Downloaded 90 times



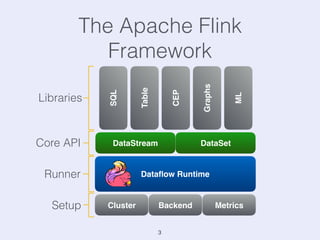
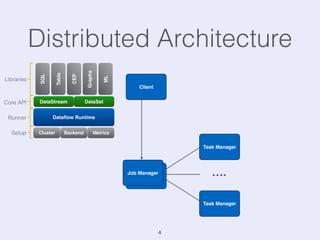
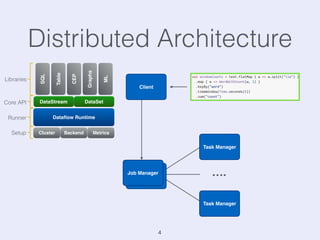
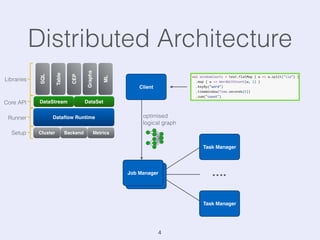
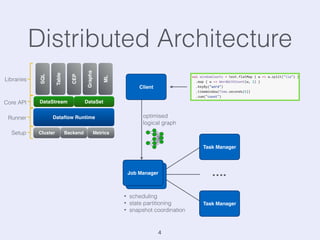
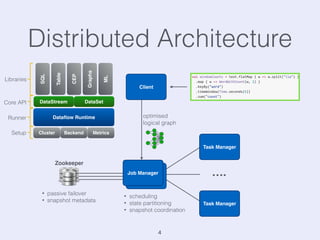
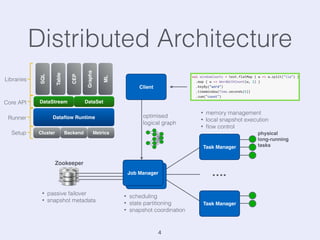
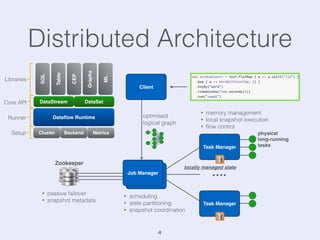
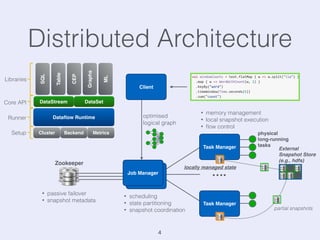
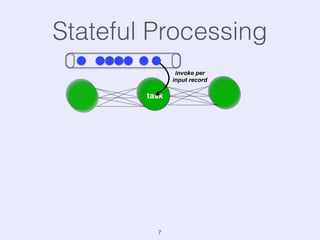
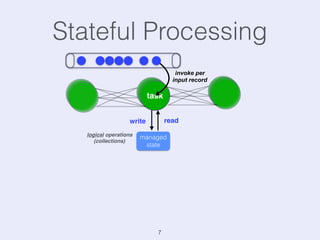
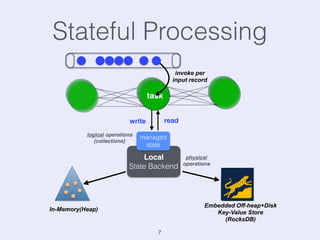
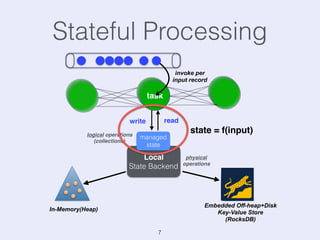

