参考⽂文献
l ニューラルネットワークの学習の謎
– “The loss surfaces of multilayer networks”, A. Choromanska, et. al.
AISTATS2015
– “Open Problem: The landscape of the loss surfaces of multilayer networks”, A.
Choromanska, et. al. 2015 COLT
l 敵対的⽣生成モデル
– Generative Adversarial Networks, I. J. Goodfellow, et. al. 2014
– Unsupervised Representation Learning with Deep Convolutional Generative
Adversarial Networks, A. Radford, ICLR 2016
l 系列列から系列列への変換
– “Sequence to sequence learning with neural networks”, I. Sutskever, 2014
– “Aetherial Symbols”, G. Hinton 2015
25
26.
l Ladder Networks
– “Semi-‐‑‒supervised Learning with Ladder Networks”, A. Rasmus, et. al. 2015
– “Deconstructing the Ladder Network Archtecture”, M. Pezeshki, 2015
26





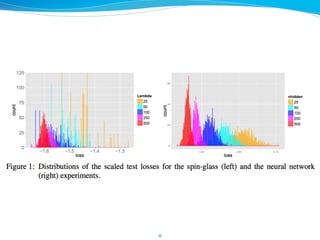
![極値の分布
7
ΛEinf以上には、
kが⼩小さい極値は
ほとんど出現しない
(殆どが鞍点)
→悪い極⼩小値は
⾒見見つからない
また,[ΛE0, ΛEinf]
の⼤大きい⽅方にはkが
⼤大きいのが多く、
⼩小さい⽅方はkが⼩小さい
のが多い
→極⼩小値はみんな
最⼩小値の近くで
⾒見見つかる](https://image.slidesharecdn.com/dnnunsolvedproblems-160520091046/85/DNN-7-320.jpg)








![GANは何をしていることになるのか?
l GANのGについてのオリジナルの更更新式は次の通りである
l しかし、log(1 – x)はxが⼩小さい場合、勾配が⼩小さいので代わりに次を使う
l この⼆二つの式を組み合わせた
これはKL[Q||P]の最⼩小化をしていることに対応する
Q : ⽣生成モデルの分布, P:経験分布
17](https://image.slidesharecdn.com/dnnunsolvedproblems-160520091046/85/DNN-17-320.jpg)

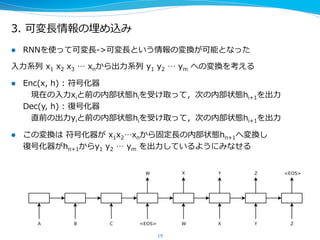

![未解決問題
l 可変⻑⾧長-‐‑‒>固定⻑⾧長の情報の埋め込みはどのように実現されているのか?
– 例例えば、⼊入⼒力力⽂文から構⽂文解析する例例では、スタックの機能は実現されている
– 再帰を含む⽂文などはどのように埋め込まれているのか?もしくは埋め込まれていな
いのか
l 固定⻑⾧長 -‐‑‒> 可変⻑⾧長の情報の展開はどのように実現されているのか?
l この場合、短期記憶の容量量は内部表現のhn+1にバウンドされている
– ⼀一種のAutoEncoderの正則化のような役割を果たしているかもしれない
l 短期記憶の容量量をあげるにはどうすればよいか?
– Attentionを使って⼊入⼒力力から直接思い出す(既存研究多数)
l 重みを⼀一次的に変えることで記憶することも可能
– 連想記憶の実現
– Hintonが提唱している[2015]が,実現はまだと思われる(過去に既にあるか?)
21](https://image.slidesharecdn.com/dnnunsolvedproblems-160520091046/85/DNN-21-320.jpg)





























![[ICLR2016] 採録論文の個人的まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2016-acceptedpapers-160209033749-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Adversarial Feature Matching for Text Generation](https://cdn.slidesharecdn.com/ss_thumbnails/dljp170707-170707035929-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)

















