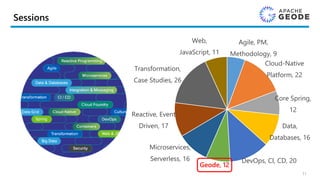
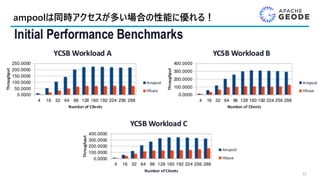
全体を通して12のApache Geodeセッション!
1. ApacheGeode: How Pymma Uses it as an Efficient Alternative to Kafka-Storm-Spark
2. Apache Geode Test Automation and Continuous Integration & Deployment (CI-CD)
3. Caching for Microservices - Introduction to Pivotal Cloud Cache
4. Cloud-Native Data: What is it? Will it Solve the Data-DevOps Divide?
5. Enable SQL/JDBC Access to Apache Geode/GemFire Using Apache Calcite
6. Exploring Data-Driven, Cognitive Capabilities in Pivotal Cloud Foundry
7. High Performance Cloud Native APIs Using Apache Geode
8. RDBMS and Apache Geode Data Movement: Low Latency ETL Pipeline By Using Cloud-
Native Event Driven Microservices
9. Real-Time Analytics for Data-Driven Applications
10. Scaling Spring Boot Applications in Real-Time
11. Simplifying Apache Geode with Spring Data
12. Spring Driven Industrial IoT Utilizing Edge, Fog, and Cloud Computing 12
14.
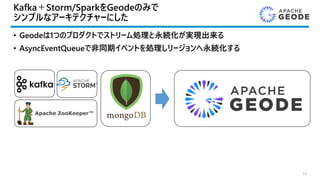
セッション
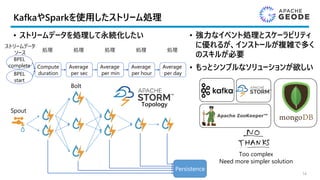
- Apache Geode:How Pymma Uses it
as an Efficient Alternative to Kafka-Storm-Spark -
Part 2
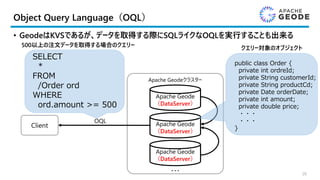
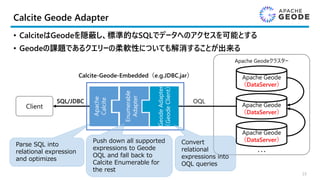
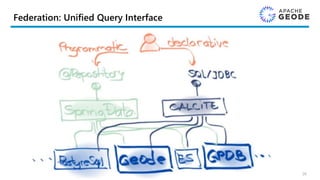
Calcite Geode Adapter
•CalciteはGeodeを隠蔽し、標準的なSQLでデータへのアクセスを可能とする
• Geodeの課題であるクエリーの柔軟性についても解消することが出来る
Client
Apache Geodeクラスター
Apache Geode
(DataServer)
Apache Geode
(DataServer)
Apache Geode
(DataServer)
・・・
Apache
Calcite
Enumerable
Adapter
GeodeAdapter
(GeodeClient)
SQL/JDBC
Calcite-Geode-Embedded(e.g.JDBC.jar)
OQL
Parse SQL into
relational expression
and optimizes
Push down all supported
expressions to Geode
OQL and fall back to
Calcite Enumerable for
the rest
Convert
relational
expressions into
OQL queries
23
25.
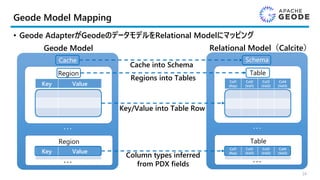
Geode Model Mapping
•Geode AdapterがGeodeのデータモデルをRelational Modelにマッピング
24
Cache
Region
Key Value
Region
・・・
Schema
Table
Col1
(Key)
Col2
(Val1)
Col3
(Val2)
Col4
(Val3)
Table
・・・
Geode Model
・・・ ・・・
Relational Model(Calcite)
Cache into Schema
Regions into Tables
Key/Value into Table Row
Column types inferred
from PDX fields
Key Value
Col1
(Key)
Col2
(Val1)
Col3
(Val2)
Col4
(Val3)
26.
