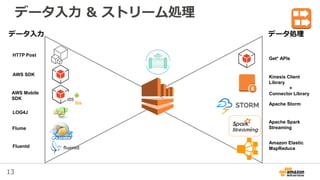
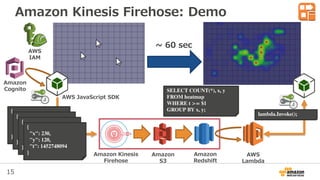
5
Stream
• Sequence ofevents/records/data
• Features
– High throughput/volume
– Continuous ingestion
• Use cases
– Log/event collection
– IoT (sensor data, image, etc.)
Ex. 1 KB * 10K record/s * 365 days
= 300 TB / year
Stream => Big Data
6.
6
Stream processing
• Eventprocessing
– Process each event one by one
• Graph for distributed event processing
– Ex. Apache Storm
• Micro-batch processing
– Process a small amount of events in a batch
• Just like a sequence of batch processing
– Ex. Spark Streaming
7.
7
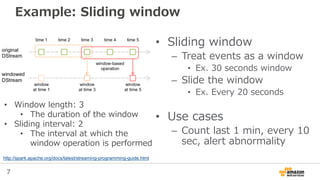
Example: Sliding window
•Sliding window
– Treat events as a window
• Ex. 30 seconds window
– Slide the window
• Ex. Every 20 seconds
• Use cases
– Count last 1 min, every 10
sec, alert abnormality
http://spark.apache.org/docs/latest/streaming-programming-guide.html
• Window length: 3
• The duration of the window
• Sliding interval: 2
• The interval at which the
window operation is performed
19
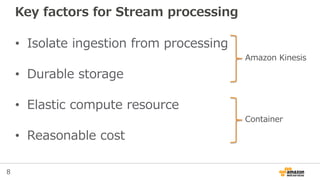
What is "Container"?
•OS-level isolation
• Portability
• Major container engine on AWS
– Docker Engine
– JVM
– AWS Lambda (Node.js/Java/Python)
20.
20
Why is "Container"important for Big Data?
• Scalability
– Easy to scale in/out
• Cost efficiency
– High utilization by multi-tenancy
• Speed of innovation
– Fine-grained architecture / Good abstraction
23
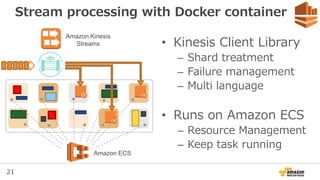
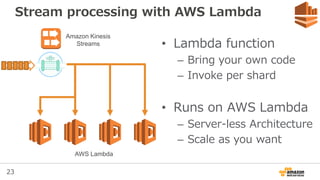
Stream processing withAWS Lambda
• Lambda function
– Bring your own code
– Invoke per shard
• Runs on AWS Lambda
– Server-less Architecture
– Scale as you want
Amazon Kinesis
Streams
AWS Lambda
24.
24
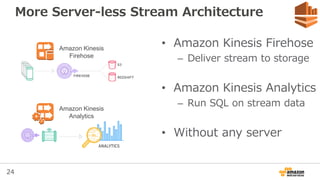
More Server-less StreamArchitecture
• Amazon Kinesis Firehose
– Deliver stream to storage
• Amazon Kinesis Analytics
– Run SQL on stream data
• Without any server
Amazon Kinesis
Analytics
Amazon Kinesis
Firehose

































































![[AWS re:invent 2013 Report] Amazon Kinesis](https://cdn.slidesharecdn.com/ss_thumbnails/repotkinesis-131209205850-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)
