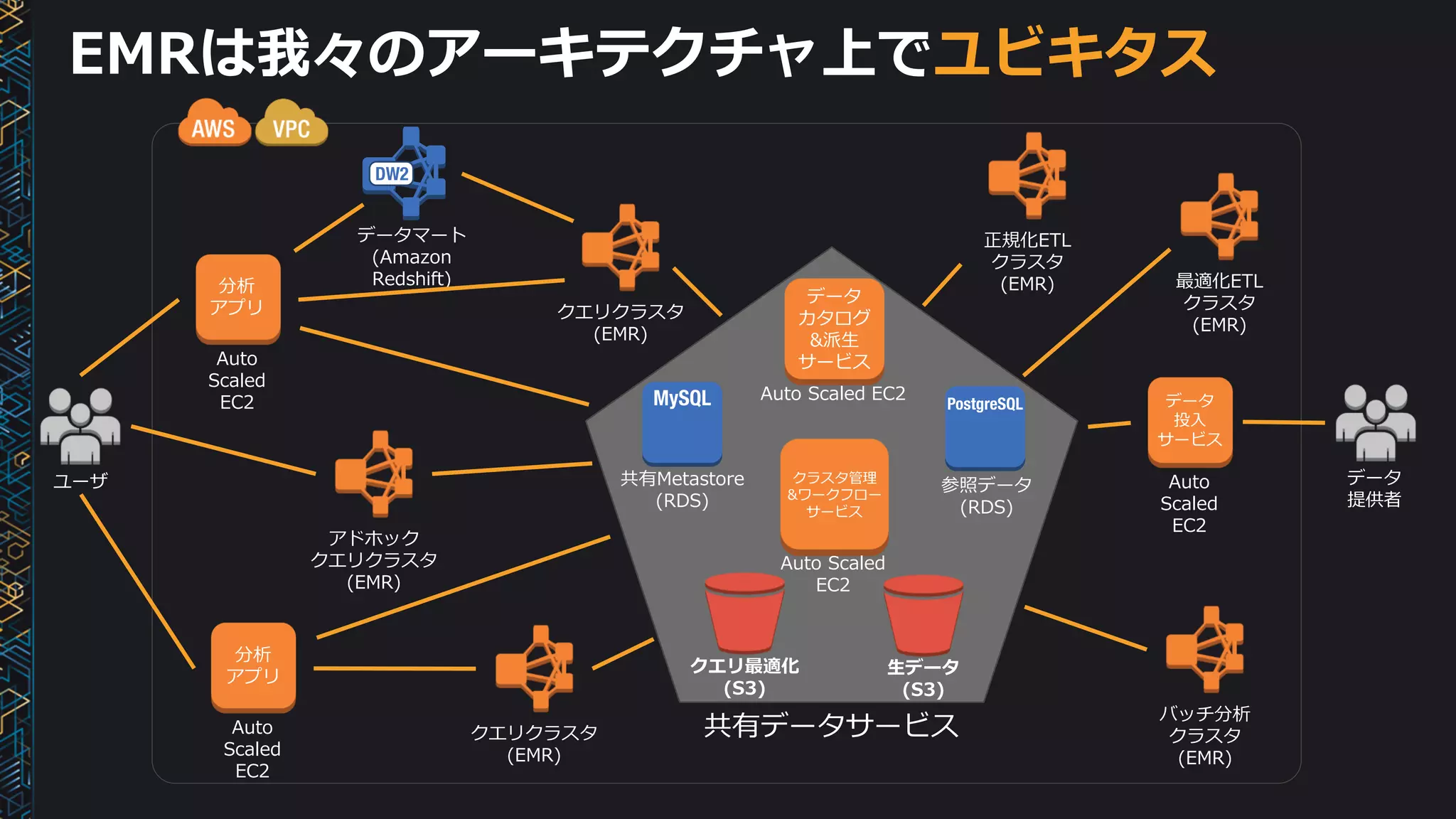
我々の partition とquery 戦略
Data
received
as:
Users
query
by:
Symbol Group 1
Symbol Group 2
Symbol Group 3
…
Symbol Group 100
Late
Data
All late
records
scanned
for all
queries
On Time Data
(Processing Date = Event Date)
99.97% of all records are on time
Symbol Only Query
FirmOnlyQuery
Symbol & Firm Query
↓10,000 Firms
→
20,000
Symobols














![[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/di06-170605024555-thumbnail.jpg?width=640&height=640&fit=bounds)
![[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化](https://cdn.slidesharecdn.com/ss_thumbnails/dlcwt2017infrastructureascodef-171108044056-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる](https://cdn.slidesharecdn.com/ss_thumbnails/dljawsbigdata11clouderaonawsamazonemr3-180207013607-thumbnail.jpg?width=640&height=640&fit=bounds)















![[db tech showcase OSS 2017] A24: マイクロソフトと OSS Database - Azure Database for M...](https://cdn.slidesharecdn.com/ss_thumbnails/uikouazurepostgresqlver1-170621081553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)

![[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/20170524decode17di06hdinsight-170702125017-thumbnail.jpg?width=640&height=640&fit=bounds)























![[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)](https://cdn.slidesharecdn.com/ss_thumbnails/20130925aws-meister-regenerate-emrpublic-130926030316-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)











