Downloaded 14 times



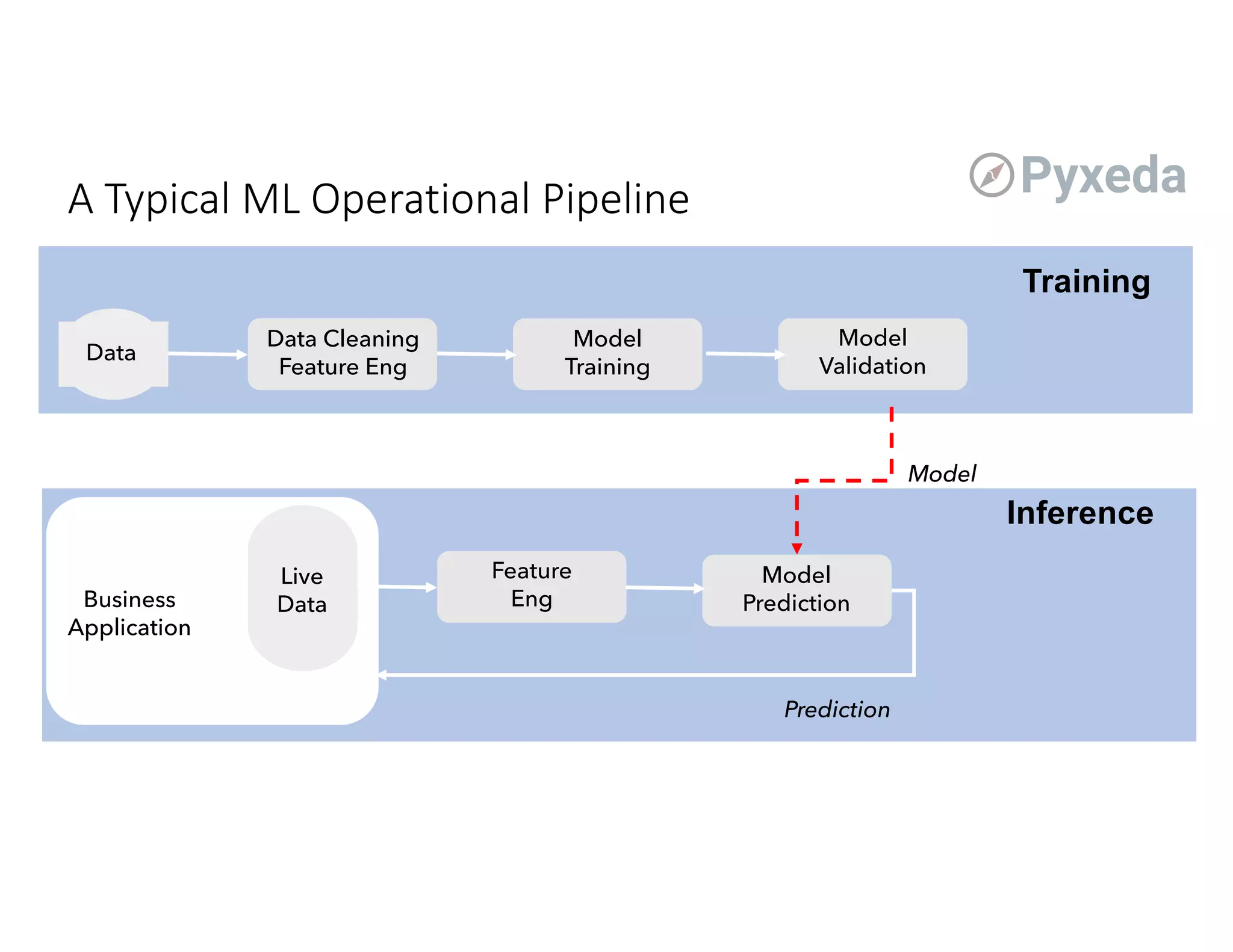
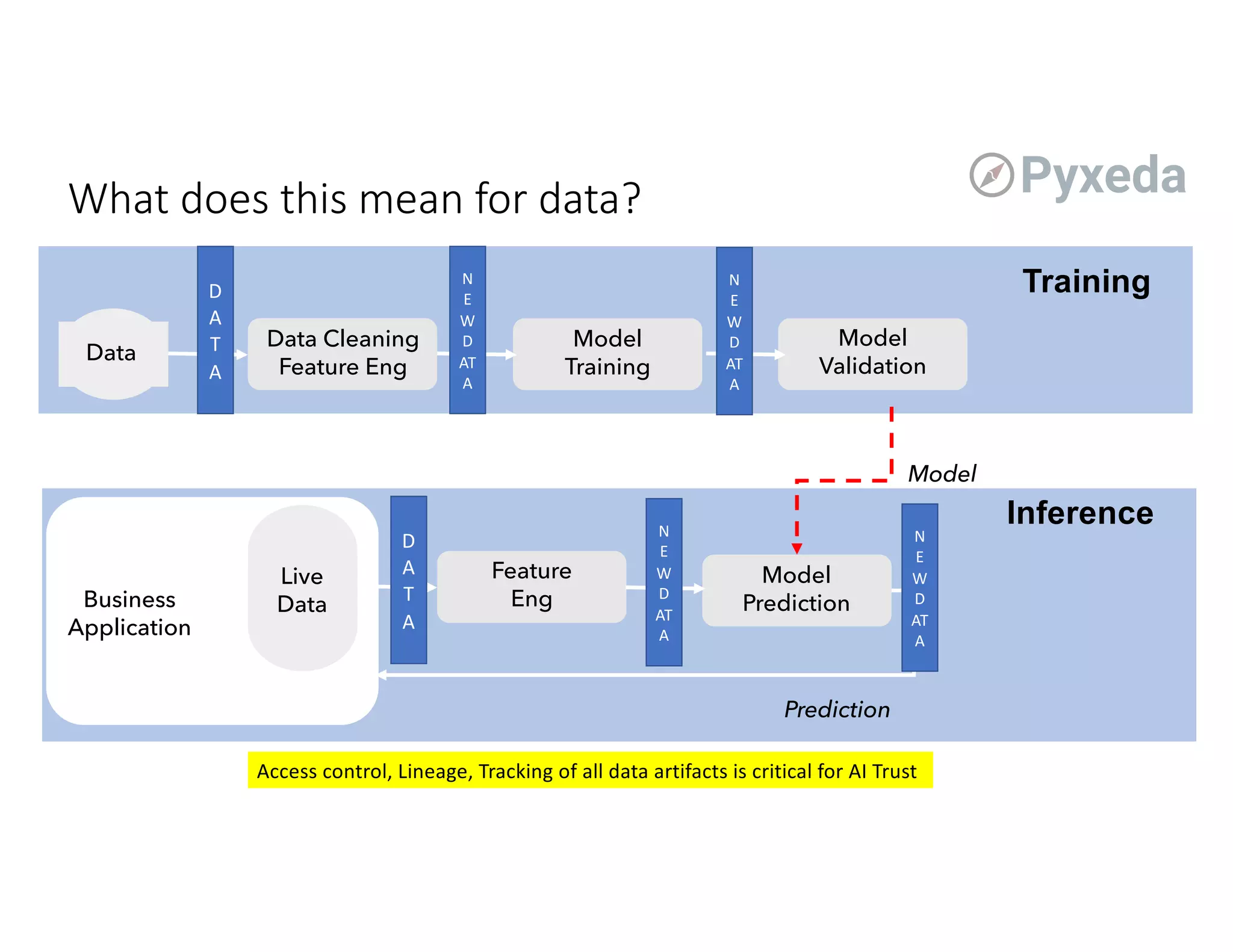







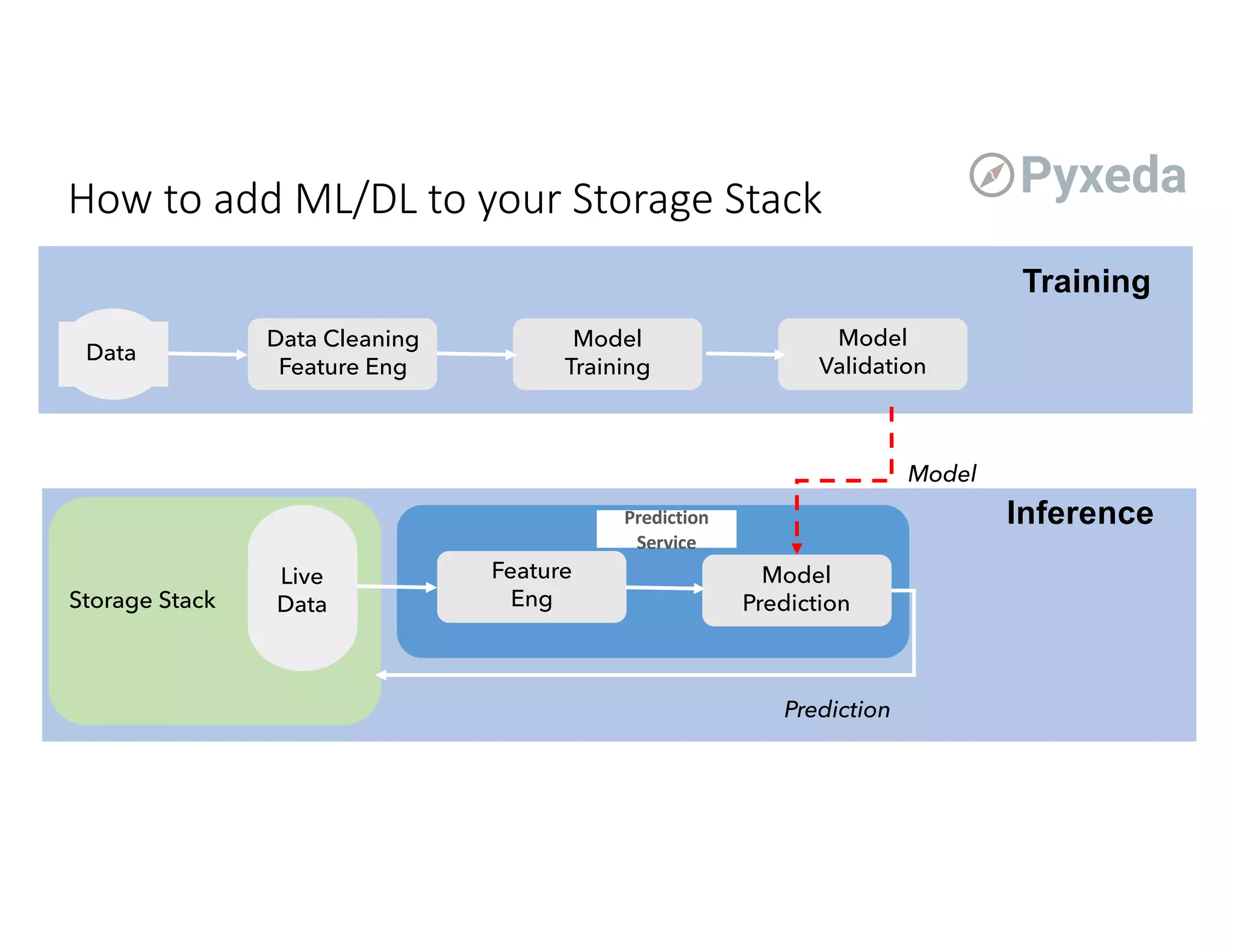
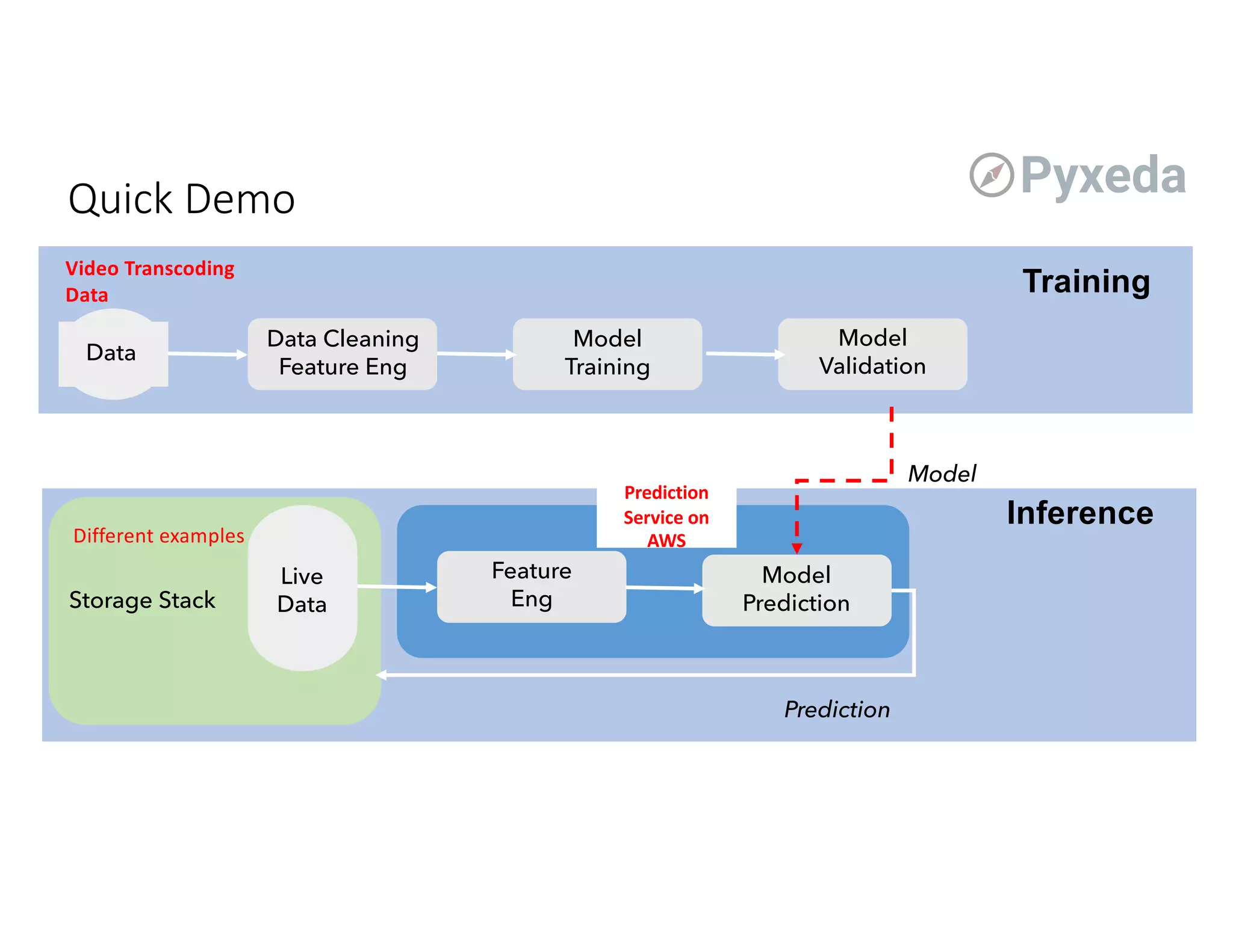




