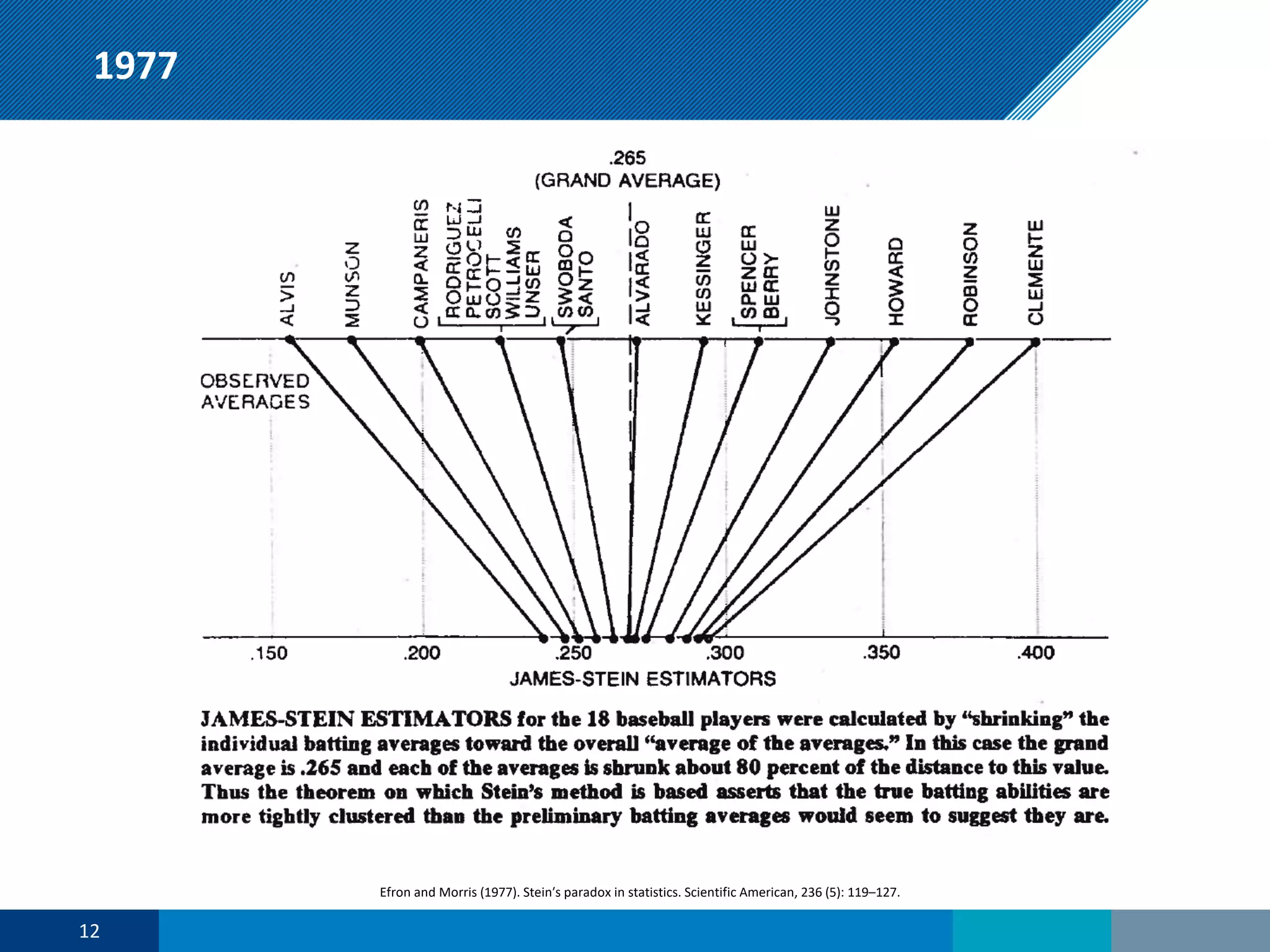
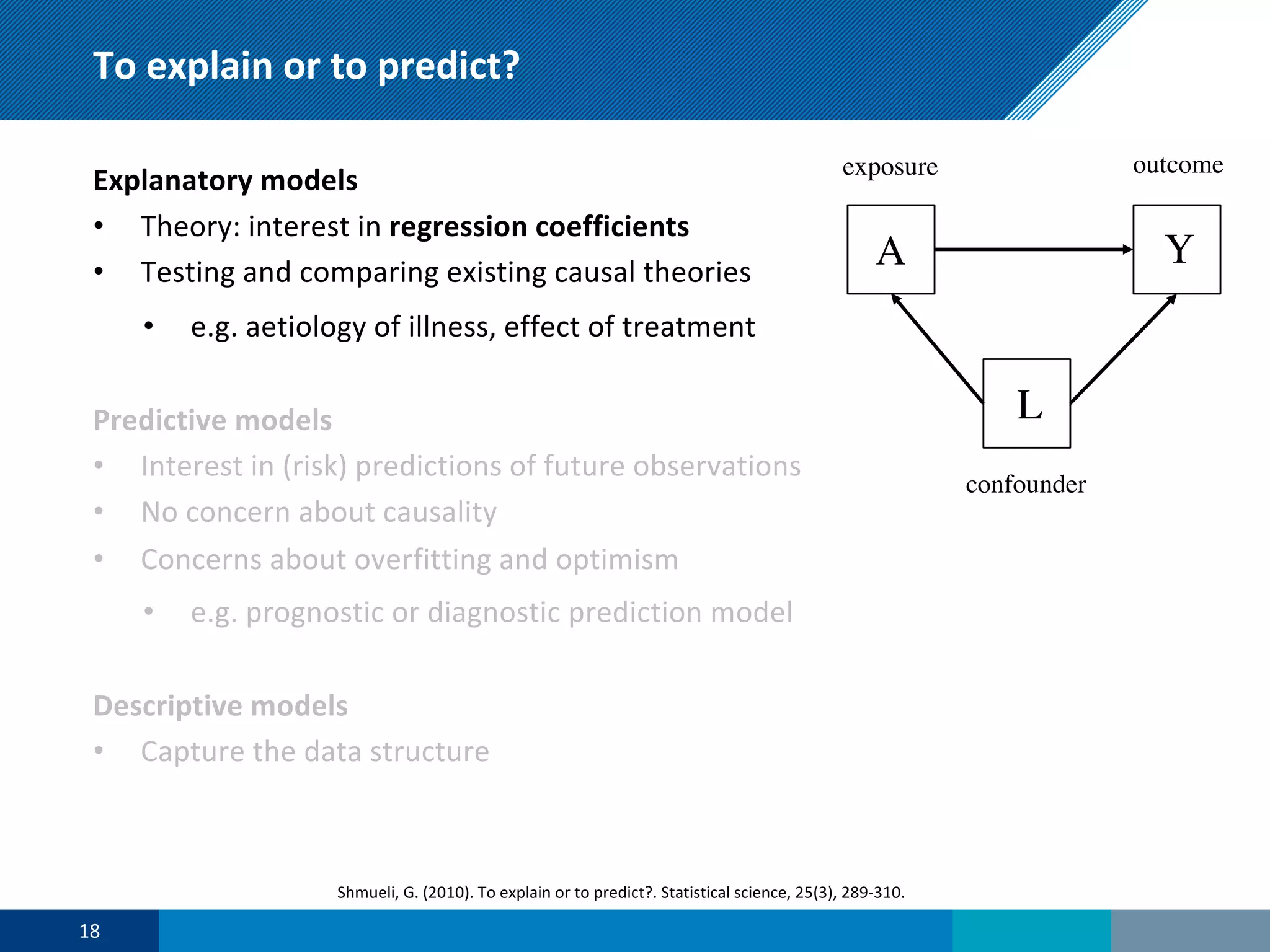
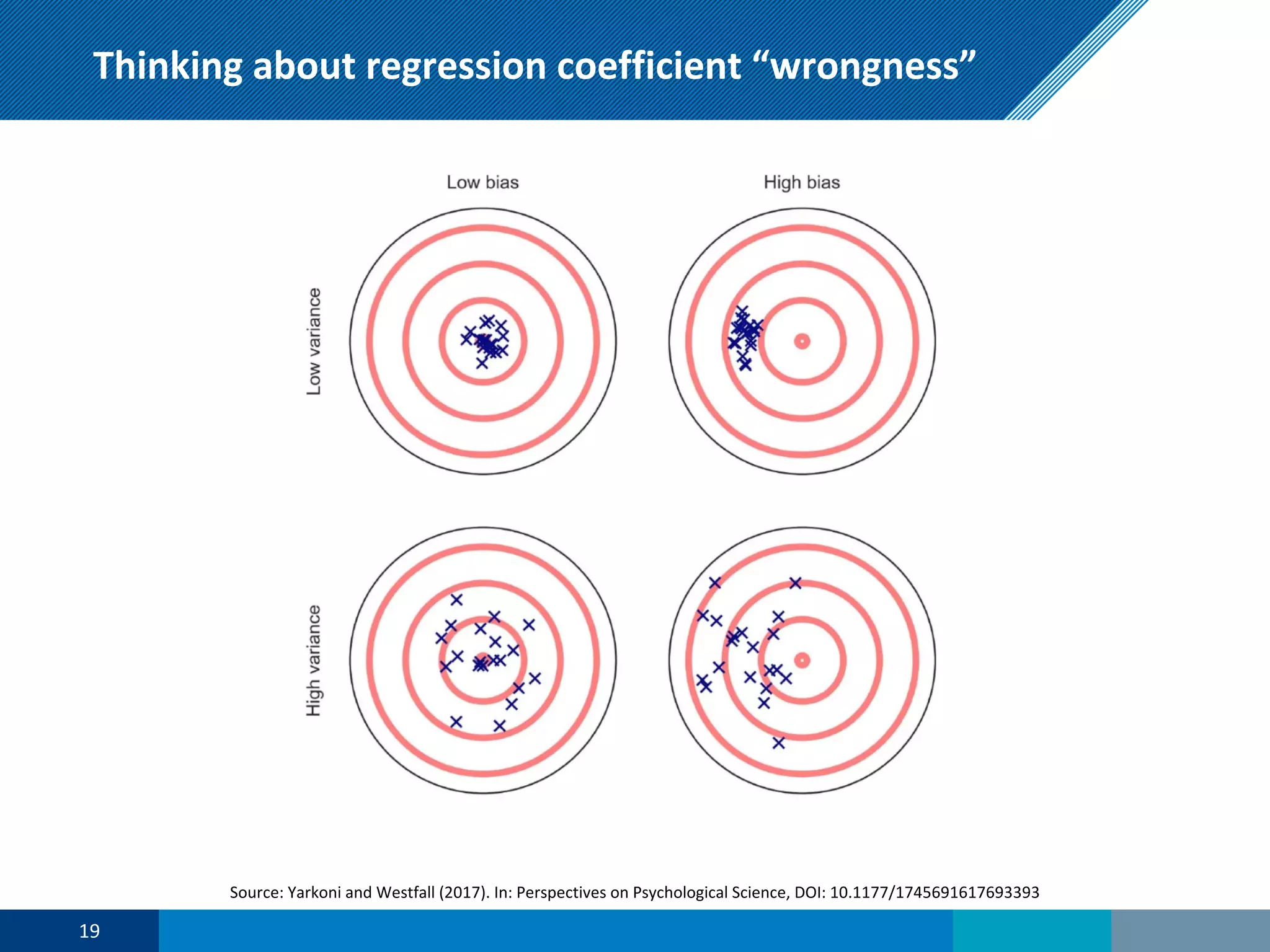