Pros & Cons
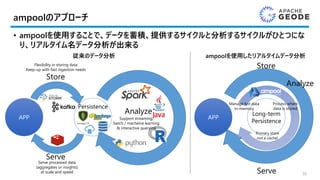
•Ad-hoc data exploration
• JDBC integration with 3rd party tools
• Data Federation, correlate Geode with
other data sources
• SQL Streaming as CQ++
• No-intrusive and extensible approach
• What happened with SQLFire?
• Geode == Transactional System!
SQL+Geode <> Analytical System!
• Key/Value vs. Full Scan
• Overhead: SQL > OQL > Functions
• Data at Rest (Table) vs. Data at Motion
(Stream)
25
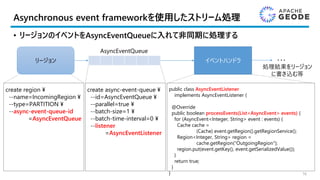
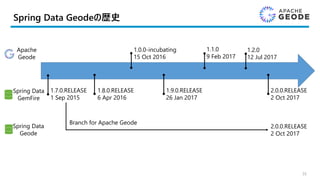
Spring Data Geodeの歴史
35
SpringData
GemFire
1.7.0.RELEASE
1 Sep 2015
Spring Data
Geode
Branch for Apache Geode
2.0.0.RELEASE
2 Oct 2017
2.0.0.RELEASE
2 Oct 2017
1.8.0.RELEASE
6 Apr 2016
1.9.0.RELEASE
26 Jan 2017
Apache
Geode
1.0.0-incubating
15 Oct 2016
1.1.0
9 Feb 2017
1.2.0
12 Jul 2017
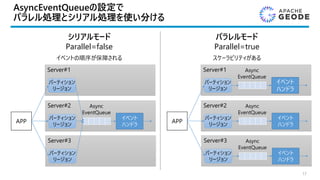
Spring Data GemFireとSpringData Geodeの違いは?
• 2つのプロダクトに差異はない
• Spring Data GemFireからSpring Data Geodeへの移行を最小限にすることを優先
37
Apache Geode 1.2.1
Pivotal GemFire 9.1.1
Spring Data Geode 2.0.0
Spring Data GemFire 2.0.0
対応する
Spring Dataバージョン
違いはない
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-gemfire</artifactId>
↓
<artifactId>spring-data-geode</artifactId>
<version>2.0.0.RELEASE</version>
</dependency>
SpringData GemFireからSpringData Geodeへ
の移行に必要なのはMaven、Gradleの依存設定
を変更するのみ
39.
Spring Data Geode2.0 Kay
• Upgrades to Apache Geode 1.2.0 (GA) release.
• Upgrades to Spring Framework 5.0.0.RELEASE.
• Upgrades to Spring Data Commons Kay.
• Additional improvements in the new Annotation-based
configuration model.
• Support Apache Geode’s Apache Lucene Integration.
38
40.
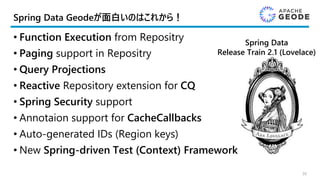
Spring Data Geodeが面白いのはこれから!
•Function Execution from Repositry
• Paging support in Repositry
• Query Projections
• Reactive Repository extension for CQ
• Spring Security support
• Annotaion support for CacheCallbacks
• Auto-generated IDs (Region keys)
• New Spring-driven Test (Context) Framework
39
Spring Data
Release Train 2.1 (Lovelace)


![自己紹介
山河 征紀
ウルシステムズ株式会社
マネージングコンサルタント
{
“分野”:”金融系”
“得技”:[“分散処理”,
“インメモリー処理”]
“趣味”:”マラソン”
}
1
一応、Apache GeodeのContributorです
ただし、サンデープログラマー](https://image.slidesharecdn.com/apachegeode-at-s1p-180327094645/85/Apache-geode-at-s1p-2-320.jpg)


























































![[db tech showcase OSS 2017] A14: IoT時代のデータストア--躍進するNoSQL、拡張するRDB by OSSコンソーシア...](https://cdn.slidesharecdn.com/ss_thumbnails/20170616dbtechshowcaseossyoshida-170621081930-thumbnail.jpg?width=640&height=640&fit=bounds)

























