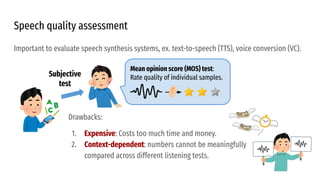
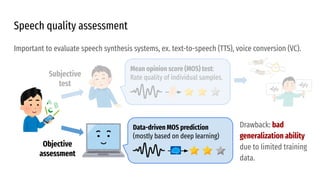
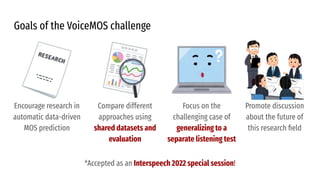
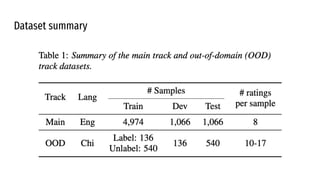
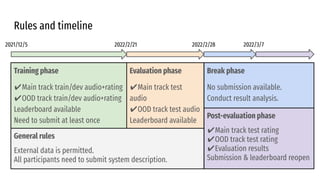
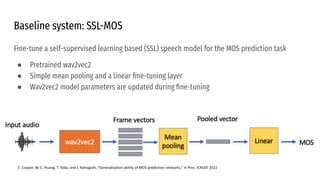
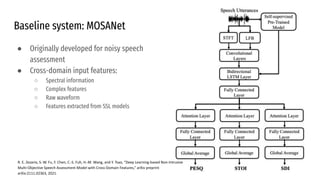
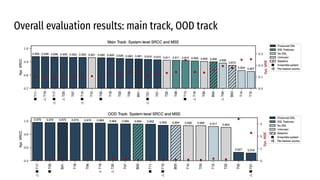
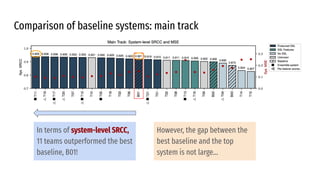
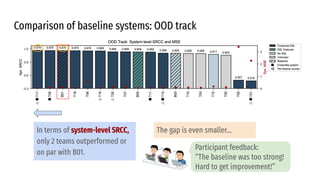
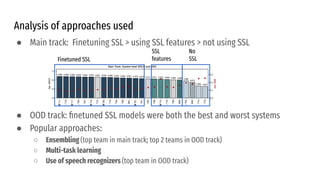
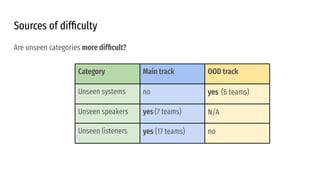
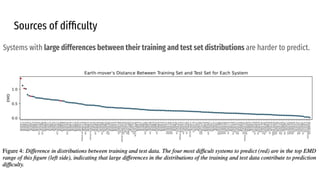
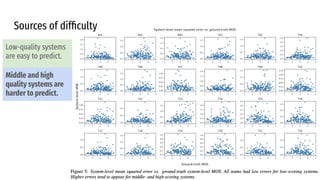
The VoiceMOS Challenge 2022 aimed to encourage research in automatic prediction of mean opinion scores (MOS) for speech quality. It featured two tracks evaluating systems' ability to predict MOS ratings from a large existing dataset or a separate listening test. 21 teams participated in the main track and 15 in the out-of-domain track. Several teams outperformed the best baseline, which fine-tuned a self-supervised model, though the top-performing approaches generally involved ensembling or multi-task learning. While unseen systems were predictable, unseen listeners and speakers remained a difficulty, especially for generalizing to a new test. The challenge highlighted progress in MOS prediction but also the need for metrics reflecting both ranking and absolute accuracy








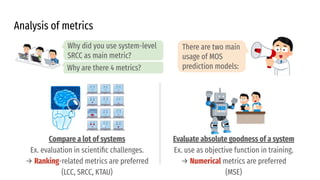
![Evaluation metrics
System-level and Utterance-level
● Mean Squared Error (MSE): difference between predicted and actual MOS
● Linear Correlation Coefficient (LCC): a basic correlation measure
● Spearman Rank Correlation Coefficient (SRCC): non-parametric; measures ranking order
● Kendall Tau Rank Correlation (KTAU): more robust to errors
import numpy as np
import scipy.stats
# `true_mean_scores` and `predict_mean_scores` are both 1-d numpy arrays.
MSE = np.mean((true_mean_scores - predict_mean_scores)**2)
LCC = np.corrcoef(true_mean_scores, predict_mean_scores)[0][1]
SRCC = scipy.stats.spearmanr(true_mean_scores, predict_mean_scores)[0]
KTAU = scipy.stats.kendalltau(true_mean_scores, predict_mean_scores)[0]
Following prior work, we
picked system-level SRCC as
the main evaluation metric.](https://image.slidesharecdn.com/thevoicemoschallenge2022-220323073026/85/The-VoiceMOS-Challenge-2022-13-320.jpg)






![[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP](https://cdn.slidesharecdn.com/ss_thumbnails/dlwav2clip1-211105022837-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































