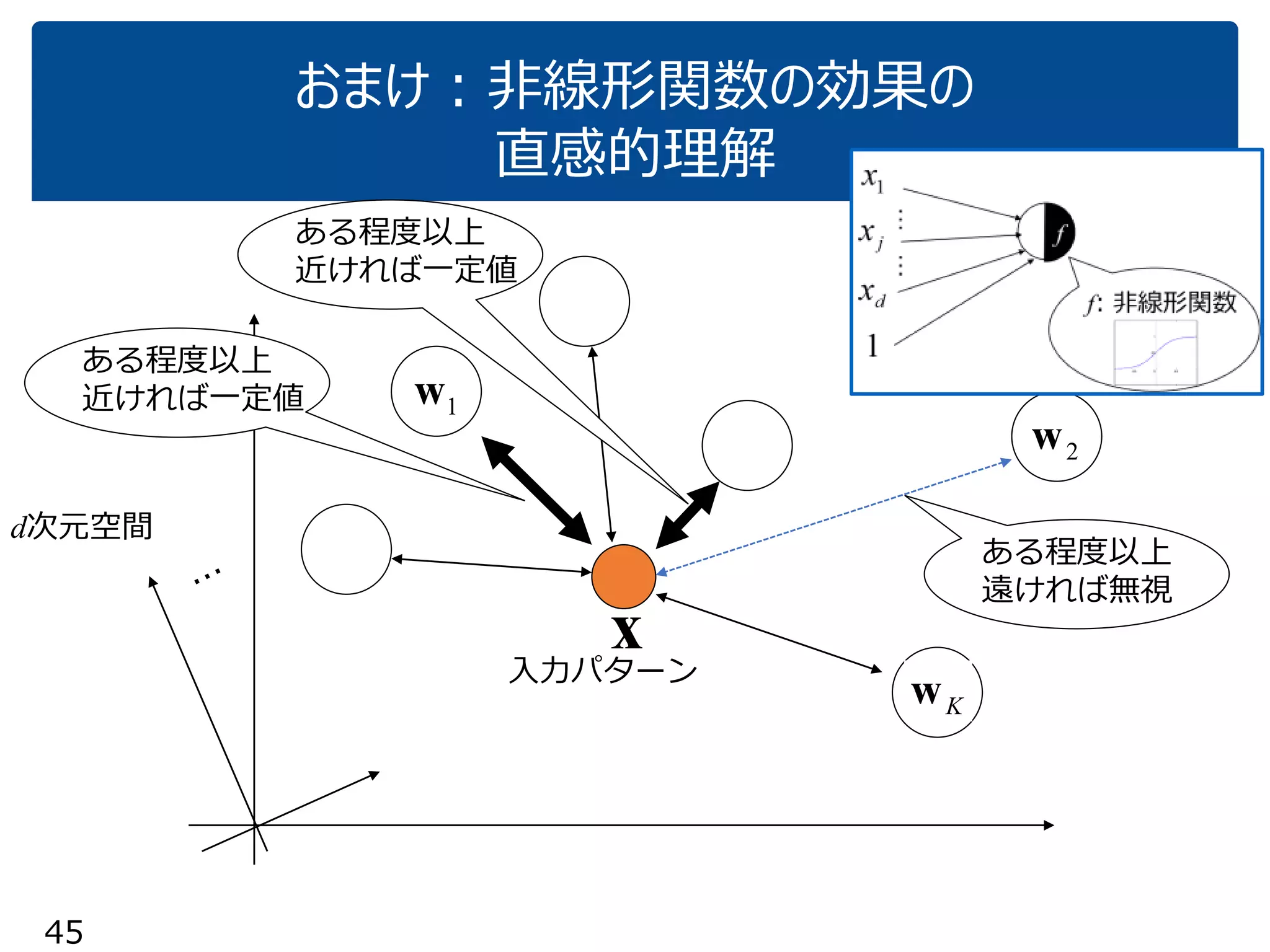
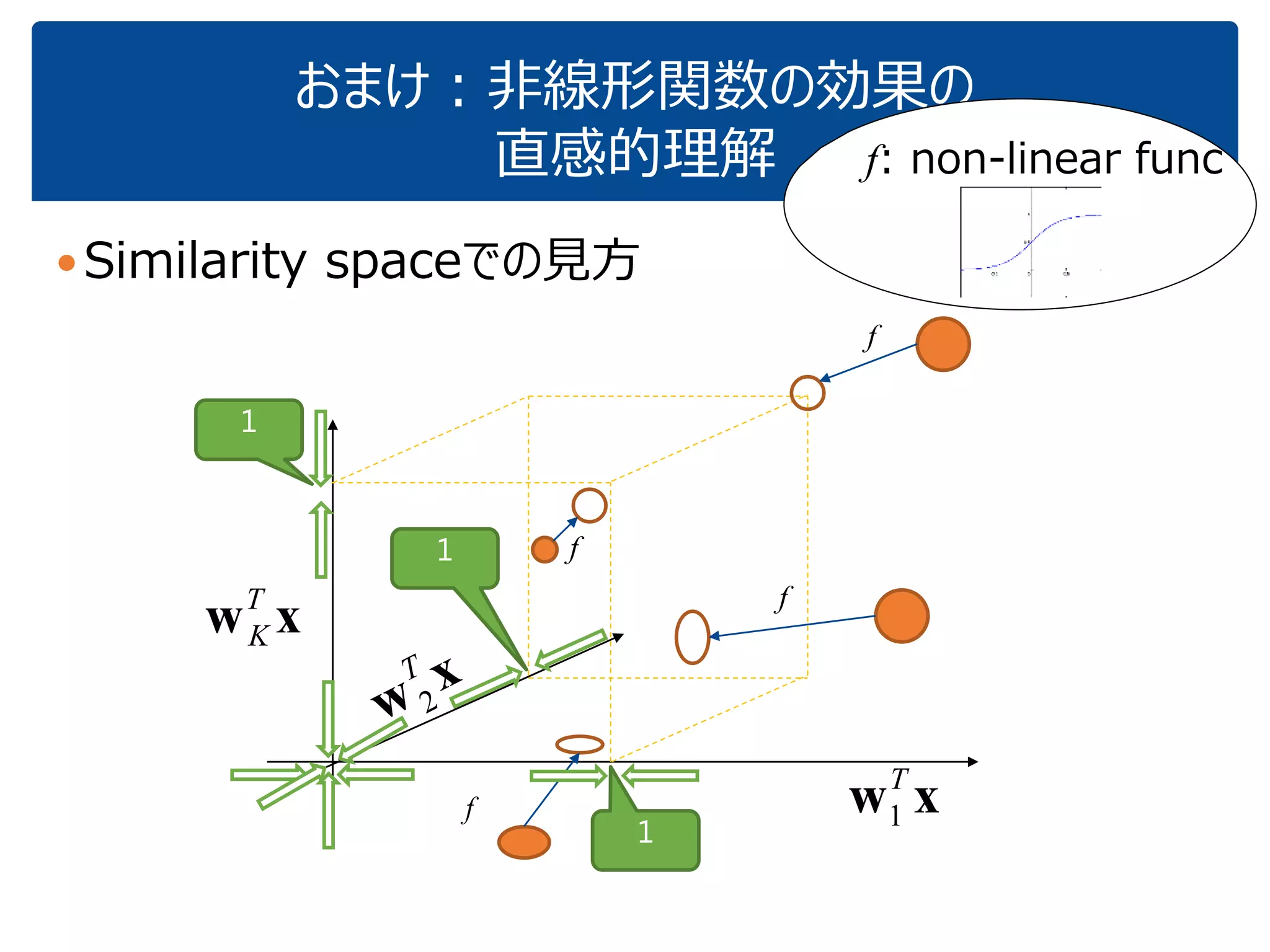
「『内積』を知っている人に,深層学習の中身がだいたいわかってもらう」ことを目指しています.これぐらいをスタートに,理解を深めていけばいいのではないかと思いました.ちなみに学習(例えばback propagationあたりの)の部分については,特に触れていません.それ以前の基本の部分です. (2017.1.28, 少々補足スライドをいれて,初学者向けにさらにわかりやすくしたつもりです.) なお,ここで出てくる数式は,せいぜい足し算と掛け算ぐらいです.






