Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Tetsutaro Watanabe
PPTX, PDF
3,431 views
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Downloaded 30 times
1
/ 27
2
/ 27
3
/ 27
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
AWS Black Belt - AWS Glue
by
Amazon Web Services Japan
PPTX
Glue DataBrewでデータをクリーニング、加工してみよう
by
takeshi suto
PDF
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
PDF
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
PDF
Apache Airflow入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight
by
Amazon Web Services Japan
PPTX
ビズリーチにおけるEMR(AWS)活用事例
by
Shin Takeuchi
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
AWS Black Belt - AWS Glue
by
Amazon Web Services Japan
Glue DataBrewでデータをクリーニング、加工してみよう
by
takeshi suto
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
Apache Airflow入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight
by
Amazon Web Services Japan
ビズリーチにおけるEMR(AWS)活用事例
by
Shin Takeuchi
What's hot
PDF
データウェアハウスモデリング入門(ダイジェスト版)(事前公開版)
by
Satoshi Nagayasu
PDF
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
PDF
Snowflake Architecture and Performance
by
Mineaki Motohashi
PDF
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
PDF
クラウドのためのアーキテクチャ設計 - ベストプラクティス -
by
SORACOM, INC
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
PDF
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
PPTX
グラフデータベース入門
by
Masaya Dake
PDF
リクルートのWebサービスを支える「RAFTEL」
by
Recruit Technologies
PDF
これで怖くない!?大規模環境で体験するDB負荷対策~垂直から水平の彼方へ~
by
hideakikabuto
PDF
20200930 AWS Black Belt Online Seminar Amazon Kinesis Video Streams
by
Amazon Web Services Japan
PPTX
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
PDF
20190521 AWS Black Belt Online Seminar Amazon Simple Email Service (Amazon SES)
by
Amazon Web Services Japan
PDF
OpenLineage による Airflow のデータ来歴の収集と可視化(Airflow Meetup Tokyo #3 発表資料)
by
NTT DATA Technology & Innovation
PDF
20191001 AWS Black Belt Online Seminar AWS Lake Formation
by
Amazon Web Services Japan
PDF
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
PPTX
Azure Search 大全
by
Daiyu Hatakeyama
PDF
異音検知プラットフォーム開発におけるMLOpsの実際と考察 - MLOps コミュニティ #3
by
Shota Saitoh
PDF
「GraphDB徹底入門」〜構造や仕組み理解から使いどころ・種々のGraphDBの比較まで幅広く〜
by
Takahiro Inoue
データウェアハウスモデリング入門(ダイジェスト版)(事前公開版)
by
Satoshi Nagayasu
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
Snowflake Architecture and Performance
by
Mineaki Motohashi
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
クラウドのためのアーキテクチャ設計 - ベストプラクティス -
by
SORACOM, INC
AWSで作る分析基盤
by
Yu Otsubo
マイクロにしすぎた結果がこれだよ!
by
mosa siru
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
グラフデータベース入門
by
Masaya Dake
リクルートのWebサービスを支える「RAFTEL」
by
Recruit Technologies
これで怖くない!?大規模環境で体験するDB負荷対策~垂直から水平の彼方へ~
by
hideakikabuto
20200930 AWS Black Belt Online Seminar Amazon Kinesis Video Streams
by
Amazon Web Services Japan
MLflowで学ぶMLOpsことはじめ
by
Kenichi Sonoda
20190521 AWS Black Belt Online Seminar Amazon Simple Email Service (Amazon SES)
by
Amazon Web Services Japan
OpenLineage による Airflow のデータ来歴の収集と可視化(Airflow Meetup Tokyo #3 発表資料)
by
NTT DATA Technology & Innovation
20191001 AWS Black Belt Online Seminar AWS Lake Formation
by
Amazon Web Services Japan
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
Azure Search 大全
by
Daiyu Hatakeyama
異音検知プラットフォーム開発におけるMLOpsの実際と考察 - MLOps コミュニティ #3
by
Shota Saitoh
「GraphDB徹底入門」〜構造や仕組み理解から使いどころ・種々のGraphDBの比較まで幅広く〜
by
Takahiro Inoue
Similar to リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
PDF
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
PDF
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PDF
AWS Black Belt Online Seminar 2016 Amazon EMR
by
Amazon Web Services Japan
PPTX
ATN No.1 Hadoop vs Amazon EMR
by
AdvancedTechNight
PDF
20111130 10 aws-meister-emr_long-public
by
Amazon Web Services Japan
PDF
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
PPT
マーケティングテクノロジー勉強会
by
伊藤 孝
PDF
Modernizing Big Data Workload Using Amazon EMR & AWS Glue
by
Noritaka Sekiyama
PDF
