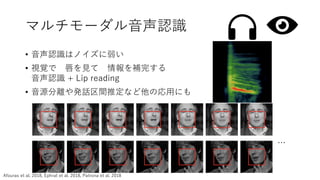
Visual QA (質問応答)
•画像を見て
参照される質問に答える
• 「What color is his umbrella?」
Antol et al. 2015, Das et al. 2017,
ECCV VisDial Challenge 2018
https://drive.google.com/file/d/1xSzg8mJYPNSRXtkCRpduefplrrUTe0PW/view
15.
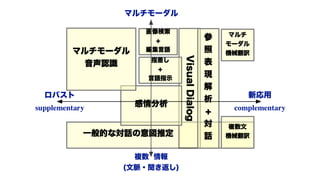
Visual Dialog
• VisualQAの対話版
• 画像と文脈の両方を見て
参照を理解する必要がある
• “What color is his umbrella?”
からの “What about hers?”
Das et al. 2017,
ECCV VisDial Challenge 2018
https://drive.google.com/file/d/1xSzg8mJYPNSRXtkCRpduefplrrUTe0PW/view
16.
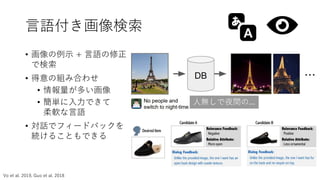
言語付き画像検索
• 画像の例示 +言語の修正
で検索
• 得意の組み合わせ
• 情報量が多い画像
• 簡単に入力できて
柔軟な言語
• 対話でフィードバックを
続けることもできる
Nam Vo1⇤
, Lu Jiang2
, Chen Sun2
, Kevin Murphy2
Li-Jia Li2,3
, Li Fei-Fei2,3
, James Hays1
1
Georgia Tech, 2
Google AI, 3
Stanford University
Abstract
y thetask of imageretrieval, where
fied in the form of an image plus
desired modifications to the input
may present an image of the Eiffel
em to find images which are visu-
dified in small ways, such as being
ad of during the day. To tackle this
y metric between a target imagexj
plus source text ti , i.e., a function
f com bine(xi , ti ) is some represen-
that thesimilarity ishigh iff xj isa Figure 1. Example of image retrieval using text and image query.
人無しで夜間の...
Vo et al. 2019, Guo et al. 2018
マルチモーダル言語理解
• 言語に表れていない情報をどう解釈する (e.g.“I”, 性, 多義, 構文, 省略)
• テキスト内の曖昧性を別のモダリティや文脈から推測する
Barzak et al. 2015, Barrault et al. 2018
I am ... Bill held the [green [chair and bag]]
Bill held the [green chair] and [bag]
19.
感情分析・強調
Hazarika et al.2018, Do et al. 2016
• ユニークですね → Positive? Negative?
• テキストとしての感情分析タスクの限界
• この部分はユニークですね
• 普通のテキストからは強調も落ちやすい
Reference
• Antol etal., “VQA: Visual Question Answering”, CVPR, 2015 https://visualqa.org/ https://arxiv.org/abs/1505.00468
• Alamri et al., “Audio Visual Scene-Aware Dialog”, arxiv, 2019 https://video-dialog.com/ https://arxiv.org/abs/1901.09107
• Afouras et al., “Deep Audio-Visual Speech Recognition”, TPAMI, 2018 https://arxiv.org/abs/1809.02108
• Baltrušaitis et al., “Multimodal Machine Learning: A Survey and Taxonomy”, TPAMI, 2018 https://ieeexplore.ieee.org/document/8269806
• Barrault, “Introduction to Multimodal Machine Translation”, 2018 https://www.clsp.jhu.edu/wp-content/uploads/sites/75/2018/06/2018-06-22-Barrault-Multimodal-
MT.pdf
• Chung et al., “The Multi-View Lip Reading Sentences dataset”, 2017 http://www.robots.ox.ac.uk/~vgg/data/lip_reading/
https://www.youtube.com/watch?v=xMznWUbWLOw
• Das et al., “Visual Dialog”, CVPR, 2017 https://visualdialog.org/challenge/2018 https://arxiv.org/abs/1611.08669
• Do et al., ”Transferring Emphasis in Speech Translation Using Hard-Attentional Neural Network Models”, InterSpeech, 2016
http://www.phontron.com/paper/do16isattention.pdf
• Ephrat et al., “Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation”, SIGGRAPH, 2018
https://arxiv.org/abs/1804.03619
• Goyal et al., “Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering”, CVPR, 2017 https://arxiv.org/abs/1612.00837
• Guo et al., “Dialog-based Interactive Image Retrieval”, NeurIPS, 2018 https://arxiv.org/abs/1805.00145
• Gupta et al., “Visual Features for Context-Aware Speech Recognition”, ICASSP, 2017 https://arxiv.org/abs/1712.00489
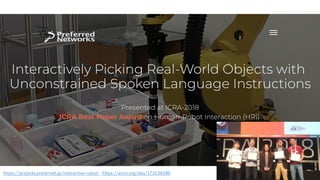
• Hatori et al., “Interactively Picking Real-World Objects with Unconstrained Spoken Language Instructions”, ICRA, 2018 https://projects.preferred.jp/interactive-robot/
https://arxiv.org/abs/1710.06280
