Download to read offline



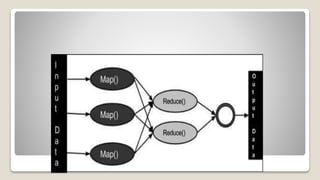


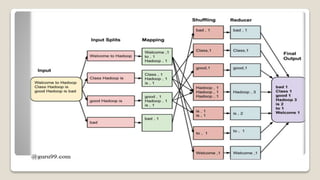
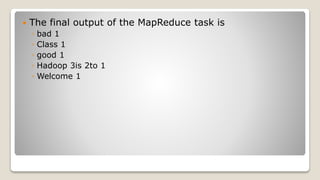


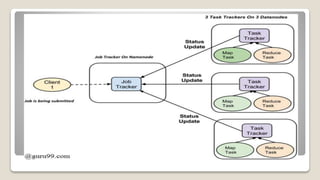


MapReduce is a programming model used for processing large datasets in a distributed computing environment. It consists of two main tasks - the Map task which converts input data into intermediate key-value pairs, and the Reduce task which combines these intermediate pairs into a smaller set of output pairs. The MapReduce framework operates on input and output in the form of key-value pairs, with the keys and values implemented as serializable Java objects. It divides jobs into map and reduce tasks executed in parallel on a cluster, with a JobTracker coordinating task assignment and tracking progress.










































































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)