AWS Elastic MapReduce詳細 -ほぼ週刊AWSマイスターシリーズ第10回-
by
SORACOM, INC
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
PPTX
20170803 bigdataevent
by
Makoto Uehara
PDF
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
PDF
ビッグデータ活用とサーバー基盤
by
日本ヒューレット・パッカード株式会社
PDF
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
PDF
基幹業務もHadoop(EMR)で!!のその後
by
Keigo Suda
PDF
リクルート式Hadoopの使い方
by
Recruit Technologies
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
AWS Black Belt Online Seminar 2016 Amazon EMR
by
Amazon Web Services Japan
ATN No.1 Hadoop vs Amazon EMR
by
AdvancedTechNight
20111130 10 aws-meister-emr_long-public
by
Amazon Web Services Japan
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
マーケティングテクノロジー勉強会
by
伊藤 孝
Modernizing Big Data Workload Using Amazon EMR & AWS Glue
by
Noritaka Sekiyama
AWS Elastic MapReduce詳細 -ほぼ週刊AWSマイスターシリーズ第10回-
by
SORACOM, INC
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
20170803 bigdataevent
by
Makoto Uehara
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
ビッグデータ活用とサーバー基盤
by
日本ヒューレット・パッカード株式会社
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
基幹業務もHadoop(EMR)で!!のその後
by
Keigo Suda
リクルート式Hadoopの使い方
by
Recruit Technologies
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
More from Tetsutaro Watanabe
PPTX
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
PPTX
MLOpsはバズワード
by
Tetsutaro Watanabe
PPTX
ドライブレコーダの動画を使った道路情報の自動差分抽出
by
Tetsutaro Watanabe
PPTX
IoTデバイスデータ収集の難しい点
by
Tetsutaro Watanabe
PPTX
ドライブレコーダの画像認識による道路情報の自動差分抽出
by
Tetsutaro Watanabe
PPTX
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
PPTX
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
PPTX
ML Ops NYC 19 & Strata Data Conference 2019 NewYork 注目セッションまとめ
by
Tetsutaro Watanabe
PPTX
タクシードライブレコーダーの動画処理MLパイプラインにkubernetesを使ってみた
by
Tetsutaro Watanabe
PPTX
JapanTaxiにおけるSagemaker+αによる機械学習アプリケーションの本番運用
by
Tetsutaro Watanabe
PPTX
JapanTaxiにおけるML Ops 〜機械学習の開発運用プロセス〜
by
Tetsutaro Watanabe
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PPTX
Google Cloud Next '18 Recap/報告会 機械学習関連
by
Tetsutaro Watanabe
PPTX
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
PPTX
リクルートを支える横断データ基盤と機械学習の適用事例
by
Tetsutaro Watanabe
PPTX
WiredTigerを詳しく説明
by
Tetsutaro Watanabe
PPTX
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
PPTX
ビックデータ処理技術の全体像とリクルートでの使い分け
by
Tetsutaro Watanabe
PPTX
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
PPTX
MongoDB3.2の紹介
by
Tetsutaro Watanabe
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
MLOpsはバズワード
by
Tetsutaro Watanabe
ドライブレコーダの動画を使った道路情報の自動差分抽出
by
Tetsutaro Watanabe
IoTデバイスデータ収集の難しい点
by
Tetsutaro Watanabe
ドライブレコーダの画像認識による道路情報の自動差分抽出
by
Tetsutaro Watanabe
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
ML Ops NYC 19 & Strata Data Conference 2019 NewYork 注目セッションまとめ
by
Tetsutaro Watanabe
タクシードライブレコーダーの動画処理MLパイプラインにkubernetesを使ってみた
by
Tetsutaro Watanabe
JapanTaxiにおけるSagemaker+αによる機械学習アプリケーションの本番運用
by
Tetsutaro Watanabe
JapanTaxiにおけるML Ops 〜機械学習の開発運用プロセス〜
by
Tetsutaro Watanabe
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
Google Cloud Next '18 Recap/報告会 機械学習関連
by
Tetsutaro Watanabe
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
リクルートを支える横断データ基盤と機械学習の適用事例
by
Tetsutaro Watanabe
WiredTigerを詳しく説明
by
Tetsutaro Watanabe
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
ビックデータ処理技術の全体像とリクルートでの使い分け
by
Tetsutaro Watanabe
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
MongoDB3.2の紹介
by
Tetsutaro Watanabe
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
1.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. リクルートテクノロジーズにおける EMR の活用とコスト圧縮方法 2017/7/5 株式会社リクルートテクノロジーズ ビッグデータ部 渡部徹太郎 AWS Solution Days 2017
2.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. BIG DATA Department自己紹介 ID: fetaro 名前: 渡部 徹太郎 所属: リクルートテクノロジーズ ビッグデータ部 略歴: 学生: 東京工業大学でデータ工学の研究 SIer 前半: 大手証券会社のオンライントレードシステム基盤 SIer 後半: オープンソース技術部隊 NoSQL, MongoDB 現職: 全社横断分析基盤: Oracle Exadata, Hortonworks 個社向け分析基盤: AWS EMR 趣味: 自宅サーバ、麻雀 エディタ: emacs派 1 AWS ビッグデータ ユーザ会
3.
