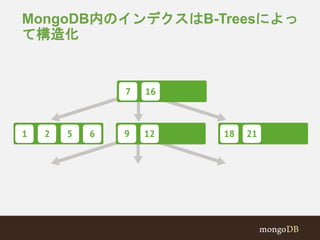
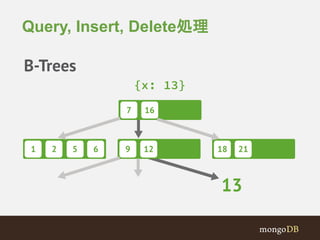
#10 MongoDB's indexes are B-Trees.
Lookups (queries), inserts and deletes happen in O(log(n)) time.
TODO: Add a page describing what a B-Tree is???
#11 So this is helpful, and can speed up queries by a tremendous amount
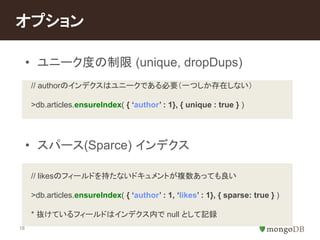
#19 unique applies a uniqueness constant on duplicate values.
dropDups will force the server to create a unique index by only keeping the first document found in natural order with a value and dropping all other documents with that value.
dropDups will likely result in data loss!!! Make sure you know what it does before you use it.
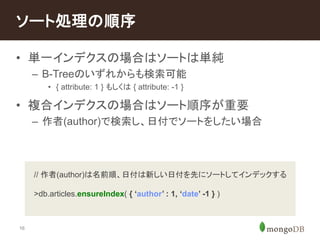
MongoDB doesn't enforce a schema – documents are not required to have the same fields.
Sparse indexes only contain entries for documents that have the indexed field.
Without sparse, documents without field 'a' have a null entry in the index for that field.
With sparse a unique constraint can be applied to a field not shared by all documents. Otherwise multiple 'null' values violate the unique constraint.
#22 cursor – the type of cursor used. BasicCursor means no index was used. TODO: Use a real example here instead of made up numbers…
n – the number of documents that match the query
nscannedObjects – the number of documents that had to be scanned
nscanned – the number of items (index entries or documents) examined
millis – how long the query took
Ratio of n to nscanned should be as close to 1 as possible.
#23 cursor – the type of cursor used. BasicCursor means no index was used. TODO: Use a real example here instead of made up numbers…
n – the number of documents that match the query
nscannedObjects – the number of documents that had to be scanned
nscanned – the number of items (index entries or documents) examined
millis – how long the query took
Ratio of n to nscanned should be as close to 1 as possible.
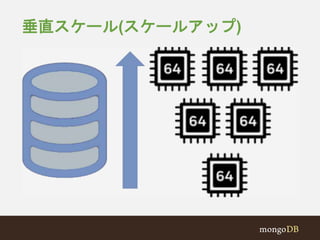
#38 From mainframes, to RAC Oracle servers... People solved problems by adding more resources to a single machine.
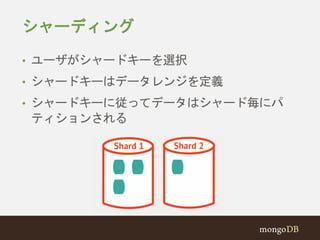
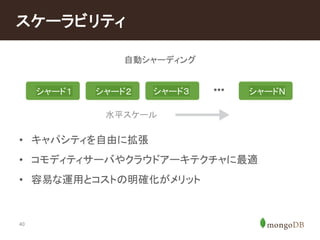
#39 Large scale operation can be combined with high performance on commodity hardware through horizontal scaling
Build
- Document oriented database maps perfectly to object oriented languages
Scale
- MongoDB presents clear path to scalability that isn't ops intensive
- Provides same interface for sharded cluster as single instance




















![2次元球体
• 地理空間上の位置情報をインデクス化
27
– GeoJSON オブジェクトを使用
– 球体の上での2次元位置情報
//GeoJSON インデクスのためのオブジェクト構造
{
name: ’MongoDB Palo Alto’,
location: { type : “Point”,
coordinates: [ 37.449157 , -122.158574 ] }
}
// GeoJSONオブジェクトのインデクス化
>db.articles.ensureIndex( { location: “2dsphere” } )
サポートされるGeoJSON オ
ブジェクト:
Point(点)
LineString(線)
Polygon(ポリゴン)
MultiPoint(複数点)
MultiLineString(複数線)
MultiPolygon(複数ポリゴン)
GeometryCollection (位置情
報コレクション)](https://image.slidesharecdn.com/random-141121152946-conversion-gate02/85/MongoDB-27-320.jpg)
![記事情報の拡張機能
• 記事(article)が投稿さ
28
れた位置情報を記録す
る
• 位置情報はブラウザー
から
Articles コレクション
>db.articles.insert({
'text': 'Article
content…’,
'date' : ISODate(...),
'title' : ’Intro to
MongoDB’,
'author' : ’Joe D’,
'tags' : ['mongodb',
'database',
'nosql’],
‘location’ : {
‘type’ : ‘Point’,
‘coordinates’ :
[37.449, -122.158]
}
});
//位置情報を取得するJavascript機能.
navigator.geolocation.getCurrentPosition();
//GeoJSONデータ構造に変換する必要あり](https://image.slidesharecdn.com/random-141121152946-conversion-gate02/85/MongoDB-28-320.jpg)
![例
29
– 指定した座標値に”近い”場所を検索する
>db.articles.find( {
location: { $near :
{ $geometry :
{ type : "Point”, coordinates : [37.449, -122.158] } },
$maxDistance : 5000
}
} )](https://image.slidesharecdn.com/random-141121152946-conversion-gate02/85/MongoDB-29-320.jpg)



















![[東京] JapanSharePointGroup 勉強会 #2](https://cdn.slidesharecdn.com/ss_thumbnails/jpsps2powershell-120405100646-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









































![[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法](https://cdn.slidesharecdn.com/ss_thumbnails/di08-170605024559-thumbnail.jpg?width=640&height=640&fit=bounds)