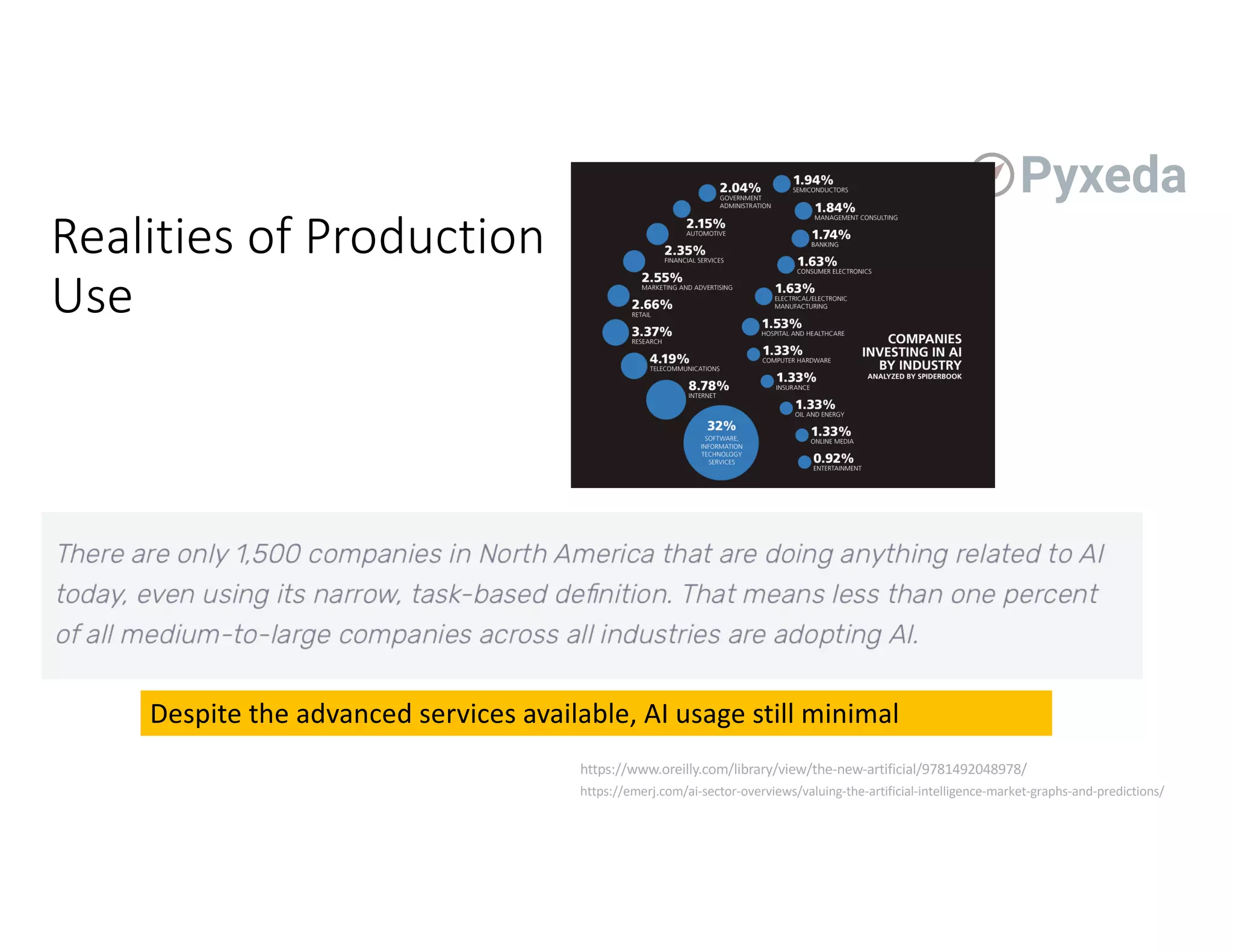

The document discusses the challenges and opportunities of using flash storage and data management in production machine learning workflows. Key themes include the significance of data governance, the growing role of edge computing, and the integration of machine learning in optimizing storage systems. Additionally, it highlights the current infancy of ML/DL adoption in enterprise solutions and outlines potential advancements in managing data for AI applications.








































![[Srijan Wednesday Webinars] Artificial Intelligence & the Future of Business](https://cdn.slidesharecdn.com/ss_thumbnails/disrupt4-171207140409-thumbnail.jpg?width=640&height=640&fit=bounds)




















![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)





