Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
MY
Uploaded by
Masaki Yamakawa
PDF, PPTX
320 views
20211118 dbts2021 マイクロサービスにおけるApache Geodeの効果的な使い方
2021/11/18 db tech showcase 2021での発表資料
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 53
2
/ 53
3
/ 53
4
/ 53
5
/ 53
6
/ 53
7
/ 53
8
/ 53
9
/ 53
10
/ 53
11
/ 53
12
/ 53
13
/ 53
14
/ 53
15
/ 53
16
/ 53
17
/ 53
18
/ 53
19
/ 53
20
/ 53
21
/ 53
22
/ 53
23
/ 53
24
/ 53
25
/ 53
26
/ 53
27
/ 53
28
/ 53
29
/ 53
30
/ 53
31
/ 53
32
/ 53
33
/ 53
34
/ 53
35
/ 53
36
/ 53
37
/ 53
38
/ 53
39
/ 53
40
/ 53
41
/ 53
42
/ 53
43
/ 53
44
/ 53
45
/ 53
46
/ 53
47
/ 53
48
/ 53
49
/ 53
50
/ 53
51
/ 53
52
/ 53
53
/ 53
More Related Content
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
PPTX
Real Time analytics with Druid, Apache Spark and Kafka
by
Daria Litvinov
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
PDF
Hadoop and Kerberos
by
Yuta Imai
PDF
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
PDF
Apache Kafka - Martin Podval
by
Martin Podval
PPTX
A visual introduction to Apache Kafka
by
Paul Brebner
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
Real Time analytics with Druid, Apache Spark and Kafka
by
Daria Litvinov
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
Hadoop and Kerberos
by
Yuta Imai
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
Apache Kafka - Martin Podval
by
Martin Podval
A visual introduction to Apache Kafka
by
Paul Brebner
What's hot
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
超高速処理とスケーラビリティを両立するApache GEODE
by
Masaki Yamakawa
PDF
グラフデータベース:Neo4j、そしてRDBからの移行手順の紹介
by
ippei_suzuki
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
20191115-PGconf.Japan
by
Kohei KaiGai
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PPTX
Hive + Tez: A Performance Deep Dive
by
DataWorks Summit
PPTX
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
PDF
【第26回Elasticsearch勉強会】Logstashとともに振り返る、やっちまった事例ごった煮
by
Hibino Hisashi
PDF
そんなトランザクションマネージャで大丈夫か?
by
takezoe
PDF
Cassandra Introduction & Features
by
DataStax Academy
PPTX
Real-Time Data Flows with Apache NiFi
by
Manish Gupta
PDF
containerdの概要と最近の機能
by
Kohei Tokunaga
PDF
Spark (Structured) Streaming vs. Kafka Streams
by
Guido Schmutz
PPTX
File Format Benchmark - Avro, JSON, ORC & Parquet
by
DataWorks Summit/Hadoop Summit
PDF
TLS 1.3 と 0-RTT のこわ〜い話
by
Kazuho Oku
PDF
Introduction to Spark with Python
by
Gokhan Atil
PPTX
Apache NiFi in the Hadoop Ecosystem
by
DataWorks Summit/Hadoop Summit
PPTX
Securing Hadoop with Apache Ranger
by
DataWorks Summit
PDF
SSHパケットの復号ツールを作ろう_v1(Decrypt SSH .pcap File)
by
Tetsuya Hasegawa
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
超高速処理とスケーラビリティを両立するApache GEODE
by
Masaki Yamakawa
グラフデータベース:Neo4j、そしてRDBからの移行手順の紹介
by
ippei_suzuki
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
20191115-PGconf.Japan
by
Kohei KaiGai
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
Hive + Tez: A Performance Deep Dive
by
DataWorks Summit
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
【第26回Elasticsearch勉強会】Logstashとともに振り返る、やっちまった事例ごった煮
by
Hibino Hisashi
そんなトランザクションマネージャで大丈夫か?
by
takezoe
Cassandra Introduction & Features
by
DataStax Academy
Real-Time Data Flows with Apache NiFi
by
Manish Gupta
containerdの概要と最近の機能
by
Kohei Tokunaga
Spark (Structured) Streaming vs. Kafka Streams
by
Guido Schmutz
File Format Benchmark - Avro, JSON, ORC & Parquet
by
DataWorks Summit/Hadoop Summit
TLS 1.3 と 0-RTT のこわ〜い話
by
Kazuho Oku
Introduction to Spark with Python
by
Gokhan Atil
Apache NiFi in the Hadoop Ecosystem
by
DataWorks Summit/Hadoop Summit
Securing Hadoop with Apache Ranger
by
DataWorks Summit
SSHパケットの復号ツールを作ろう_v1(Decrypt SSH .pcap File)
by
Tetsuya Hasegawa
Similar to 20211118 dbts2021 マイクロサービスにおけるApache Geodeの効果的な使い方
PDF
MongoDB概要:金融業界でのMongoDB
by
ippei_suzuki
PDF
事例から見るNoSQLの使い方 - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
PDF
20170714_MySQL 5.7 GIS(地理情報システム) by 日本オラクル株式会社 MySQL GBU 山﨑由章
by
Insight Technology, Inc.
PDF
NoSQLデータベースと位置情報
by
Koji Ichiwaki
PDF
日本発オープンソース!! スケールアウト型データベース GridDB入門 ~ GitHubからダウンロードして使ってみましょう ~
by
griddb
PDF
Apache Drill を利用した実データの分析
by
MapR Technologies Japan
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
PDF
Apache Drill で JSON 形式の オープンデータを分析してみる - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
PPTX
BIM/CIMにおける3D-GIS・IoTの役割と展望
by
Koji Makanae
PPTX
Apache Geode で始める Spring Data Gemfire
by
Akihiro Kitada
PDF
日本生態学会第65回全国大会 自由集会01 地理情報へのDeep Learning活用の可能性と、学習データセットに求められる要件
by
Kunihiko Miyoshi
PDF
Apache drillを業務利用してみる(までの道のり)
by
Keigo Suda
PDF
20180217 hackertackle geode
by
Masaki Yamakawa
PDF
MySQL 8.0で強化されたGIS機能のご紹介:「FOSS4G 2018 Hokkaido」での発表資料
by
yoyamasaki
PDF
Geode meetup 20160609
by
Tomohiro Ichimura
PDF
Apache geode at-s1p
by
Masaki Yamakawa
PPTX
Okuyama説明資料 20120119 ss
by
Takahiro Iwase
PDF
20181031 springfest spring data geode
by
Masaki Yamakawa
PPTX
MongoDB: システム可用性を拡張するインデクス戦略
by
ippei_suzuki
PDF
20121014 micorgeodatahansonaoki
by
和人 青木
MongoDB概要:金融業界でのMongoDB
by
ippei_suzuki
事例から見るNoSQLの使い方 - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
20170714_MySQL 5.7 GIS(地理情報システム) by 日本オラクル株式会社 MySQL GBU 山﨑由章
by
Insight Technology, Inc.
NoSQLデータベースと位置情報
by
Koji Ichiwaki
日本発オープンソース!! スケールアウト型データベース GridDB入門 ~ GitHubからダウンロードして使ってみましょう ~
by
griddb
Apache Drill を利用した実データの分析
by
MapR Technologies Japan
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
Apache Drill で JSON 形式の オープンデータを分析してみる - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
BIM/CIMにおける3D-GIS・IoTの役割と展望
by
Koji Makanae
Apache Geode で始める Spring Data Gemfire
by
Akihiro Kitada
日本生態学会第65回全国大会 自由集会01 地理情報へのDeep Learning活用の可能性と、学習データセットに求められる要件
by
Kunihiko Miyoshi
Apache drillを業務利用してみる(までの道のり)
by
Keigo Suda
20180217 hackertackle geode
by
Masaki Yamakawa
MySQL 8.0で強化されたGIS機能のご紹介:「FOSS4G 2018 Hokkaido」での発表資料
by
yoyamasaki
Geode meetup 20160609
by
Tomohiro Ichimura
Apache geode at-s1p
by
Masaki Yamakawa
Okuyama説明資料 20120119 ss
by
Takahiro Iwase
20181031 springfest spring data geode
by
Masaki Yamakawa
MongoDB: システム可用性を拡張するインデクス戦略
by
ippei_suzuki
20121014 micorgeodatahansonaoki
by
和人 青木
More from Masaki Yamakawa
PDF
20221117_クラウドネイティブ向けYugabyteDB活用シナリオ
by
Masaki Yamakawa
PDF
インメモリーデータグリッドの選択肢
by
Masaki Yamakawa
PDF
インメモリーで超高速処理を実現する場合のカギ
by
Masaki Yamakawa
PDF
20250726_Devinで変えるエンプラシステム開発の未来
by
Masaki Yamakawa
PDF
20250717_Devin×GitHubCopilotで10人分の仕事は出来るのか?
by
Masaki Yamakawa
PDF
20250710_Devinで切り拓くDB革命_〜価値創出に集中せよ〜
by
Masaki Yamakawa
PDF
20231111_YugabyteDB-on-k8s.pdf
by
Masaki Yamakawa
PDF
20250729_Devin-for-Enterprise
by
Masaki Yamakawa
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
20250826_Devinで切り拓く沖縄ITの未来_AI駆動開発勉強会 沖縄支部 第2回
by
Masaki Yamakawa
PDF
20250611_話題のDevin、エンプラ開発で〇人分の仕事はできるのか !?
by
Masaki Yamakawa
PDF
Geode hands-on
by
Masaki Yamakawa
PDF
20190523 IMC meetup-IMDG&DS
by
Masaki Yamakawa
PDF
20171118 jjug snappydata
by
Masaki Yamakawa
PDF
20220331_DSSA_MigrationToYugabyteDB
by
Masaki Yamakawa
PDF
20171125 springfest snappydata
by
Masaki Yamakawa
20221117_クラウドネイティブ向けYugabyteDB活用シナリオ
by
Masaki Yamakawa
インメモリーデータグリッドの選択肢
by
Masaki Yamakawa
インメモリーで超高速処理を実現する場合のカギ
by
Masaki Yamakawa
20250726_Devinで変えるエンプラシステム開発の未来
by
Masaki Yamakawa
20250717_Devin×GitHubCopilotで10人分の仕事は出来るのか?
by
Masaki Yamakawa
20250710_Devinで切り拓くDB革命_〜価値創出に集中せよ〜
by
Masaki Yamakawa
20231111_YugabyteDB-on-k8s.pdf
by
Masaki Yamakawa
20250729_Devin-for-Enterprise
by
Masaki Yamakawa
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
20250826_Devinで切り拓く沖縄ITの未来_AI駆動開発勉強会 沖縄支部 第2回
by
Masaki Yamakawa
20250611_話題のDevin、エンプラ開発で〇人分の仕事はできるのか !?
by
Masaki Yamakawa
Geode hands-on
by
Masaki Yamakawa
20190523 IMC meetup-IMDG&DS
by
Masaki Yamakawa
20171118 jjug snappydata
by
Masaki Yamakawa
20220331_DSSA_MigrationToYugabyteDB
by
Masaki Yamakawa
20171125 springfest snappydata
by
Masaki Yamakawa
20211118 dbts2021 マイクロサービスにおけるApache Geodeの効果的な使い方
1.
マイクロサービスにおける Apache Geodeの効果的な使い方 マイクロサービス時代では データ管理システムは適材適所で使おう! 0 RDB一辺倒な あなたに贈る
2.
自己紹介 山河 征紀 ウルシステムズ株式会社 コンサルタント { “分野” :
”金融系(証券・FX)”, “得技” : [“インメモリー処理”, “分散処理”], “その他” : ”Apache Geodeコミッター” } 1
3.
本日お伝えしたいテーマ 2 RDB以外の選択肢としてのApache Geodeを あなたの引き出しに追加する方法
4.
証券業界・FX業界における よくある要求 3
5.
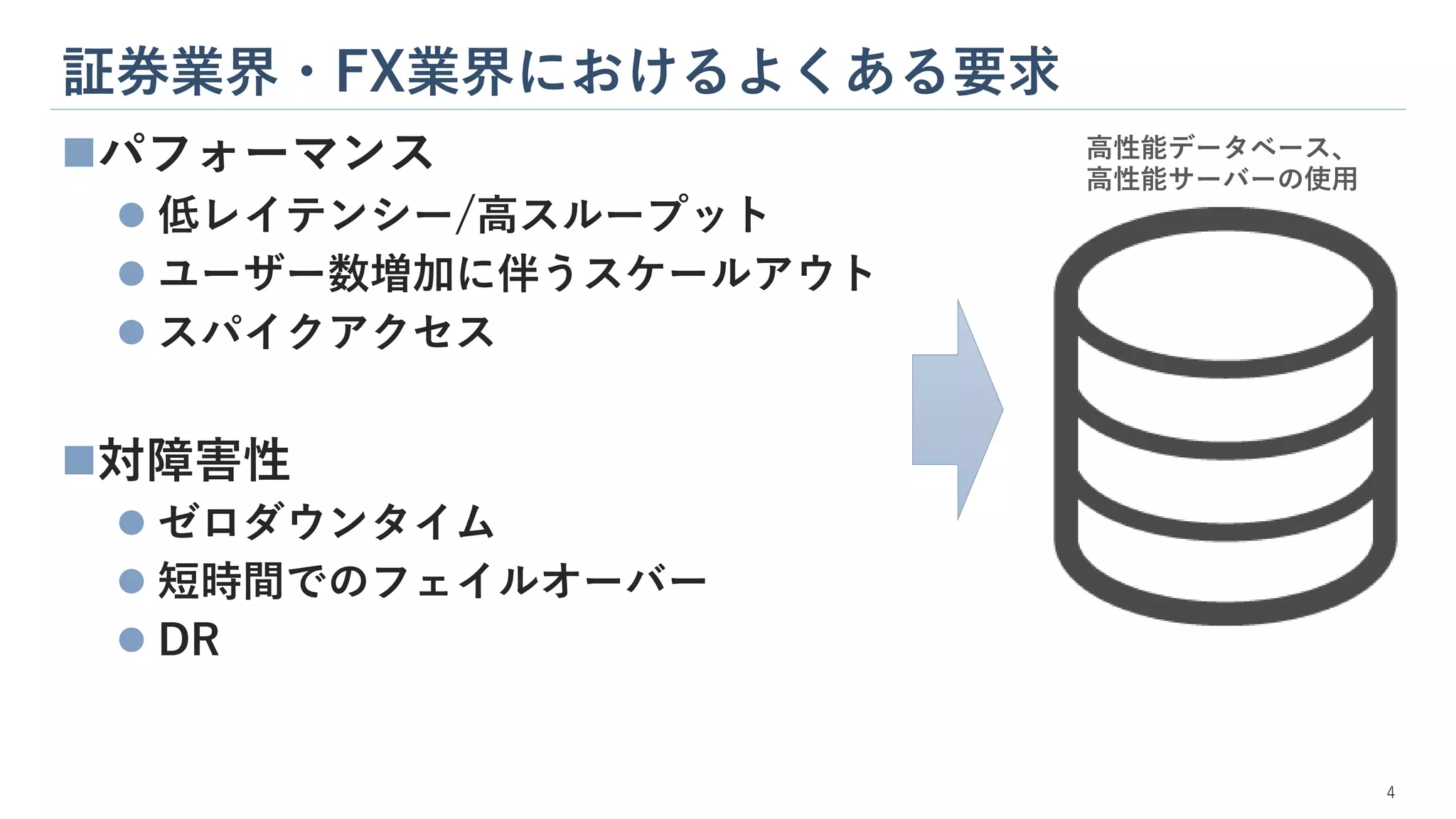
証券業界・FX業界におけるよくある要求 4 ◼パフォーマンス ⚫ 低レイテンシー/高スループット ⚫ ユーザー数増加に伴うスケールアウト ⚫
スパイクアクセス ◼対障害性 ⚫ ゼロダウンタイム ⚫ 短時間でのフェイルオーバー ⚫ DR 高性能データベース、 高性能サーバーの使用
6.