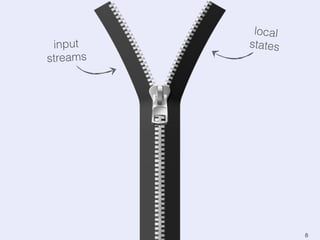
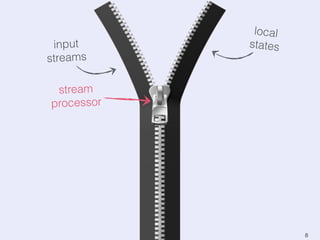
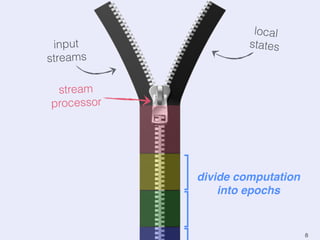
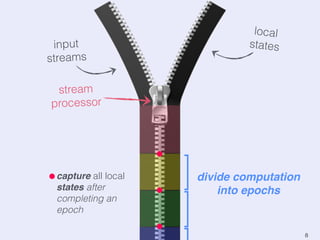
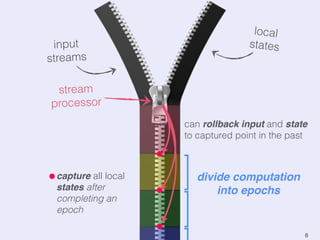
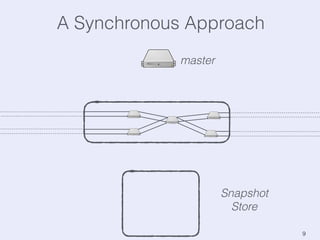
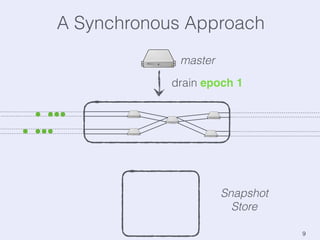
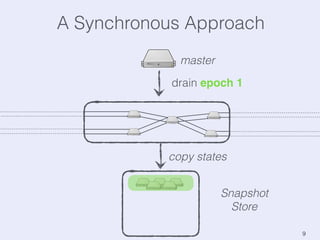
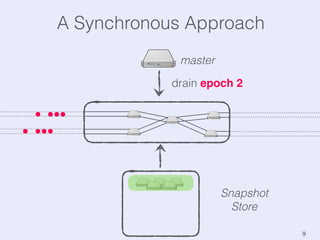
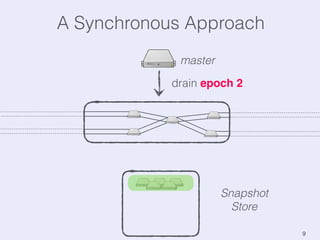
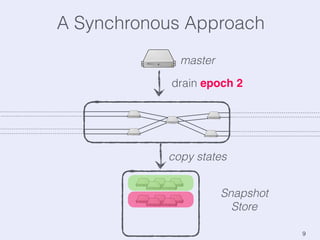

