Recommended
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
PDF
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
PPTX
PDF
AWS Black Belt Online Seminar AWS Direct Connect
PDF
試して覚えるPacemaker入門 『リソース設定編』
PPTX
PDF
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
PDF
20191001 AWS Black Belt Online Seminar AWS Lake Formation
PDF
しばちょう先生による特別講義! RMANバックアップの運用と高速化チューニング
PDF
GoldenGateテクニカルセミナー2「Oracle GoldenGate 新機能情報」(2016/5/11)
PDF
PDF
Amazon Kinesis Analytics によるストリーミングデータのリアルタイム分析
PDF
【より深く知ろう】活用最先端!データベースとアプリケーション開発をシンプルに、高速化するテクニック
PPT
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
PPTX
[フルバージョン] WebLogic Server for OCI 活用のご提案 - TCO削減とシステムのモダナイズ
PDF
Oracle Databaseはクラウドに移行するべきか否か 全10ケースをご紹介 (Oracle Cloudウェビナーシリーズ: 2021年11月30日)
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
PDF
AWS Black Belt - AWS Glue
PDF
Zero Data Loss Recovery Applianceのご紹介
PPTX
AWS Organizations連携サービスの罠(Security JAWS 第26回 発表資料)
PDF
SAML / OpenID Connect / OAuth / SCIM 技術解説 - ID&IT 2014 #idit2014
PDF
Oracle Database 11g,12cからのアップグレード対策とクラウド移行 (Oracle Cloudウェビナーシリーズ: 2021年7...
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
PPTX
Oracle Advanced Security Transparent Data Encryptionのご紹介
PDF
NetflixにおけるPresto/Spark活用事例
PDF
AWS Black Belt Techシリーズ Amazon Kinesis
PDF
AWS Black Belt Tech シリーズ 2015 - Amazon Kinesis
More Related Content
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
PDF
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
PPTX
PDF
AWS Black Belt Online Seminar AWS Direct Connect
PDF
試して覚えるPacemaker入門 『リソース設定編』
PPTX
PDF
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
What's hot
PDF
20191001 AWS Black Belt Online Seminar AWS Lake Formation
PDF
しばちょう先生による特別講義! RMANバックアップの運用と高速化チューニング
PDF
GoldenGateテクニカルセミナー2「Oracle GoldenGate 新機能情報」(2016/5/11)
PDF
PDF
Amazon Kinesis Analytics によるストリーミングデータのリアルタイム分析
PDF
【より深く知ろう】活用最先端!データベースとアプリケーション開発をシンプルに、高速化するテクニック
PPT
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
PPTX
[フルバージョン] WebLogic Server for OCI 活用のご提案 - TCO削減とシステムのモダナイズ
PDF
Oracle Databaseはクラウドに移行するべきか否か 全10ケースをご紹介 (Oracle Cloudウェビナーシリーズ: 2021年11月30日)
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
PDF
AWS Black Belt - AWS Glue
PDF
Zero Data Loss Recovery Applianceのご紹介
PPTX
AWS Organizations連携サービスの罠(Security JAWS 第26回 発表資料)
PDF
SAML / OpenID Connect / OAuth / SCIM 技術解説 - ID&IT 2014 #idit2014
PDF
Oracle Database 11g,12cからのアップグレード対策とクラウド移行 (Oracle Cloudウェビナーシリーズ: 2021年7...