別の解決策はないか… 5 高性能データベース、 高性能サーバーの使用
7.
選択肢の1つとしてのApache Geode 6
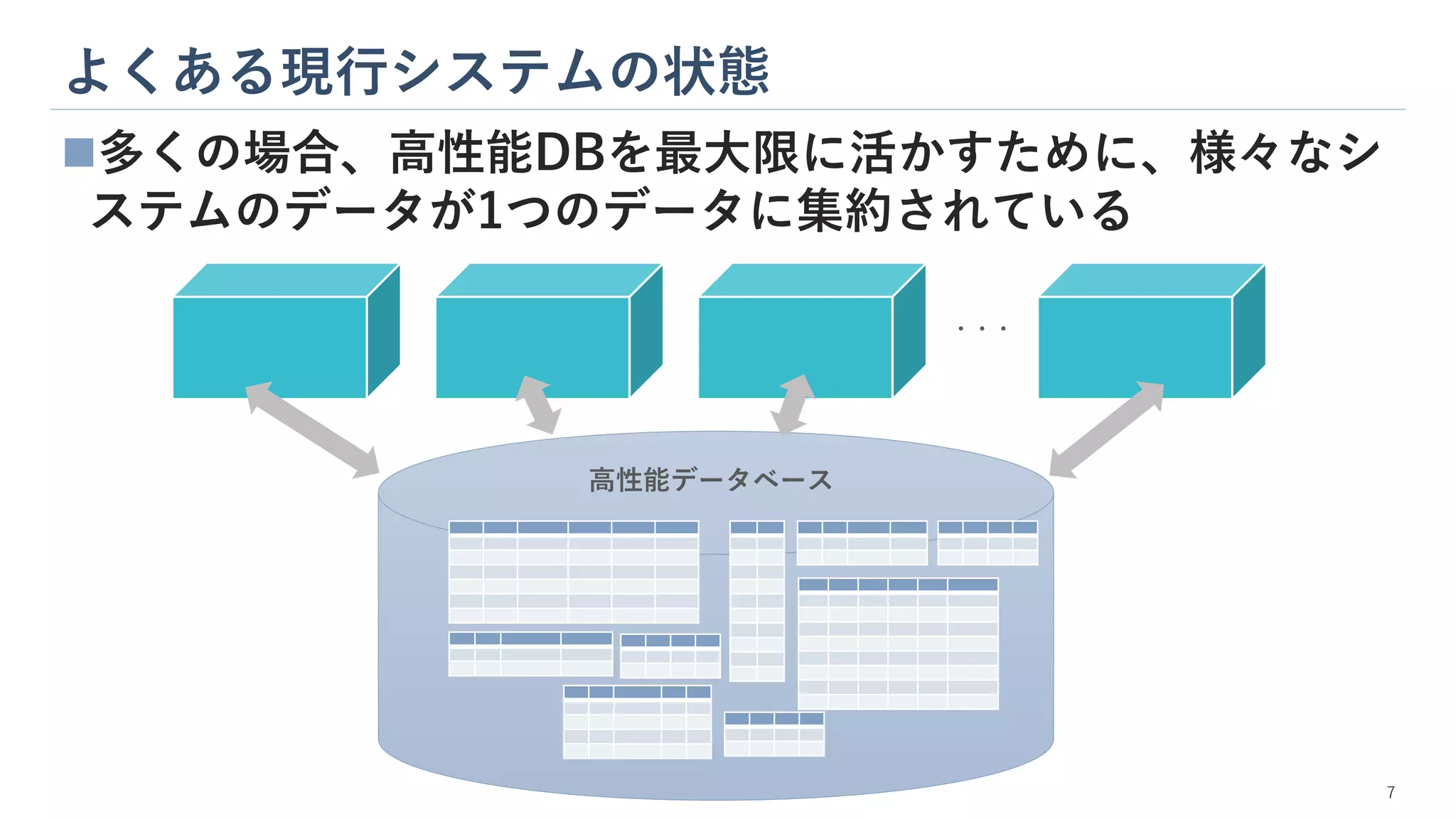
8.
よくある現行システムの状態 7 ◼多くの場合、高性能DBを最大限に活かすために、様々なシ ステムのデータが1つのデータに集約されている 高性能データベース ・・・
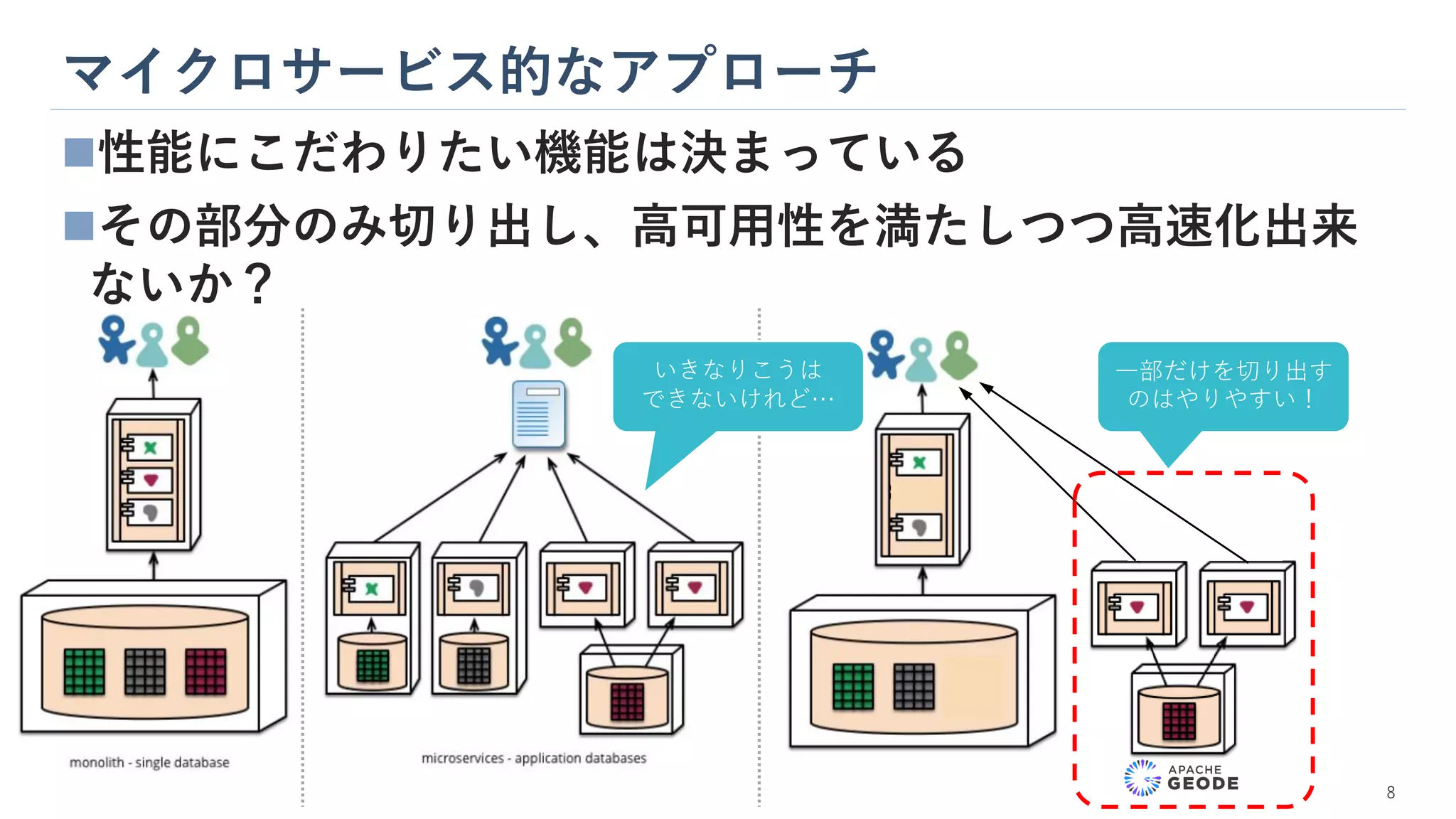
9.
マイクロサービス的なアプローチ 8 ◼性能にこだわりたい機能は決まっている ◼その部分のみ切り出し、高可用性を満たしつつ高速化出来 ないか? いきなりこうは できないけれど… 一部だけを切り出す のはやりやすい!
10.
RDB以外の選択肢としての Apache Geode 9
11.
Apache Geodeとは? 10 インメモリー データグリッド製品 RDBとは異なりメモリー内へのデータ保持を ベースとするプロダクト 主要なインメモリーデータグリッド製品
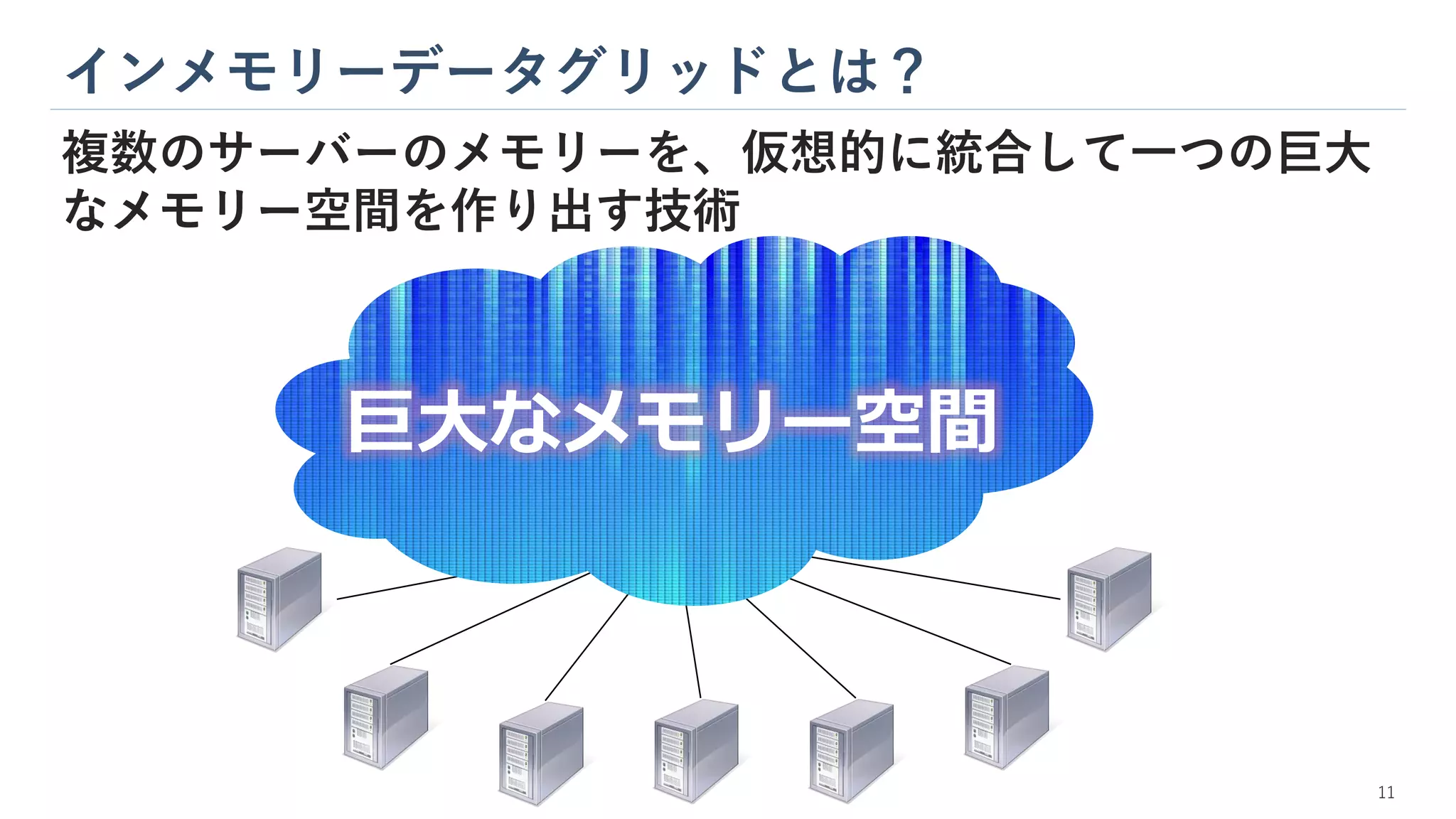
12.
インメモリーデータグリッドとは? 複数のサーバーのメモリーを、仮想的に統合して一つの巨大 なメモリー空間を作り出す技術 巨大なメモリー空間 11
13.
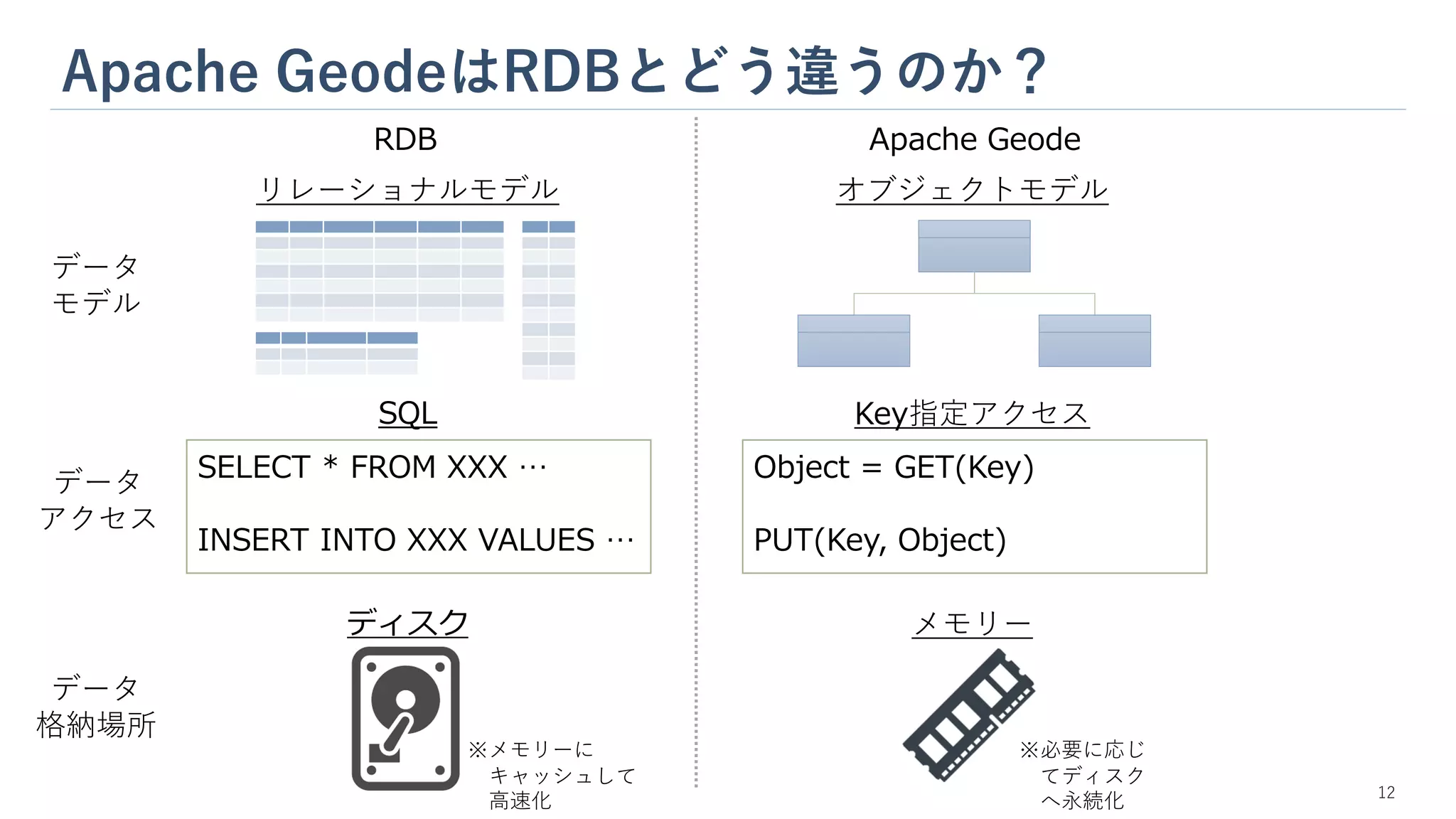
Apache GeodeはRDBとどう違うのか? RDB Apache
Geode データ モデル リレーショナルモデル オブジェクトモデル データ 格納場所 ディスク メモリー データ アクセス SELECT * FROM XXX … INSERT INTO XXX VALUES … Object = GET(Key) PUT(Key, Object) SQL Key指定アクセス ※メモリーに キャッシュして 高速化 ※必要に応じ てディスク へ永続化 12
14.