(C) Recruit Technologies
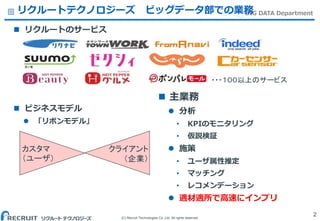
Co.,Ltd. All rights reserved. BIG DATA Departmentリクルートテクノロジーズ ビッグデータ部での業務 リクルートのサービス ビジネスモデル 「リボンモデル」 2 カスタマ (ユーザ) クライアント (企業) 主業務 分析 • KPIのモニタリング • 仮説検証 施策 • ユーザ属性推定 • マッチング • レコメンデーション 適材適所で高速にインプリ ・・・100以上のサービス
4.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. BIG DATA Departmentアジェンダ Hadoopの説明 EMRの紹介 リクルートテクノロジーズでの使い方 活用事例 3
5.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. Hadoopの説明 4
6.
(C) Recruit Technologies
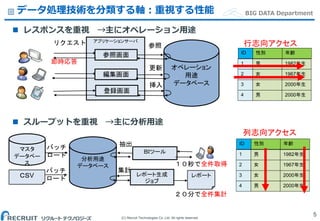
Co.,Ltd. All rights reserved. BIG DATA Departmentデータ処理技術を分類する軸:重視する性能 5 レスポンスを重視 →主にオペレーション用途 スループットを重視 →主に分析用途 アプリケーションサーバ オペレーション 用途 データベース 登録画面 リクエスト 参照 更新 挿入 参照画面 編集画面 即時応答 マスタ データベー ス BIツール 集計 バッチ ロード 分析用途 データベース レポート生成 ジョブ 抽出 CSV バッチ ロード レポート 20分で全件集計 10秒で全件取得 1 1982年生 2 1967年生 3 2000年生 4 2000年生 男 女 女 男 ID 年齢性別 1 1982年生 2 1967年生 3 2000年生 4 2000年生 男 女 女 男 ID 年齢性別 行志向アクセス 列志向アクセス
7.
(C) Recruit Technologies
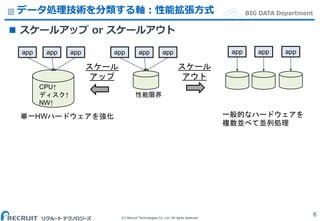
Co.,Ltd. All rights reserved. BIG DATA Departmentデータ処理技術を分類する軸:性能拡張方式 6 スケール アップ スケール アウト app app app app app appapp app app 一般的なハードウェアを 複数並べて並列処理 単一HWハードウェアを強化 性能限界 CPU↑ ディスク↑ NW↑ スケールアップ or スケールアウト
8.
(C) Recruit Technologies
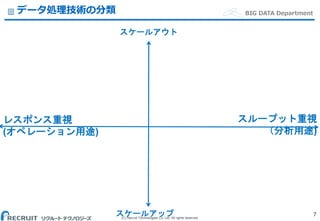
Co.,Ltd. All rights reserved. BIG DATA Departmentデータ処理技術の分類 7 レスポンス重視 (オペレーション用途) スループット重視 (分析用途) スケールアップ スケールアウト
9.
(C) Recruit Technologies
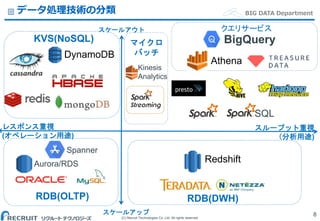
Co.,Ltd. All rights reserved. BIG DATA Department BigQuery Spanner データ処理技術の分類 8 レスポンス重視 (オペレーション用途) スループット重視 (分析用途) スケールアップ DynamoDB Redshift Athena Aurora/RDS RDB(OLTP) KVS(NoSQL) RDB(DWH) スケールアウト Kinesis Analytics マイクロ バッチ SQL クエリサービス
10.
