Download as PDF, PPTX








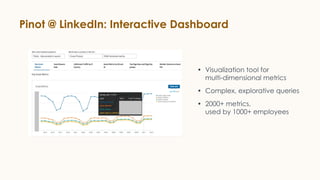






![Site Facing Analytics
select sum(articleViewCount) from T
where articleId = x
...
and time >= y time < z
group by viewer[title|geo|industry]
• Pre-defined queries with different
filtering values
• Usually have a filter on the primary key
(e.g. articleId)
• High QPS (thousands), low latency
(< 100ms for 99%) requirements](https://image.slidesharecdn.com/apacheconpinot-190911001418/85/Pinot-Enabling-Real-time-Analytics-Applications-LinkedIn-s-Scale-33-320.jpg)
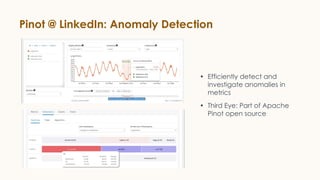
![Anomaly Detection
for d1 in [us, ca, ...]
for d2 in [chrome, firefox, ...]
...
select sum(pageViews) from T
where country = d1 and browser = d2…
group by time
Filter Aggregation
select …
where country = us …
Slow, scan 60-70% data
select …
where country = ireland …
Scan less than 1%
• Identifying issues requires monitoring
all possible combinations
• Data distribution can be skewed](https://image.slidesharecdn.com/apacheconpinot-190911001418/85/Pinot-Enabling-Real-time-Analytics-Applications-LinkedIn-s-Scale-34-320.jpg)
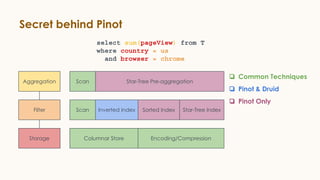

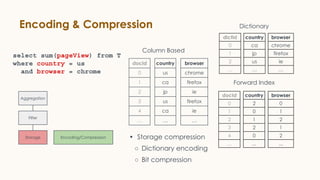

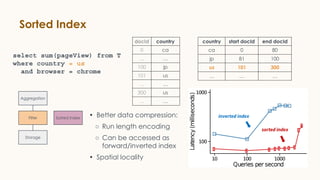
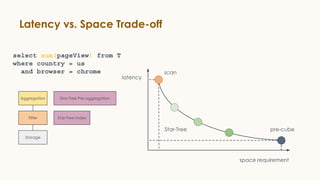
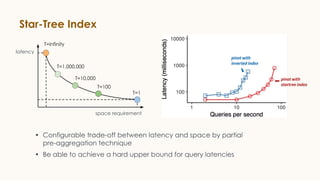

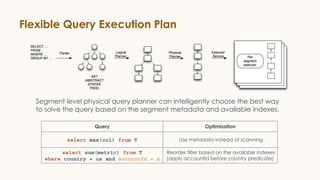




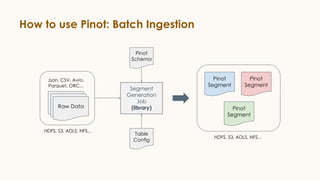
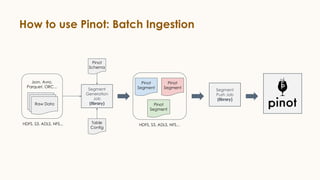
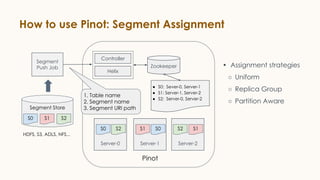
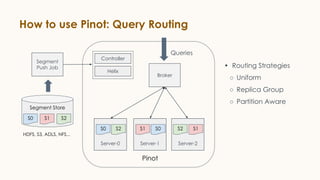
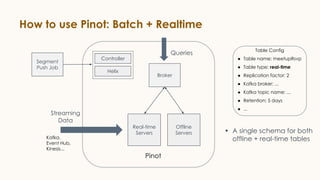
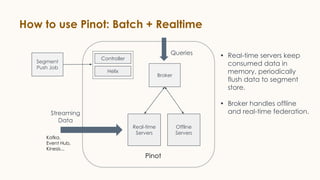
Pinot is an open source distributed OLAP data store designed for low latency analytics on large datasets. It is used at LinkedIn for various real-time analytics applications requiring sub-second latency on billions of events daily. Pinot uses a columnar data format, inverted indexes, encoding, and star tree indexes to enable fast filtering and aggregation. It also supports both batch and real-time ingestion from streaming data sources like Kafka.