Downloaded 77 times












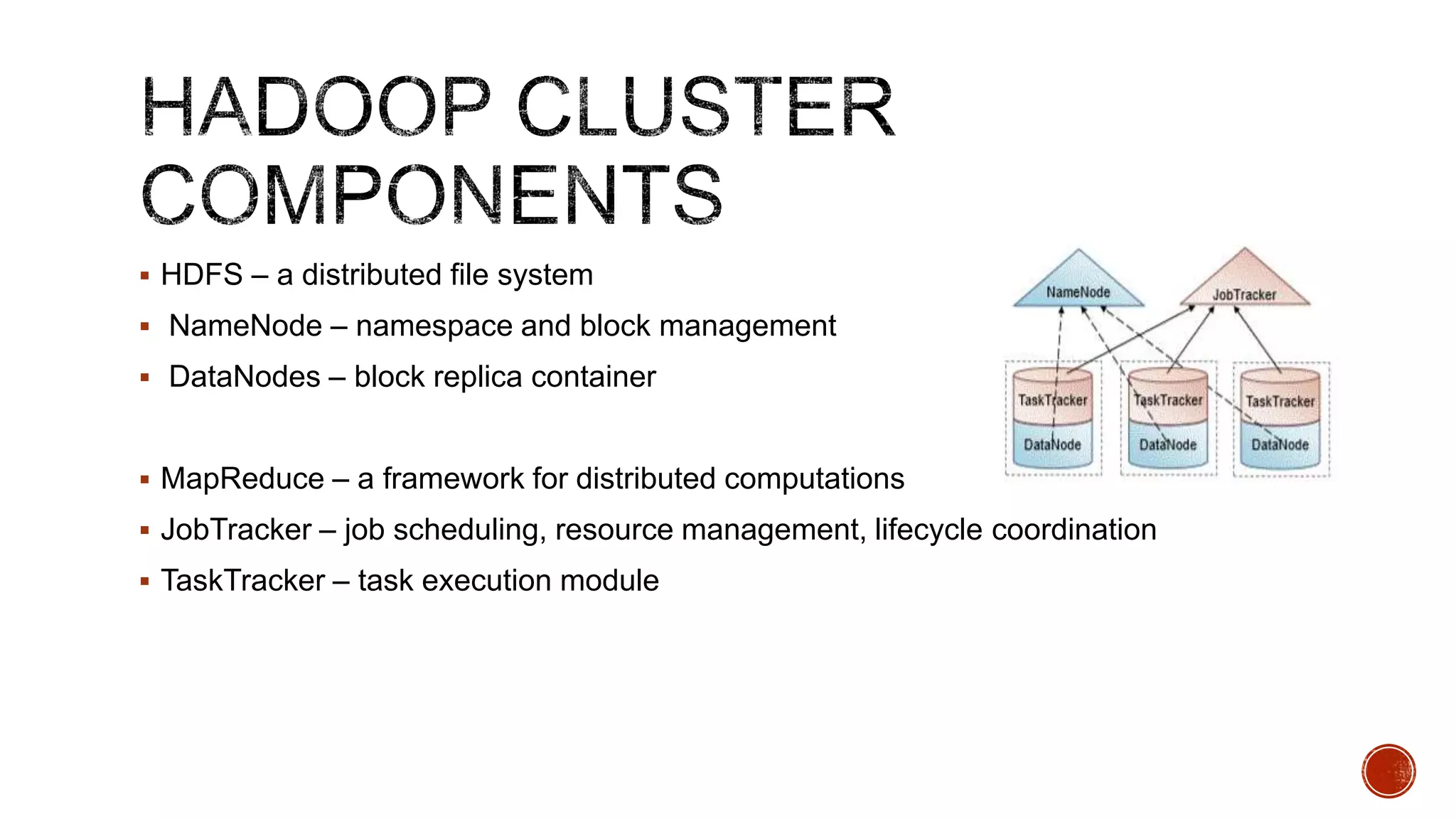




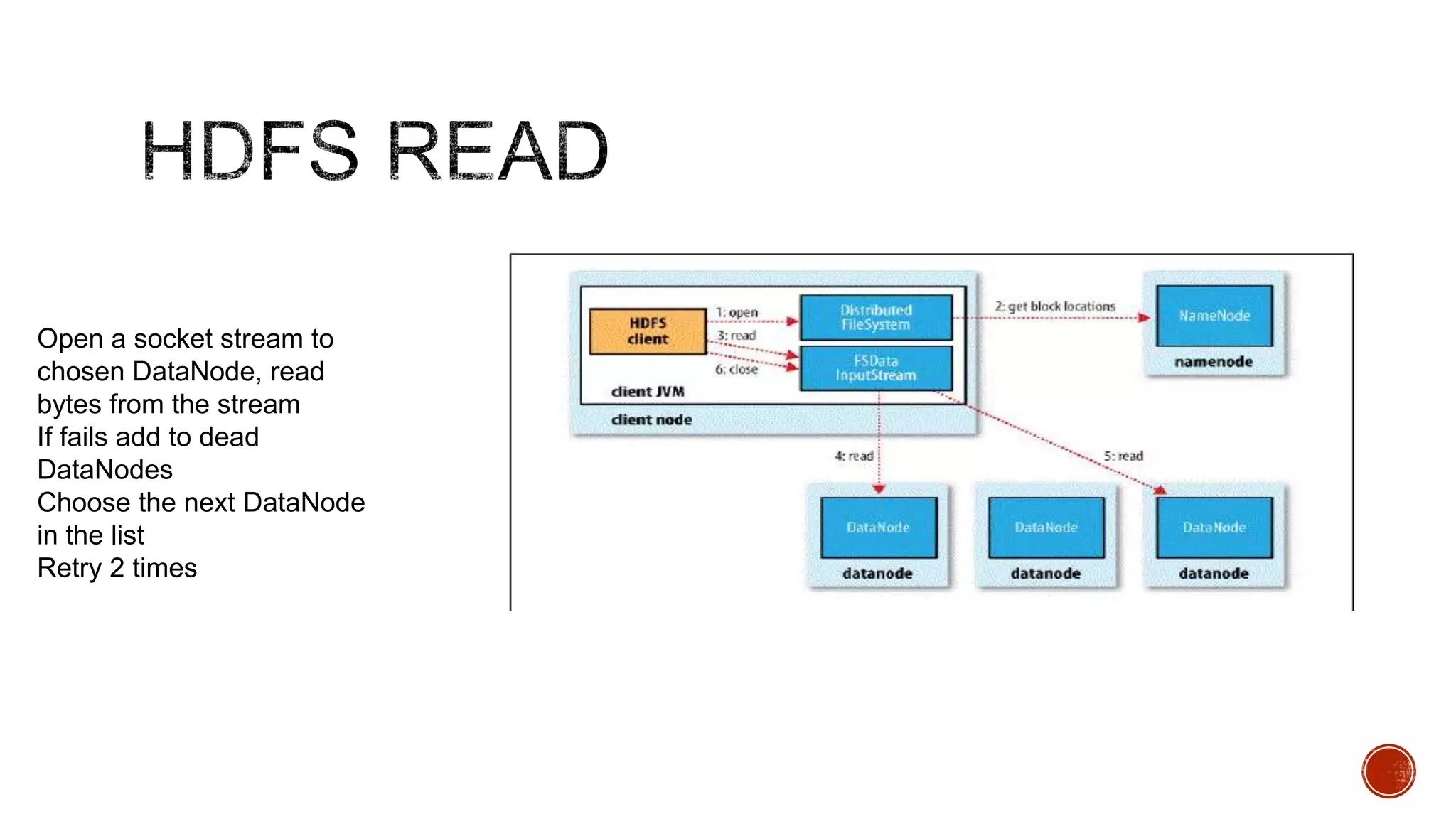
