Downloaded 14 times

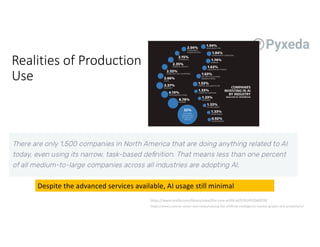


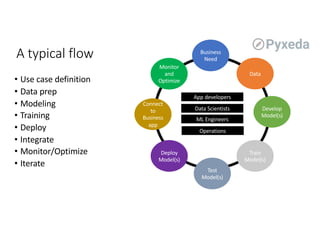
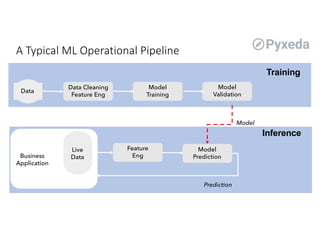



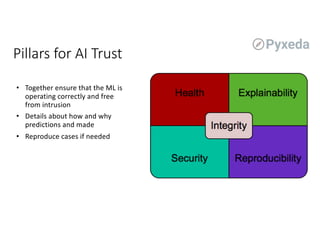
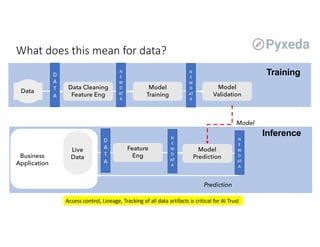









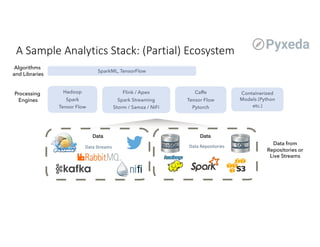
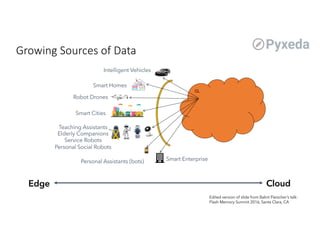

The document discusses challenges for machine learning data storage and management. It notes that machine learning workloads involve large and growing data sizes and types. Proper data governance is also essential for ensuring trustworthy machine learning systems, through mechanisms like data lineage tracking and access control. Emerging areas like edge computing further complicate storage needs. Effective machine learning storage systems will need to address issues of data access speeds, management, reproducibility and governance.



































































