Download to read offline



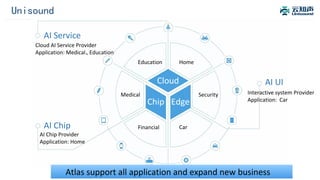
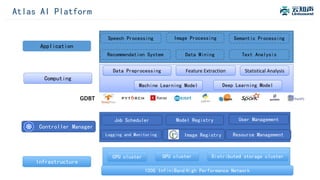
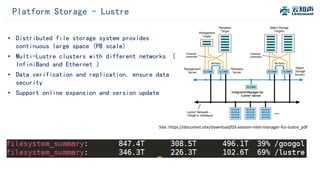



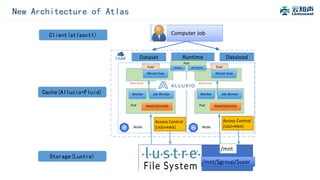



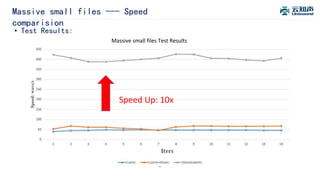
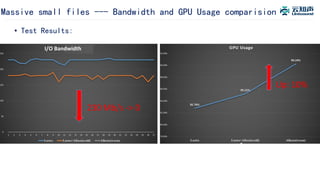

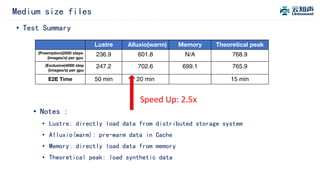

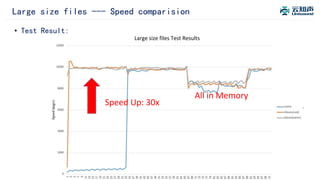
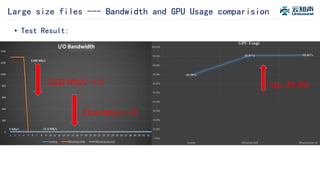

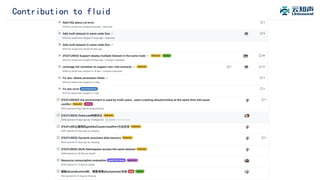




The document discusses the integration of Alluxio with the Atlas deep learning platform to enhance performance by addressing storage and data management challenges. It presents test scenarios demonstrating significant speed improvements across various file sizes and applications, highlighting up to 30x acceleration in processing large datasets. The paper concludes with a call for further exploration and optimization of fluid scheduling in conjunction with Alluxio to improve user experience and system efficiency.























































