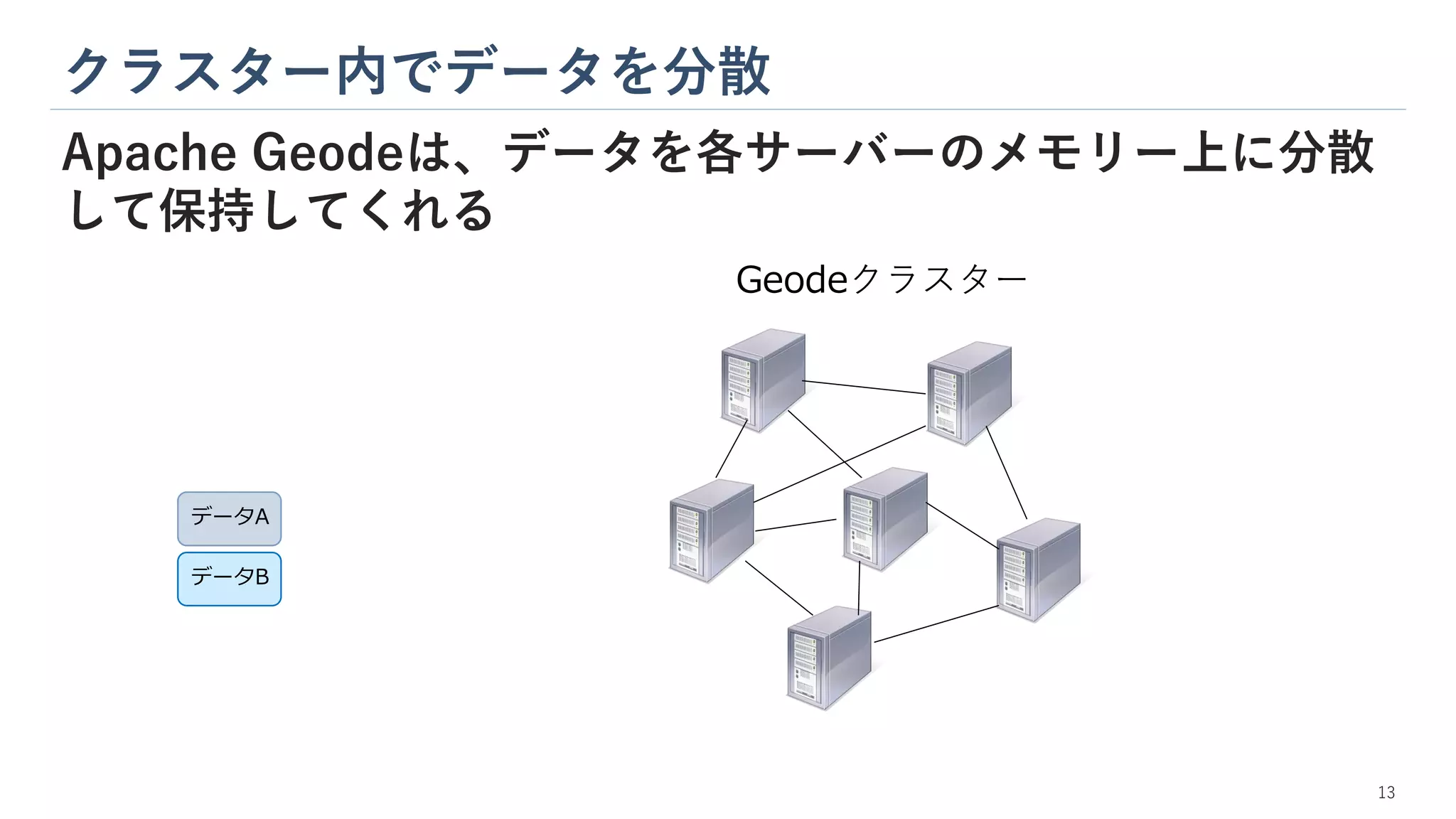
クラスター内でデータを分散 Apache Geodeは、データを各サーバーのメモリー上に分散 して保持してくれる データB コピー Geodeクラスター データA コピー データA データB 13
15.
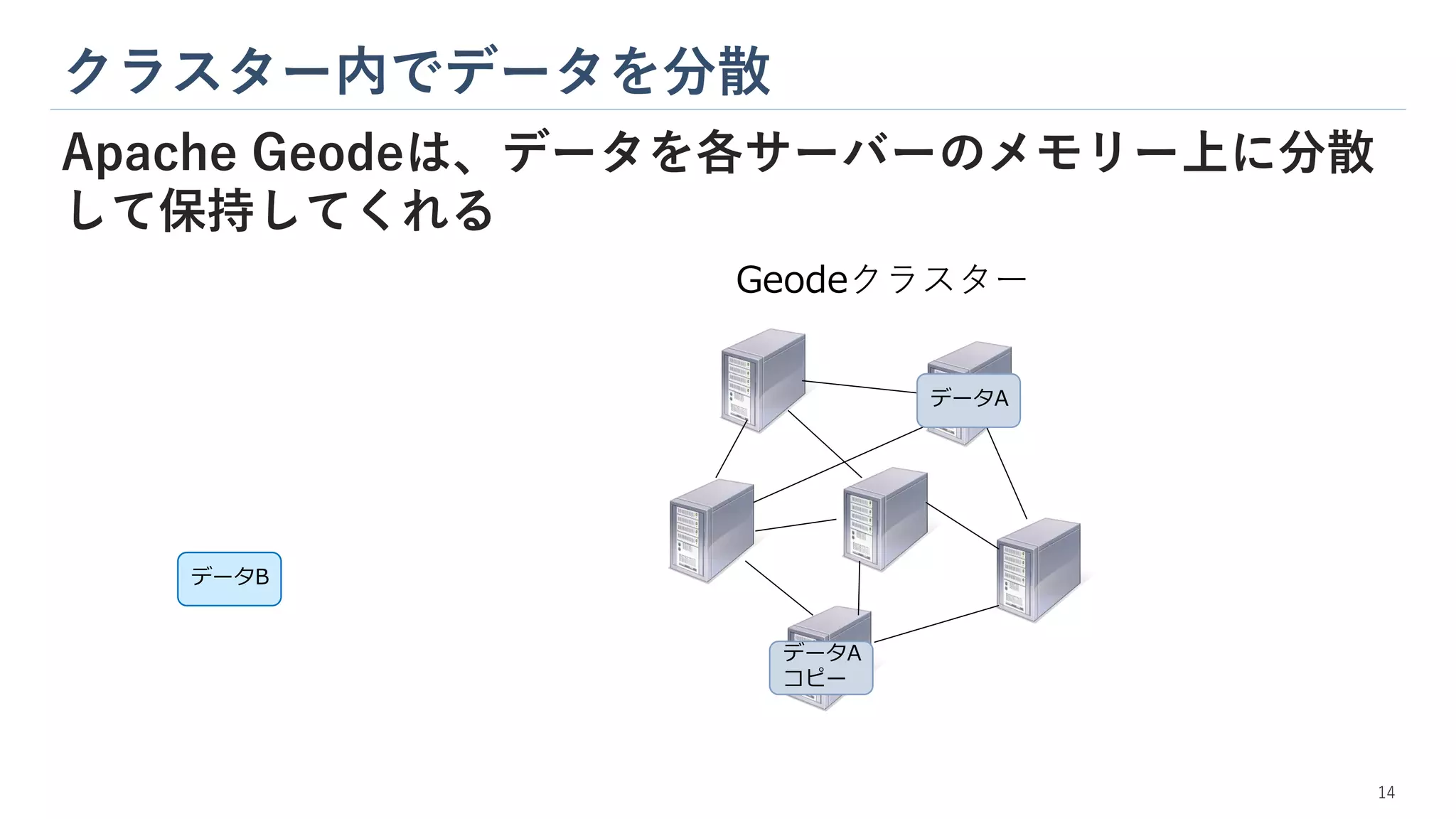
クラスター内でデータを分散 Apache Geodeは、データを各サーバーのメモリー上に分散 して保持してくれる データB コピー Geodeクラスター データA コピー データA データB 14
16.
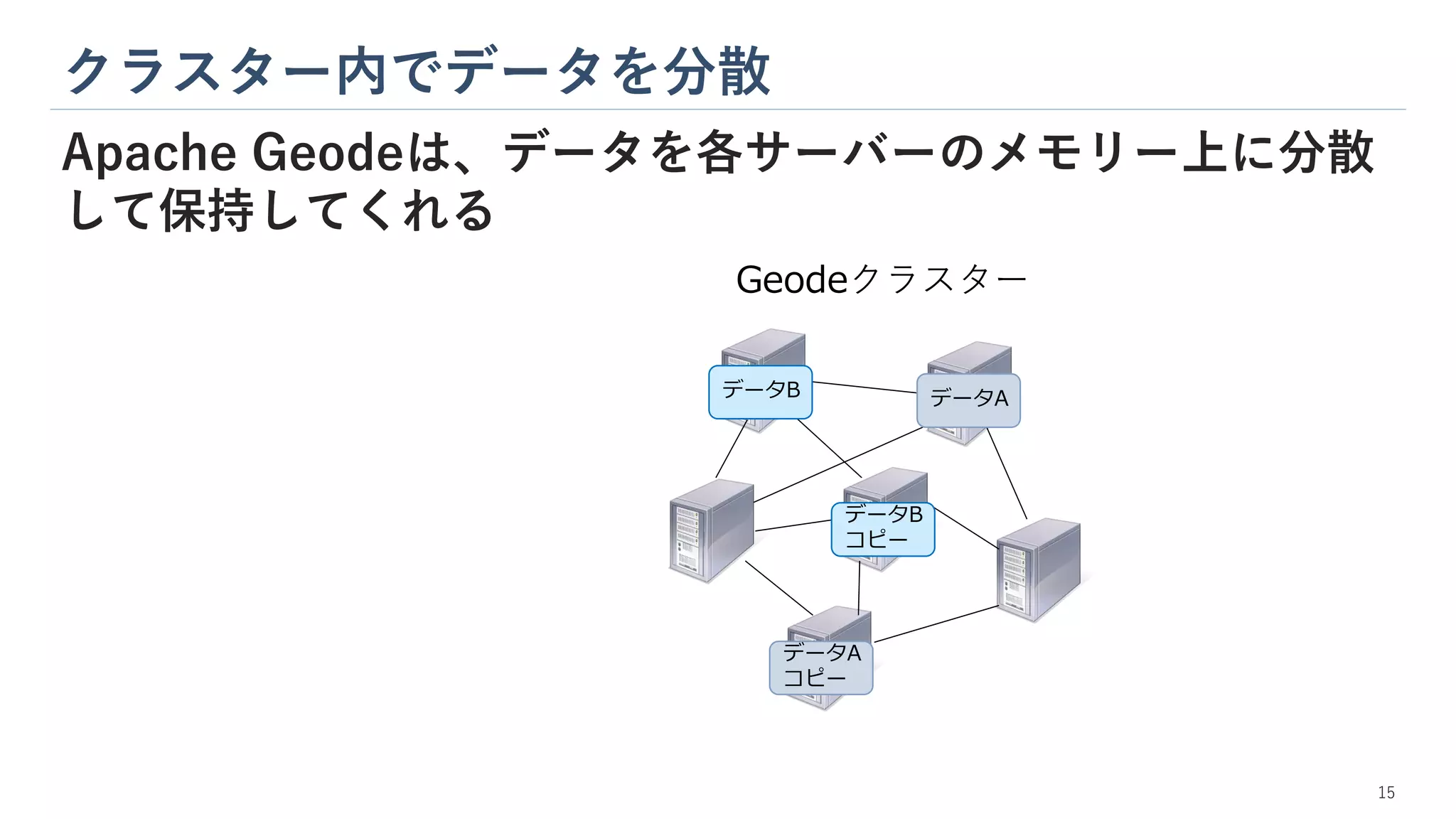
クラスター内でデータを分散 Apache Geodeは、データを各サーバーのメモリー上に分散 して保持してくれる データB コピー Geodeクラスター データA コピー データA データB 15
17.
Cache cache =
new CacheFactory() .set("cache-xml-file", “cache.xml").create(); Region<Integer, Employee> region = cache.getRegion(“Employee"); Integer key = 1; Employee employee = new Employee(…); // データ登録 region.put(key, employee); // データ取得 Employee value = region.get(key); // データ削除 region.remove(key); 使い方は簡単 java.util.Mapを使用してる感覚で使用が可能 16
18.