(C) Recruit Technologies
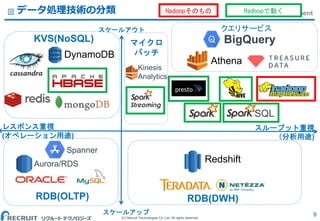
Co.,Ltd. All rights reserved. BIG DATA Department BigQuery Spanner データ処理技術の分類 9 レスポンス重視 (オペレーション用途) スループット重視 (分析用途) スケールアップ DynamoDB Redshift Athena Aurora/RDS RDB(OLTP) KVS(NoSQL) RDB(DWH) スケールアウト Kinesis Analytics マイクロ バッチ SQL クエリサービス Hadoopそのもの Hadoopで動く
11.
(C) Recruit Technologies
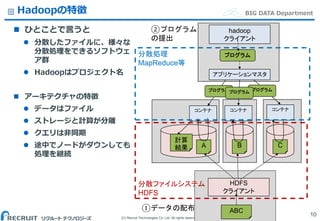
Co.,Ltd. All rights reserved. BIG DATA DepartmentHadoopの特徴 ひとことで言うと 分散したファイルに、様々な 分散処理をできるソフトウェ ア群 Hadoopはプロジェクト名 アーキテクチャの特徴 データはファイル ストレージと計算が分離 クエリは非同期 途中でノードがダウンしても 処理を継続 10 ABC A B C HDFS クライアント コンテナ コンテナ コンテナ アプリケーションマスタ ①データの配布 ②プログラム の提出 計算 結果 プログラム プログラム hadoop クライアント プログラムプログラム 分散ファイルシステム HDFS 分散処理 MapReduce等
12.
(C) Recruit Technologies
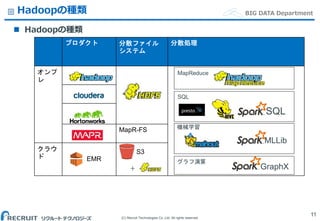
Co.,Ltd. All rights reserved. BIG DATA DepartmentHadoopの種類 Hadoopの種類 11 プロダクト 分散ファイル システム 分散処理 オンプ レ MapR-FS クラウ ド EMR S3 MapReduce SQL 機械学習 グラフ演算 GraphX SQL MLLib +
13.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. EMRの説明 12
14.
(C) Recruit Technologies
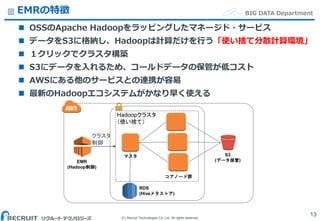
Co.,Ltd. All rights reserved. BIG DATA DepartmentEMRの特徴 OSSのApache Hadoopをラッピングしたマネージド・サービス データをS3に格納し、Hadoopは計算だけを行う「使い捨て分散計算環境」 1クリックでクラスタ構築 S3にデータを入れるため、コールドデータの保管が低コスト AWSにある他のサービスとの連携が容易 最新のHadoopエコシステムがかなり早く使える 13 S3 (データ保管)EMR (Hadoop制御) RDS (Hiveメタストア) マスタ Hadoopクラスタ (使い捨て) クラスタ 制御 コアノード群
15.
(C) Recruit Technologies
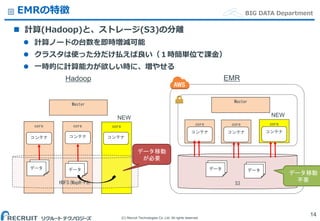
Co.,Ltd. All rights reserved. BIG DATA Department core core core HDFS(MapR-FS) EMRの特徴 計算(Hadoop)と、ストレージ(S3)の分離 計算ノードの台数を即時増減可能 クラスタは使った分だけ払えば良い(1時簡単位で課金) 一時的に計算能力が欲しい時に、増やせる 14 S3 Master データ データ コンテナ データ データ コンテナ データ データデータ データ core コンテナ Master コンテナ core コンテナ core コンテナ Hadoop EMR NEWNEW データ移動 が必要 データ移動 不要
16.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. BIG DATA DepartmentEMRはオンプレHadoopの課題を解決 15 オンプレHadoop EMR 構築 ✕ 非常に複雑で手間がかかる ◯ APIコールのみ 運用 ✕ 高い技術力と重厚な体制が必要 △ H/Wの面倒を見なくて良くなる コードによる構成管理ができる 破棄可能になる スケールアウト・ス ケールイン速度 △ H/Wの調達が必要 データの移動が必要 ◯ 即時 データの移動は不要 スケールアウトの限 界 ✕ DCの物理的な限界がある ◯ ほぼ無限 開発環境 ✕ H/Wの購入が必要 ◯ 必要なときだけ従量課金できる
17.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. リクルートテクノロジーズでの使い方 16
18.