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
PPTX
Oracle Advanced Security Transparent Data Encryptionのご紹介
PDF
NetflixにおけるPresto/Spark活用事例
Viewers also liked
PDF
AWS Black Belt Techシリーズ Amazon Kinesis
PDF
AWS Black Belt Tech シリーズ 2015 - Amazon Kinesis
PDF
AWS 初心者向けWebinar Amazon Web Services料金の見積り方法 -料金計算の考え方・見積り方法・お支払方法-
PDF
[AWSマイスターシリーズ] AWS CLI / AWS Tools for Windows PowerShell
PDF
AWS Black Belt Techシリーズ AWS CloudTrail & CloudWatch Logs
PDF
AWS Black Belt Online Seminar 2016 Amazon Kinesis
PDF
AWS Blackbelt 2015シリーズ Amazon CloudWatch & Amazon CloudWatch Logs
PDF
AWS サービスアップデートまとめ re:Invent 2017 直前編
PDF
[AWS初心者向けWebinar] AWSではじめよう、IoTシステム構築
PDF
Amazon kinesisで広がるリアルタイムデータプロセッシングとその未来
PDF
PDF
Similar to Pydata Amazon Kinesisのご紹介
PDF
AWS Black Belt Online Seminar 2017 Amazon Kinesis
PDF
Amazon Kinesis Familyを活用したストリームデータ処理
PDF
AWS Black Belt Techシリーズ AWS Data Pipeline
PPTX
PDF
Spark Streaming + Amazon Kinesis
PDF
AWS LambdaとDynamoDBがこんなにツライはずがない #ssmjp
PDF
AWS初心者向けWebinar AWSでBig Data活用
PDF
Big DataとContainerとStream - AWSでのクラスタ構成とストリーム処理 -
PPTX
JAWS-UG CLI #22 Amazon Kinesis
PDF
Amazon dynamo db、cloudant、blockchainの紹介 20160706
PDF
PDF
PDF
PDF
Serverless analytics on aws
PPTX
PDF
Amazon Kinesis developersio-meetup-05
PDF
[AWS re:invent 2013 Report] Amazon Kinesis
PDF
Kinesushi cmregrowth-2014-tokyo-20141216
PDF
jaws-ug kansai-special_kinesis_20150207
PDF
Akka Stream x Kinesis at Shinjuku reactive meetup vol2
More from Amazon Web Services Japan
PDF
マルチテナント化で知っておきたいデータベースのこと
PDF
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
PPTX
20220409 AWS BLEA 開発にあたって検討したこと
PDF
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
PDF
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
PDF
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
PPTX
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
PDF
Infrastructure as Code (IaC) 談義 2022
PDF
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
PDF
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
PDF
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
PDF
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
PDF
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
PDF
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
PDF
Amazon QuickSight の組み込み方法をちょっぴりDD
PDF
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
PDF
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
PDF
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
PDF
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
PDF
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
PPTX
PDF
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
Pydata Amazon Kinesisのご紹介 1. 2. ⾃自⼰己紹介
• 名前
– 榎並 利利晃(えなみ としあき)
– toshiake@amazon.co.jp
– @ToshiakiEnami
• 役割
– パートナーソリューションアーキテクト
– 主にエマージングパートナー様を担当
• 好きなAWSのサービス
– Amazon Kinesis
– Amazon DynamoDB
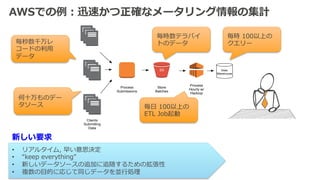
3. AWSでの例例:迅速かつ正確なメータリング情報の集計
S3
Process
Submissions
Store
Batches
Process
Hourly w/
Hadoop
Clients
Submitting
Data
Data
Warehouse
毎秒数千万レ
コードの利利⽤用
データ
何⼗十万ものデー
タソース
毎時数テラバイ
トのデータ
毎⽇日 100以上の
ETL Job起動
毎時 100以上の
クエリー
新しい要求
• リアルタイム, 早い意思決定
• “keep everything”
• 新しいデータソースの追加に追随するための拡張性
• 複数の⽬目的に応じて同じデータを並⾏行行処理理
4. 5. Ingest Layerの重要性
構造の異異なるデータソースに対する⾼高速処理理
• 耐障害性とスケールに対する考慮
• ⾼高い信頼性の維持
• 順序性
ランダムにくるデータをまとめて、シーケンスストリームの形に変換
• シーケンスデータによる容易易な処理理の実現
• 容易易なスケール
• 永続化データ
Processing
Or
Kinesis
Kafka
Processing
Kinesis
6. 7. 8. Amazon Kinesisとは?