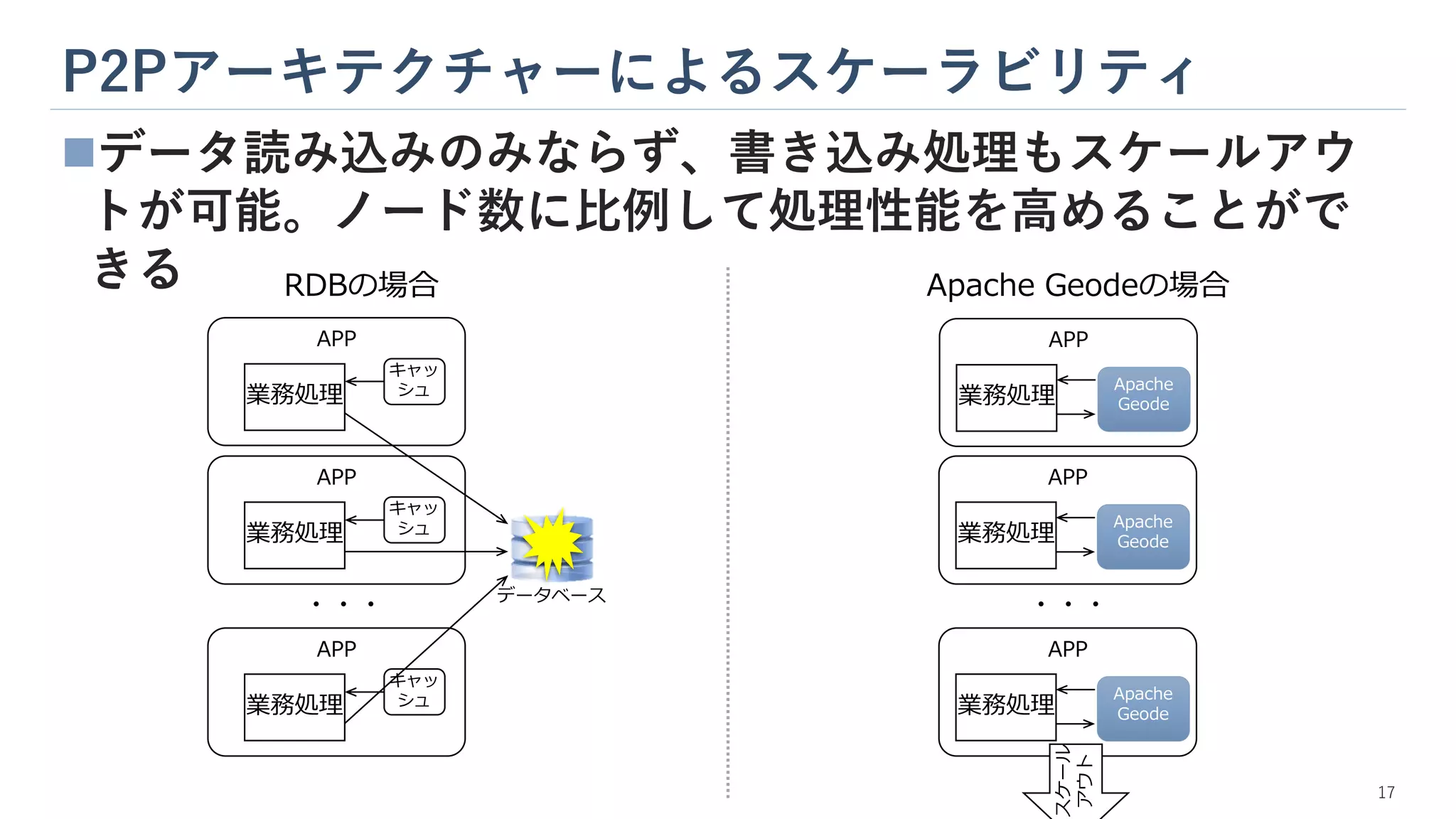
P2Pアーキテクチャーによるスケーラビリティ ◼データ読み込みのみならず、書き込み処理もスケールアウ トが可能。ノード数に比例して処理性能を高めることがで きる ・・・ データベース ・・・ RDBの場合 Apache Geodeの場合 APP 業務処理 キャッ シュ APP 業務処理 キャッ シュ APP 業務処理 キャッ シュ APP 業務処理 Apache Geode APP 業務処理 Apache Geode APP 業務処理 Apache Geode スケール アウト 17
19.
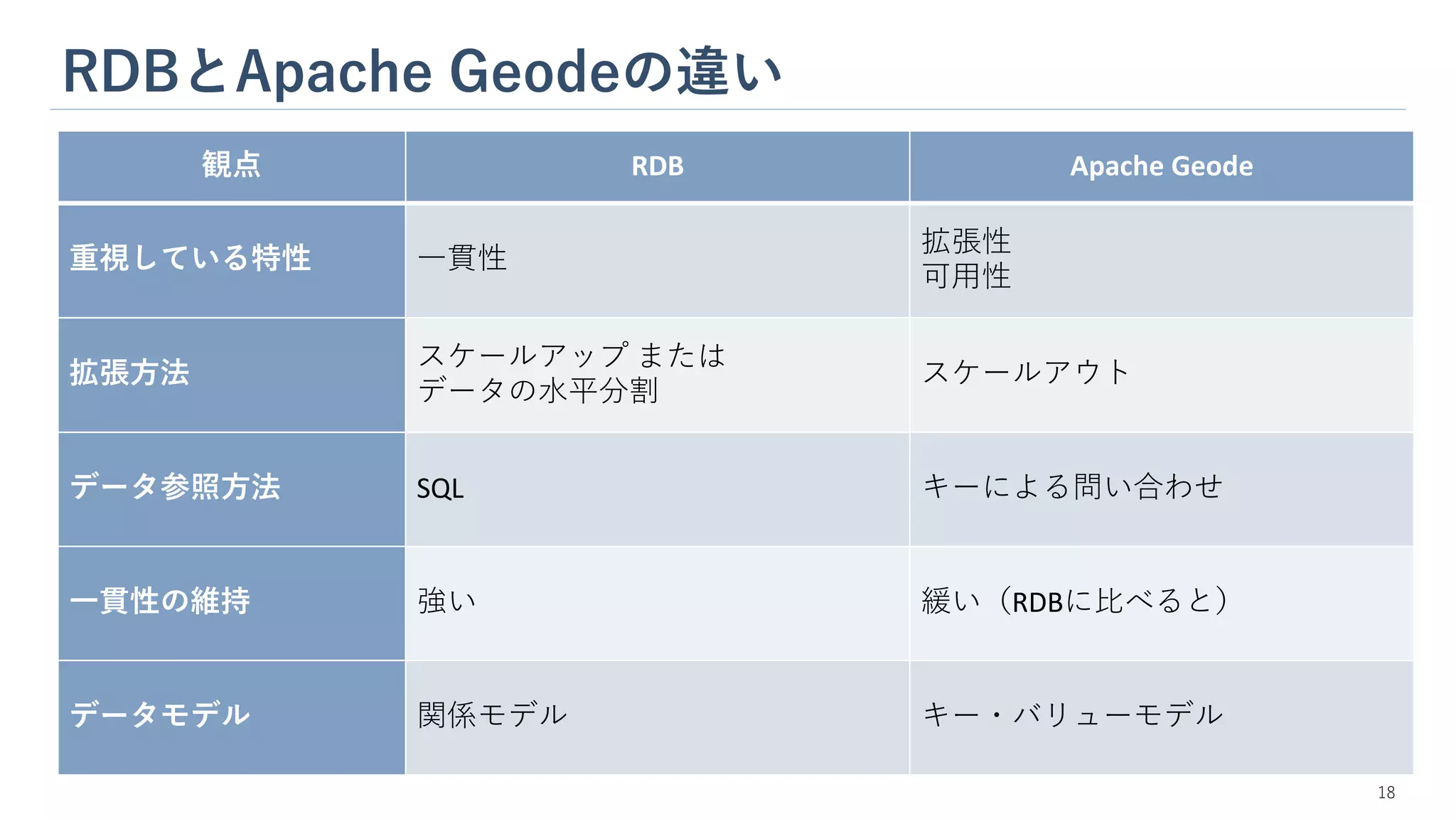
RDBとApache Geodeの違い 18 観点 RDB
Apache Geode 重視している特性 一貫性 拡張性 可用性 拡張方法 スケールアップ または データの水平分割 スケールアウト データ参照方法 SQL キーによる問い合わせ 一貫性の維持 強い 緩い(RDBに比べると) データモデル 関係モデル キー・バリューモデル
20.
Apache Geodeのメリット 高速処理 大量のトランザクションを高速に処理できる スケーラビリティ ノードの追加に応じて巨大なメモリー空間を生み出せる 可用性 ノード単体の障害による影響がない 高信頼性 欧米の金融機関を中心にミッションクリティカル領域での利用実績多数 19
21.
切り出したマイクロサービスへの Apache Geodeの適用方法 20
22.
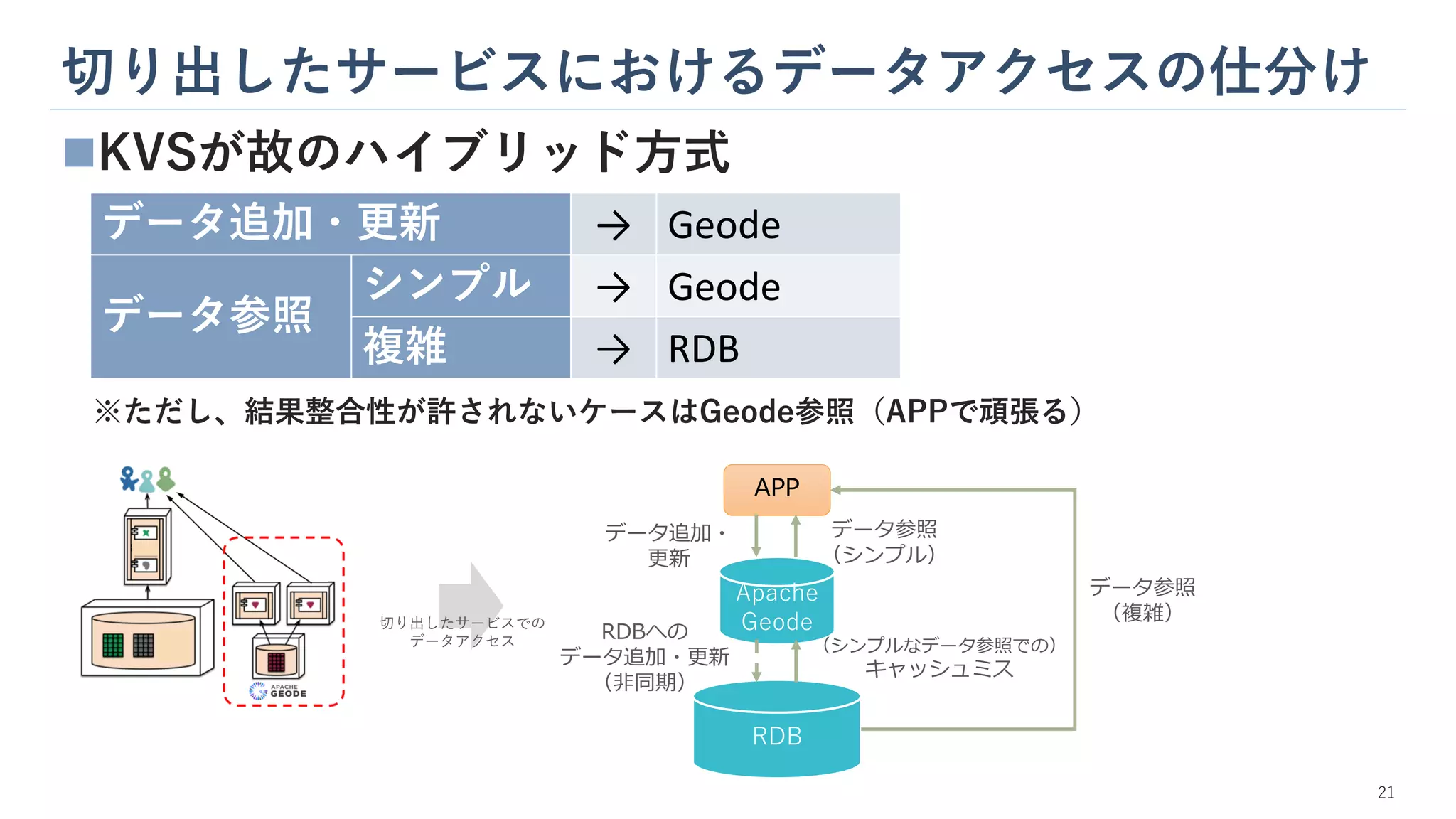
切り出したサービスにおけるデータアクセスの仕分け 21 ◼KVSが故のハイブリッド方式 ※ただし、結果整合性が許されないケースはGeode参照(APPで頑張る) APP Apache Geode RDB RDBへの データ追加・更新 (非同期) データ追加・ 更新 データ参照 (シンプル) (シンプルなデータ参照での) キャッシュミス データ参照 (複雑) データ追加・更新 → Geode データ参照 シンプル
→ Geode 複雑 → RDB 切り出したサービスでの データアクセス
23.
Apache Geodeのはじめ方 切り出したマイクロサービスへの Apache Geodeの適用方法 22
24.
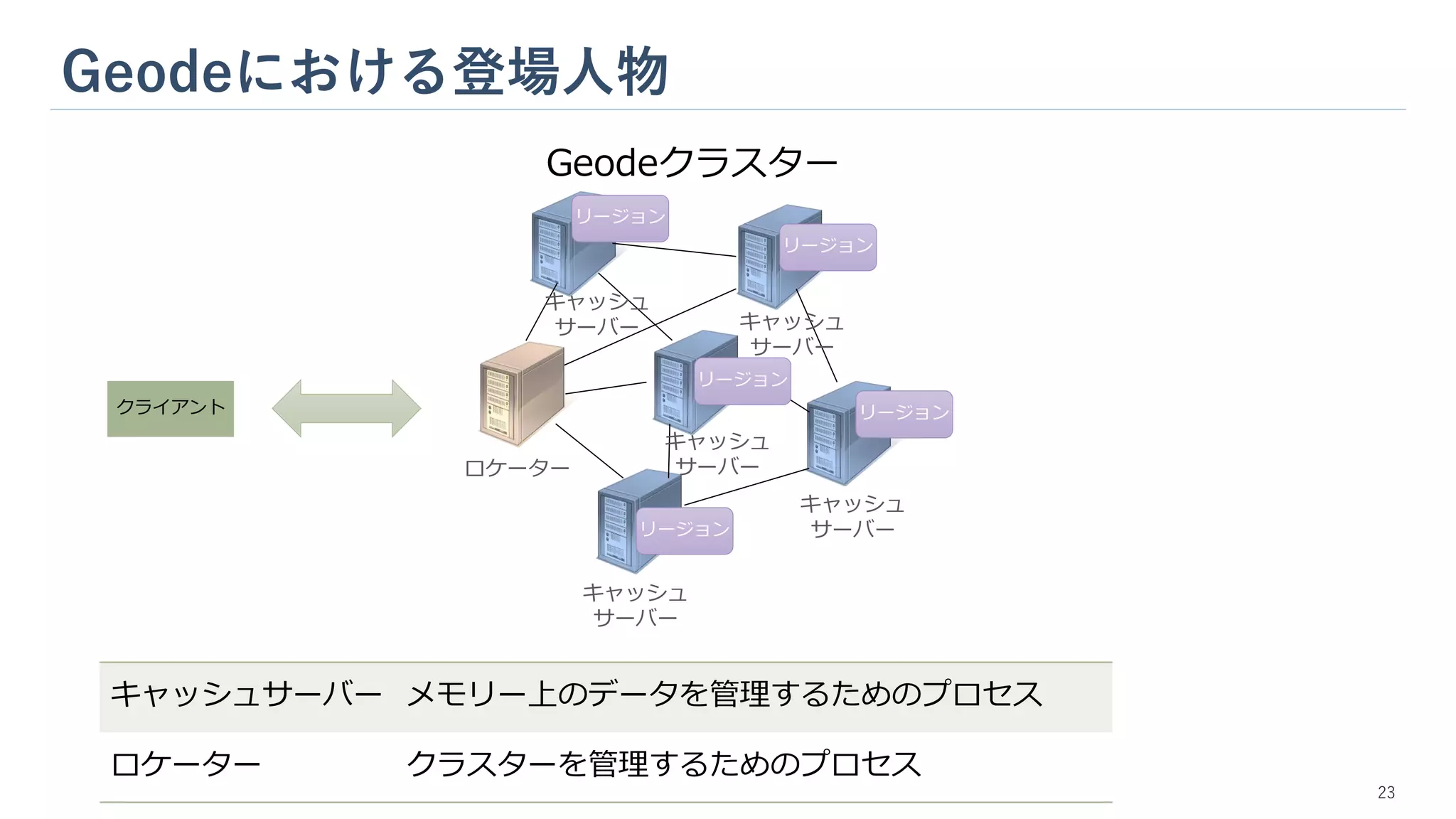
Geodeにおける登場人物 23 Geodeクラスター ロケーター キャッシュ サーバー キャッシュ サーバー キャッシュ サーバー キャッシュ サーバー キャッシュ サーバー クライアント リージョン リージョン リージョン リージョン リージョン キャッシュサーバー メモリー上のデータを管理するためのプロセス ロケーター
クラスターを管理するためのプロセス
25.