(C) Recruit Technologies
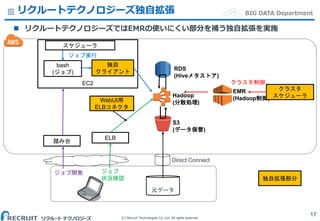
Co.,Ltd. All rights reserved. BIG DATA Departmentリクルートテクノロジーズ独自拡張 リクルートテクノロジーズではEMRの使いにくい部分を補う独自拡張を実施 17 独自拡張部分 元データ S3 (データ保管) Hadoop (分散処理) EMR (Hadoop制御) EC2 クラスタ スケジューラ RDS (Hiveメタストア) 独自 クライアント WebUI用 ELBコネクタ bash (ジョブ) ELB ジョブ 状況確認 Direct Connect 踏み台 ジョブ開発 スケジューラ ジョブ実行 クラスタ制御
19.
(C) Recruit Technologies
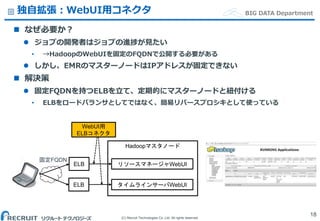
Co.,Ltd. All rights reserved. BIG DATA Department独自拡張:WebUI用コネクタ なぜ必要か? ジョブの開発者はジョブの進捗が見たい • →HadoopのWebUIを固定のFQDNで公開する必要がある しかし、EMRのマスターノードはIPアドレスが固定できない 解決策 固定FQDNを持つELBを立て、定期的にマスターノードと紐付ける • ELBをロードバランサとしてではなく、簡易リバースプロシキとして使っている 18 WebUI用 ELBコネクタ ELB 固定FQDN Hadoopマスタノード リソースマネージャWebUI タイムラインサーバWebUIELB
20.
(C) Recruit Technologies
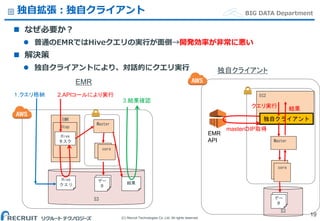
Co.,Ltd. All rights reserved. BIG DATA Department独自拡張:独自クライアント なぜ必要か? 普通のEMRではHiveクエリの実行が面倒→開発効率が非常に悪い 解決策 独自クライアントにより、対話的にクエリ実行 19 S3 EMR Step Hive クエリ Hive タスク 2.APIコールにより実行 EMR 結果 core Master core デー タ デー タ 1.クエリ格納 3.結果確認 S3 独自クライアント core Master デー タ デー タ EC2 core 独自クライアント 結果クエリ実行 masterのIP取得 EMR API
21.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. BIG DATA Department独自拡張:独自クライアント 使い勝手 特徴 pythonのライブラリとして導入 マスターノードを探し出して、SSHで接続して処理を実行 hive, hadoopクライアントと同等の使い勝手 • 結果がすぐに確認できる。bashでエラーハンドリングできる 引数を変えるだけで、クエリを実行するクラスタを変えられる • 本番、開発環境の打ち分けも引数だけで可能 非同期オプションを使えば、SSH通信が切れても問題なし 工夫点 APIの結果をキャッシュ EMRマスターノードのSSH接続数を増加 Hiveのクエリのエスケープ 20 $ rhive cluster1 -e "select * from table1;"
22.