• ハイボリュームな連続したデータをリアルタイム
で処理理可能なフルマネージドサービス
• Kinesisは、数⼗十万のデータソースからの1時間辺
り数テラバイトのデータを処理理することができ、
かつ、格納されたデータは、複数のAZに格納する
信頼性と耐久性をもつサービス
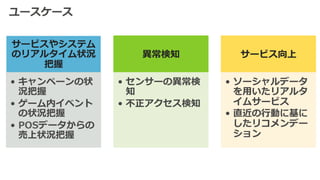
9. ユースケース
サービスやシステム
のリアルタイム状況
把握
• キャンペーンの状
況把握
• ゲーム内イベント
の状況把握
• POSデータからの
売上状況把握
異異常検知
• センサーの異異常検
知
• 不不正アクセス検知
サービス向上
• ソーシャルデータ
を⽤用いたリアルタ
イムサービス
• 直近の⾏行行動に基に
したリコメンデー
ション
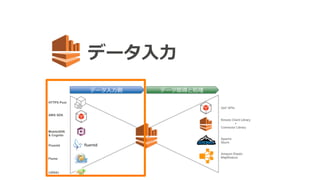
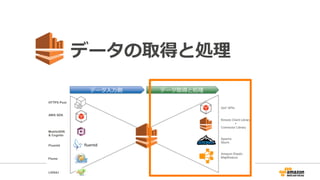
10. Kinesis概要
Kinesis Client Library
+
Connector Library
HTTPS Post
AWS SDK
Fluentd
Flume
LOG4J
Get* APIs
Apache
Storm
Amazon Elastic
MapReduce
データ⼊入⼒力力側データ取得と処理理
MobileSDK
Cognito
11. Kinesis構成内容
Data
Sources
App.1
[Aggregate
De-‐‑‒Duplicate]
App.4
[Machine
Learning]
Data
Sources
Data
Sources
Data
Sources
App.2
[Metric
Extraction]
S3
DynamoDB
Redshift
App.3
[Real-‐‑‒time
Dashboard]
Data
Sources
Stream
Availability
Zone
Availability
Zone
Shard 1
Shard 2
Shard N
Availability
Zone
Kinesis
AWS Endpoint
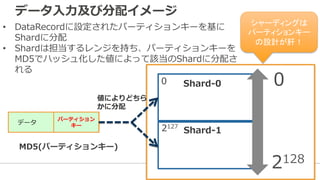
• ⽤用途単位でStreamを作成し、Streamは、1つ以上のShardで構成される
• Shardは、データ⼊入⼒力力側 1MB/sec, 1000 TPS、データ処理理側 2 MB/sec, 5TPSのキャパシティを持つ
• ⼊入⼒力力するデータをData Recordと呼び、⼊入⼒力力されたData Recordは、24 時間かつ複数のAZに保管される
• Shardの増加減によってスケールの制御が可能
12. Kinesisコスト
従量量課⾦金金 初期費⽤用不不要
課⾦金金項⽬目単価
シャード利利⽤用料料$0.0195/shard/時間
Putトランザクション$0.043/100万Put
• シャード1つで、⼀一ヶ⽉月約$14
• Getトランザクションは無料料
• インバウンドのデータ転送料料は無料料
• アプリケーションが⾛走るEC2は通常の料料⾦金金がかかります
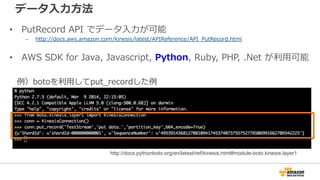
13. 14. データ⼊入⼒力力⽅方法
• PutRecord API でデータ⼊入⼒力力が可能
– http://docs.aws.amazon.com/kinesis/latest/APIReference/API_̲PutRecord.html
• AWS SDK for Java, Javascript, Python, Ruby, PHP, .Net が利利⽤用可能
例例)botoを利利⽤用してput_̲recordした例例
http://docs.pythonboto.org/en/latest/ref/kinesis.html#module-boto.kinesis.layer1
15. 16. 17. 18. 既存ログ収集パターン
• Fluentd Plugin利利⽤用パターン
• Webサーバ、アプリケーションサー
バなどにあるログデータの⼊入⼒力力に最
適
• GithubからPluginを取得することが
可能
https://github.com/awslabs/
aws-‐‑‒fluent-‐‑‒plugin-‐‑‒kinesis
• Log4J利利⽤用パターン
• JavaアプリケーションでLog4Jを利利⽤用
している場合導⼊入が容易易
• 開発者ガイド
http://docs.aws.amazon.com/
ElasticMapReduce/latest/DeveloperGuide/
kinesis-‐‑‒pig-‐‑‒publisher.html
Web
log4j.properties サンプル
# KINESIS appender
log4j.logger.KinesisLogger=INFO, KINESIS
log4j.additivity.KinesisLogger=false
log4j.appender.KINESIS=com.amazonaws.services.kin
esis.log4j.KinesisAppender
log4j.appender.KINESIS.layout=org.apache.log4j.Patte
rnLayout
log4j.appender.KINESIS.layout.ConversionPattern=
%m
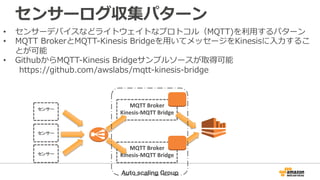
19. センサーログ収集パターン
• センサーデバイスなどライトウェイトなプロトコル(MQTT)を利利⽤用するパターン
• MQTT BrokerとMQTT-‐‑‒Kinesis Bridgeを⽤用いてメッセージをKinesisに⼊入⼒力力するこ