Geodeクラスター作成 24 ◼ロケーター起動 ⚫ gfsh> start
locator ◼キャッシュサーバー起動 ⚫ gfsh> start server --locators=localhost[10334] ✓ポイントはlocatorを指定すること ✓これでクラスターに参加できる
26.
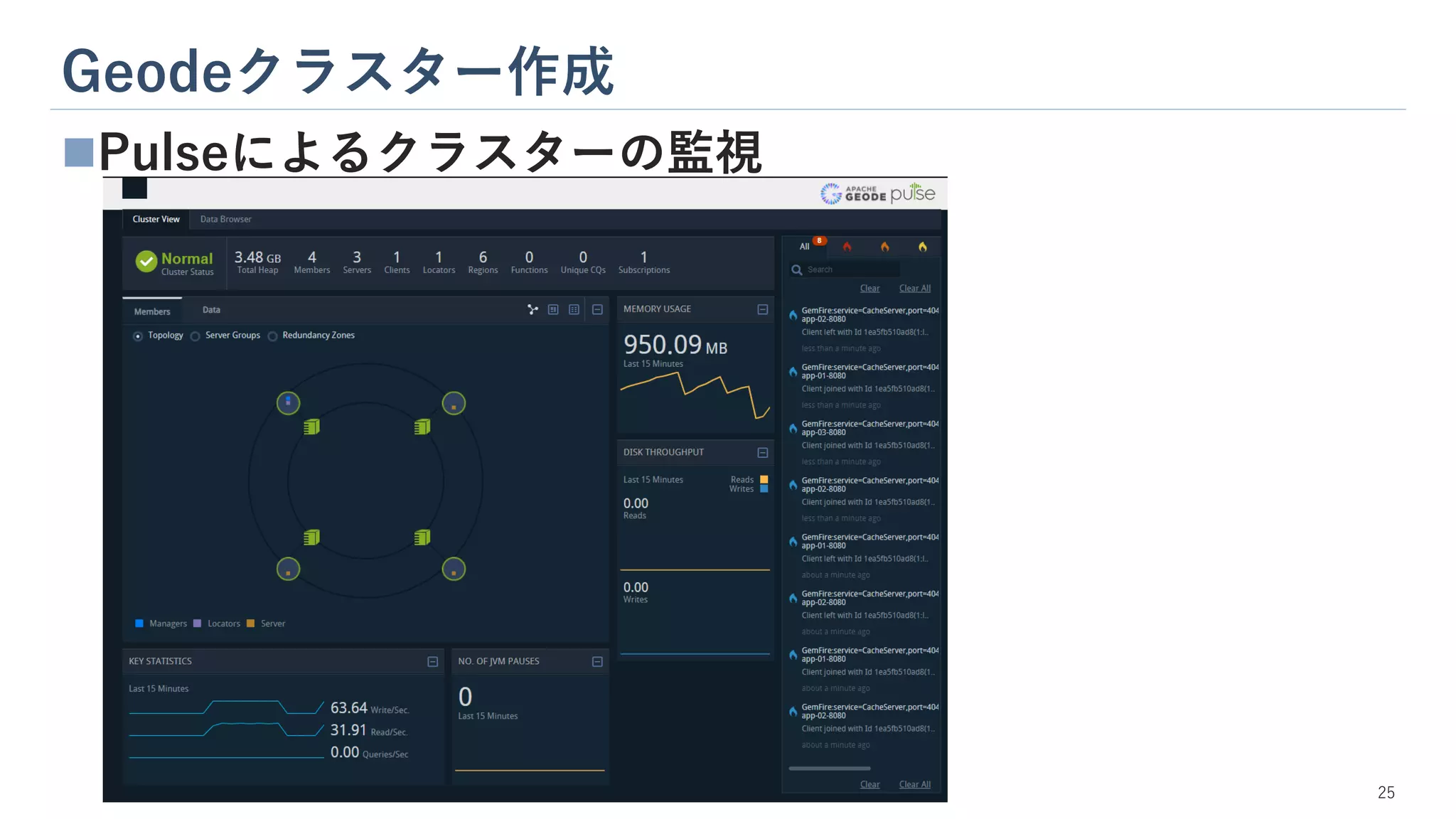
Geodeクラスター作成 25 ◼Pulseによるクラスターの監視
27.
クラスター作成後にやること 26 ◼リージョン作成 ⚫ gfsh> create
region --name=OrderRegion --type=REPLICATE ◼Index作成 ⚫ gfsh> create index --name=orderStatusIndex --region=/OrderRegion --expression=status
28.
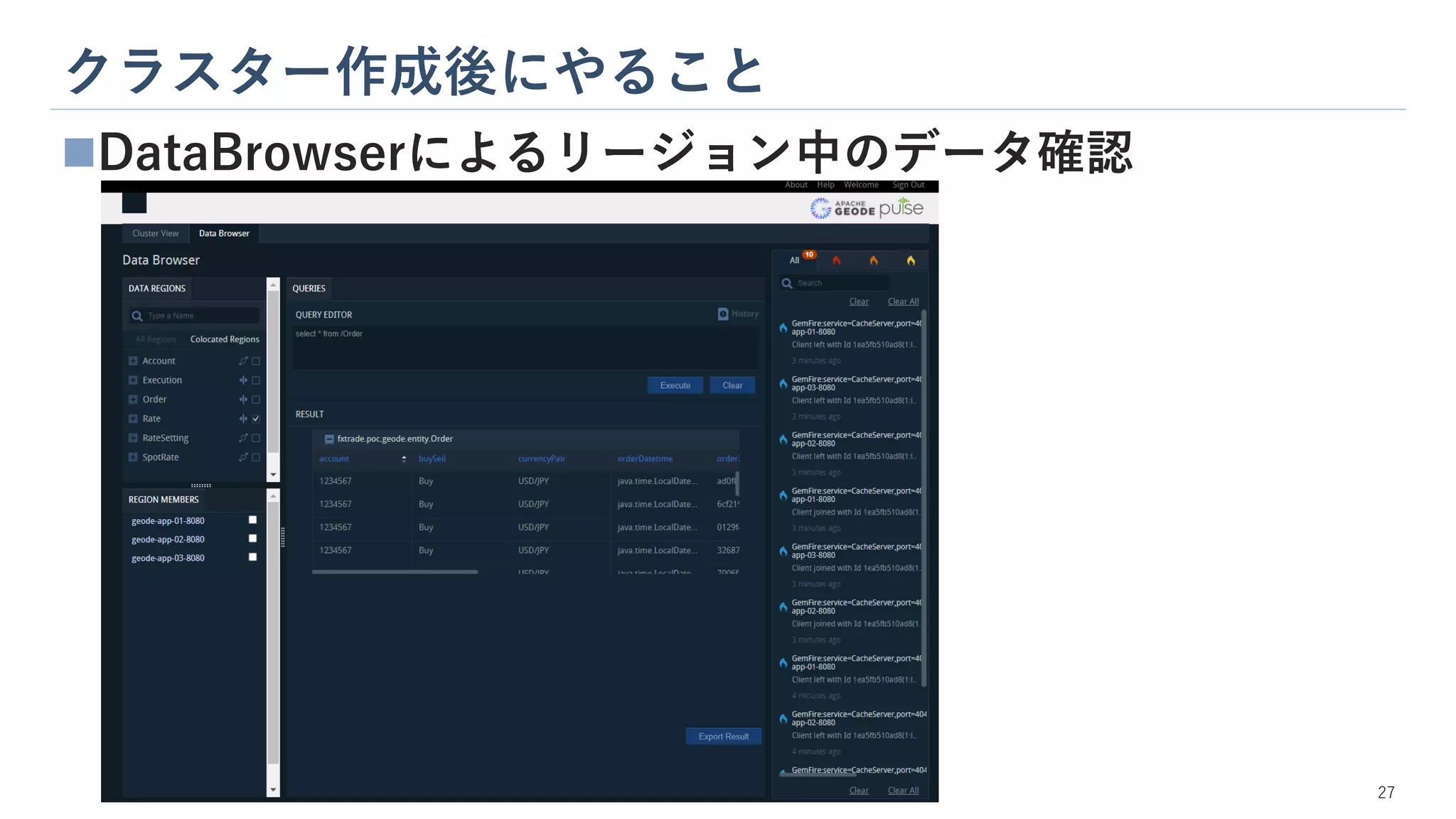
クラスター作成後にやること 27 ◼DataBrowserによるリージョン中のデータ確認
29.
Apache Geode 第1の壁 切り出したマイクロサービスへの Apache
Geodeの適用方法 28
30.
KVSの壁 29 1. キー設計 2. レプリケート
or パーティション 3. パーティショニング
31.
KVSの壁:1. キー設計 30 ◼参照優先で検討 ◼アクセスパターンを整理 https://speakerdeck.com/mogamin/rdbnoy-haanatanisong-ru-kvsmoderingufalsefalseuhauwogong- kai-aws-dynamodb-azurecosmosdbdefalsekvsshe-ji-hakousiyou
32.
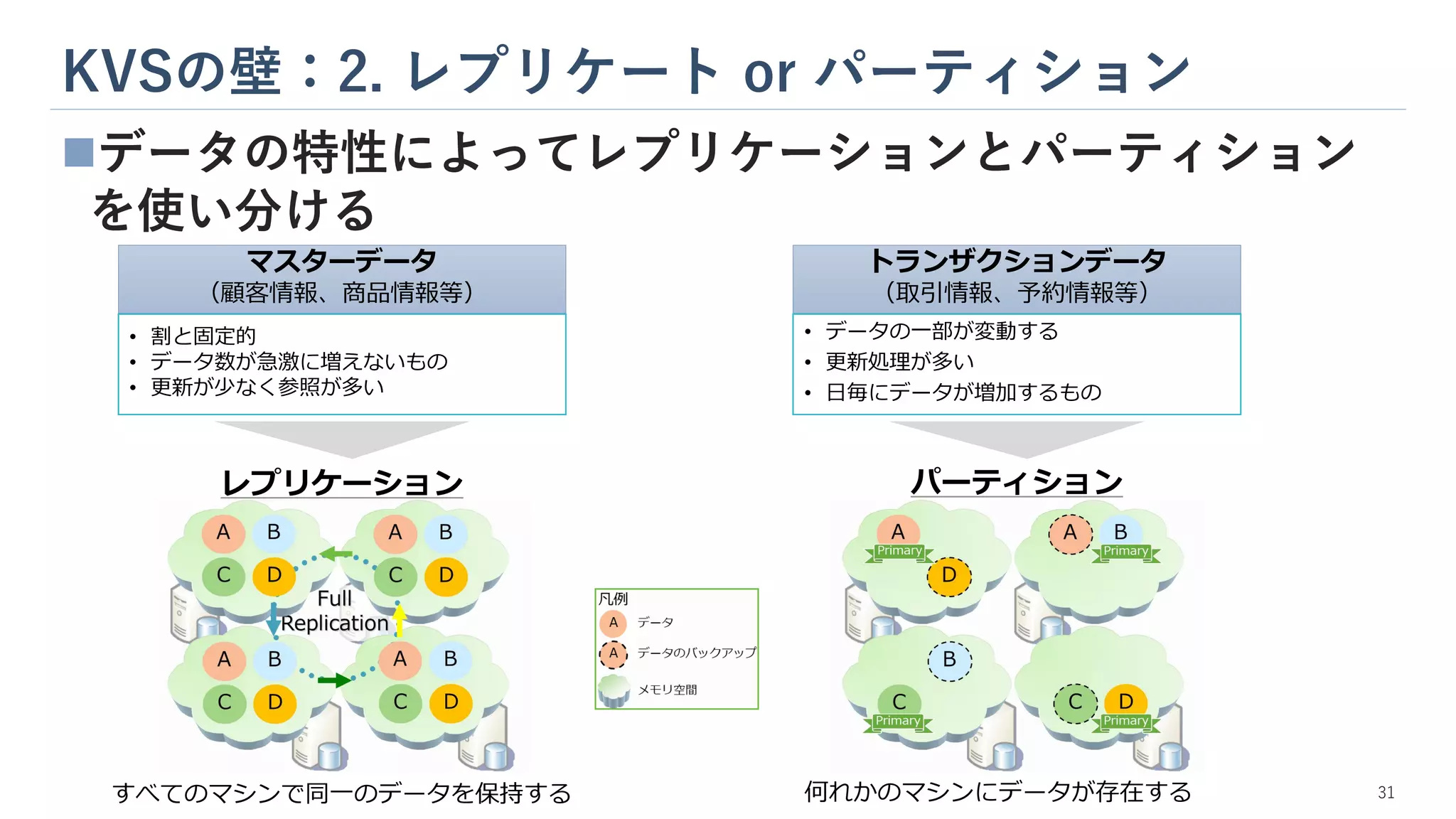
KVSの壁:2. レプリケート or
パーティション ◼データの特性によってレプリケーションとパーティション を使い分ける パーティション レプリケーション すべてのマシンで同一のデータを保持する 何れかのマシンにデータが存在する 31 マスターデータ (顧客情報、商品情報等) トランザクションデータ (取引情報、予約情報等) • 割と固定的 • データ数が急激に増えないもの • 更新が少なく参照が多い • データの一部が変動する • 更新処理が多い • 日毎にデータが増加するもの
33.
KVSの壁:3. パーティショニング 32 ◼データの分散配置するノードを最適化するオプション ⚫ PartitionResolver ⚫
Co-Location
34.
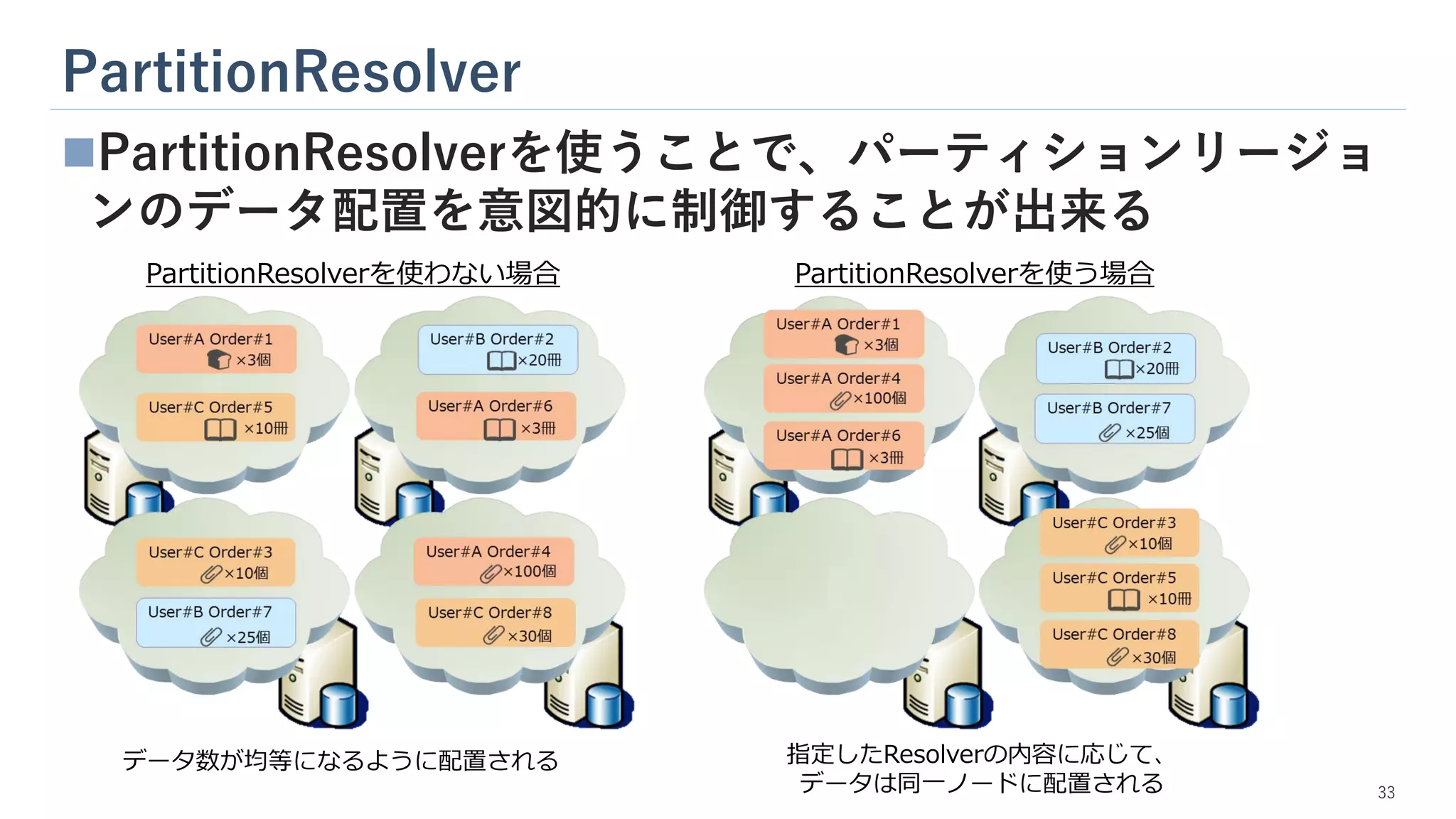
PartitionResolver ◼PartitionResolverを使うことで、パーティションリージョ ンのデータ配置を意図的に制御することが出来る PartitionResolverを使わない場合 PartitionResolverを使う場合 データ数が均等になるように配置される 指定したResolverの内容に応じて、 データは同一ノードに配置される
33
35.
