Downloaded 282 times






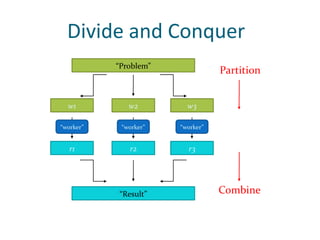




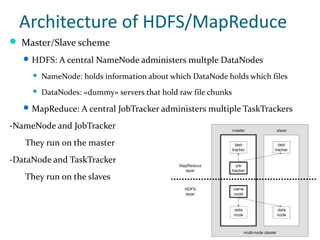








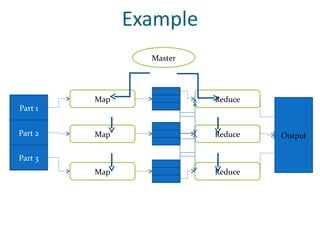
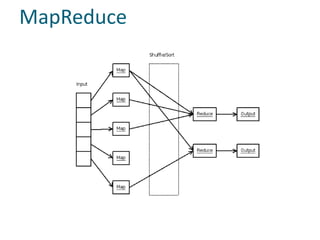


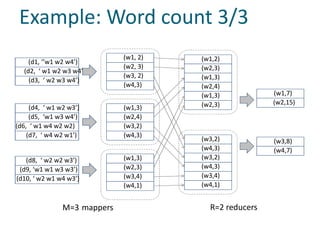













The document discusses Hadoop and MapReduce, illustrating their relevance in managing and processing large volumes of data generated at an unprecedented rate. It details the architecture of Hadoop, which consists of the Hadoop Distributed File System (HDFS) and the MapReduce programming model, as well as how tasks are distributed and executed across multiple nodes. Additionally, it provides examples of practical applications and use cases, emphasizing Hadoop's scalability and efficiency for parallelized data processing.














































