MQTT
Broker
Kinesis-‐MQTT
Bridge
とが可能
• GithubからMQTT-‐‑‒Kinesis Bridgeサンプルソースが取得可能
https://github.com/awslabs/mqtt-‐‑‒kinesis-‐‑‒bridge
MQTT
Broker
Kinesis-‐MQTT
Bridge
センサー
センサー
センサー
Auto scaling Group
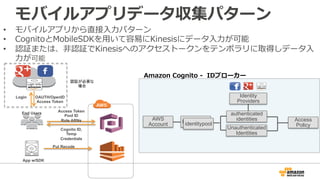
20. モバイルアプリデータ収集パターン
• モバイルアプリから直接⼊入⼒力力パターン
• CognitoとMobileSDKを⽤用いて容易易にKinesisにデータ⼊入⼒力力が可能
• 認証または、⾮非認証でKinesisへのアクセストークンをテンポラリに取得しデータ⼊入
⼒力力が可能
Login OAUTH/OpenID
Access Token
End Users
App w/SDK
認証が必要な
Access Token
Pool ID
Role ARNs
Cognito ID,
Temp
Credentials
Put Recode
場合
Amazon Cognito -‐‑‒ IDブローカー
AWS identities
Account
Identitypool
Identity
Providers
Access
authenticated
identitypool Policy
Unauthenticated
Identities
21. 22. データ取得⽅方法
• GetShardIterator APIでShard内のポジションを取得し、GetRecords
APIでデータ⼊入⼒力力が可能
– http://docs.aws.amazon.com/kinesis/latest/APIReference/API_̲GetShardIterator.html
– http://docs.aws.amazon.com/kinesis/latest/APIReference/API_̲GetRecords.html
• AWS SDK for Java, Javascript, Python, Ruby, PHP, .Net が利利⽤用可
能
例例)botoを利利⽤用してget_̲shard_̲iterator, get_̲recordsした例例
http://docs.pythonboto.org/en/latest/ref/kinesis.html#module-boto.kinesis.layer1
23. GetShardIteratorでのデータ取得指定⽅方法
• GetShardIterator APIでは、ShardIteratorTypeを指定してポジションを取得
する。
• ShardIteratorTypeは以下の通り
– AT_̲SEQUENCE_̲NUMBER ( 指定のシーケンス番号からデータ取得 )
– AFTER_̲SEQUENCE_̲NUMBER ( 指定のシーケンス番号以降降からデータ取得 )
– TRIM_̲HORIZON ( Shardにある最も古いデータからデータ取得 )
– LATEST ( 最新のデータからデータ取得 )
Seq: xxx
LATEST
AT_̲SEQUENCE_̲NUMBER
AFTER_̲SEQUENCE_̲NUMBER
TRIM_̲HORIZON
GetShardIteratorの動作イメージ
24. Kinesis Client Library (KCL)
Client library for fault-‐‑‒tolerant, at least-‐‑‒once, Continuous
Processing
• Shardと同じ数のWorker
• Workerを均等にロードバランシング
Shard 1
• 障害感知と新しいWorkerの⽴立立ち上げ
Shard 2
• シャードの数に応じてworkerが動作する
Shard 3
• AutoScalingでエラスティック
Shard 4
• チェックポインティングとAt least once処理理
Shard n
EC2 Instance
KCL Worker 1
KCL Worker 2
EC2 Instance
KCL Worker 3
KCL Worker 4
EC2 Instance
KCL Worker n
Kinesis
これらの煩雑な処理理を意識識することなく
ビジネスロジックに集中することができる。
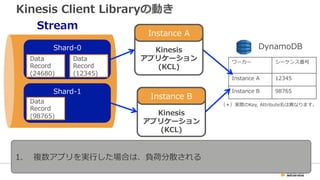
25. Kinesis Client Libraryの動き
Stream
Shard-‐‑‒0
Shard-‐‑‒1
Kinesis
アプリケーション
(KCL)
ワーカーシーケンス番号
Instance A12345
Instance A98765
Data
Record
(12345)
Data
Record
(24680)
Data
Record
(98765)
DynamoDB
Instance A
(*)実際のKey, Attribute名は異異なります。
1. Kinesis Client LibraryがShardからData Recordを取得
2. 設定された間隔でシーケンス番号をそのワーカーのIDをキーにした
DynamoDBのテーブルに格納
3. 1つのアプリが複数Shardからデータを取得し処理理を実⾏行行
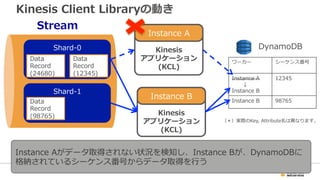
26. Kinesis Client Libraryの動き
Stream
Shard-‐‑‒0
Shard-‐‑‒1
Kinesis
アプリケーション
(KCL)ワーカーシーケンス番号
Instance A12345
Instance B98765