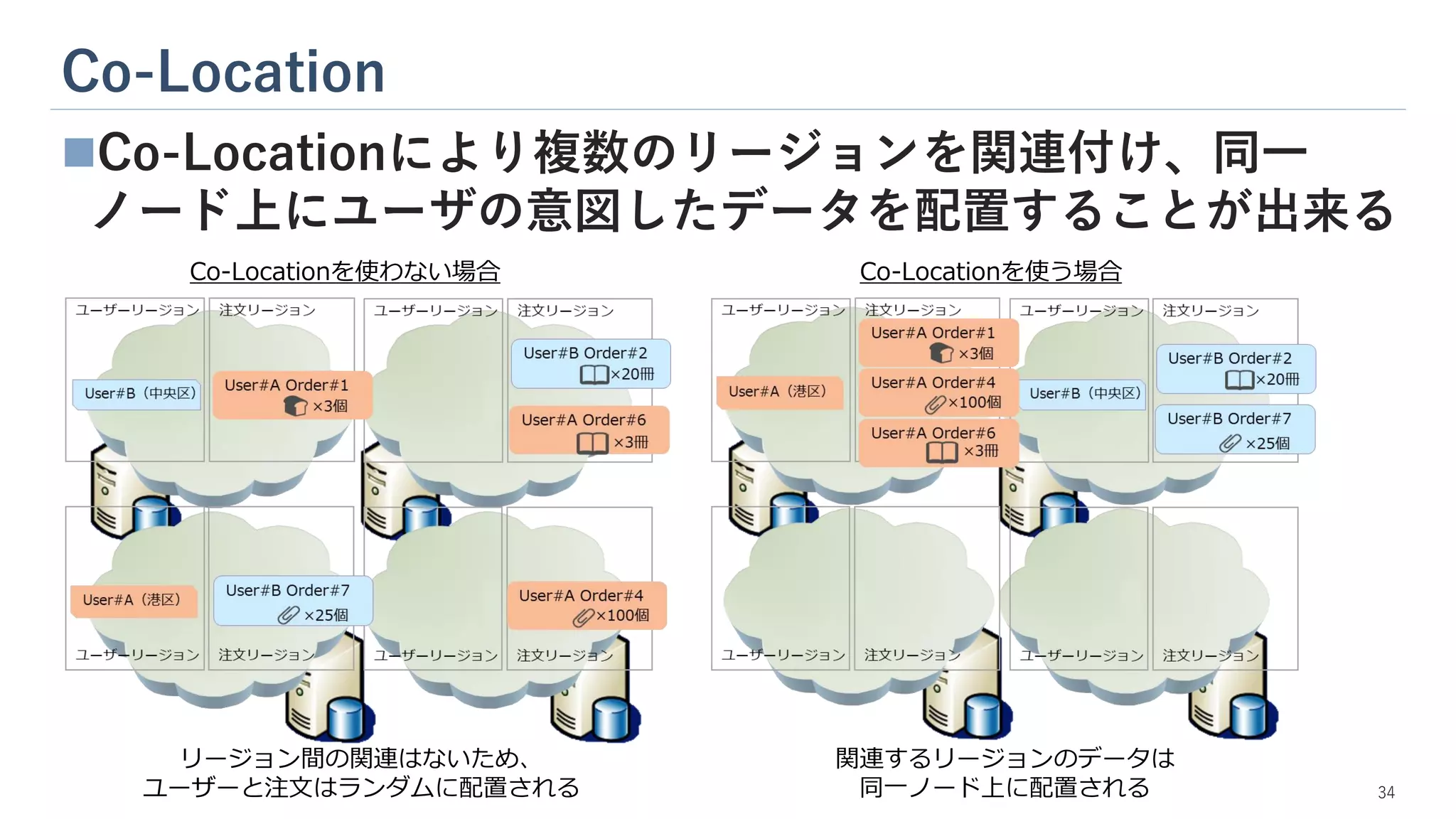
Co-Location ◼Co-Locationにより複数のリージョンを関連付け、同一 ノード上にユーザの意図したデータを配置することが出来る Co-Locationを使わない場合 Co-Locationを使う場合 34 リージョン間の関連はないため、 ユーザーと注文はランダムに配置される 関連するリージョンのデータは 同一ノード上に配置される
36.
なぜパーティショニングが必要なのか? ◼デフォルトのパーティションリージョンのデータ配置では ノード間の通信が発生してしまう 太郎 次郎 ECサイトでユーザーマスターと過去の注文履歴をチェックしつつ、注文処理を行う場合 花子 ×3個 太郎 ×100個 次郎 太郎(港区) 次郎(中央区) 花子(目黒区) 次郎
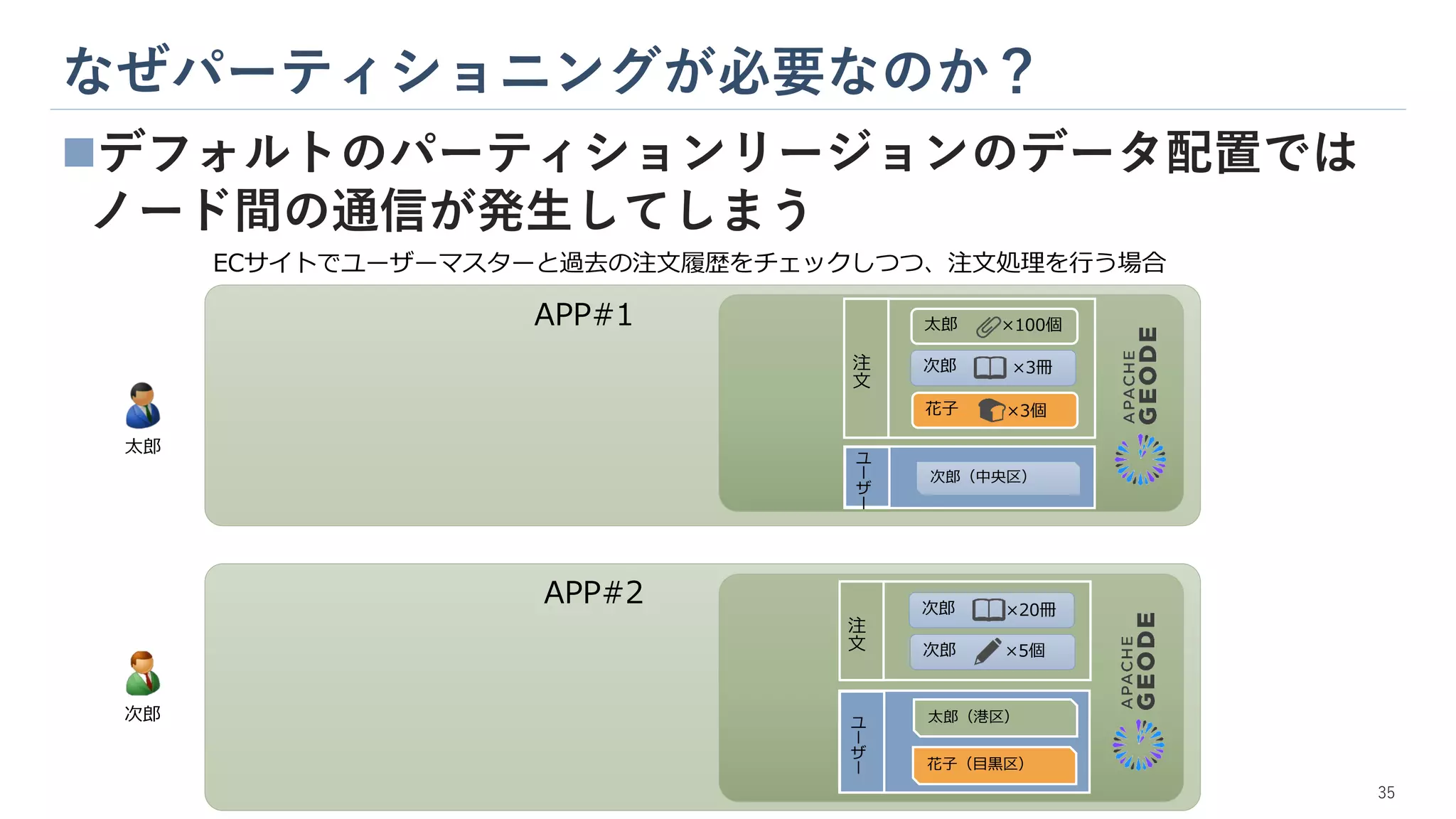
×20冊 ×5個 次郎 ×3冊 APP#1 APP#2 注 文 注 文 ユ ー ザ ー ユ ー ザ ー 35
37.
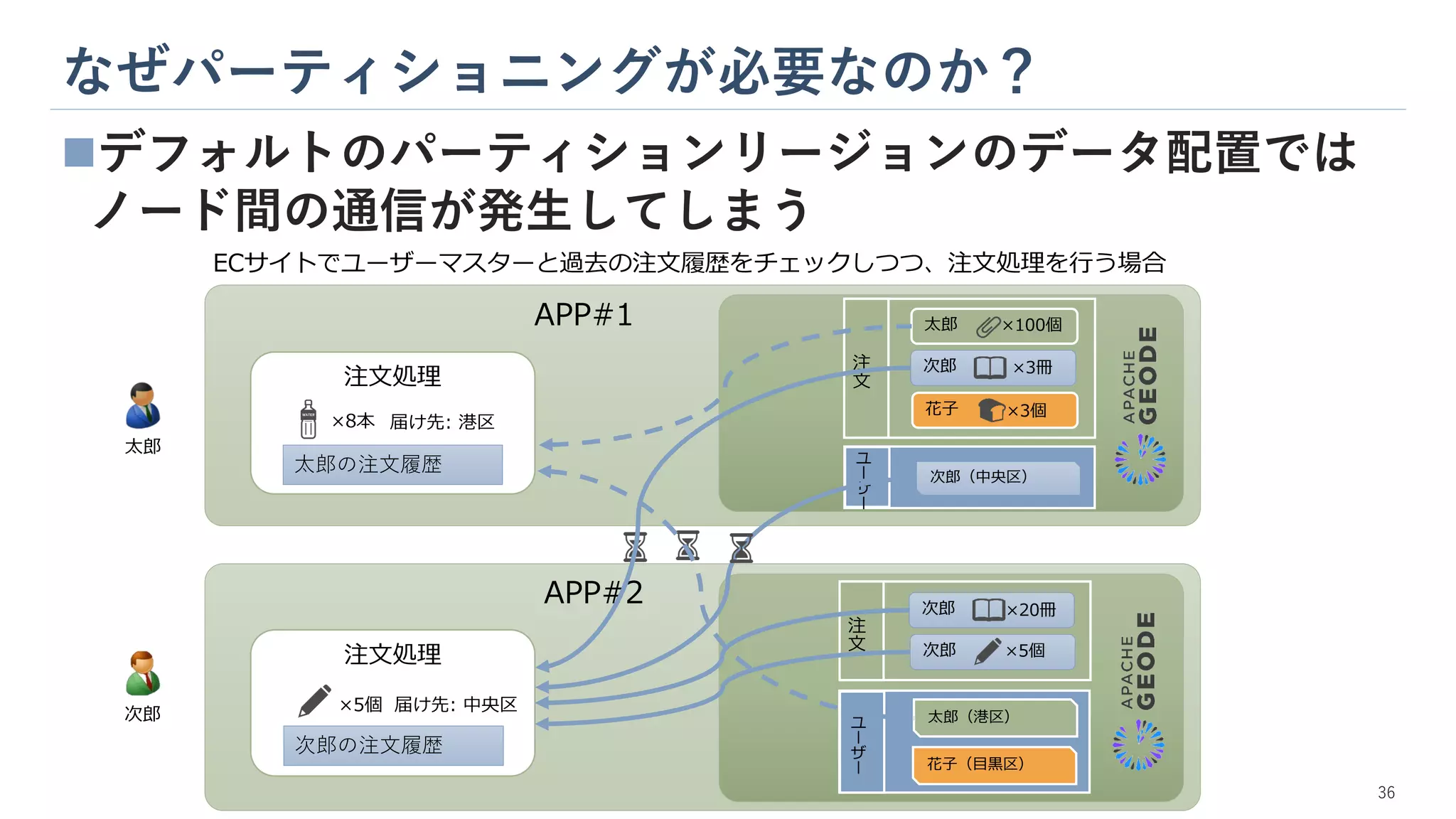
なぜパーティショニングが必要なのか? ◼デフォルトのパーティションリージョンのデータ配置では ノード間の通信が発生してしまう 注文処理 注文処理 ×8本 ×5個 太郎 次郎 太郎の注文履歴 次郎の注文履歴 届け先: 港区 届け先: 中央区 ECサイトでユーザーマスターと過去の注文履歴をチェックしつつ、注文処理を行う場合 花子
×3個 太郎 ×100個 次郎 太郎(港区) 次郎(中央区) 花子(目黒区) 次郎 ×20冊 ×5個 次郎 ×3冊 APP#1 APP#2 注 文 注 文 ユ ー ザ ー ユ ー ザ ー 36
38.