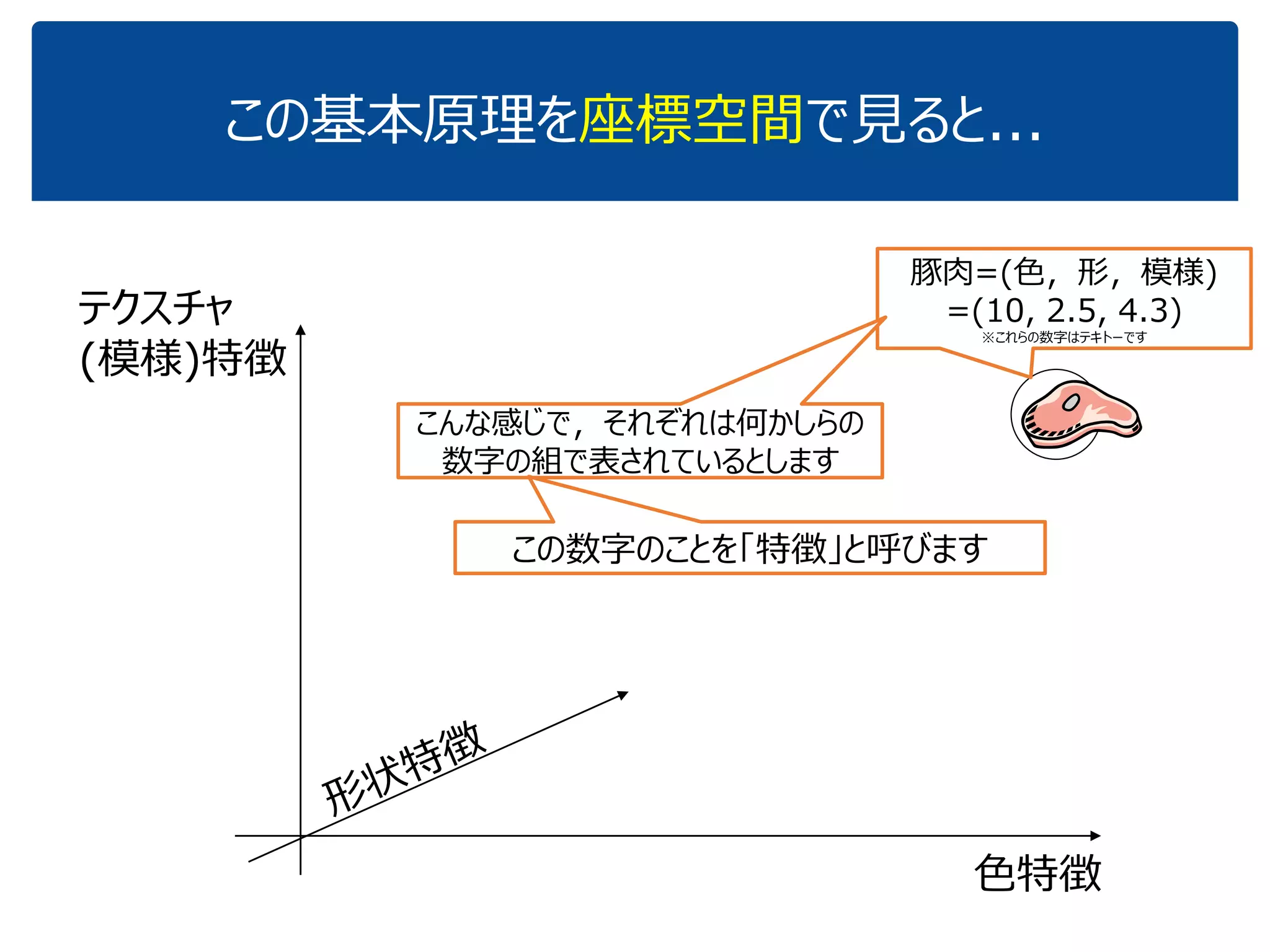
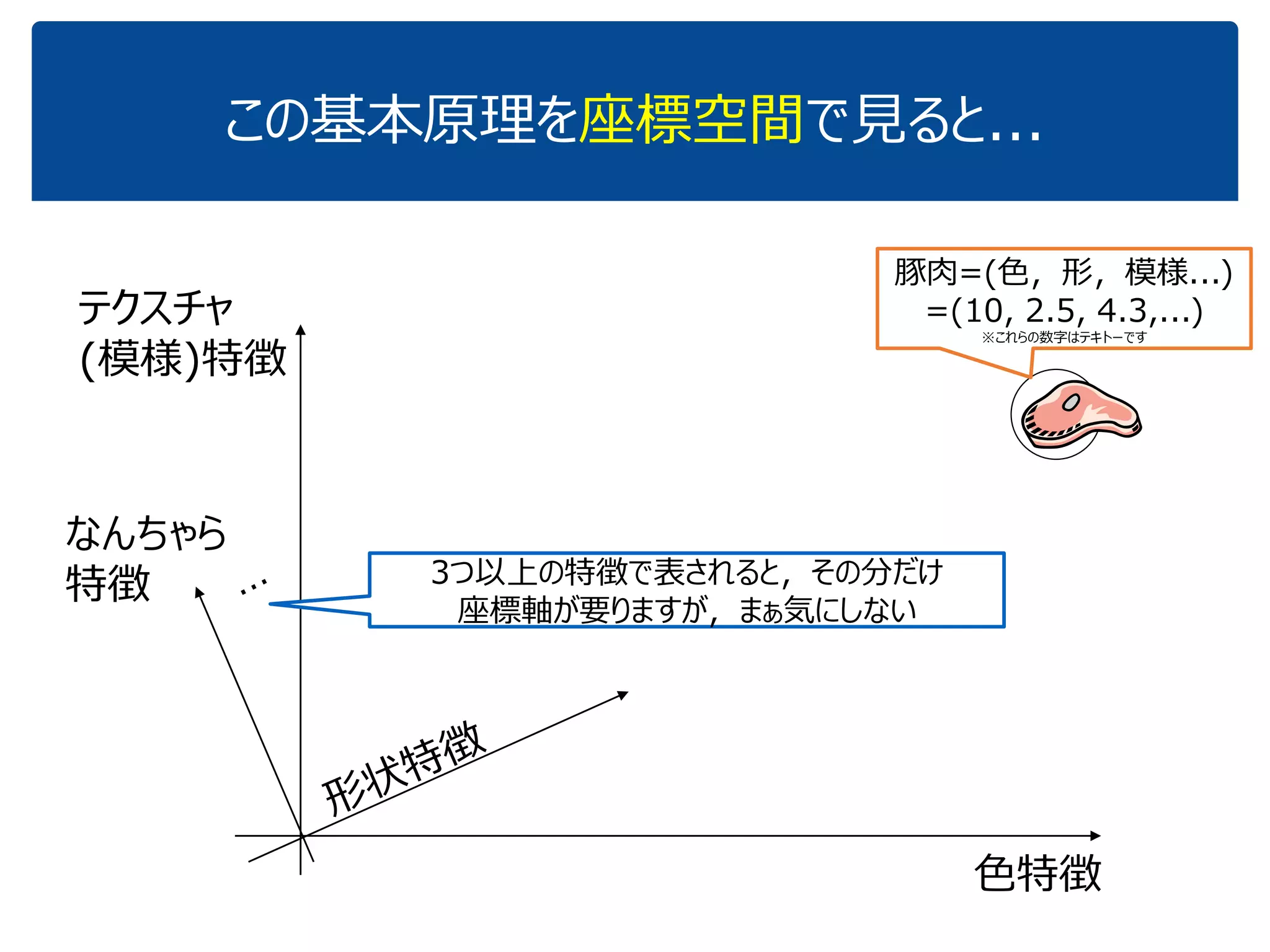