Data
Record
(12345)
Data
Record
(24680)
Data
Record
(98765)
DynamoDB
Instance A
Instance B
Kinesis
アプリケーション
(KCL)
1. 複数アプリを実⾏行行した場合は、負荷分散される
(*)実際のKey, Attribute名は異異なります。
27. Kinesis Client Libraryの動き
Stream
Shard-‐‑‒0
Shard-‐‑‒1
Kinesis
アプリケーション
(KCL)ワーカーシーケンス番号
Instance A
↓
Instance B
12345
Instance B98765
Data
Record
(12345)
Data
Record
(24680)
Data
Record
(98765)
DynamoDB
Instance A
Instance B
Kinesis
アプリケーション
(KCL)
(*)実際のKey, Attribute名は異異なります。
Instance Aがデータ取得されない状況を検知し、Instance Bが、DynamoDBに
格納されているシーケンス番号からデータ取得を⾏行行う
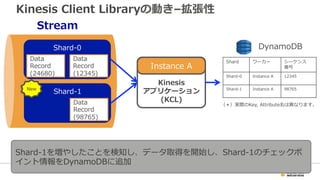
28. Kinesis Client Libraryの動き–拡張性
Stream
Shard-‐‑‒0
Kinesis
アプリケーション
(KCL)
Shardワーカーシーケンス
番号
Shard-‐‑‒0Instance A12345
Shard-‐‑‒1Instance A98765
Data
Record
(12345)
Data
Record
(24680)
DynamoDB
Instance A
Shard-‐‑‒1
Data
Record
(98765)
New
(*)実際のKey, Attribute名は異異なります。
Shard-‐‑‒1を増やしたことを検知し、データ取得を開始し、Shard-‐‑‒1のチェックポ
イント情報をDynamoDBに追加
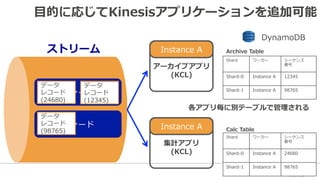
29. ⽬目的に応じてKinesisアプリケーションを追加可能
ストリーム
データ
レコード
(12345)
データ
レコード
(24680)
シャード
データ
レコード
(98765)
シャード
アーカイブアプリ
(KCL)
DynamoDB
Instance A
Archive Table
Shardワーカーシーケンス
番号
Shard-‐‑‒0Instance A12345
Shard-‐‑‒1Instance A98765
各アプリ毎に別テーブルで管理理される
Instance A
集計アプリ
(KCL)
Calc Table
Shardワーカーシーケンス
番号
Shard-‐‑‒0Instance A24680
Shard-‐‑‒1Instance A98765
30. Kinesis Client Library (KCL) for Pythonについて
• KCL for Pythonは、KCL for Javaの“MultiLangDaemon”を常駐プロセ
スとして利利⽤用し、データ処理理のメインロジックをPythonで記述できるラ
イブラリ
• データ処理理は、サブプロセスとして起動される
• “MultiLangDaemon”とサブプロセス間のデータ通信は、定義されたプロ
トコルでSTDIN/STDOUTを使って⾏行行われる
31. Kinesis Client Library (KCL) for Pythonについて
• KCL for Pythonは、KCL for Javaの“MultiLangDaemon”を常駐プロセ
スとして利利⽤用し、データ処理理のメインロジックをPythonで記述できるラ
イブラリ
• データ処理理は、サブプロセスとして起動される
• “MultiLangDaemon”とサブプロセス間のデータ通信は、定義されたプロ
トコルでSTDIN/STDOUTを使って⾏行行われる
KCL(Java)
Worker Thread Python Logic
Shard-‐‑‒0
Shard-‐‑‒1Worker Thread
Process
Python Logic
Process
32. KCL for Python実装
#!env python
from amazon_kclpy import kcl
import json, base64
class RecordProcessor(kcl.RecordProcessorBase):
def initialize(self, shard_id):
pass
def process_records(self, records, checkpointer):
pass
def shutdown(self, checkpointer, reason):
pass
if __name__ == __main__:
kclprocess = kcl.KCLProcess(RecordProcessor())
kclprocess.run()
33. KCL for Python実装
KCL for Python
https://github.com/awslabs/amazon-kinesis-client-python/blob/
master/amazon_kclpy/kcl.py
KCL for Java
https://github.com/awslabs/amazon-kinesis-client/tree/master/src/
main/java/com/amazonaws/services/kinesis/multilang
34. Multi Language Protocol
Action Parameter