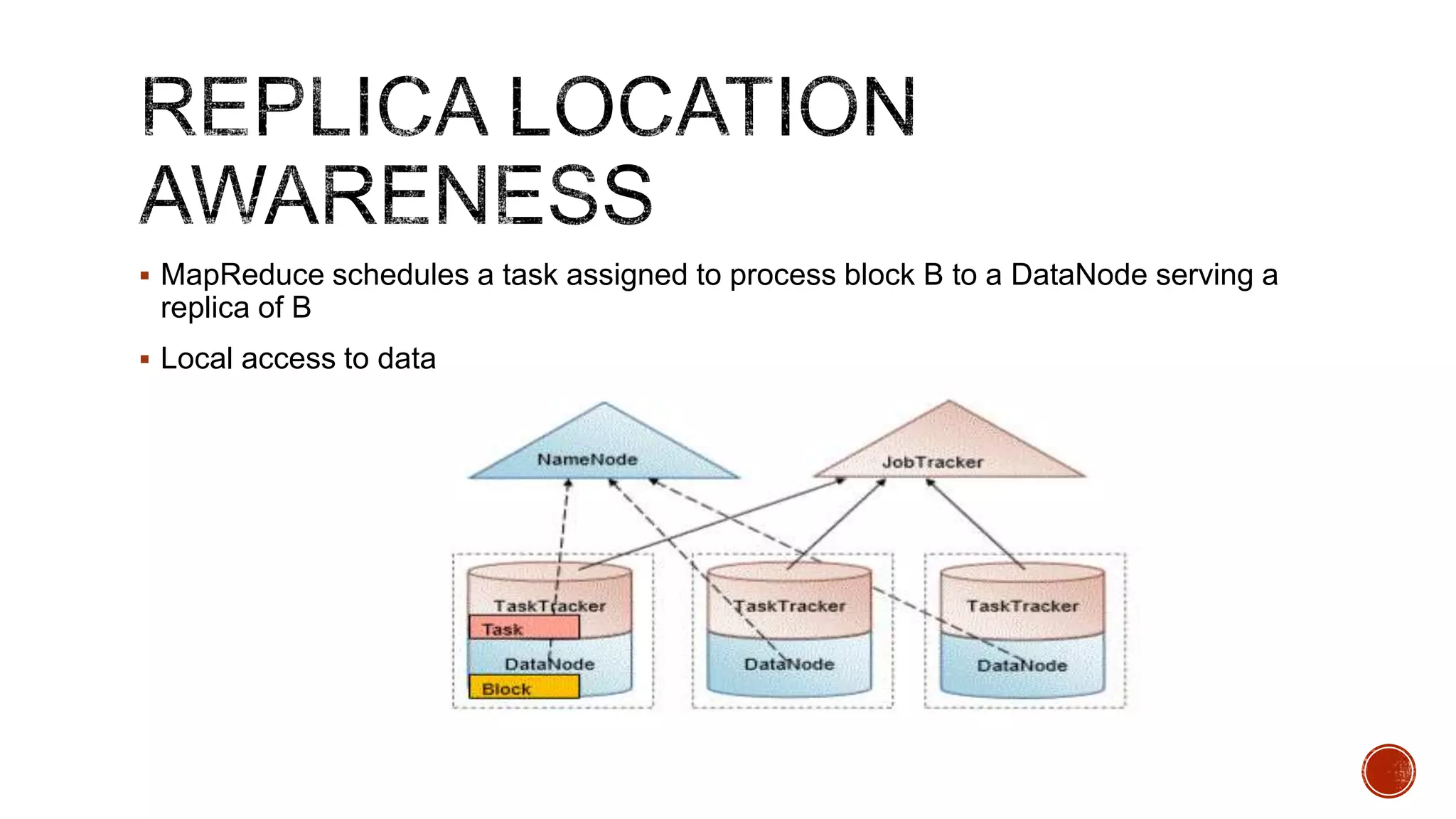


