Downloaded 65 times




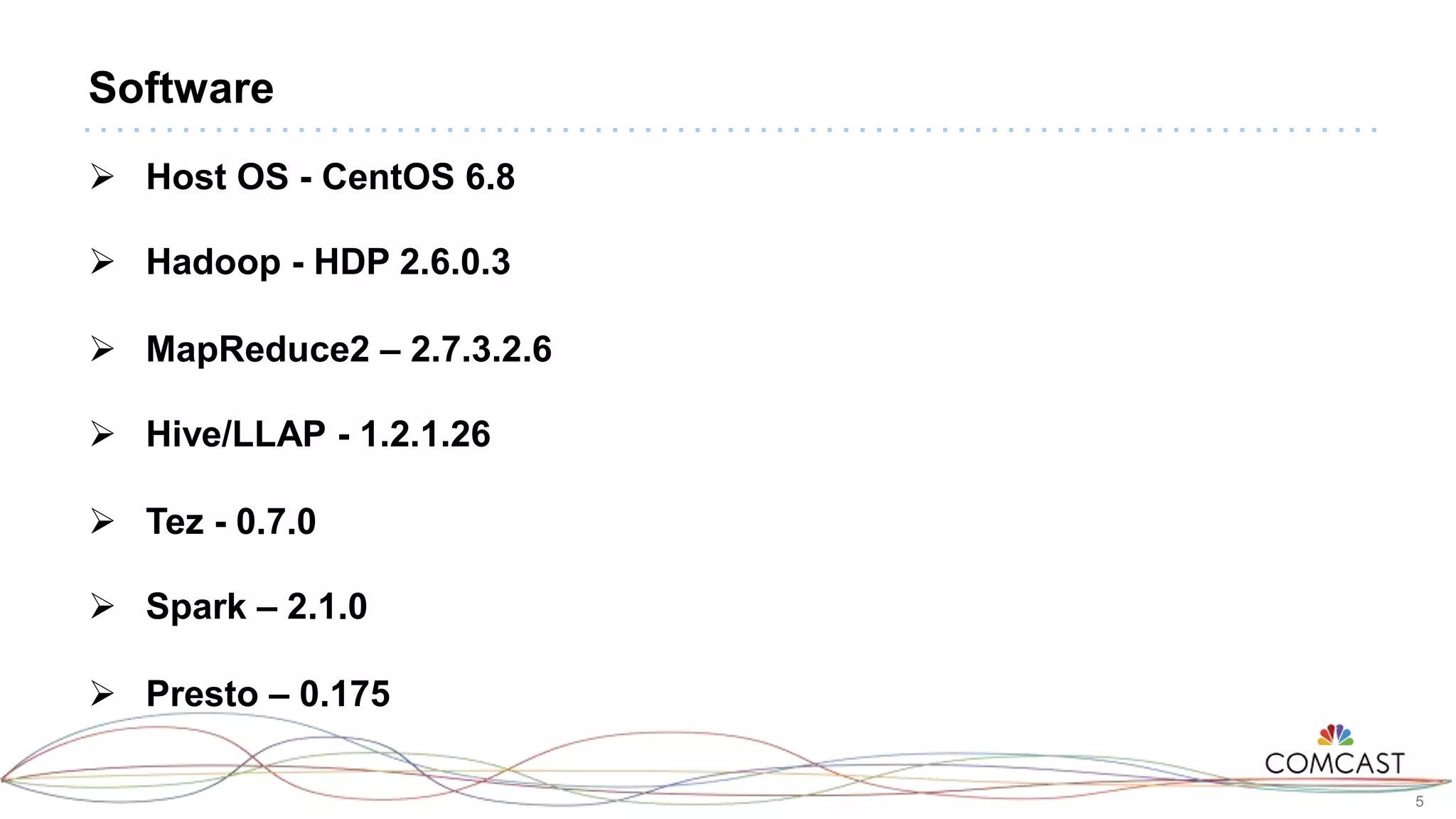

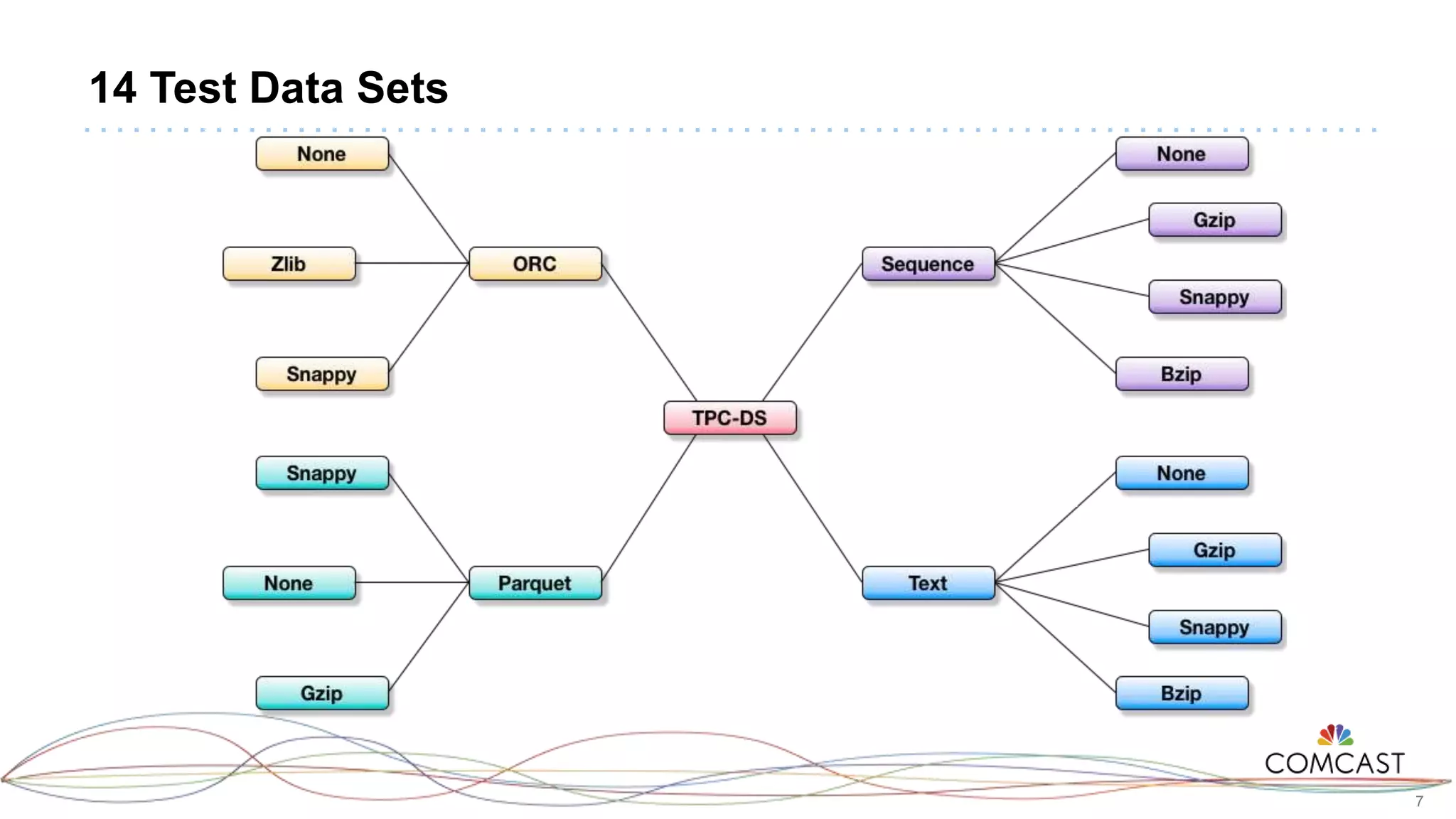






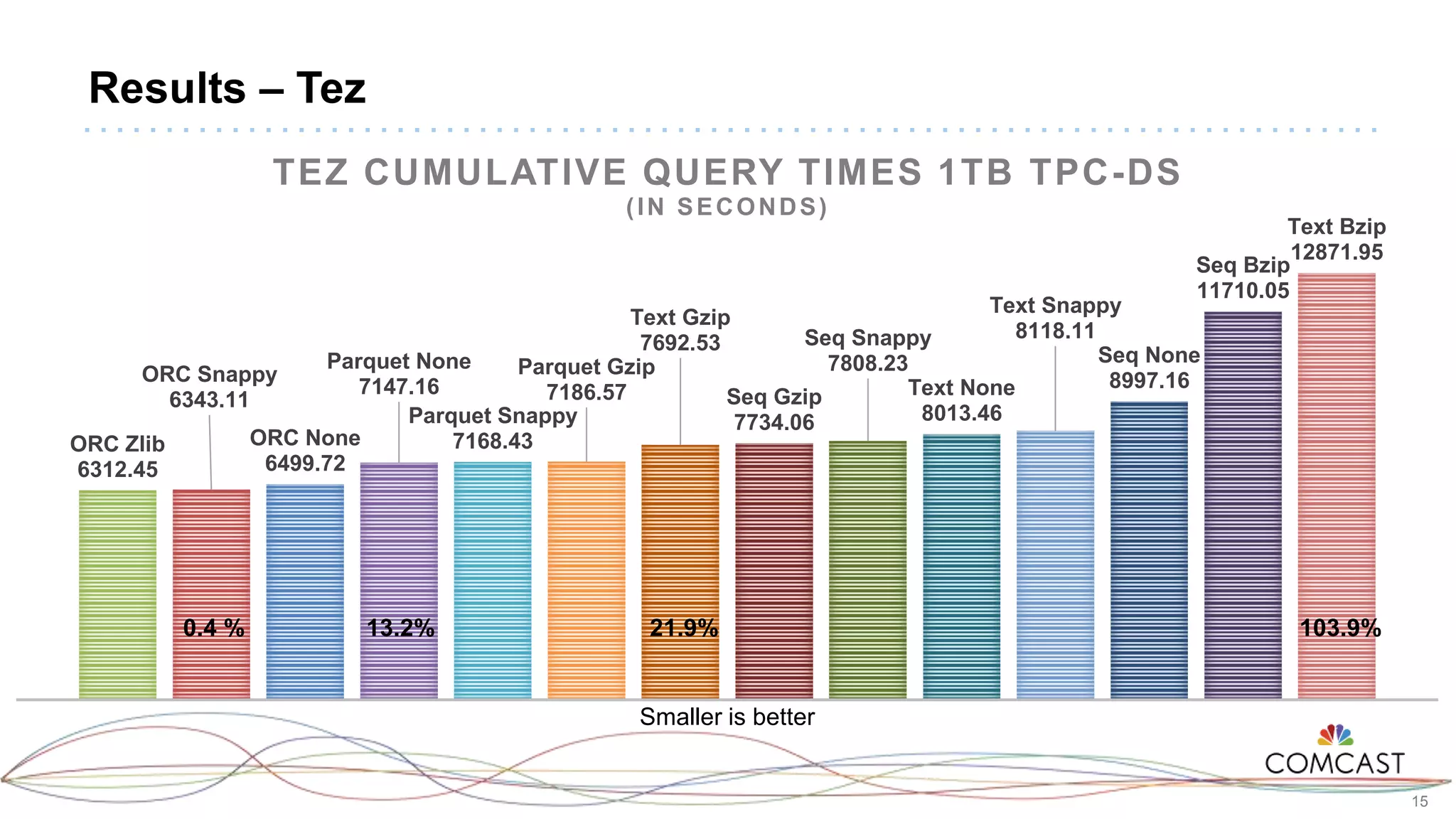