Initialize shardId : string
processRecords [{ data : ”base64encoded_string,
partitionKey : ”partition key,
sequenceNumber : ”sequence number;
}] // a list of records
checkpoint checkpoint : ”sequence number,
error : NameOfException
shutdown reason : “TERMINATE|ZOMBIE
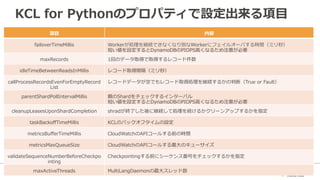
35. KCL for Pythonのプロパティで設定出来る項⽬目
項⽬目内容
failoverTimeMillisWorkerが処理理を継続できなくなり別なWorkerにフェイルオーバする時間(ミリ秒)
短い値を設定するとDynamoDBのPIOPS⾼高くなるため注意が必要
maxRecords1回のデータ取得で取得するレコード件数
idleTimeBetweenReadsInMillisレコード取得間隔(ミリ秒)
callProcessRecordsEvenForEmptyRecord
List
レコードデータが空でもレコード取得処理理を継続するかの判断(True or Fault)
parentShardPollIntervalMillis親のShardをチェックするインターバル
短い値を設定するとDynamoDBのPIOPS⾼高くなるため注意が必要
cleanupLeasesUponShardCompletionshradが終了了した後に継続して処理理を続けるかクリーンアップするかを指定
taskBackoffTimeMillisKCLのバックオフタイムの設定
metricsBufferTimeMillisCloudWatchのAPIコールする前の時間
metricsMaxQueueSizeCloudWatchのAPIコールする最⼤大のキューサイズ
validateSequenceNumberBeforeCheckpo
inting
Checkpointingする前にシーケンス番号をチェックするかを指定
maxActiveThreadsMultiLangDaemonの最⼤大スレッド数
36. KCL for Python実⾏行行⽅方法
[ec2-user@ip-172-31-17-43 samples]$ amazon_kclpy_helper.py --print_command -j /usr/bin/java -p /home/ec2-
user/amazon-kinesis-client-python/samples/sample.properties
/usr/bin/java -cp /usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/amazon-kinesis-
client-1.2.0.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
jackson-annotations-2.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/
jars/commons-codec-1.3.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/
jars/commons-logging-1.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/
jars/joda-time-2.4.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
jackson-databind-2.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
jackson-core-2.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/aws-java-
sdk-1.7.13.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
httpclient-4.2.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
httpcore-4.2.jar:/home/ec2-user/amazon-kinesis-client-python/samples
com.amazonaws.services.kinesis.multilang.MultiLangDaemon sample.properties
出⼒力力結果をコピーして、シェルの⼊入⼒力力
としてペーストし、実⾏行行すると、KCL
が実⾏行行されます
37. 【前提】データ処理理デザインパターン
• データ処理理を⾏行行うアプリケーション側でリカバリーやロードバランシン
グを考慮した設計が必要
• Kinesisの特徴であるシリアル番号を利利⽤用しチェックポイントを打つこと
が重要
• 1つのデータを複数のアプリケーションで利利⽤用できるためアプリケー
ション毎に追加・削除できる設計
• 本番データを⽤用いて開発中のロジックの評価や複数のロジックを同じ
データを⽤用いて評価することが可能
データ
ソース
ロジック
A
ロジック
SeqNoB
(14)
SeqNo
(17)
SeqNo
(25)
SeqNo
(26)
SeqNo
(32)
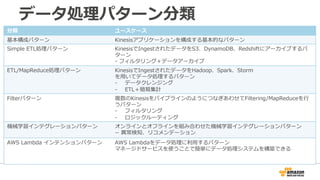
38. データ処理理パターン分類
分類ユースケース