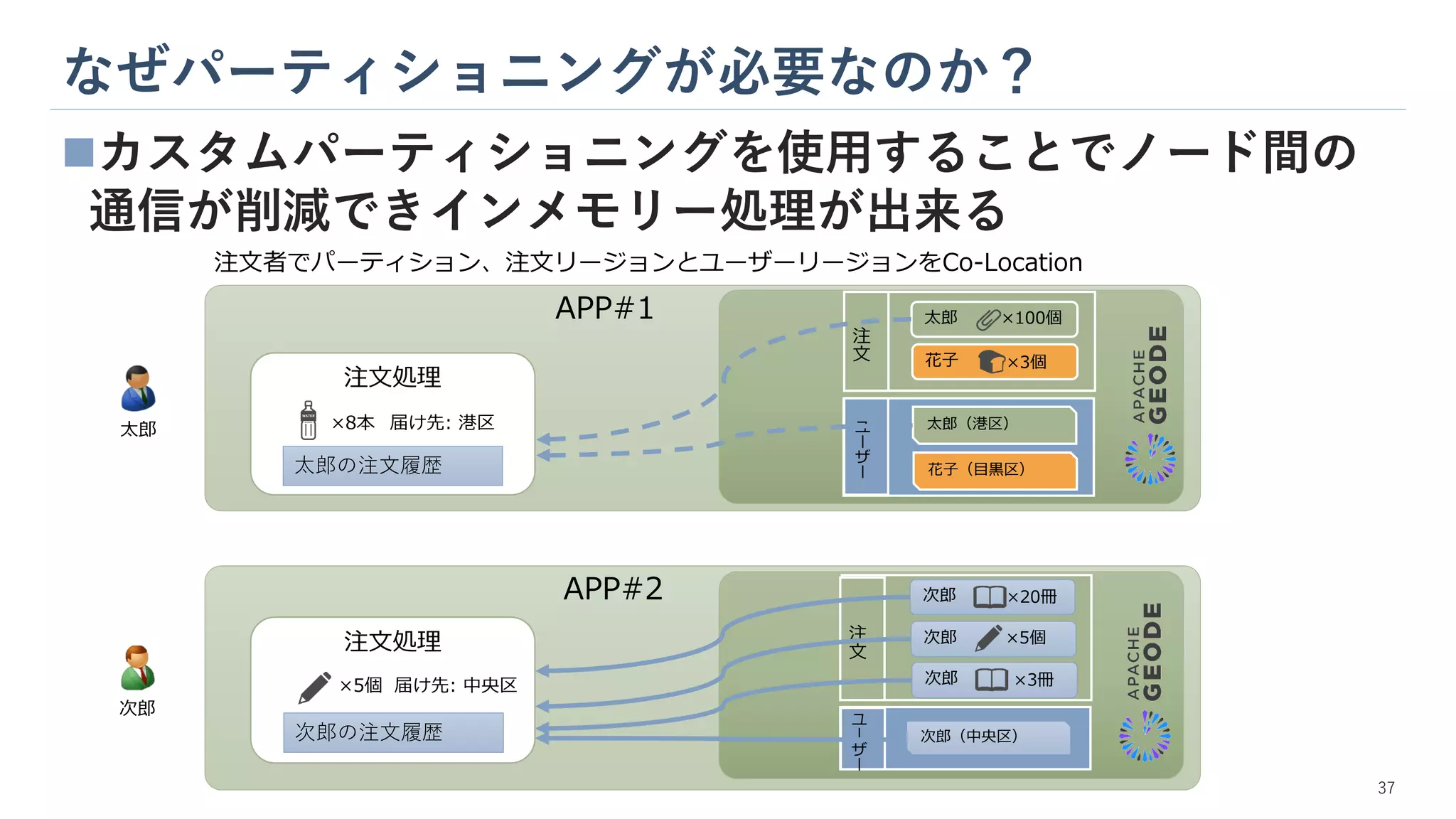
なぜパーティショニングが必要なのか? ◼カスタムパーティショニングを使用することでノード間の 通信が削減できインメモリー処理が出来る 注文処理 注文処理 ×8本 ×5個 太郎 次郎 太郎の注文履歴 次郎の注文履歴 届け先: 港区 届け先: 中央区 花子
×3個 太郎 ×100個 次郎 次郎 ×20冊 ×5個 注 文 注 文 ユ ー ザ ー ユ ー ザ ー 太郎(港区) 花子(目黒区) 次郎(中央区) 次郎 ×3冊 注文者でパーティション、注文リージョンとユーザーリージョンをCo-Location APP#1 APP#2 37
39.
これでKVSが使えるようになりました! 38
40.
Apache Geode 第2の壁 切り出したマイクロサービスへの Apache
Geodeの適用方法 39
41.
永続化の壁 40 ◼複雑な検索向けのRDB永続化 ⚫ リージョンデータをRDBにも登録 ◼メモリー上限 ⚫ RDBのデータをもとにメモリー上のデータを復元
42.
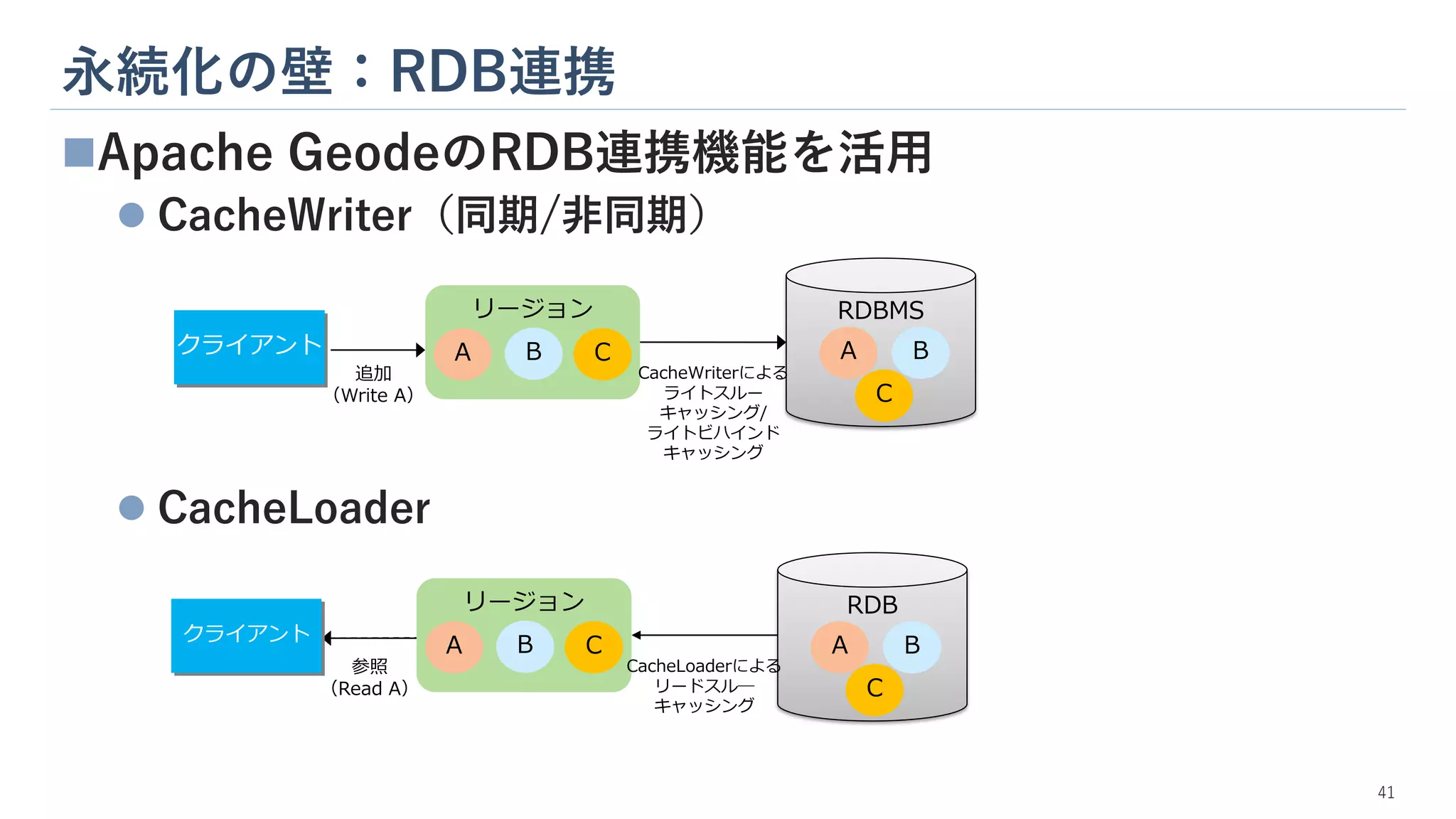
永続化の壁:RDB連携 41 ◼Apache GeodeのRDB連携機能を活用 ⚫ CacheWriter(同期/非同期) ⚫
CacheLoader RDB リージョン 参照 (Read A) CacheLoaderによる リードスル― キャッシング A B C C A B クライアント RDBMS リージョン 追加 (Write A) CacheWriterによる ライトスルー キャッシング/ ライトビハインド キャッシング A B C C A B クライアント
43.
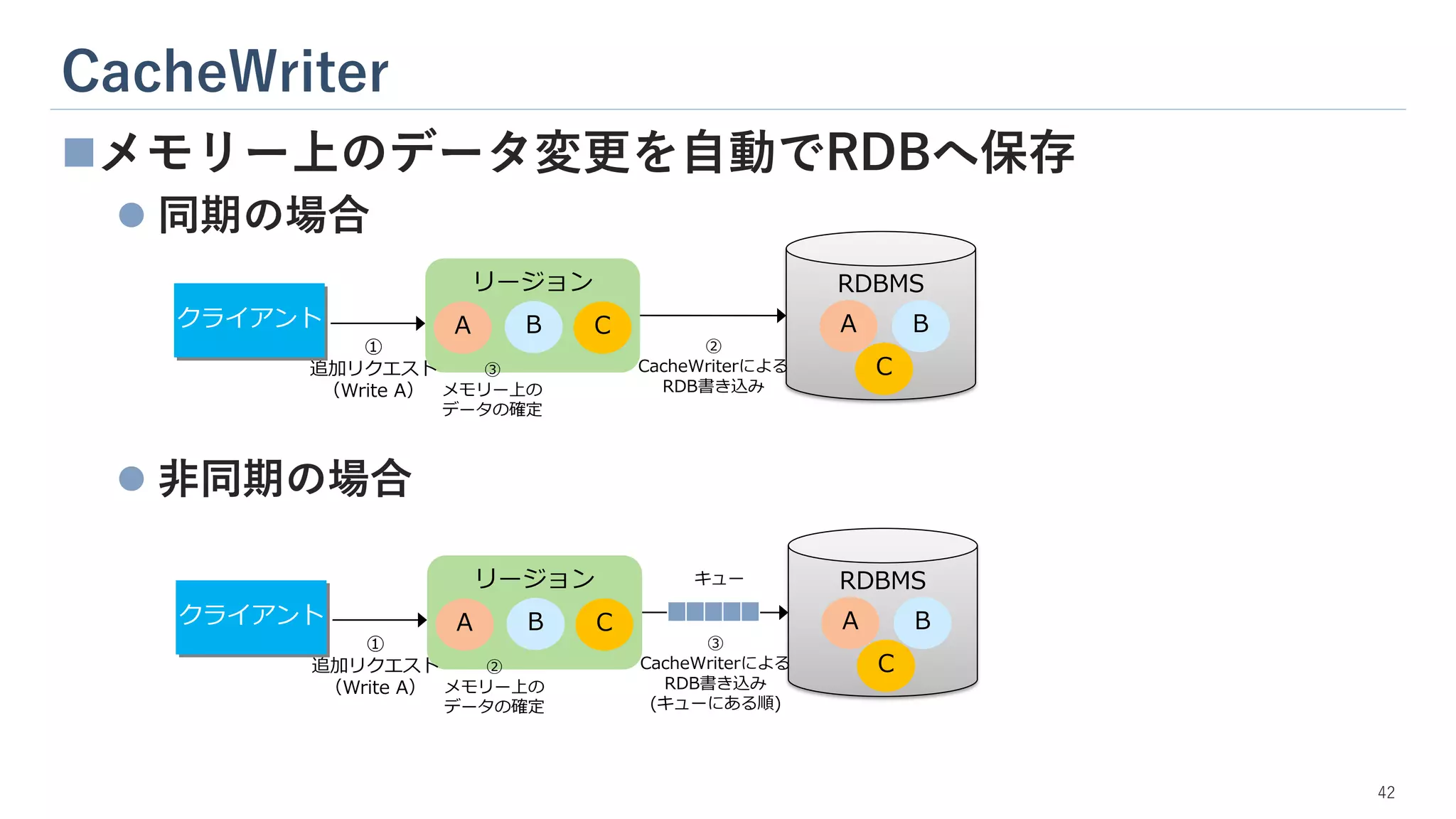
CacheWriter 42 ◼メモリー上のデータ変更を自動でRDBへ保存 ⚫ 同期の場合 ⚫ 非同期の場合 RDBMS リージョン ① 追加リクエスト (Write
A) ② CacheWriterによる RDB書き込み A B C C A B クライアント ③ メモリー上の データの確定 RDBMS リージョン ① 追加リクエスト (Write A) ③ CacheWriterによる RDB書き込み (キューにある順) A B C C A B クライアント ② メモリー上の データの確定 キュー
44.
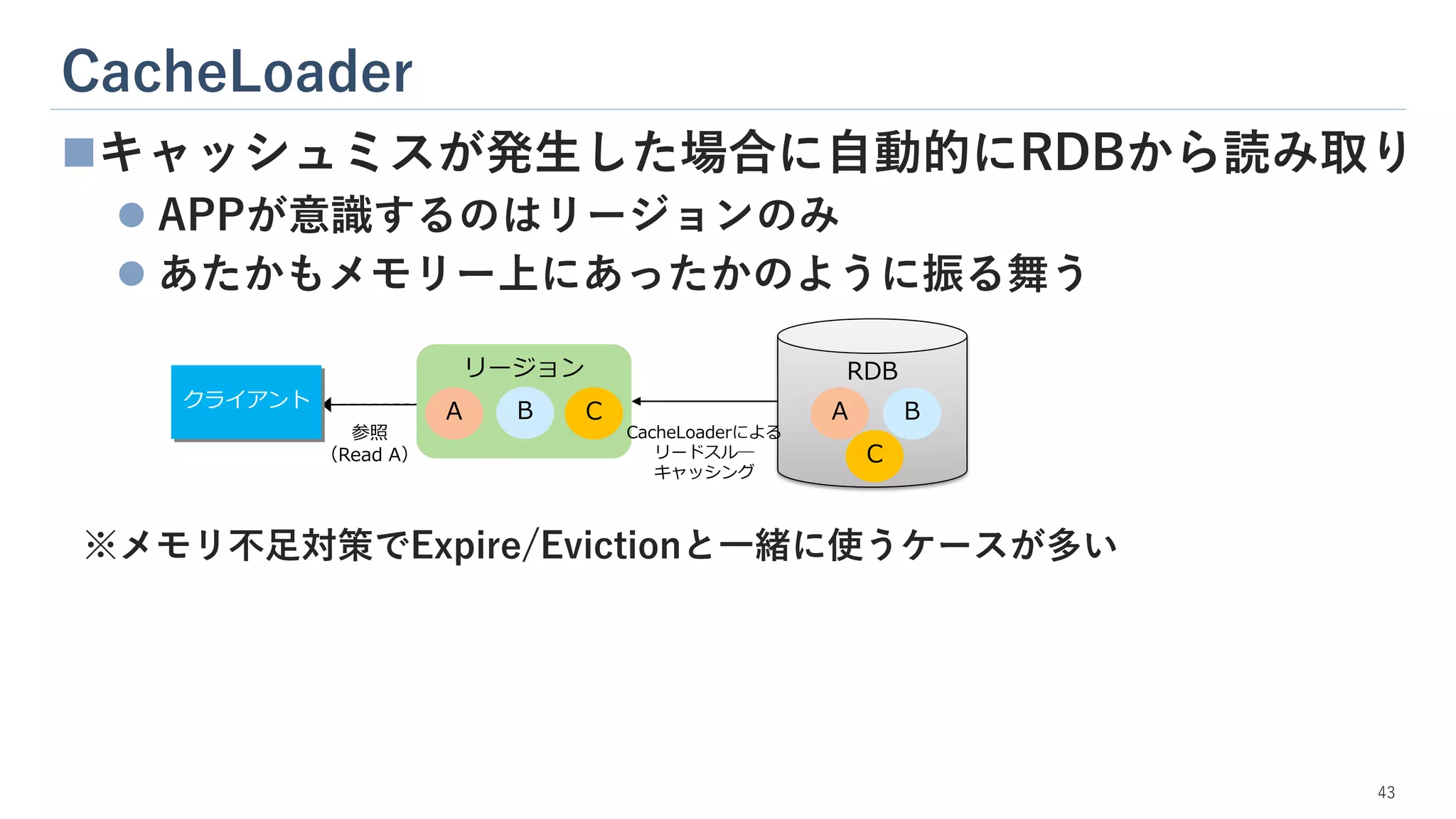
CacheLoader 43 ◼キャッシュミスが発生した場合に自動的にRDBから読み取り ⚫ APPが意識するのはリージョンのみ ⚫ あたかもメモリー上にあったかのように振る舞う ※メモリ不足対策でExpire/Evictionと一緒に使うケースが多い RDB リージョン 参照 (Read
A) CacheLoaderによる リードスル― キャッシング A B C C A B クライアント
45.