(C) Recruit Technologies
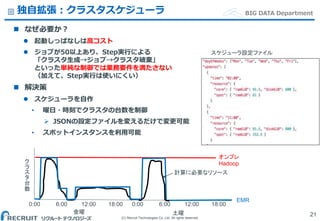
Co.,Ltd. All rights reserved. BIG DATA Department独自拡張:クラスタスケジューラ なぜ必要か? 起動しっぱなしは高コスト ジョブが50以上あり、Step実行による 「クラスタ生成→ジョブ→クラスタ破棄」 といった単純な制御では業務要件を満たさない (加えて、Step実行は使いにくい) 解決策 スケジューラを自作 • 曜日・時刻でクラスタの台数を制御 JSONの設定ファイルを変えるだけで変更可能 • スポットインスタンスを利用可能 21 0:00 6:00 12:00 18:00 ク ラ ス タ 台 数 オンプレ Hadoop 0:00 6:00 12:00 18:00 金曜 土曜 EMR 計算に必要なリソース スケジューラ設定ファイル
23.
(C) Recruit Technologies
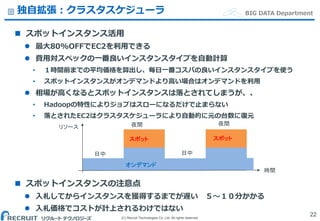
Co.,Ltd. All rights reserved. BIG DATA Department独自拡張:クラスタスケジューラ スポットインスタンス活用 最大80%OFFでEC2を利用できる 費用対スペックの一番良いインスタンスタイプを自動計算 • 1時間前までの平均価格を算出し、毎日一番コスパの良いインスタンスタイプを使う • スポットインスタンスがオンデマンドより高い場合はオンデマンドを利用 相場が高くなるとスポットインスタンスは落とされてしまうが、、 • Hadoopの特性によりジョブはスローになるだけで止まらない • 落とされたEC2はクラスタスケジューラにより自動的に元の台数に復元 スポットインスタンスの注意点 入札してからインスタンスを獲得するまでが遅い 5〜10分かかる 入札価格でコストが計上されるわけではない 22 オンデマンド スポット スポット 時間 リソース 夜間 日中 夜間 日中
24.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. BIG DATA Department独自拡張:クラスタスケジューラ SpotFleetでいいんじゃないの?? SpotFleetが出る1年前から実装して使ってます!! 23
25.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. 活用事例 24
26.
(C) Recruit Technologies
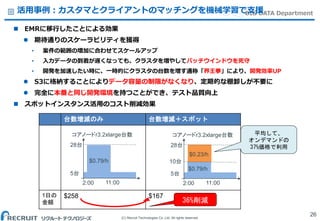
Co.,Ltd. All rights reserved. BIG DATA Department活用事例:カスタマとクライアントのマッチングを機械学習で支援 業務 バッチによりカスタマ(約1万アクティブユーザ)とクライアント(約1万件)のマッチングのス コアを計算 →営業業務の大幅な工数削減に寄与 KPIモニタリングデータをBIツールに連携 →データドリブンな意思決定を支援 仕組み 毎晩50以上のジョブ データ量は30TB以上(ORC+Snappy圧縮) オンプレHadoopの課題 施策の領域によって、対象のカスタマの量が変わるので、キャパシティのプランニングが困難 クラウド移行を検討するも、既存のSQLベースの分析技術では自然言語解析や機械学習がで きない EMRの選択 必要な分だけクラスタを使える Hadoopの強力な分散計算能力(自然言語解析、機械学習)を利用できる オンプレHadoopのプログラムがほぼそのまま動くため、移行工数が低い 25
27.
(C) Recruit Technologies
Co.,Ltd. All rights reserved. BIG DATA Department活用事例:カスタマとクライアントのマッチングを機械学習で支援 EMRに移行したことによる効果 期待通りのスケーラビリティを獲得 • 案件の範囲の増加に合わせてスケールアップ • 入力データの到着が遅くなっても、クラスタを増やしてバッチウインドウを死守 • 開発を加速したい時に、一時的にクラスタの台数を増す通称「界王拳」により、開発効率UP S3に格納することによりデータ容量の制限がなくなり、定期的な棚卸しが不要に 完全に本番と同じ開発環境を持つことができ、テスト品質向上 スポットインスタンス活用のコスト削減効果 26 台数増減のみ 台数増減+スポット 1日の 金額 $258 $167 5台 28台 $0.79/h 2:00 11:00 コアノードr3.2xlarge台数 5台 28台 $0.79/h $0.23/h 2:00 11:00 コアノードr3.2xlarge台数 10台 平均して、 オンデマンドの 37%価格で利用 36%削減
Download



















![[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessiondatalake-191027185852-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)](https://cdn.slidesharecdn.com/ss_thumbnails/20130925aws-meister-regenerate-emrpublic-130926030316-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