基本構成パターンKinesisアプリケーションを構成する基本的なパターン
Simple ETL処理理パターンKinesisでIngestされたデータをS3、DynamoDB、Redshiftにアーカイブするパ
ターン
-‐‑‒ フィルタリング+データアーカイブ
ETL/MapReduce処理理パターンKinesisでIngestされたデータをHadoop、Spark、Storm
を⽤用いてデータ処理理するパターン
-‐‑‒ データクレンジング
-‐‑‒ ETL+簡易易集計
Filterパターン複数のKinesisをパイプラインのようにつなぎあわせてFiltering/MapReduceを⾏行行
うパターン
-‐‑‒ フィルタリング
-‐‑‒ ロジックルーティング
機械学習インテグレーションパターンオンラインとオフラインを組み合わせた機械学習インテグレーションパターン
−異異
常検知、リコメンデーション
AWS Lambda インテンションパターンAWS Lambdaをデータ処理理に利利⽤用するパターン
マネージドサービスを使うことで簡単にデータ処理理システムを構築できる
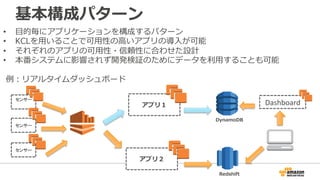
39. 基本構成パターン
• ⽬目的毎にアプリケーションを構成するパターン
• KCLを⽤用いることで可⽤用性の⾼高いアプリの導⼊入が可能
• それぞれのアプリの可⽤用性・信頼性に合わせた設計
• 本番システムに影響されず開発検証のためにデータを利利⽤用することも可能
センサー
センサー
センサー
アプリ1Dashboard
アプリ2
DynamoDB
Redshift
例例:リアルタイムダッシュボード
40. Simple ETL処理理パターン
• DynamoDB、Redshift、S3などとのインテグレーションを容易易にするKinesis
Connector Libraryを利利⽤用可能
https://github.com/awslabs/amazon-kinesis-connectors
センサー
センサー
センサー
S3
アーカイブ
Redshift
データロード
S3
Redshift
Kinesis Connectorのデータフロー
TransformerFilterBufferEmitter
41. ETL/MapReduce処理理パターン(1)
• HadoopやSparkを⽤用いたパターン
• Kinesisに集積されたデータをHive、PigなどのHadoopツールを⽤用いてETL処理理(Map Reduce
処理理)が可能
• 別のKinesis Stream, S3, DynamoDB, HDFSのHive Tableなどの他のデータソースのテーブ
ルとJOINすることなども可能
• Data pipeline / Crontabで定期実⾏行行することにより、定期的にKinesisからデータを取り込み、
処理理することが可能
Data Pipeline
EMR ClusterS3
構成例例
DataPipelineで定期的にHiveを実
⾏行行しKinesisにあるデータを処理理。
結果をS3に格納
Kinesis
EMR AMI 3.0.4以上を⽤用いることでKinesisインテグレーションが可能
42. ETL/MapReduce処理理パターン(2)
• Apache Stormを利利⽤用するパターン
• Boltをつなげることで⾼高度度なデータ処理理をリアルタイムで分散処理理が可能
• KinesisからApache Stormへのインテグレーションを容易易にするためのSpoutを提
供
https://github.com/awslabs/kinesis-‐‑‒storm-‐‑‒spout
Data
Sources
Data
Sources
Data
Sources
Storm
Spout
Storm
Bolt
Storm
Bolt
Storm
Bolt
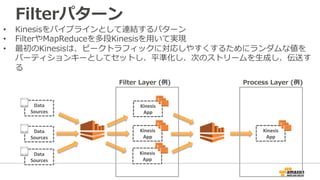
43. Filterパターン
• Kinesisをパイプラインとして連結するパターン
• FilterやMapReduceを多段Kinesisを⽤用いて実現
• 最初のKinesisは、ピークトラフィックに対応しやすくするためにランダムな値を
パーティションキーとしてセットし、平準化し、次のストリームを⽣生成し、伝送す
る
Data
Sources
Data
Sources
Data
Sources
Filter Layer (例例)Process Layer (例例)
Kinesis
App
Kinesis
App
Kinesis
App
Kinesis
App
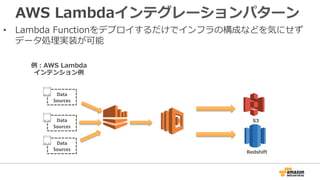
44. 45. AWS Lambdaインテグレーションパターン
• Lambda Functionをデプロイするだけでインフラの構成などを気にせず
データ処理理実装が可能
例例:AWS Lambda
インテンション例例
Data
Sources
Data
Sources
Data
Sources
S3
Redshift
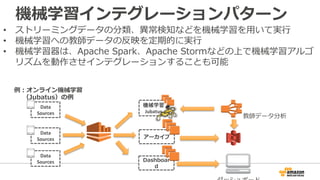
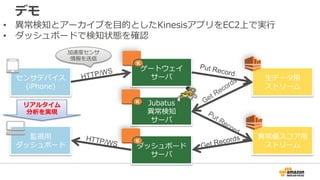
46. デモ
• 異異常検知とアーカイブを⽬目的としたKinesisアプリをEC2上で実⾏行行
• ダッシュボードで検知状態を確認
リアルタイム
分析を実現
ゲートウェイ
サーバ
Jubatus
異異常検知
サーバ
ダッシュボード
サーバ
センサデバイス
(iPhone)
監視⽤用
ダッシュボード
⽣生データ⽤用
ストリーム
異異常値スコア⽤用
ストリーム
HTTP/WS
Put Record
HTTP/WS
Get Records
加速度度センサ
情報を送信
47. 48.








