This document provides an overview of key concepts in recommender systems, including:
- The components of a recommender system including users, items, interactions, features, representations, predictions, loss functions, and learning.
- Design considerations for recommender systems such as choosing appropriate interaction values, features, representation functions, prediction functions, and loss functions.
- Examples of different types of recommender systems including collaborative filtering, content-based, hybrid, and real-world systems from Netflix, YouTube, and e-commerce.
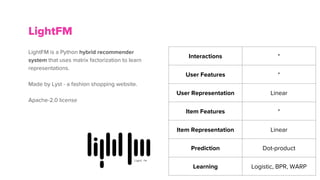
- Tools for building recommender systems in Python like Implicit, Scikit-Learn, LightFM, TensorRec, and Annoy.
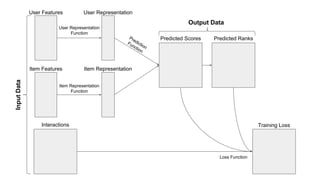
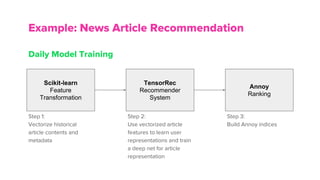
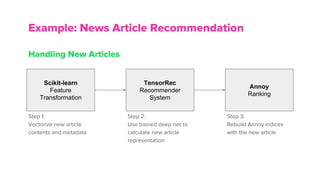
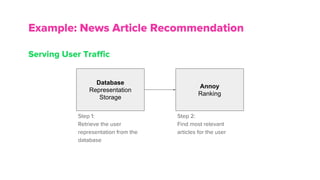
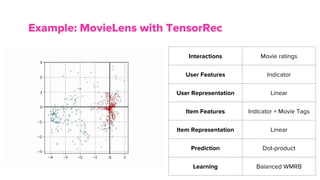
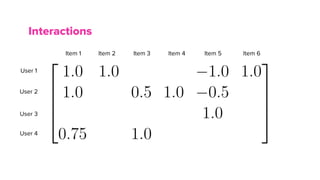
The document discusses the architecture








![User/Item Features
Indicator Features Metadata Features
Encoded
Labels/Tags/et
c.
[n_users x n_user_features]
or
[n_items x n_item_features]
User 1
User 2
User 3
User 4
User 5
User 6](https://image.slidesharecdn.com/bostonml-architectingrecommendersystems-180827131413/85/Boston-ML-Architecting-Recommender-Systems-12-320.jpg)