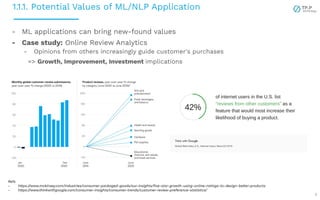
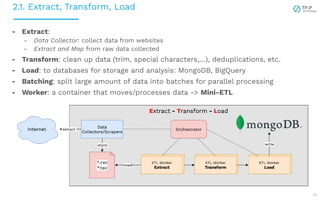
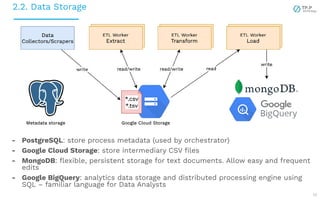
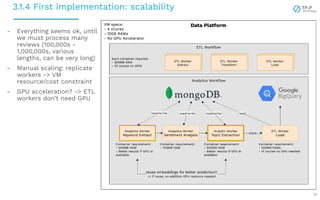
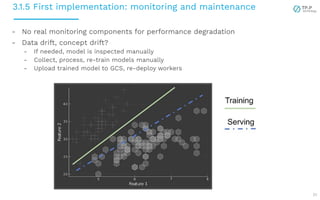
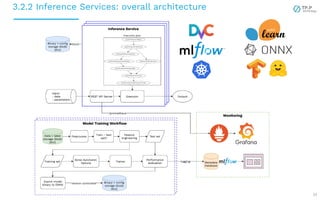
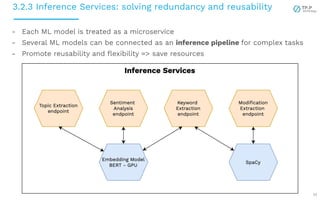
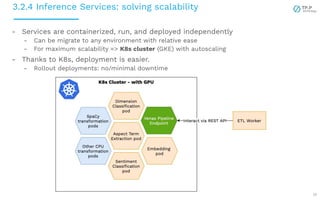
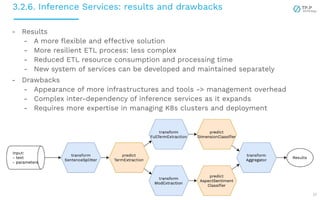
The document presents a case study on implementing machine learning (ML) and natural language processing (NLP) applications within a data platform, focusing on the challenges and solutions in data extraction, transformation, and loading (ETL) processes, along with analytics workflow. It details the architecture for efficiently handling and analyzing review text data, highlighting the importance of separating concerns in system design for better scalability and maintainability. Key insights include the challenges of web-scraping, processing, and the potential for improved resource management through containerization and microservices.