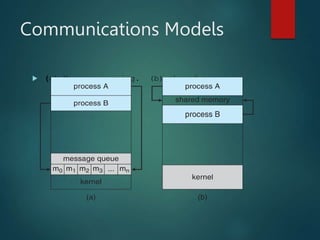
The document discusses inter-process communication (IPC) in operating systems, detailing the importance of IPC for cooperating processes through shared memory and message passing mechanisms. It examines the producer-consumer problem and outlines both direct and indirect communication methods, along with synchronization, buffering, and threading concepts. Additionally, it presents advantages of multithreading, including improved responsiveness, resource sharing, and scalability.








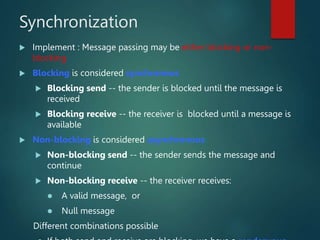
![Bounded-Buffer – Shared-
Memory Solution
Shared data
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item buffer[BUFFER_SIZE];
int in = 0;#if free one process enter in
int out = 0;# one process comes out and
becomes NULL
Solution is correct, but can only use BUFFER_SIZE-1 elements](https://image.slidesharecdn.com/inter-processcommunicationinoperatingsystem-231102073525-0d5bcfb4/85/Inter-Process-communication-in-Operating-System-ppt-10-320.jpg)
![Bounded-Buffer – Producer
item next_produced;
while (true) {
/* produce an item in next produced */
while (((in + 1) % BUFFER_SIZE) == out)
; /* do nothing */
buffer[in] = next_produced; #next new item
is stored
in = (in + 1) % BUFFER_SIZE;
}](https://image.slidesharecdn.com/inter-processcommunicationinoperatingsystem-231102073525-0d5bcfb4/85/Inter-Process-communication-in-Operating-System-ppt-11-320.jpg)
![Bounded Buffer – Consumer
item next_consumed;
while (true) {
while (in == out)
; /* do nothing */
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
/* consume the item in next
consumed */
}](https://image.slidesharecdn.com/inter-processcommunicationinoperatingsystem-231102073525-0d5bcfb4/85/Inter-Process-communication-in-Operating-System-ppt-12-320.jpg)