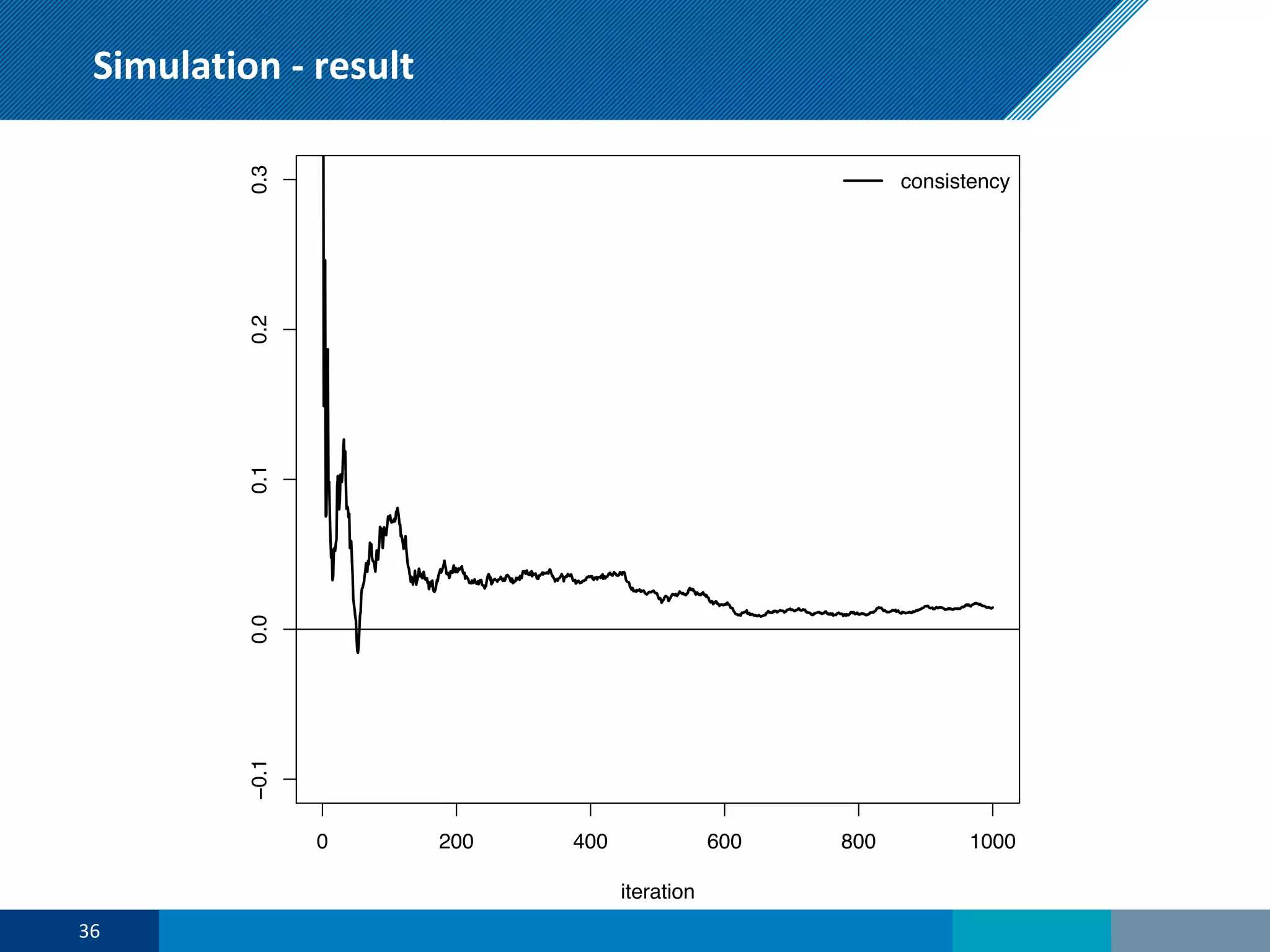
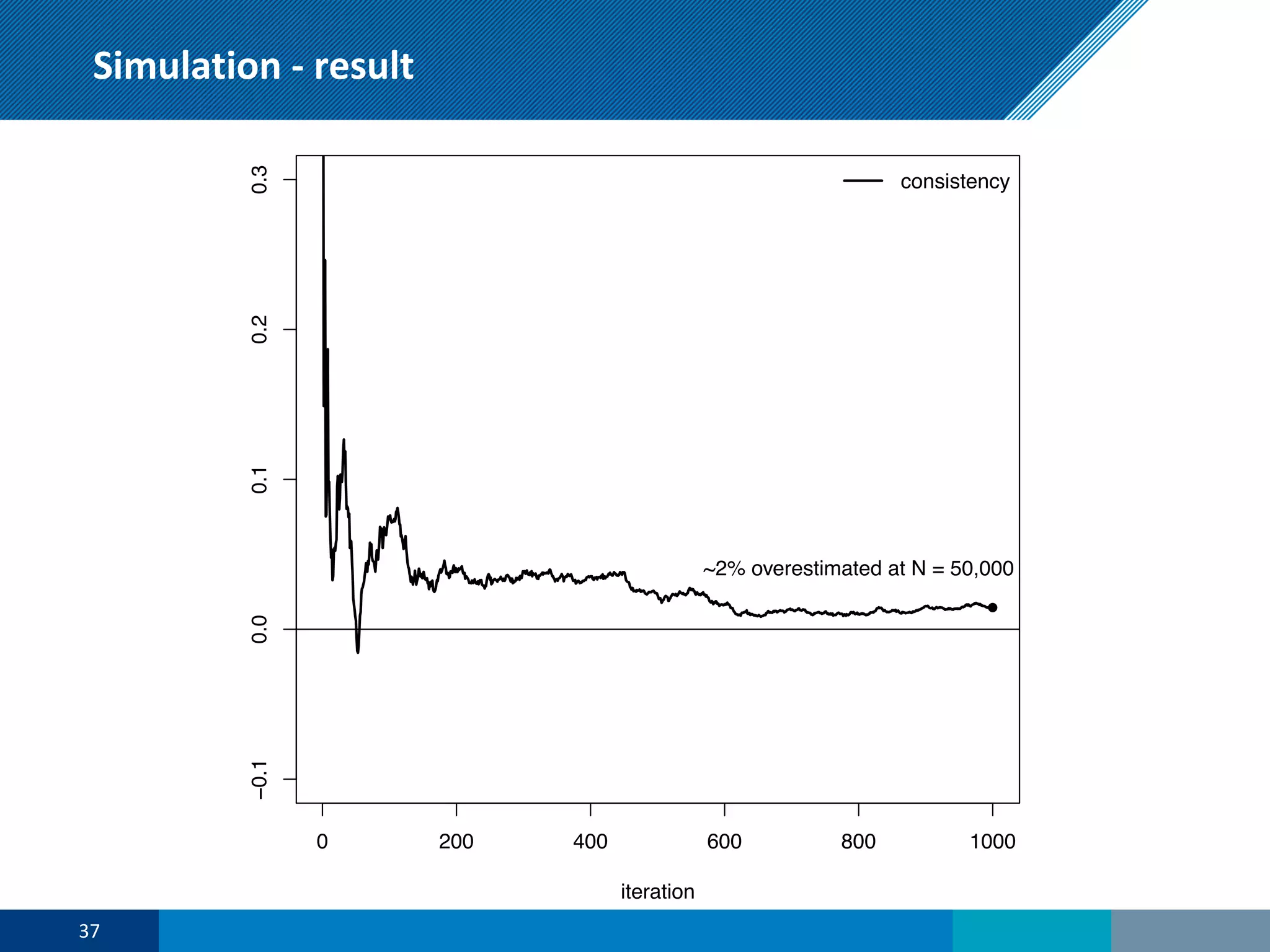
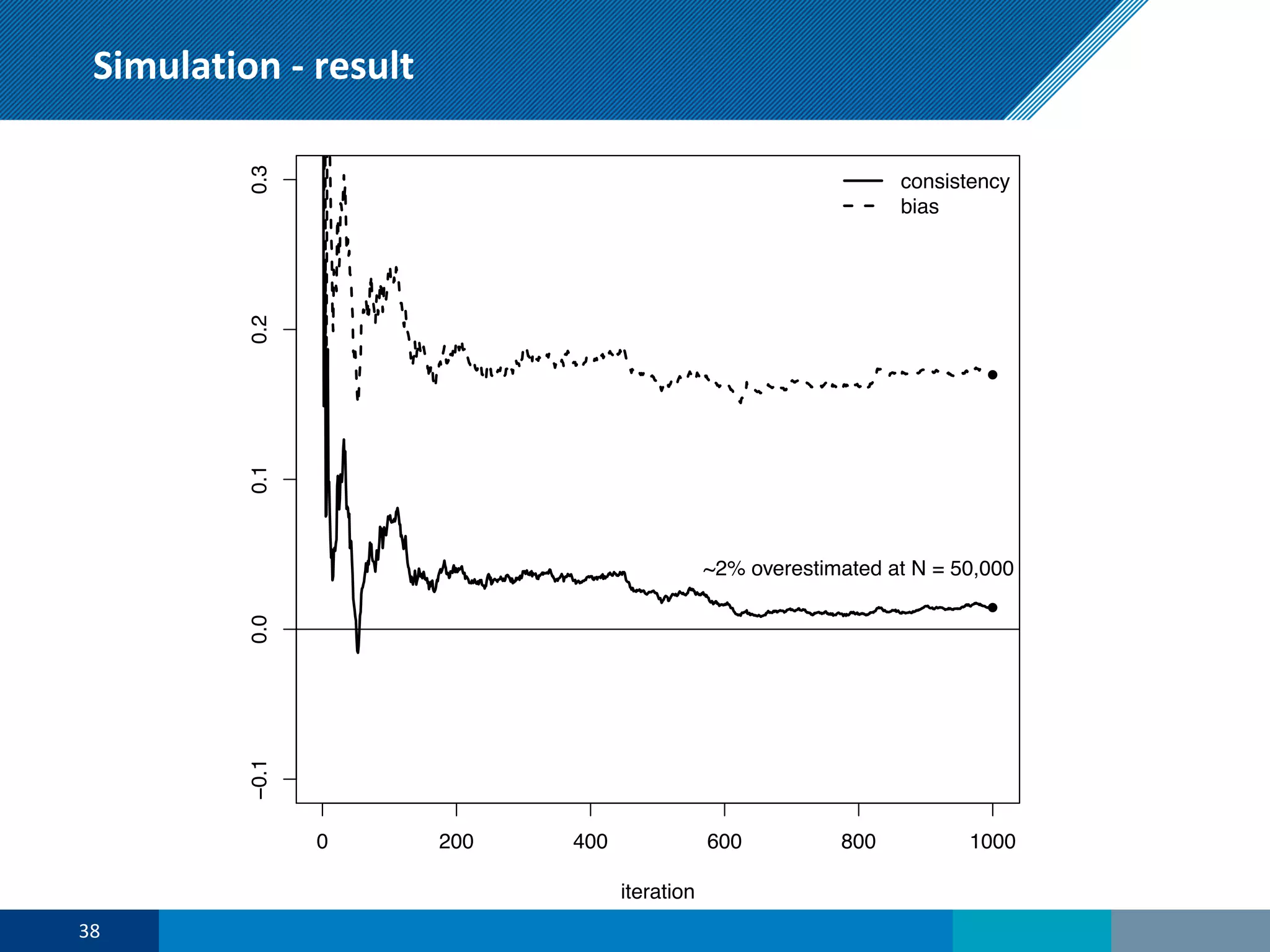
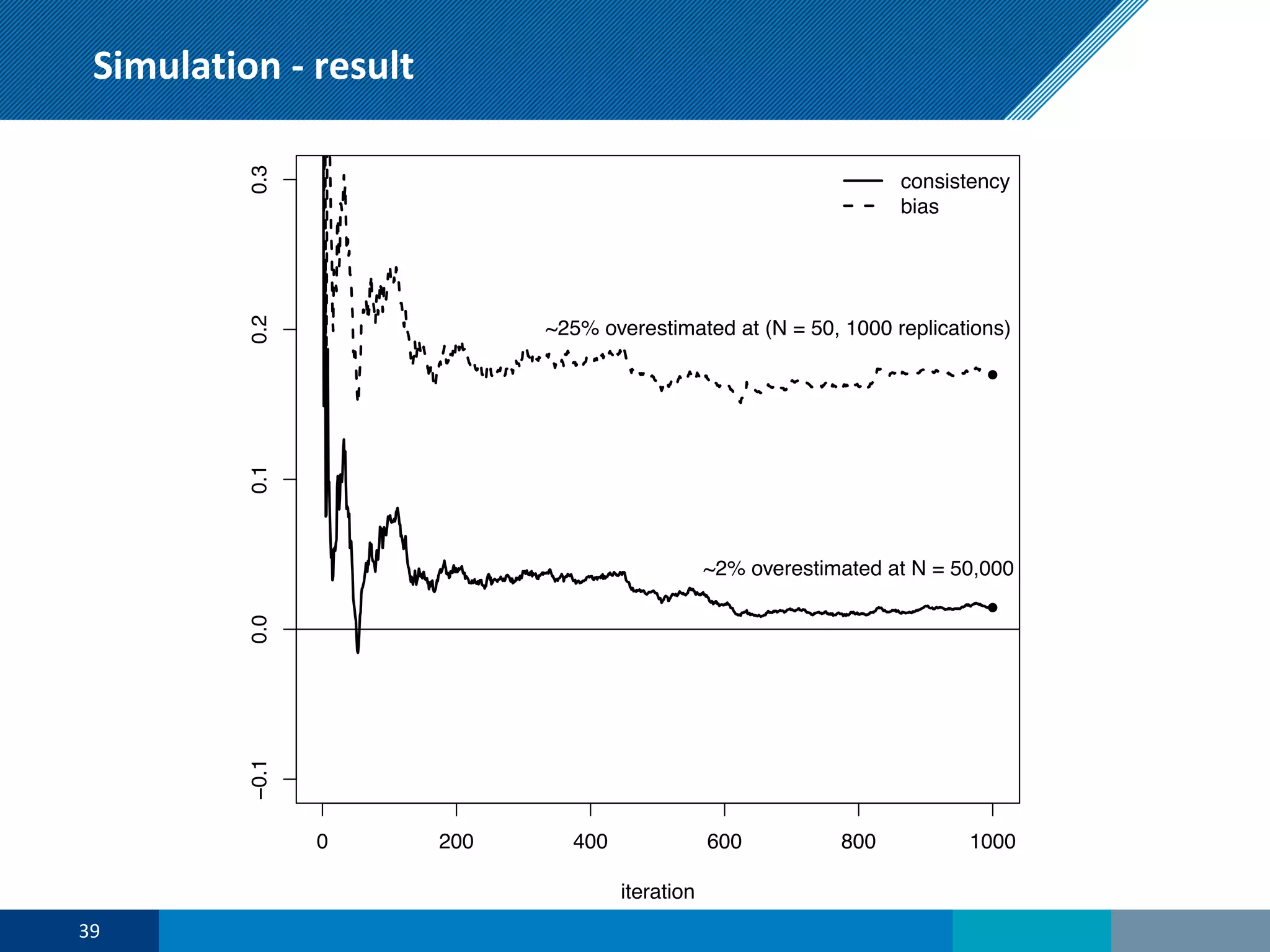
