Downloaded 22 times


![Matched (Molecular) Pairs
[Cl, F]1.6
3.5
Coined by Kenny and Sadowski in 2005*
Easier to predict differences in the values of a property
than it is to predict the value itself
* Chemoinformatics in drug discovery, Wiley, 271–285.](https://image.slidesharecdn.com/visualizationmatsy-150825090607-lva1-app6892/85/CINF-29-Visualization-and-manipulation-of-Matched-Molecular-Series-for-decision-support-2-320.jpg)

![Matched Series of length 2
= Matched Pair
[Cl, F]
“Matching molecular series” introduced by Wawer and
Bajorath, J. Med. Chem. 2011, 54, 2944](https://image.slidesharecdn.com/visualizationmatsy-150825090607-lva1-app6892/85/CINF-29-Visualization-and-manipulation-of-Matched-Molecular-Series-for-decision-support-4-320.jpg)
![Matched Series of length 3
[Cl, F, NH2]](https://image.slidesharecdn.com/visualizationmatsy-150825090607-lva1-app6892/85/CINF-29-Visualization-and-manipulation-of-Matched-Molecular-Series-for-decision-support-5-320.jpg)
![Ordered Matched Series of length 3
3.5
2.1
1.6
pIC50
[Cl > F > NH2]](https://image.slidesharecdn.com/visualizationmatsy-150825090607-lva1-app6892/85/CINF-29-Visualization-and-manipulation-of-Matched-Molecular-Series-for-decision-support-6-320.jpg)


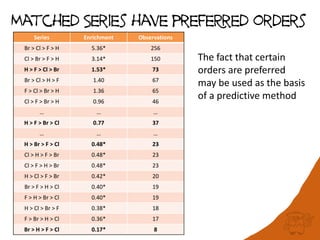
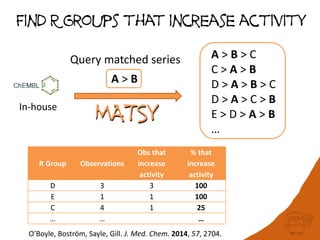



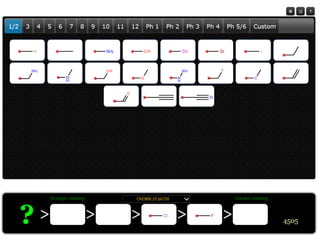




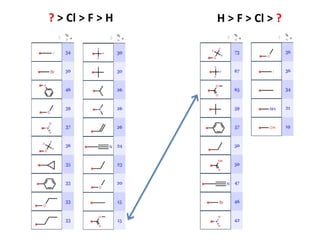



The document discusses the visualization and manipulation of matched molecular series to aid decision support in drug discovery. It explores the concept of matched pairs and series, highlights their application in predicting physicochemical property changes, and discusses a dataset-centric approach for generating predictions based on molecular activities. The proposed visual interface aims to encourage exploration and hypothesis generation while addressing the limitations of traditional matched pair methodologies.

































































![RDKit: Six Not-So-Easy Pieces [RDKit UGM 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/rdkittautomersbasel16-161031122400-thumbnail.jpg?width=640&height=640&fit=bounds)















![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)