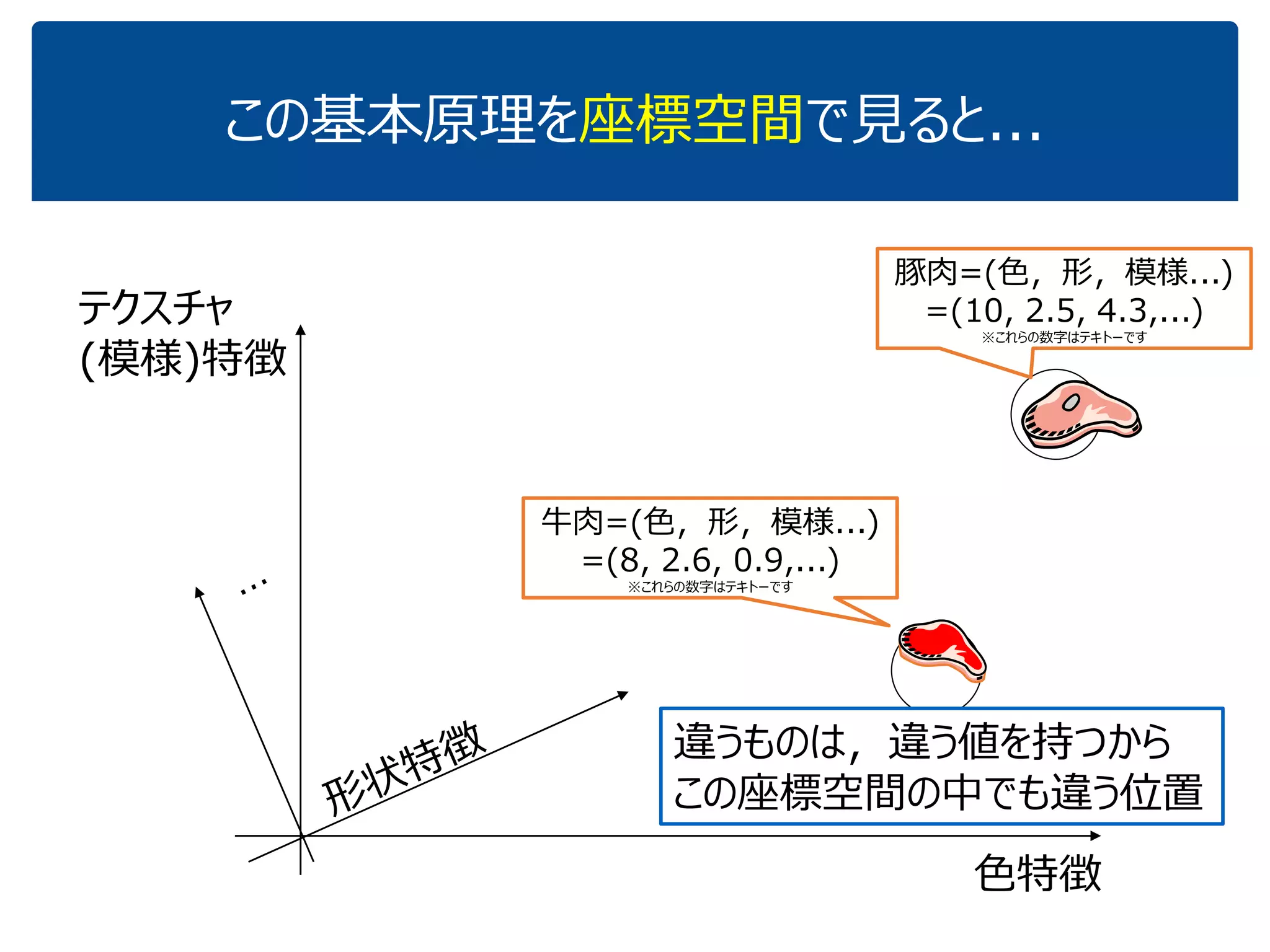
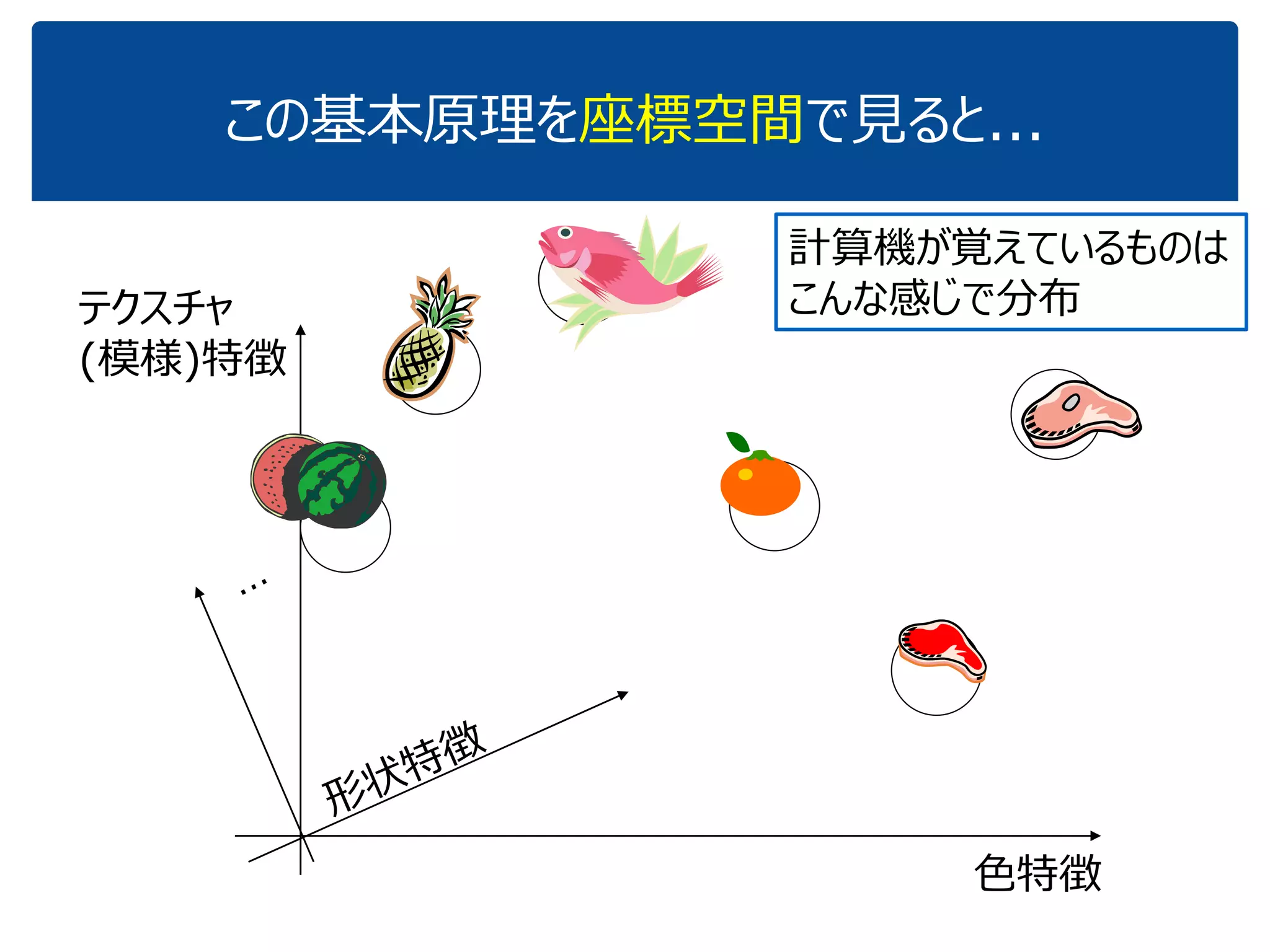








































![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)


































