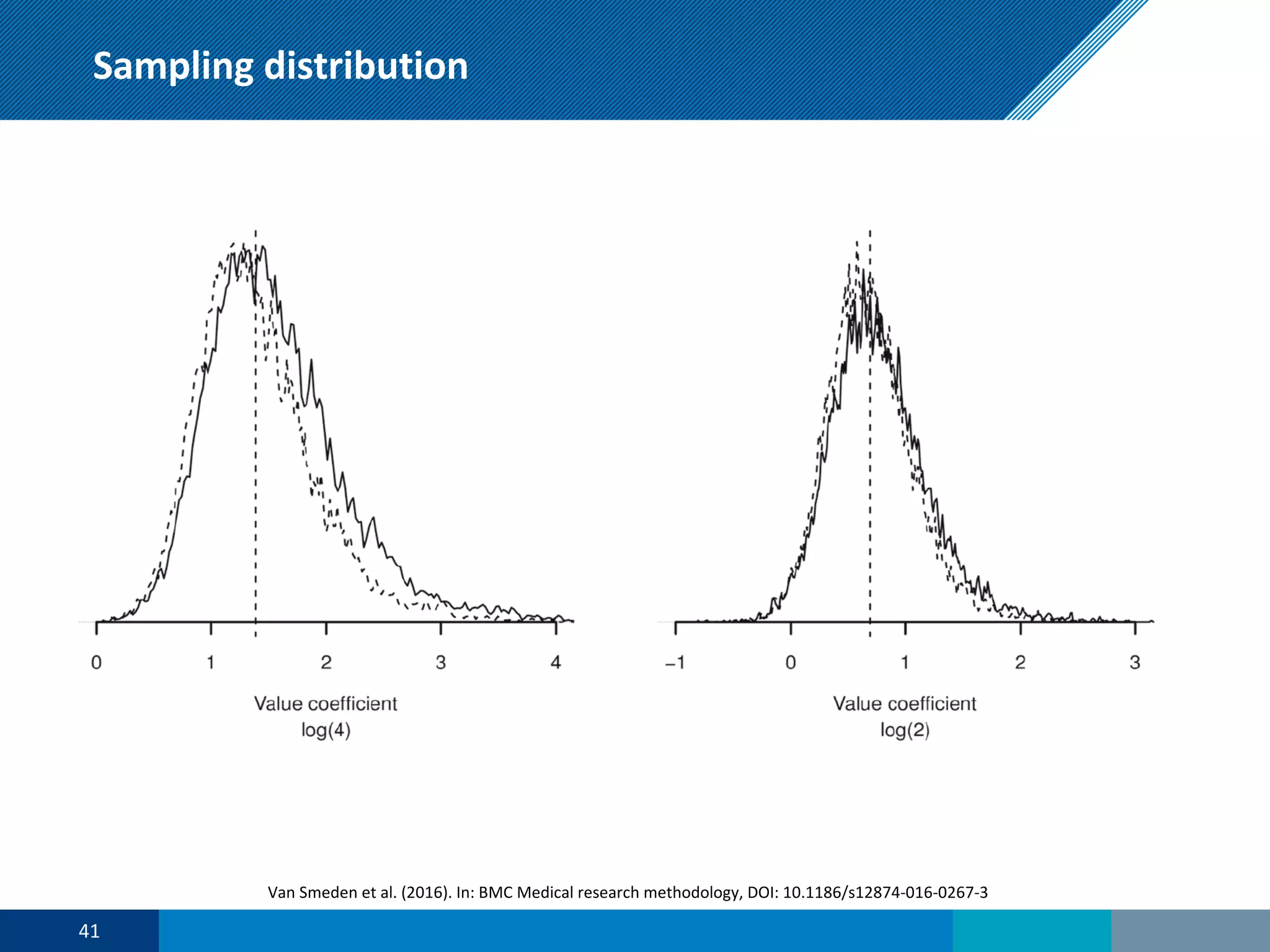
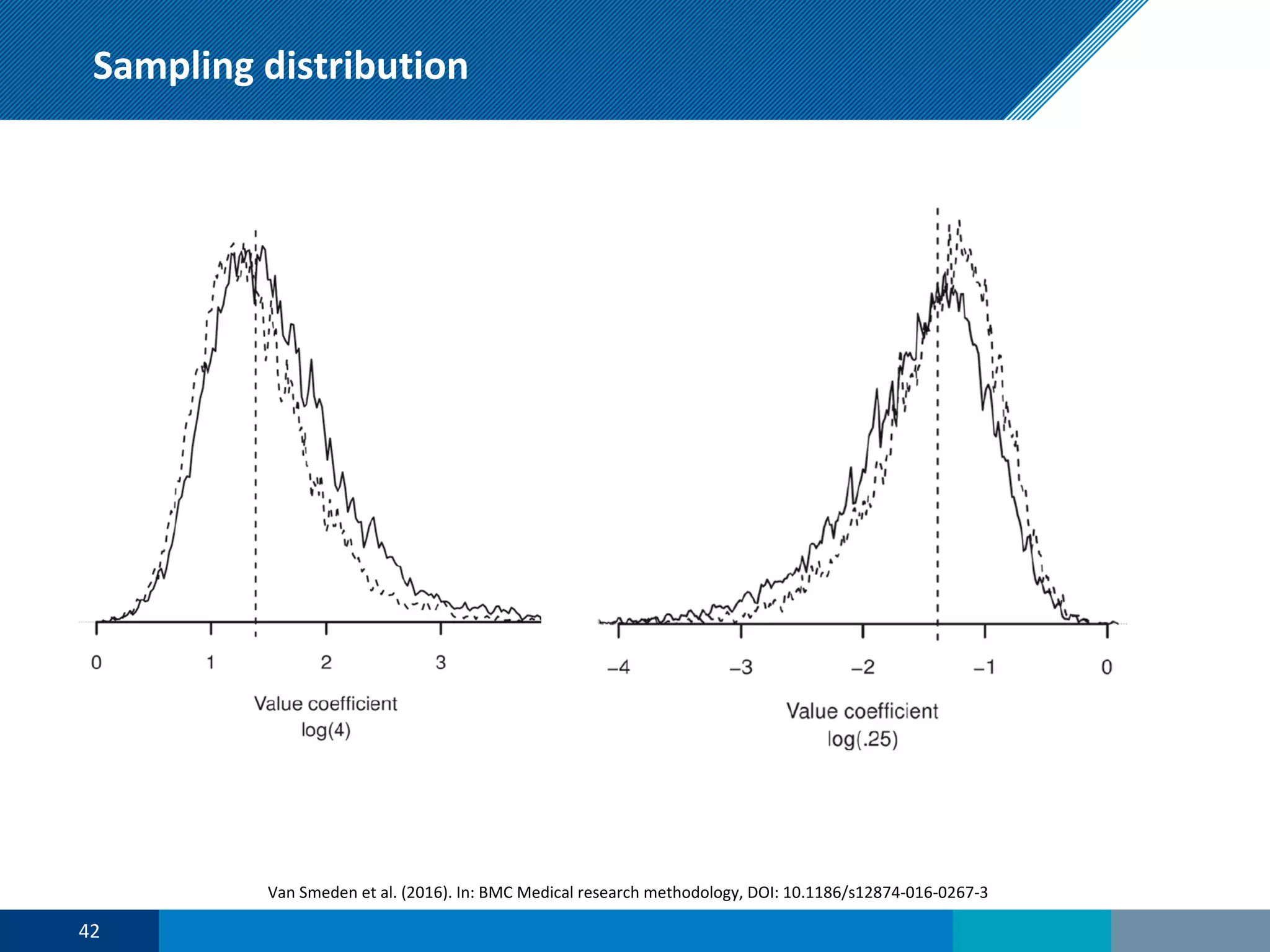
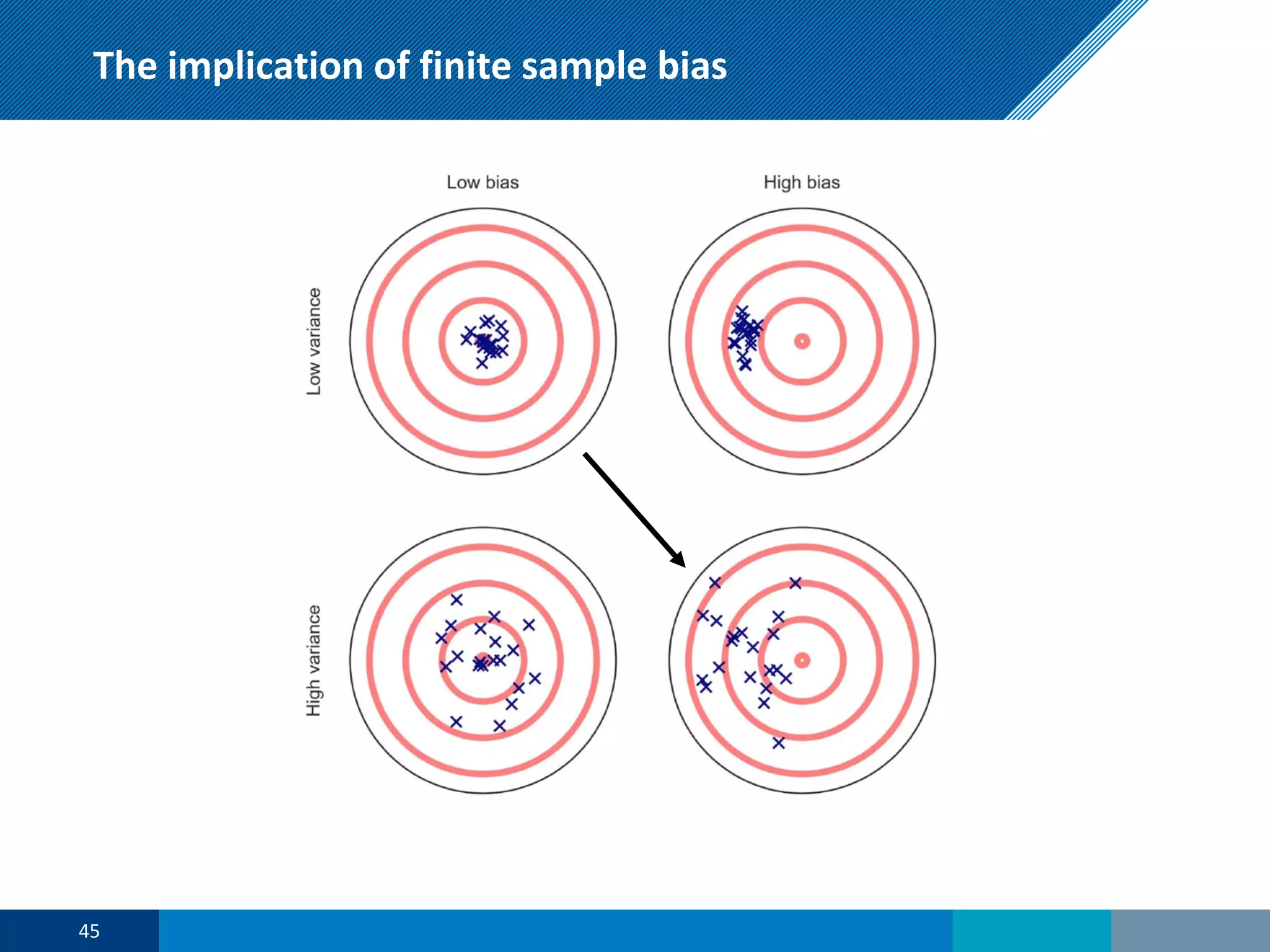