RDB連携の設定 44 ◼データソース作成 ⚫ gfsh> create
data-source --name=mysql_data_source --url=“jdbc:mysql://localhost/geode_db“ --username=myuser --password=mypassword ◼リージョン <-> RDBマッピング作成 ⚫ gfsh> create jdbc-mapping --data-source=mysql_data_source --region=Order --table=order --pdx-name=geode.examples.Order --catalog=geode_db --id=orderId
46.
これで実用レベルでGeodeが使えるようになりました 45
47.
CQRS 46
48.
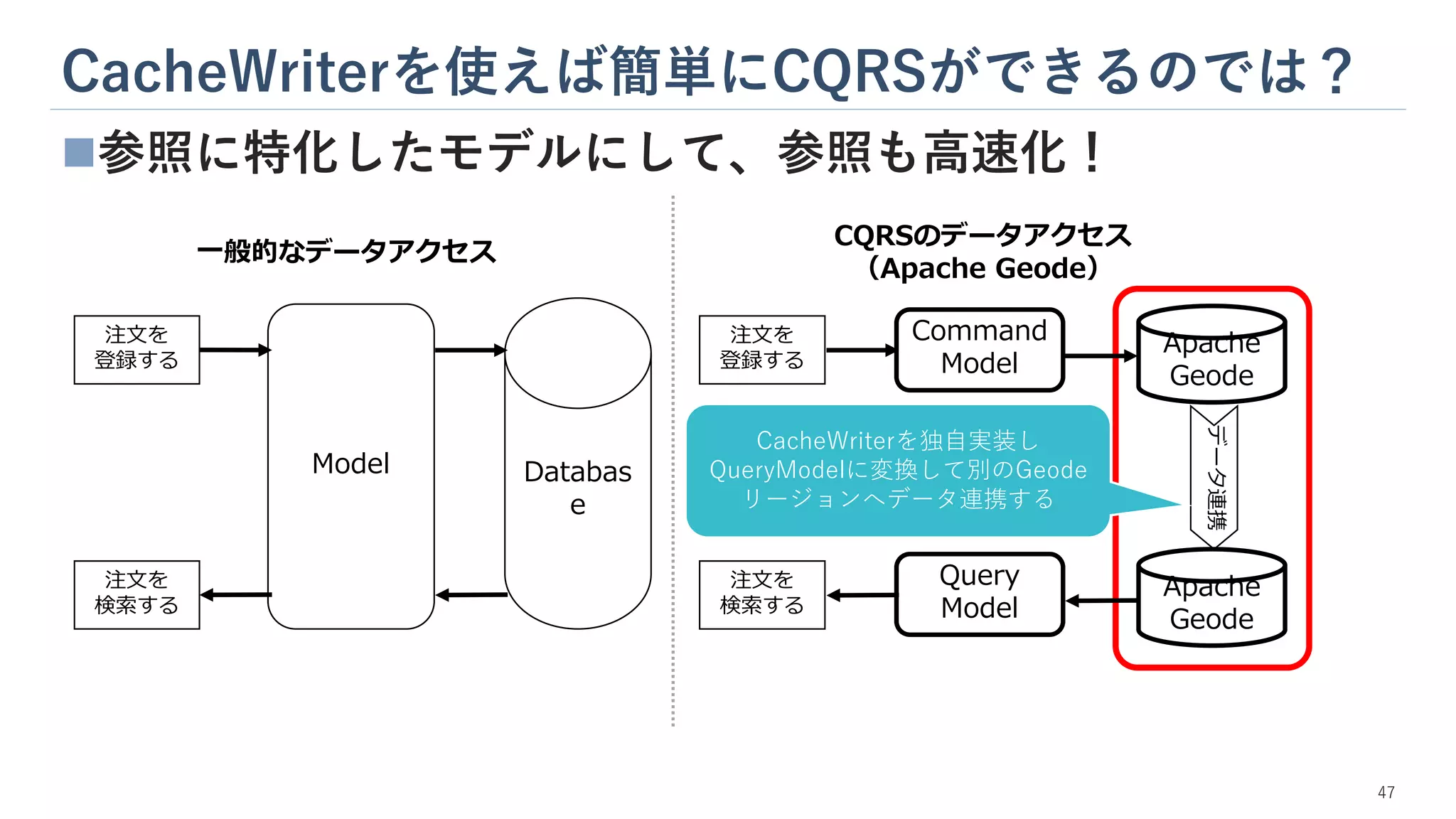
CacheWriterを使えば簡単にCQRSができるのでは? 47 ◼参照に特化したモデルにして、参照も高速化! 注文を 登録する データ連携 Command Model Query Model Apache Geode Apache Geode 注文を 検索する 注文を 登録する Model Databas e 注文を 検索する 一般的なデータアクセス CQRSのデータアクセス (Apache Geode) CacheWriterを独自実装し QueryModelに変換して別のGeode リージョンへデータ連携する
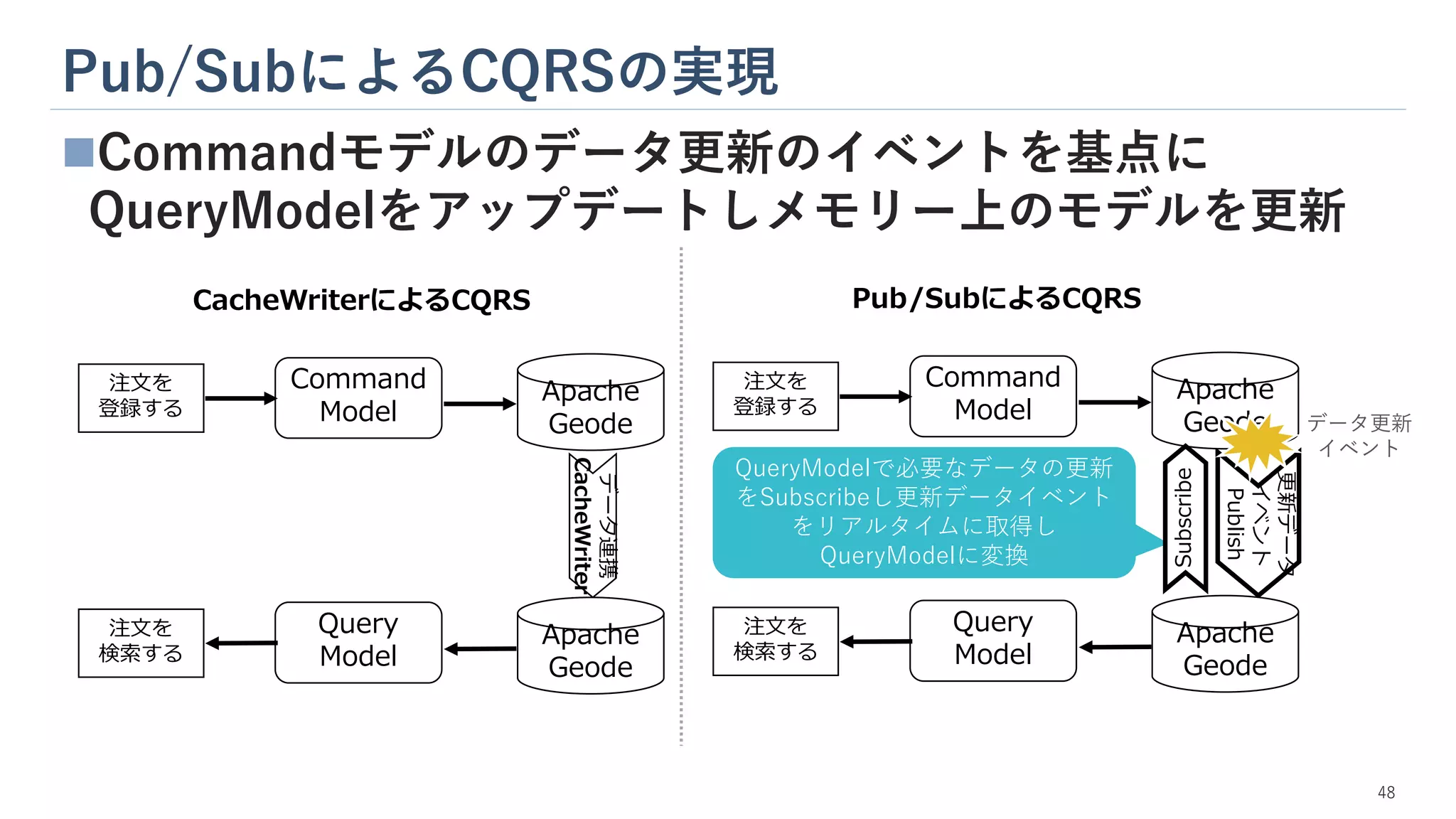
49.
Pub/SubによるCQRSの実現 ◼Commandモデルのデータ更新のイベントを基点に QueryModelをアップデートしメモリー上のモデルを更新 48 注文を 登録する データ連携 CacheWriter Command Model Query Model Apache Geode Apache Geode 注文を 検索する CacheWriterによるCQRS 注文を 登録する 更新データ イベント Publish Command Model Query Model Apache Geode Apache Geode 注文を 検索する Pub/SubによるCQRS QueryModelで必要なデータの更新 をSubscribeし更新データイベント をリアルタイムに取得し QueryModelに変換 データ更新 イベント Subscribe
50.
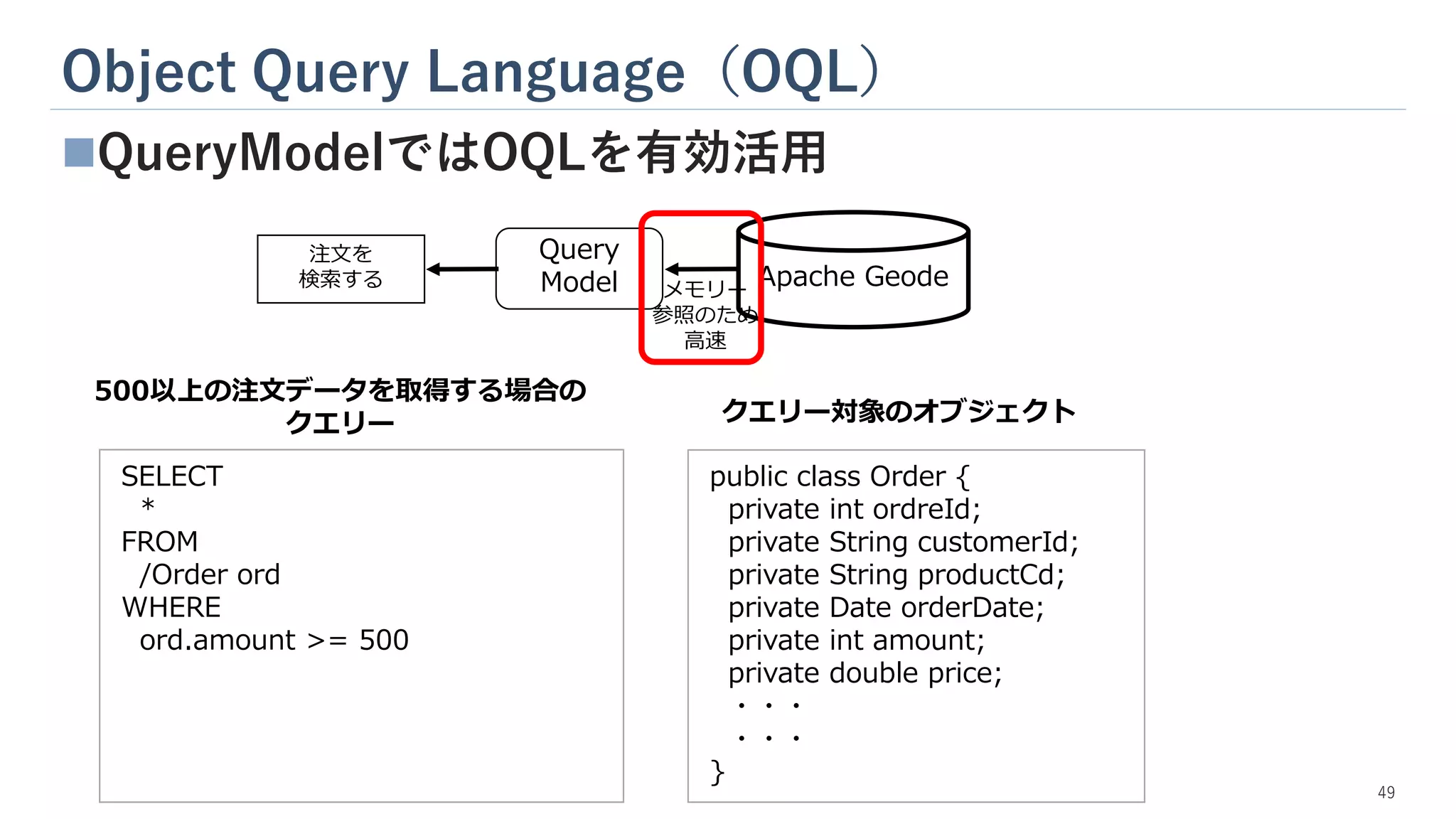
Object Query Language(OQL) ◼QueryModelではOQLを有効活用 public
class Order { private int ordreId; private String customerId; private String productCd; private Date orderDate; private int amount; private double price; ・・・ ・・・ } SELECT * FROM /Order ord WHERE ord.amount >= 500 Query Model Apache Geode 注文を 検索する メモリー 参照のため 高速 500以上の注文データを取得する場合の クエリー クエリー対象のオブジェクト 49
51.
まとめ 50
52.
まとめ 51 Apache Geodeは特定のマイクロサービスを 高速化する際の1つの手段 RDBとのハイブリッド使用で様々なデータアクセスに対応 KVSではキー設計&パーティショニングが重要 高速化のためにRDBと非同期で連携 CQRSパターンでデータ参照を最適化
53.
52 お問合せ先 mailto: info@ulsystems.co.jp http://www.ulsystems.co.jp
Download

![自己紹介
山河 征紀
ウルシステムズ株式会社
コンサルタント
{
“分野” : ”金融系(証券・FX)”,
“得技” : [“インメモリー処理”,
“分散処理”],
“その他” : ”Apache Geodeコミッター”
}
1](https://image.slidesharecdn.com/20211118dbts2021microservicesapachegeode-211118093129/75/20211118-dbts2021-Apache-Geode-2-2048.jpg)








![Geodeクラスター作成
24
◼ロケーター起動
⚫ gfsh> start locator
◼キャッシュサーバー起動
⚫ gfsh> start server --locators=localhost[10334]
✓ポイントはlocatorを指定すること
✓これでクラスターに参加できる](https://image.slidesharecdn.com/20211118dbts2021microservicesapachegeode-211118093129/75/20211118-dbts2021-Apache-Geode-25-2048.jpg)