![Kinesis構成内容
Data
Sources
App.1
[Aggregate
De-‐‑‒Duplicate]
App.4
[Machine
Learning]
Data
Sources
Data
Sources
Data
Sources
App.2
[Metric
Extraction]
S3
DynamoDB
Redshift
App.3
[Real-‐‑‒time
Dashboard]
Data
Sources
Stream
Availability
Zone
Availability
Zone
Shard 1
Shard 2
Shard N
Availability
Zone
Kinesis
AWS Endpoint
• ⽤用途単位でStreamを作成し、Streamは、1つ以上のShardで構成される
• Shardは、データ⼊入⼒力力側 1MB/sec, 1000 TPS、データ処理理側 2 MB/sec, 5TPSのキャパシティを持つ
• ⼊入⼒力力するデータをData Recordと呼び、⼊入⼒力力されたData Recordは、24 時間かつ複数のAZに保管される
• Shardの増加減によってスケールの制御が可能](https://image.slidesharecdn.com/pydata-kinesis-20141123-141130185218-conversion-gate01/85/Pydata-Amazon-Kinesis-11-320.jpg)












![Multi Language Protocol
Action Parameter
Initialize shardId : string
processRecords [{ data : ”base64encoded_string,
partitionKey : ”partition key,
sequenceNumber : ”sequence number;
}] // a list of records
checkpoint checkpoint : ”sequence number,
error : NameOfException
shutdown reason : “TERMINATE|ZOMBIE](https://image.slidesharecdn.com/pydata-kinesis-20141123-141130185218-conversion-gate01/85/Pydata-Amazon-Kinesis-34-320.jpg)
![KCL for Python実⾏行行⽅方法
[ec2-user@ip-172-31-17-43 samples]$ amazon_kclpy_helper.py --print_command -j /usr/bin/java -p /home/ec2-
user/amazon-kinesis-client-python/samples/sample.properties
/usr/bin/java -cp /usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/amazon-kinesis-
client-1.2.0.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
jackson-annotations-2.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/
jars/commons-codec-1.3.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/
jars/commons-logging-1.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/
jars/joda-time-2.4.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
jackson-databind-2.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
jackson-core-2.1.1.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/aws-java-
sdk-1.7.13.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
httpclient-4.2.jar:/usr/lib/python2.6/site-packages/amazon_kclpy-1.0.0-py2.6.egg/amazon_kclpy/jars/
httpcore-4.2.jar:/home/ec2-user/amazon-kinesis-client-python/samples
com.amazonaws.services.kinesis.multilang.MultiLangDaemon sample.properties
出⼒力力結果をコピーして、シェルの⼊入⼒力力
としてペーストし、実⾏行行すると、KCL
が実⾏行行されます](https://image.slidesharecdn.com/pydata-kinesis-20141123-141130185218-conversion-gate01/85/Pydata-Amazon-Kinesis-36-320.jpg)






















![[フルバージョン] WebLogic Server for OCI 活用のご提案 - TCO削減とシステムのモダナイズ](https://cdn.slidesharecdn.com/ss_thumbnails/weblogicserverforoci1stcallfull1-210215083511-thumbnail.jpg?width=640&height=640&fit=bounds)













![[AWSマイスターシリーズ] AWS CLI / AWS Tools for Windows PowerShell](https://cdn.slidesharecdn.com/ss_thumbnails/20140115aws-meister-regenerate-awsclipowershell-140130055421-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS初心者向けWebinar] AWSではじめよう、IoTシステム構築](https://cdn.slidesharecdn.com/ss_thumbnails/20151124-iot-151124082925-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[初音ミク] Kinesis でフリーザを撃て!](https://cdn.slidesharecdn.com/ss_thumbnails/jawsdayslt20140315up-140315190450-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[AWS re:invent 2013 Report] Amazon Kinesis](https://cdn.slidesharecdn.com/ss_thumbnails/repotkinesis-131209205850-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)





