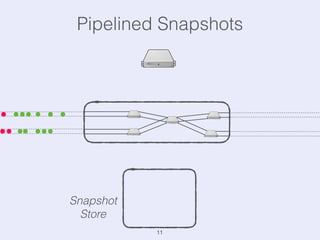
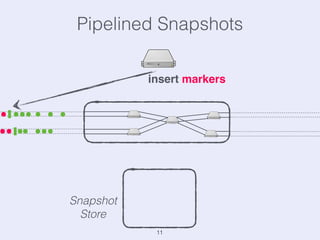
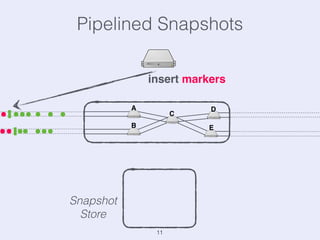
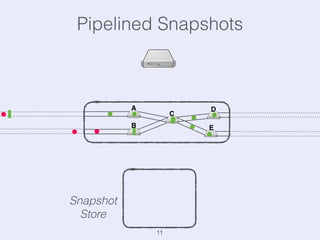
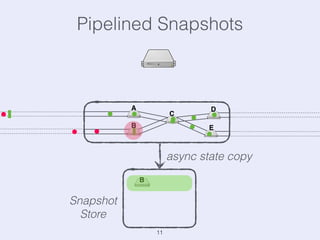
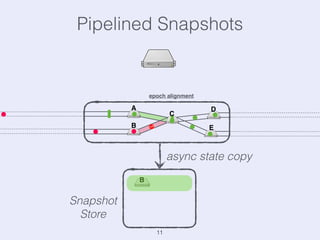
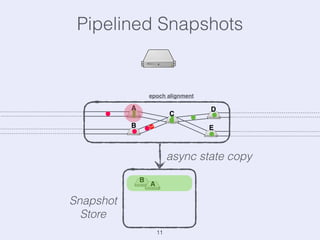
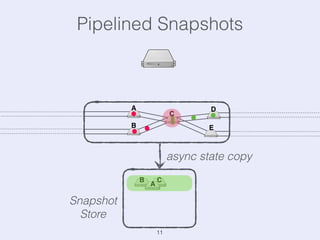
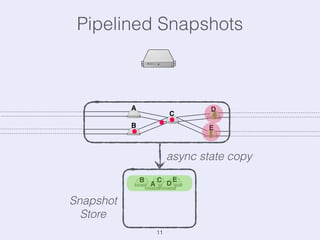
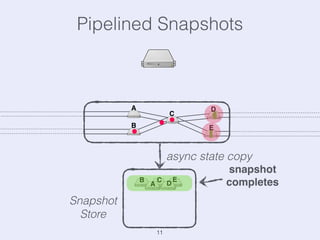
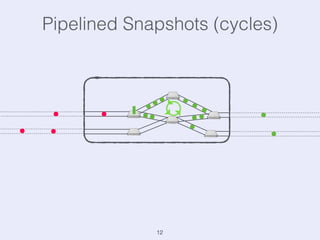
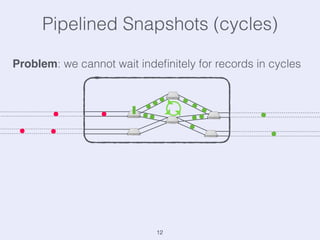
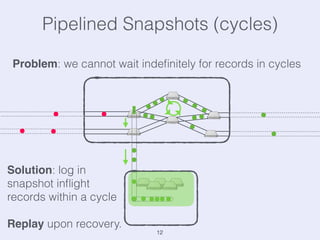

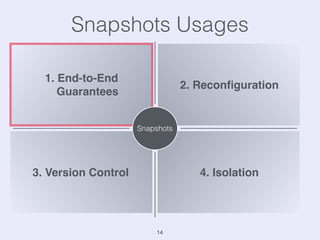

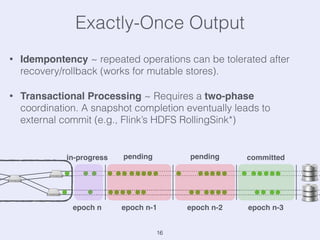
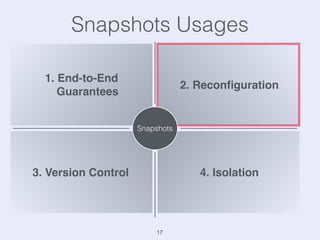


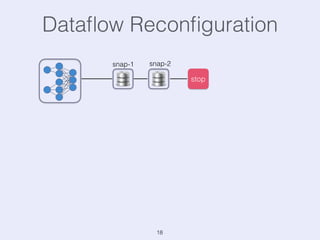
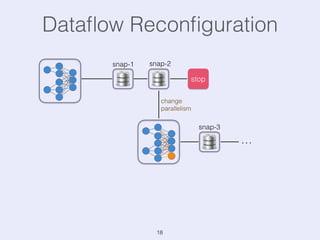
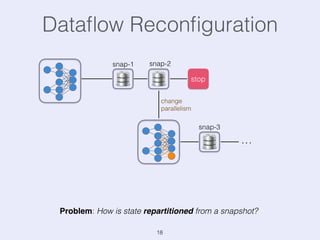