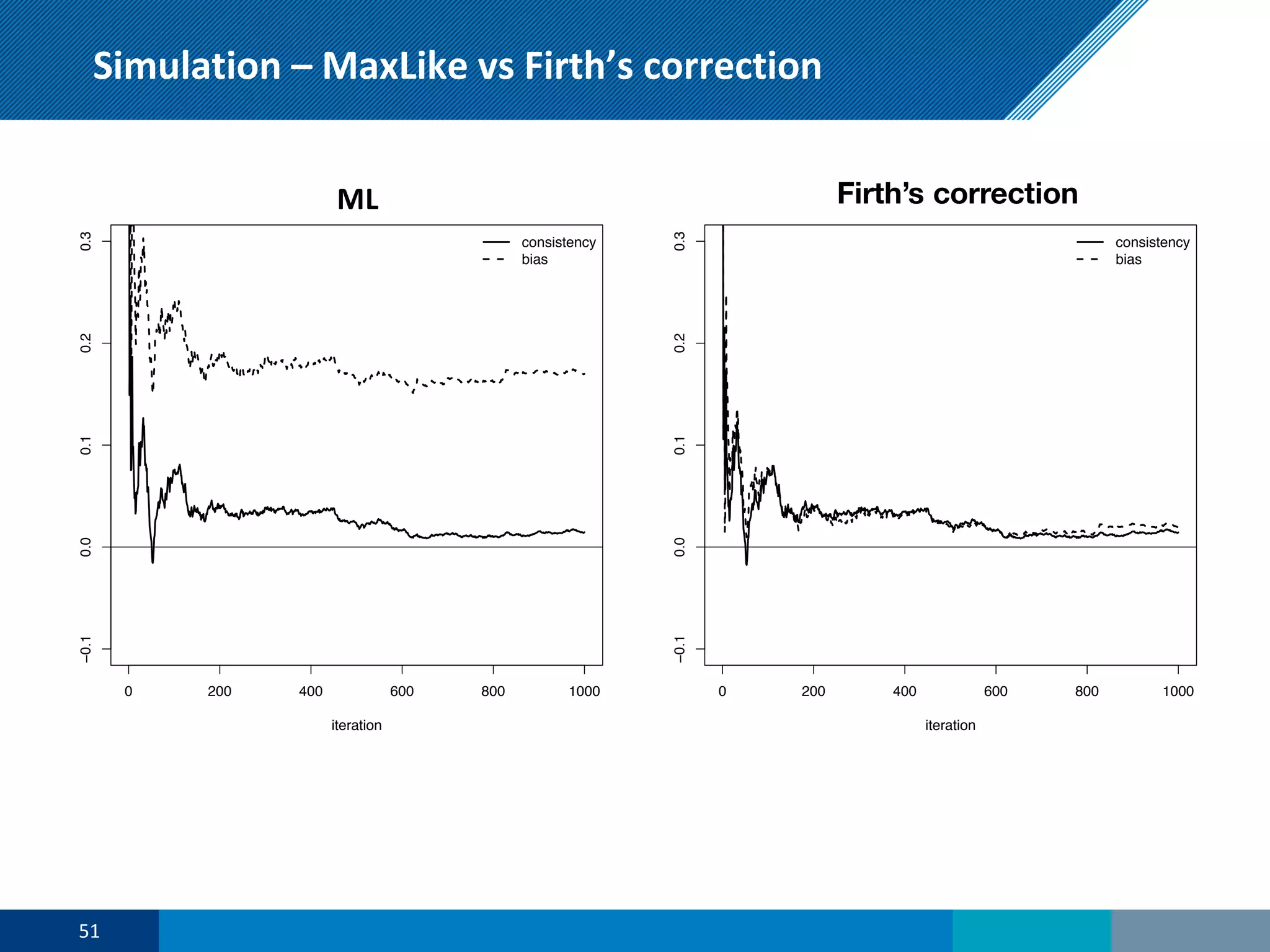
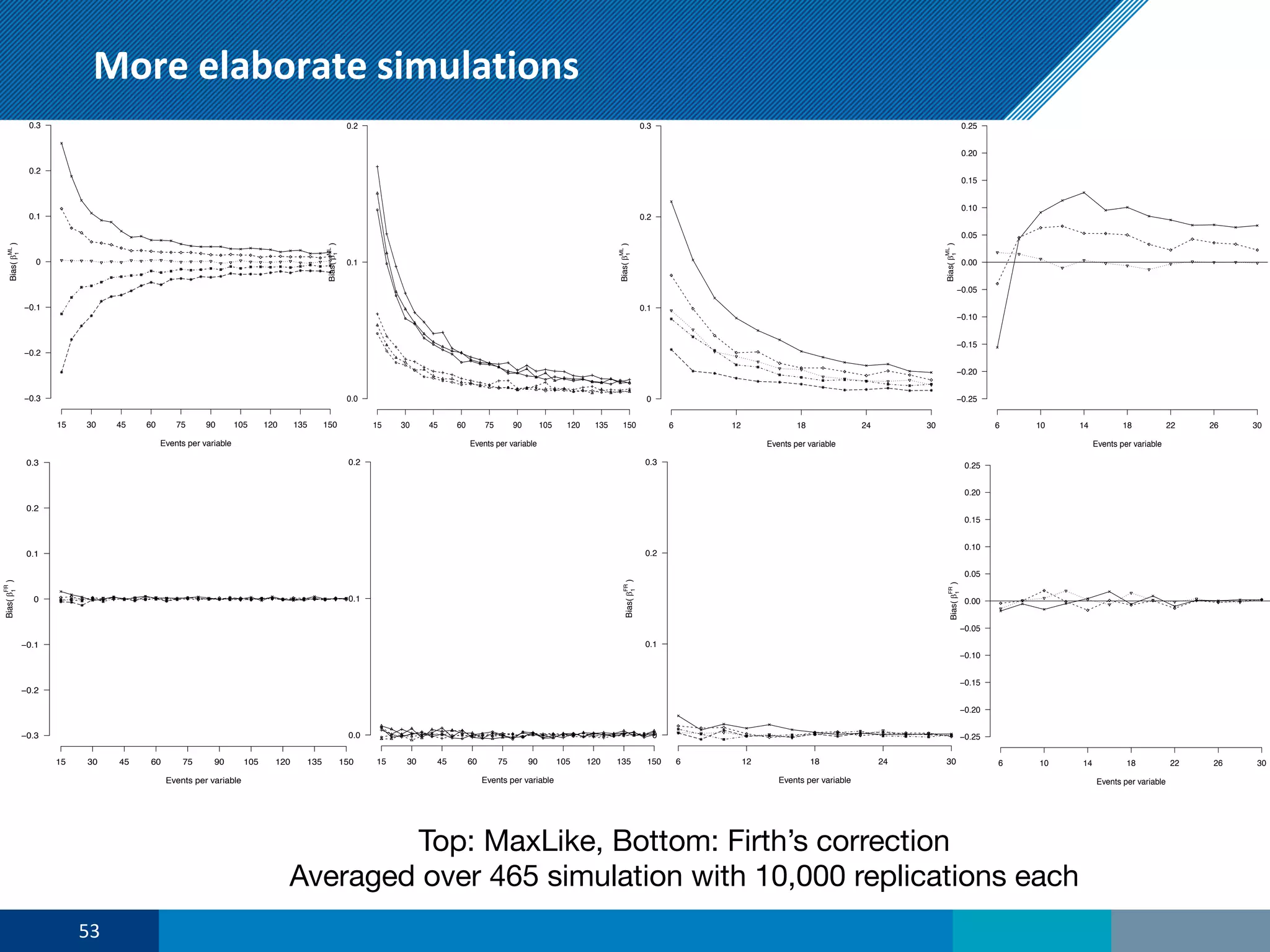
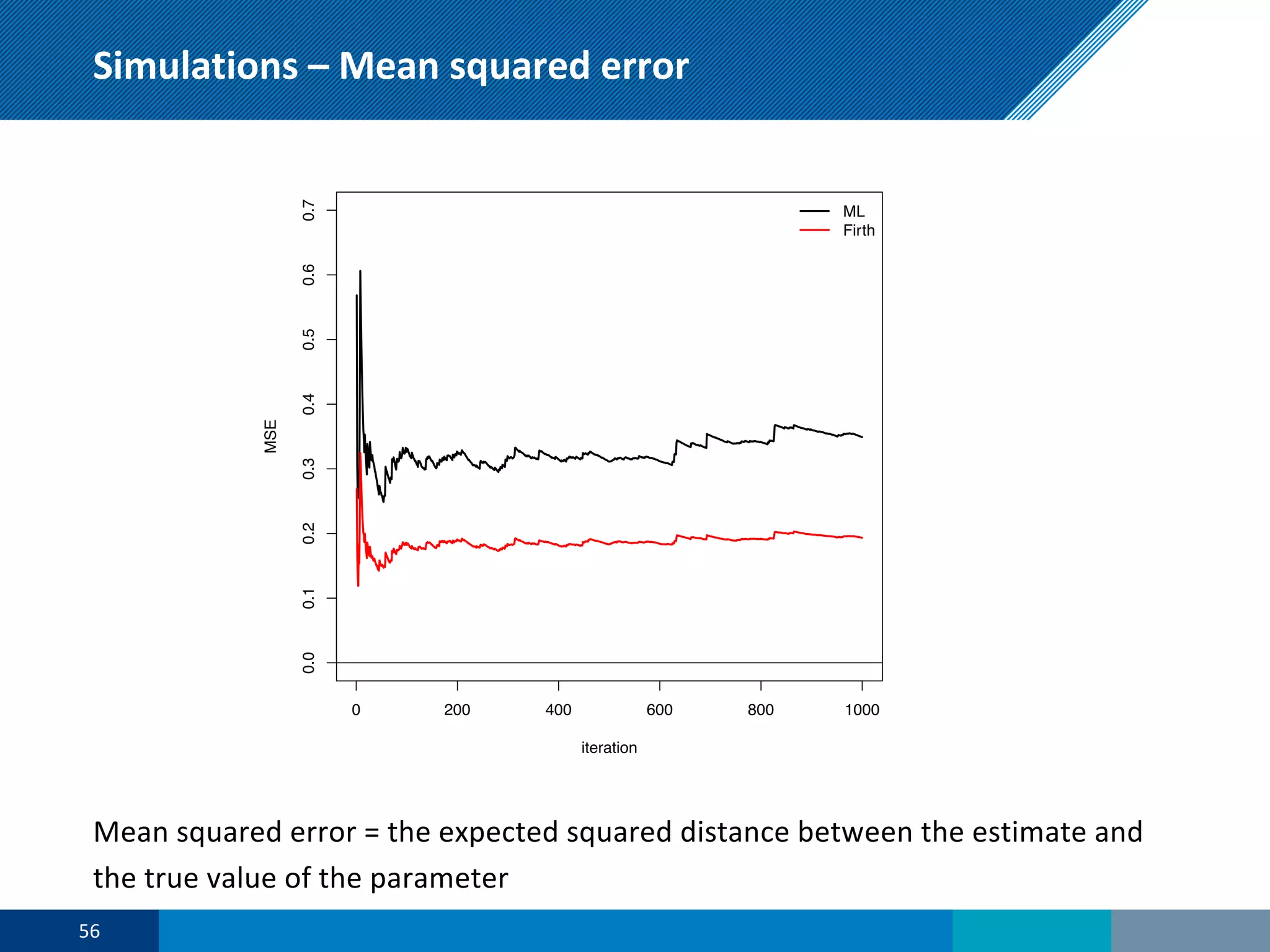
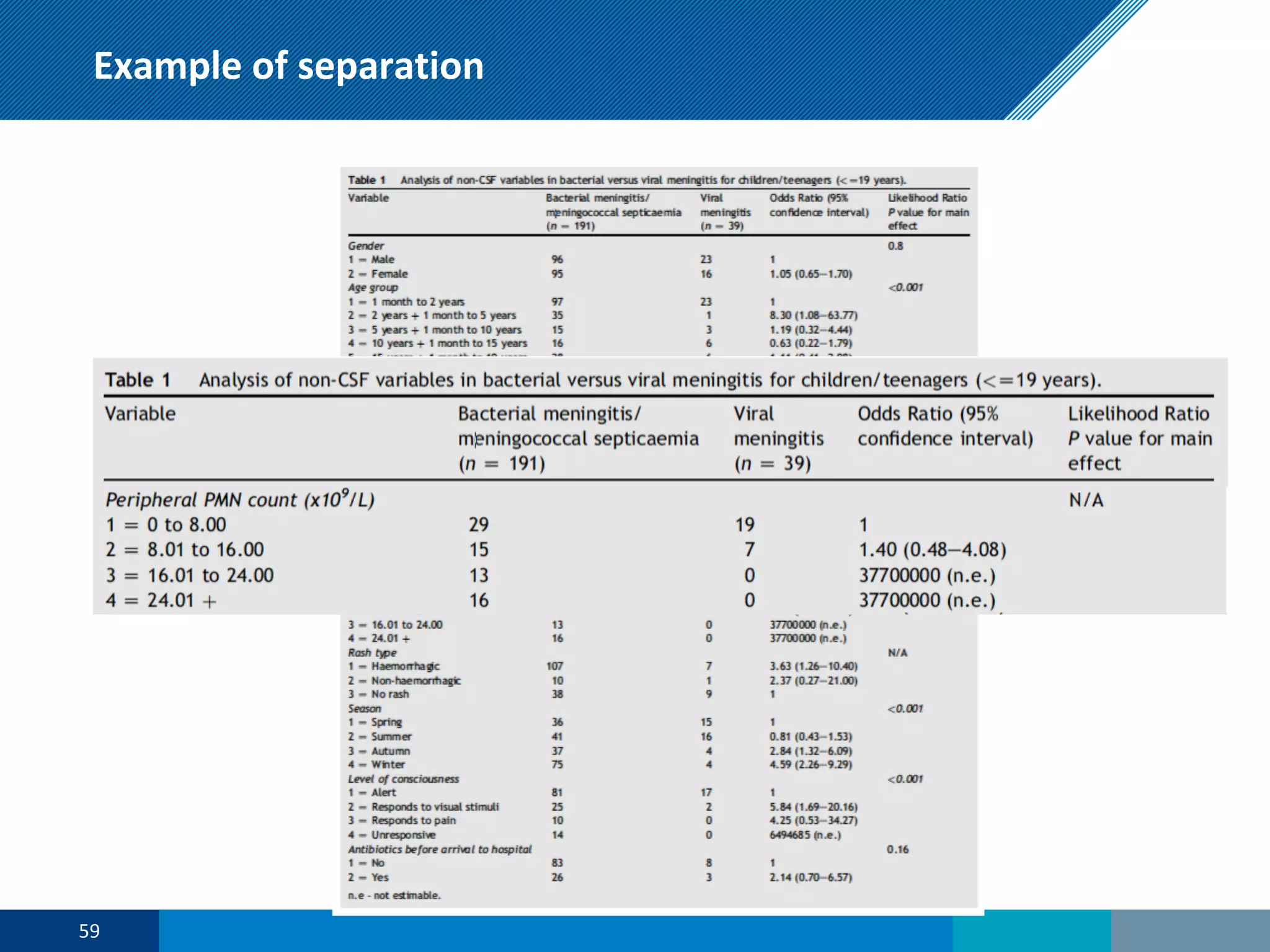
The document discusses a presentation on regression shrinkage and its implications for causal inference in epidemiological research. The presentation argues that alternative statistical models to logistic regression, such as Firth's correction, are generally "better" as they reduce bias. Firth's correction shrinks estimated coefficients towards less extreme values, reducing finite sample bias compared to maximum likelihood estimation. Simulations show that Firth's correction reduces bias in estimated odds ratios from around 25% to approximately 3%.