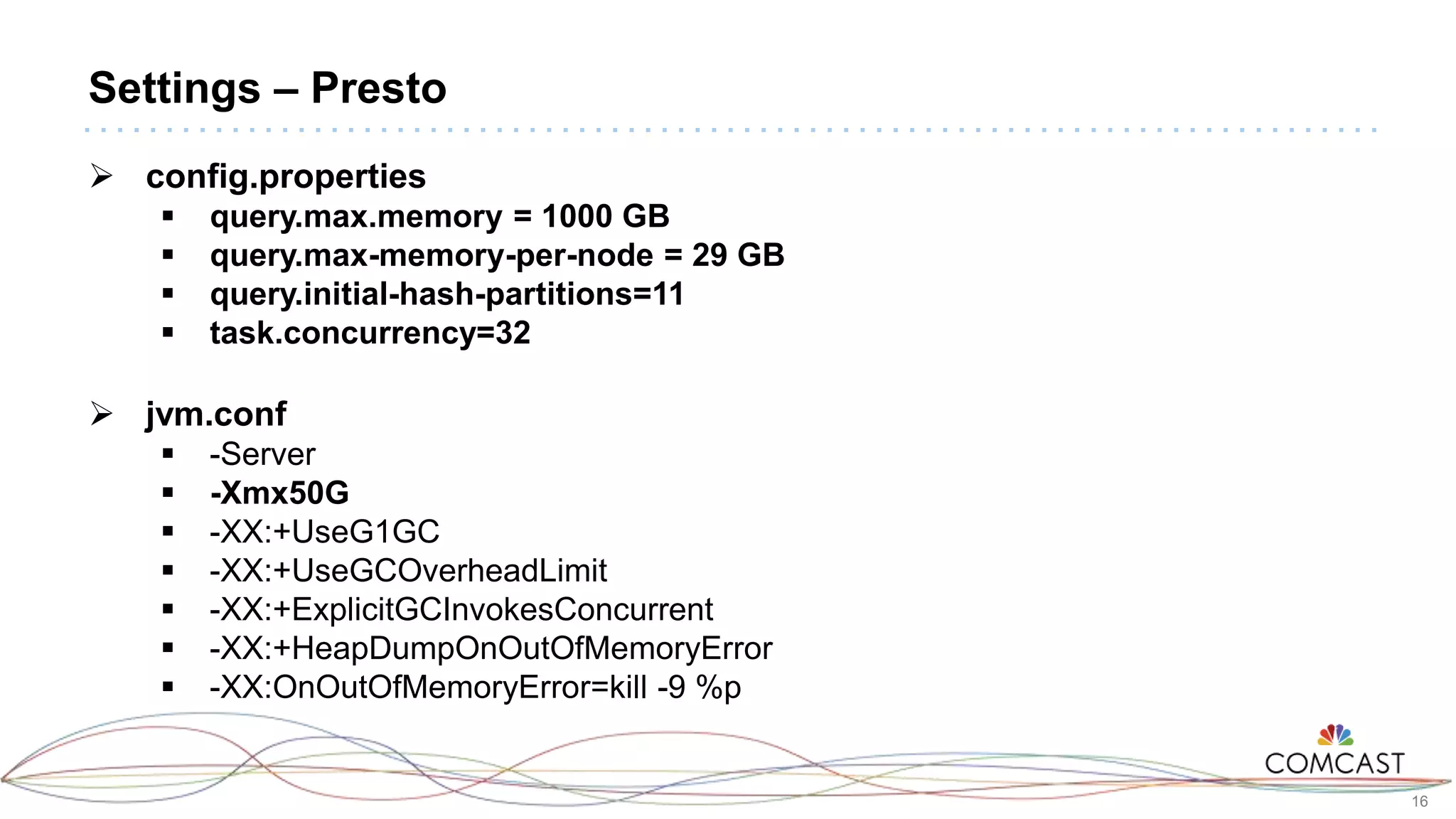
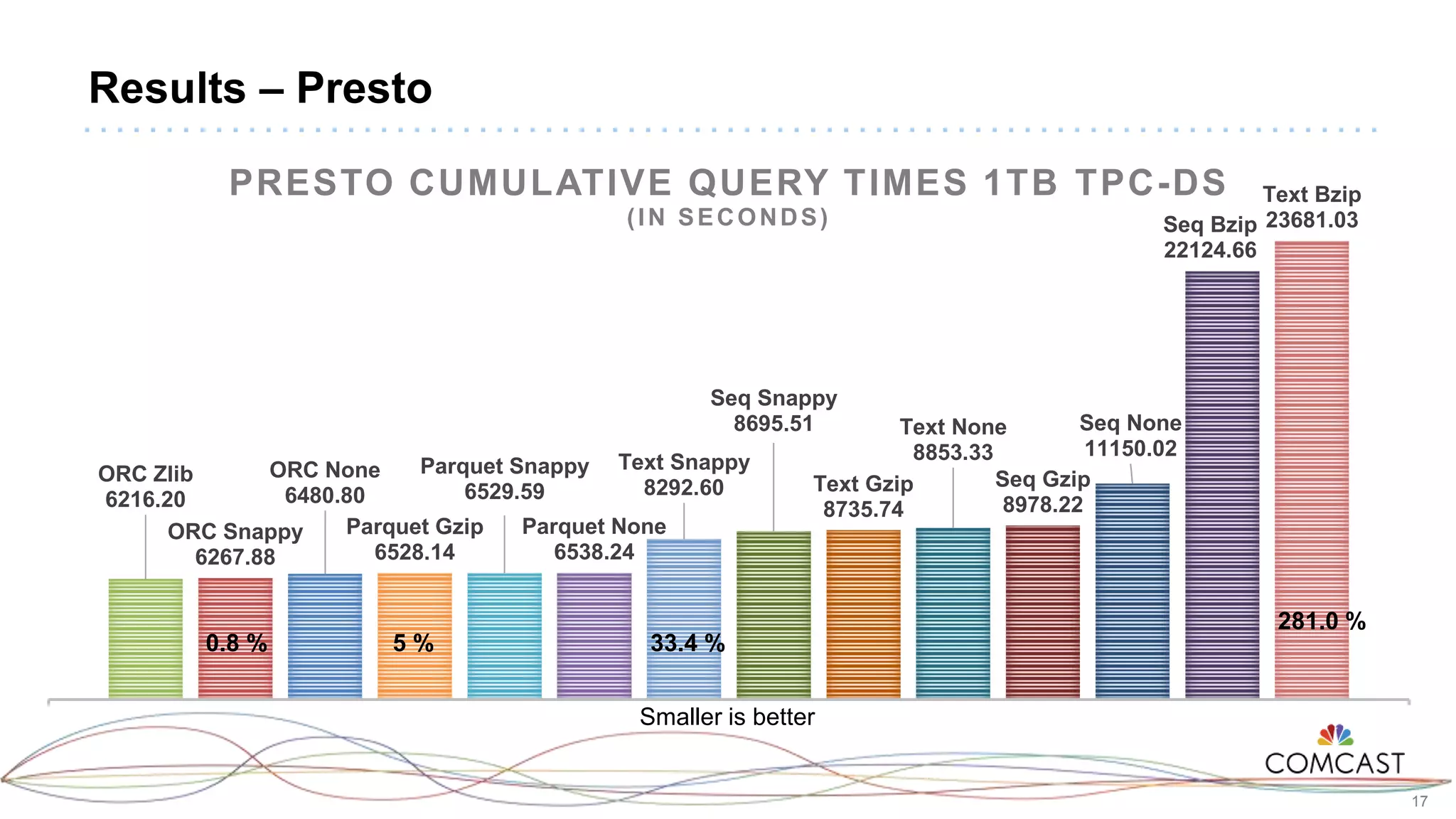


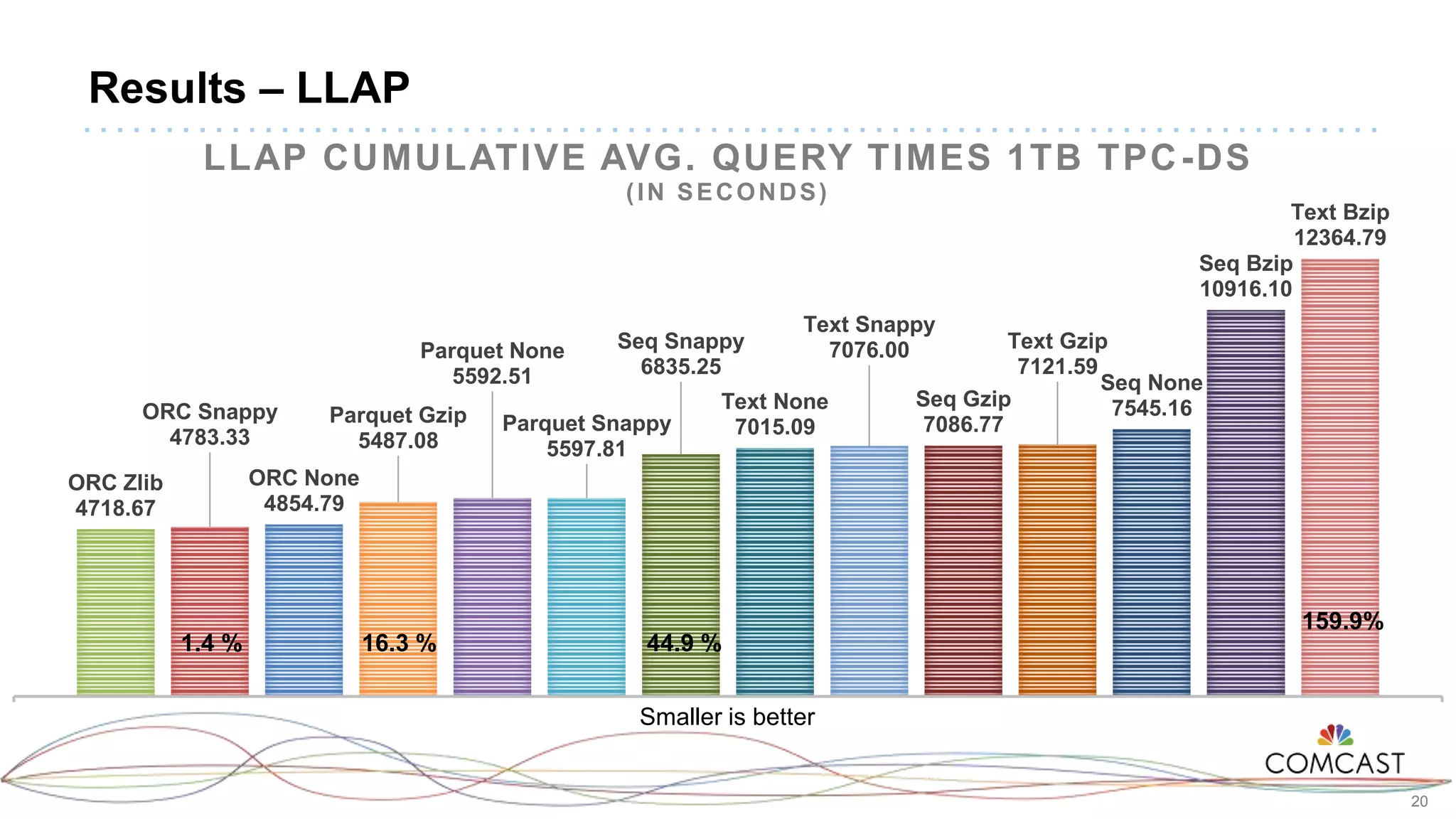
