アクション認識
Khurram Soomro, AmirRoshan Zamir and Mubarak Shah, UCF101: A Dataset of 101 Human Action Classes From
Videos in The Wild., CRCV-TR-12-01, 2012.
6.
キャプション生成
J. Xu, T.Mei, T. Yao, and Y. Rui, MSR-VTT: A Large Video Description Dataset for Bridging Video and Language, in
CVPR, 2016, pp. 5288‒5296.
A black and
white horse
runs around.
7.
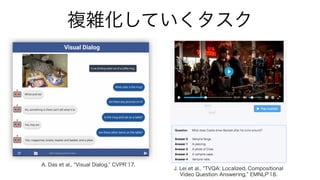
複雑化していくタスク
A. Das etal., Visual Dialog, CVPR 17.
J. Lei et al., TVQA: Localized, Compositional
Video Question Answering, EMNLP 18.
シンプルな画像識別タスク
Kinship verification:この二人が家族か当てる
J. P.Robinson, M. Shao, Y. Wu, H. Liu, T. Gillis, and Y. Fu, Visual Kinship Recognition of Families in the Wild, IEEE
Trans. Pattern Anal. Mach. Intell., vol. 40, no. 11, pp. 2624‒2637, 2018.
このタスクができる→顔の複雑な特徴の認識ができているはず!
11.
データに意図しないバイアス
M. Dawson, A.Zisserman, C. Nellaker, "From Same Photo: Cheating on Visual Kinship Challenges," Asian
Conference on Computer Vision, 2018
背景・照明環境などが強力なヒントとして潜在
2 M. Dawson et al.
Fig. 1. Representative examples of how cropping face images from the same original
photo can make the kinship verification a trivial task. Confounding, non–kinship infor-
mation includes camera specific noise, the background similarity (A,C), the historical
言語(質問文・回答)に大きな偏り
Y. Goyal, T.Khot, D. Summers-Stay, D. Batra, and D. Parikh, Making the v in VQA Matter: Elevating the Role of
Image Understanding in Visual Question Answering, in CVPR, 2017.
偏りのあるデータで学習すると
A. Agrawal, D.Batra, and D. Parikh, Analyzing the Behavior of Visual Question Answering Models, in EMNLP, 2016,
pp. 1955‒1960.
QとAの対応だけ学習
画像を見ないで回答してるかも
• (特に出力が言語だと)なにか賢いシステムができているように見える
• 結果を細かく分析することが重要
※全てがこれで説明できるわけではない
17.
さらに複雑な意味理解タスクでは?
映像要約(自動編集):
長い動画から自動で重要な箇所を抜き出して短い
動画を作成
このタスクができる→動画中のイベントの重要度
を判定できているはず!
M. Otani etal., Rethinking the Evaluation of Video Summaries, CVPR 19.
Mayu Otani
CyberAgent, Inc.
Yuta Nakashima
Osaka University
Esa Rahtu
Tampere University
Janne Hei
University o
Abstract
Video summarization is a technique to create a short
skim of the original video while preserving the main sto-
ries/content. There exists a substantial interest in automa-
tizing this process due to the rapid growth of the available
material. The recent progress has been facilitated by public
benchmark datasets, which enable easy and fair compari-
son of methods. Currently the established evaluation proto-
col is to compare the generated summary with respect to a
set of reference summaries provided by the dataset. In this
paper, we will provide in-depth assessment of this pipeline
using two popular benchmark datasets. Surprisingly, we
observe that randomly generated summaries achieve com-
parable or better performance to the state-of-the-art. In
some cases, the random summaries outperform even the
human generated summaries in leave-one-out experiments.
Moreover, it turns out that the video segmentation, which is
Importance Score Prediction
Video Segmentation
Segment Selection
Interestingness
Representativeness
etc.
動画像にはどんな意図がある?
たとえば、動画の中の人(キャラクター)の行動の意図
Q. Why isCastle vexed after he read the note?
J. Lei et al., TVQA: Localized, Compositional
Video Question Answering, EMNLP 18.
Why is pointing at ?
R. Zellers et al., From Recognition to Cognition:
Visual Commonsense Reasoning, EMNLP 18.
質問応答の問題として研究が出てきている

























![[DL輪読会]Efficient Video Generation on Complex Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20190823dvd-ganlast-190826093116-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)