• Hazarika et al., “Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos”, NAACL, 2018 https://www.aclweb.org/anthology/N18-1193
• Kafle et al., “Challenges and Prospects in Vision and Language Research”, arxiv, 2019 https://arxiv.org/abs/1904.09317
• Liang, “Cheap Tricks and the Perils of Machine Learning”, NAACL workshop, 2018 https://newgeneralization.github.io/slides/PercyLiang.pdf
• Naszadi et al., “Image-sensitive language modeling for automatic speech recognition”, ECCV workshop, 2018
http://openaccess.thecvf.com/content_ECCVW_2018/papers/11132/Naszadi_Image-
sensitive_language_modeling_for_automatic_speech_recognition_ECCVW_2018_paper.pdf
• Parikh, “Generalization "Opportunities" in Visual Question Answering”, NAACL workshop, 2018 https://newgeneralization.github.io/slides/DeviParikh.pptx
• Patrona et al., “Visual Voice Activity Detection in the Wild”, IEEE Transactions on Multimedia, 2016 https://ieeexplore.ieee.org/abstract/document/7420734
• Preferred Networks, “Autonomous Tidying-up Robot System”, CEATEC, 2018 https://projects.preferred.jp/tidying-up-robot/
• Sugawara et al., “What Makes Reading Comprehension Questions Easier?”, EMNLP, 2018 https://aclweb.org/anthology/D18-1453
• Vo et al., “Composing Text and Image for Image Retrieval - An Empirical Odyssey”, CVPR, 2019 https://arxiv.org/abs/1812.07119
• Berzak et al., “Do You See What I Mean? Visual Resolution of Linguistic Ambiguities”, EMNLP, 2015, https://www.aclweb.org/anthology/D15-1172
• Christiano et al., “Deep Reinforcement Learning from Human Preferences”, NIPS, 2017 https://arxiv.org/abs/1706.03741 https://youtu.be/oC7Cw3fu3gU
• Arakawa et al., “DQN-TAMER: Human-in-the-Loop Reinforcement Learning with Intractable Feedback”, ICRA workshop, 2019 https://arxiv.org/abs/1810.11748
• Co-Reyes et al., “Guiding Policies with Language via Meta-Learning”, ICLR, 2019 https://arxiv.org/abs/1811.07882
• [Materials] http://fukidesign.com/, https://iconmonstr.com/, https://pixabay.com/














![マルチモーダル言語理解
• 言語に表れていない情報をどう解釈する (e.g. “I”, 性, 多義, 構文, 省略)
• テキスト内の曖昧性を別のモダリティや文脈から推測する
Barzak et al. 2015, Barrault et al. 2018
I am ... Bill held the [green [chair and bag]]
Bill held the [green chair] and [bag]](https://image.slidesharecdn.com/os1-03-190610002505/85/SSII2019OS-18-320.jpg)



![Reference
• Antol et al., “VQA: Visual Question Answering”, CVPR, 2015 https://visualqa.org/ https://arxiv.org/abs/1505.00468
• Alamri et al., “Audio Visual Scene-Aware Dialog”, arxiv, 2019 https://video-dialog.com/ https://arxiv.org/abs/1901.09107
• Afouras et al., “Deep Audio-Visual Speech Recognition”, TPAMI, 2018 https://arxiv.org/abs/1809.02108
• Baltrušaitis et al., “Multimodal Machine Learning: A Survey and Taxonomy”, TPAMI, 2018 https://ieeexplore.ieee.org/document/8269806
• Barrault, “Introduction to Multimodal Machine Translation”, 2018 https://www.clsp.jhu.edu/wp-content/uploads/sites/75/2018/06/2018-06-22-Barrault-Multimodal-
MT.pdf
• Chung et al., “The Multi-View Lip Reading Sentences dataset”, 2017 http://www.robots.ox.ac.uk/~vgg/data/lip_reading/
https://www.youtube.com/watch?v=xMznWUbWLOw
• Das et al., “Visual Dialog”, CVPR, 2017 https://visualdialog.org/challenge/2018 https://arxiv.org/abs/1611.08669
• Do et al., ”Transferring Emphasis in Speech Translation Using Hard-Attentional Neural Network Models”, InterSpeech, 2016
http://www.phontron.com/paper/do16isattention.pdf
• Ephrat et al., “Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation”, SIGGRAPH, 2018
https://arxiv.org/abs/1804.03619