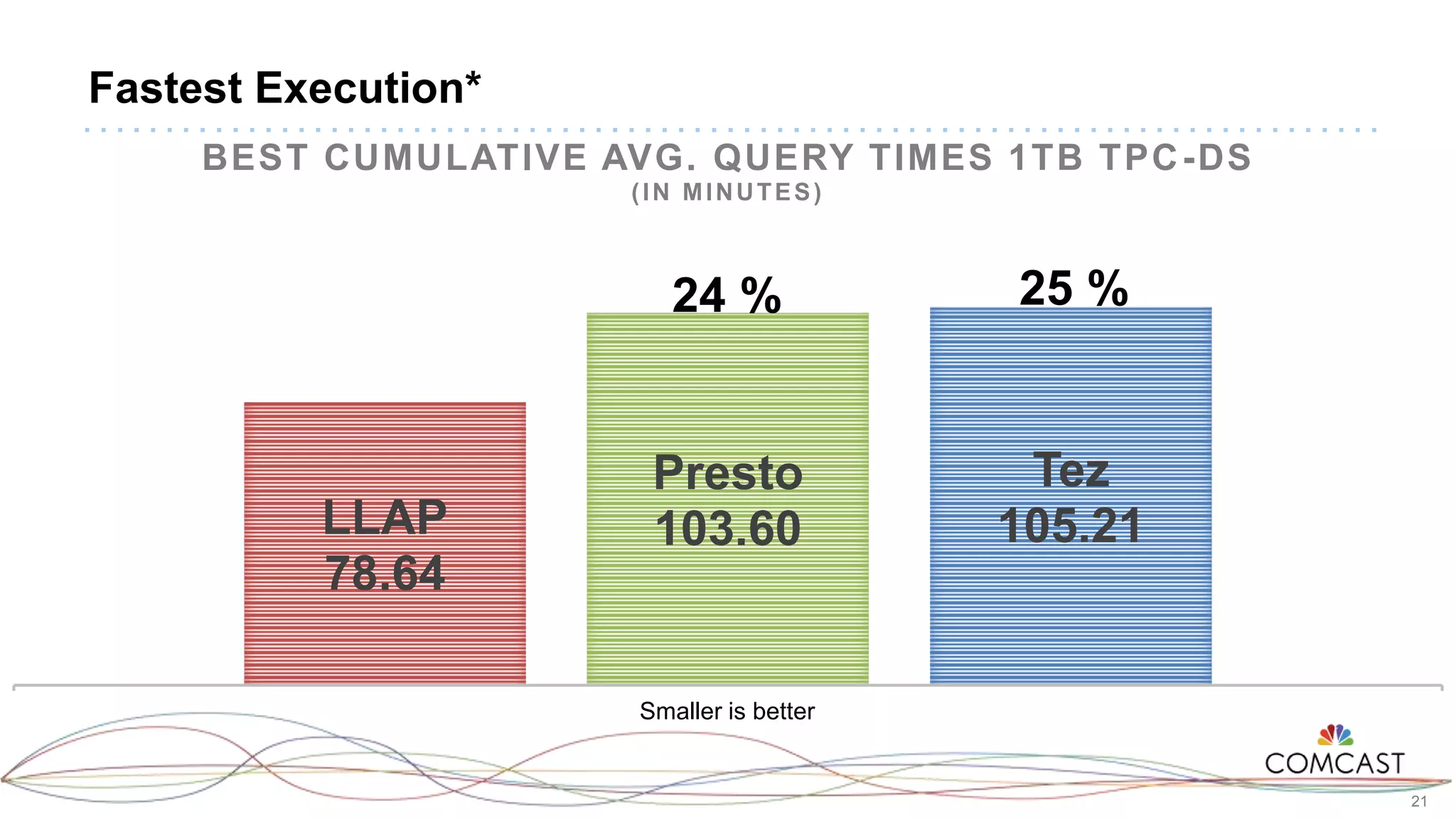
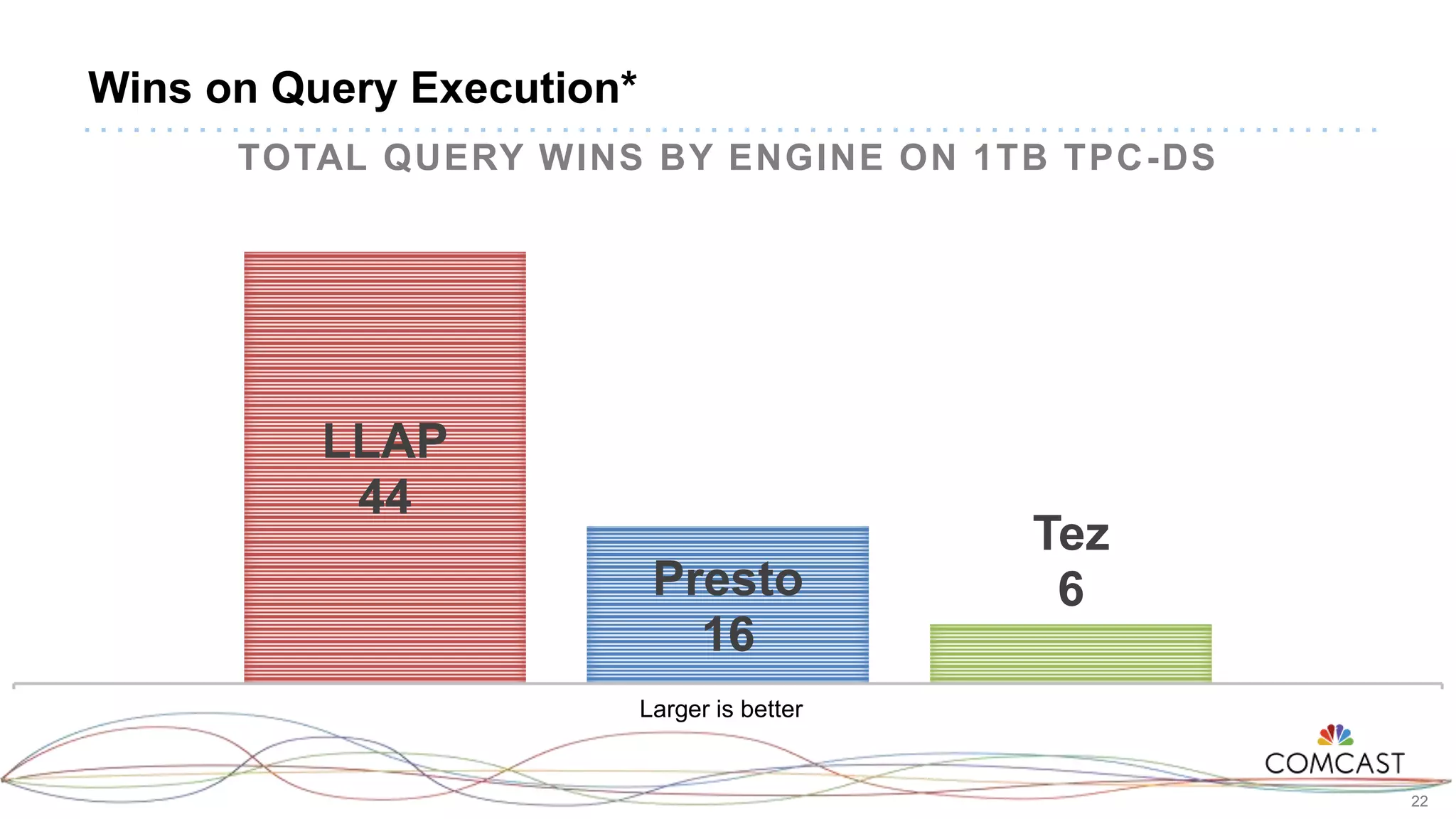
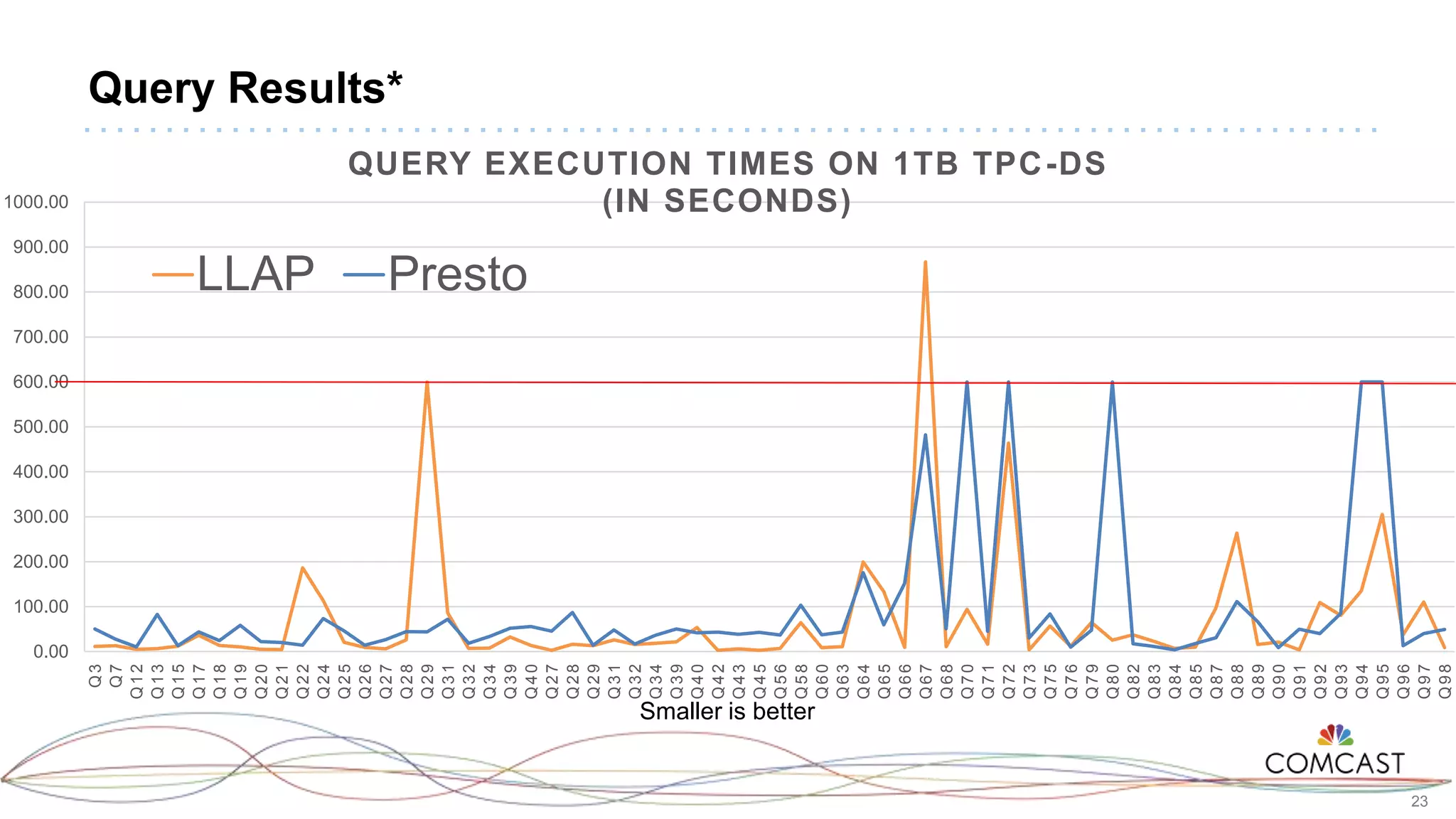







The document presents a comprehensive performance evaluation of various SQL query engines within a big data environment at Comcast, detailing the test setup and methodology used to assess their efficiency with TPC-DS datasets. Key findings reveal that LLAP exhibited the fastest execution times, outperforming Presto and Tez, while MapReduce and the Spark Thrift Server were identified as underperformers. The study underscores the importance of performance tuning and highlights the effectiveness of columnar storage, specifically ORC with Zlib compression, in enhancing query performance.




































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