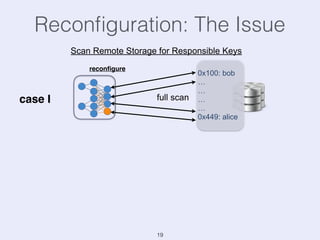
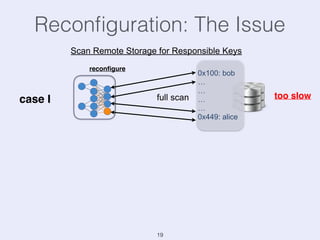
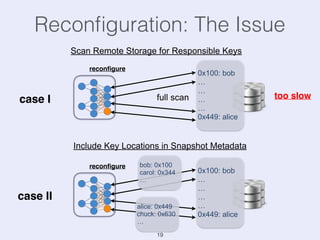
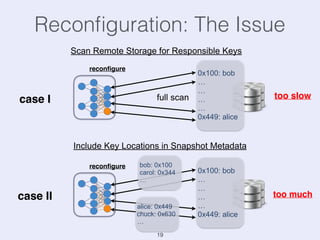
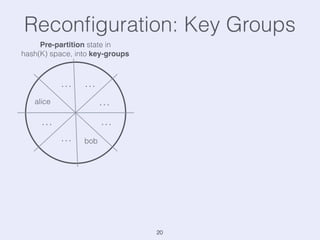
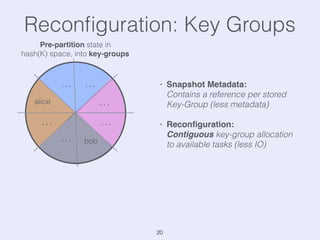
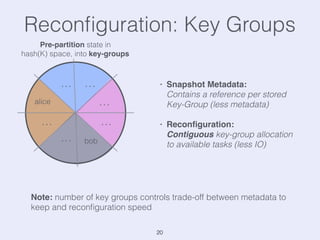


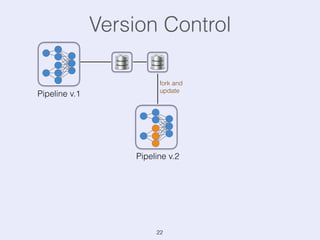
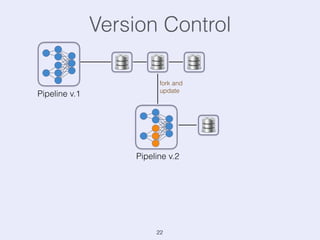
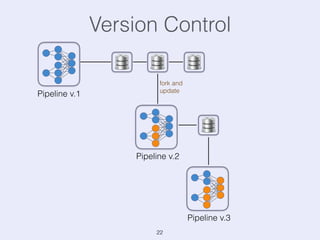
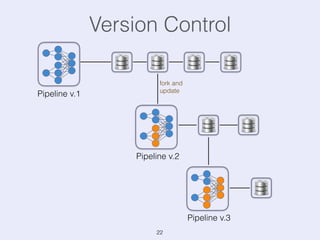
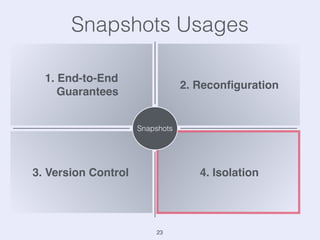
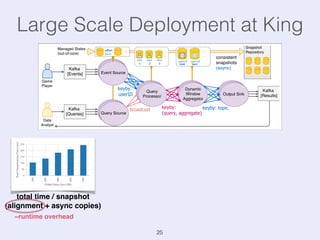
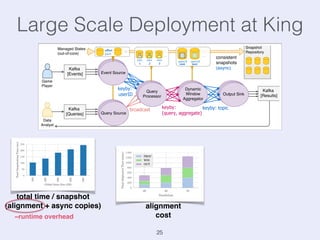
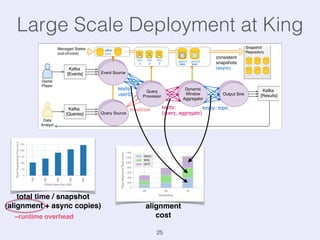
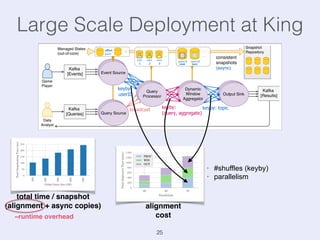



The document presents an overview of state management in Apache Flink, focusing on consistent stateful distributed stream processing. It covers topics such as the system architecture, pipelined consistent snapshots, and operations with snapshots aimed at large-scale deployments. Additionally, it discusses the implications of state reconfiguration, version control, and the importance of maintaining end-to-end processing guarantees.














































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)