• Goyal et al., “Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering”, CVPR, 2017 https://arxiv.org/abs/1612.00837
• Guo et al., “Dialog-based Interactive Image Retrieval”, NeurIPS, 2018 https://arxiv.org/abs/1805.00145
• Gupta et al., “Visual Features for Context-Aware Speech Recognition”, ICASSP, 2017 https://arxiv.org/abs/1712.00489
• Hatori et al., “Interactively Picking Real-World Objects with Unconstrained Spoken Language Instructions”, ICRA, 2018 https://projects.preferred.jp/interactive-robot/
https://arxiv.org/abs/1710.06280
• Hazarika et al., “Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos”, NAACL, 2018 https://www.aclweb.org/anthology/N18-1193
• Kafle et al., “Challenges and Prospects in Vision and Language Research”, arxiv, 2019 https://arxiv.org/abs/1904.09317
• Liang, “Cheap Tricks and the Perils of Machine Learning”, NAACL workshop, 2018 https://newgeneralization.github.io/slides/PercyLiang.pdf
• Naszadi et al., “Image-sensitive language modeling for automatic speech recognition”, ECCV workshop, 2018
http://openaccess.thecvf.com/content_ECCVW_2018/papers/11132/Naszadi_Image-
sensitive_language_modeling_for_automatic_speech_recognition_ECCVW_2018_paper.pdf
• Parikh, “Generalization "Opportunities" in Visual Question Answering”, NAACL workshop, 2018 https://newgeneralization.github.io/slides/DeviParikh.pptx
• Patrona et al., “Visual Voice Activity Detection in the Wild”, IEEE Transactions on Multimedia, 2016 https://ieeexplore.ieee.org/abstract/document/7420734
• Preferred Networks, “Autonomous Tidying-up Robot System”, CEATEC, 2018 https://projects.preferred.jp/tidying-up-robot/
• Sugawara et al., “What Makes Reading Comprehension Questions Easier?”, EMNLP, 2018 https://aclweb.org/anthology/D18-1453
• Vo et al., “Composing Text and Image for Image Retrieval - An Empirical Odyssey”, CVPR, 2019 https://arxiv.org/abs/1812.07119
• Berzak et al., “Do You See What I Mean? Visual Resolution of Linguistic Ambiguities”, EMNLP, 2015, https://www.aclweb.org/anthology/D15-1172
• Christiano et al., “Deep Reinforcement Learning from Human Preferences”, NIPS, 2017 https://arxiv.org/abs/1706.03741 https://youtu.be/oC7Cw3fu3gU
• Arakawa et al., “DQN-TAMER: Human-in-the-Loop Reinforcement Learning with Intractable Feedback”, ICRA workshop, 2019 https://arxiv.org/abs/1810.11748
• Co-Reyes et al., “Guiding Policies with Language via Meta-Learning”, ICLR, 2019 https://arxiv.org/abs/1811.07882
• [Materials] http://fukidesign.com/, https://iconmonstr.com/, https://pixabay.com/](https://image.slidesharecdn.com/os1-03-190610002505/85/SSII2019OS-24-320.jpg)














![[DL輪読会]Experience Grounds Language](https://cdn.slidesharecdn.com/ss_thumbnails/20200515iwasawa-200515060537-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-01] 深層学習のための効率的なデータ収集と活用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-01-220607020740-e80781dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS2-01] イメージング最前線](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os2-1-220607020403-b550c379-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS1-01] AI時代のチームビルディング](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os1-01-220607015404-49188612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-03] 画像と点群を用いた、森林という広域空間のゾーニングと施業管理](https://cdn.slidesharecdn.com/ss_thumbnails/os3-04-210605062524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-02] BIM/CIMにおいて安価に点群を取得する目的とその利活用](https://cdn.slidesharecdn.com/ss_thumbnails/os3-03-210605062350-thumbnail.jpg?width=640&height=640&fit=bounds)