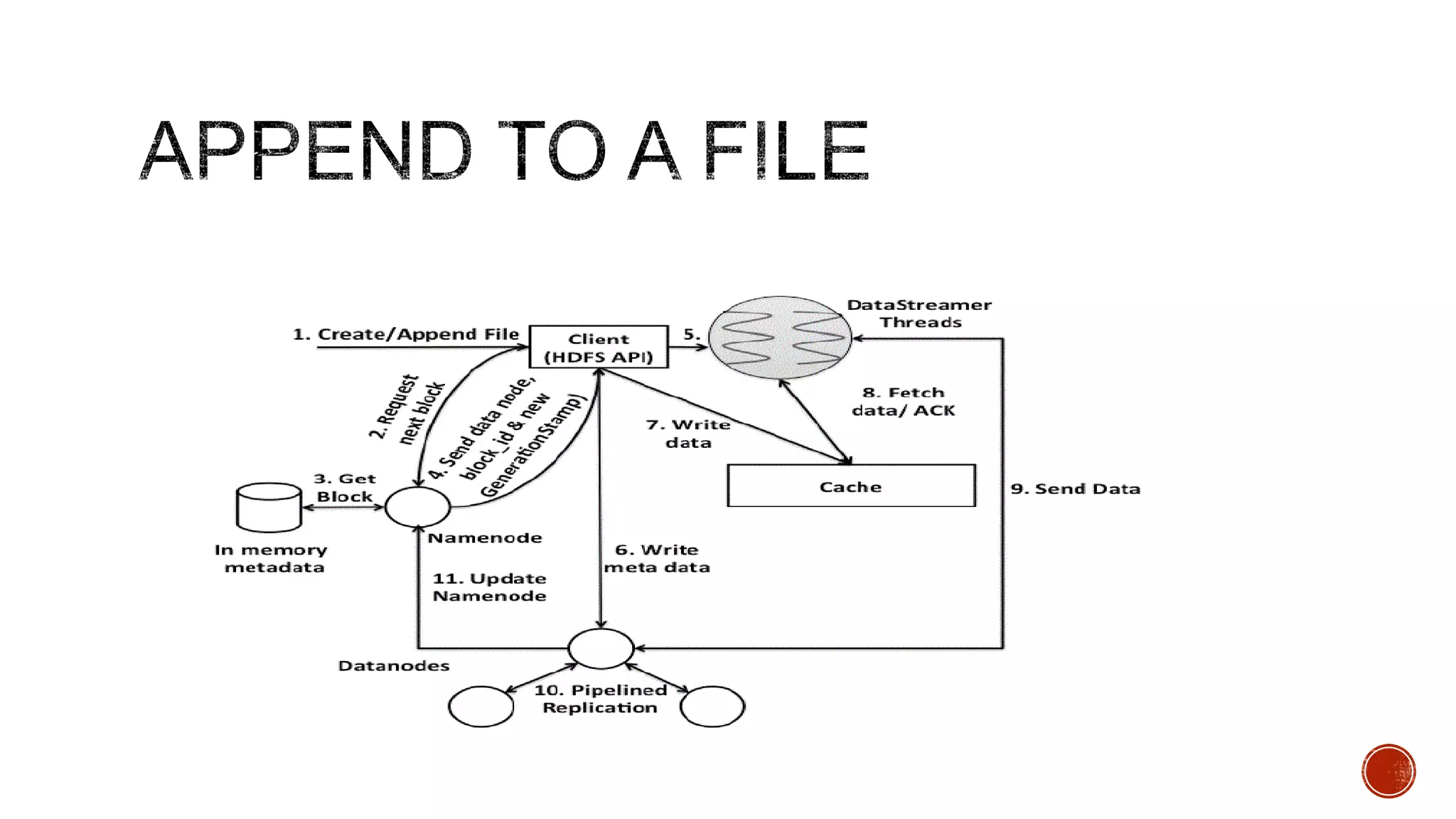







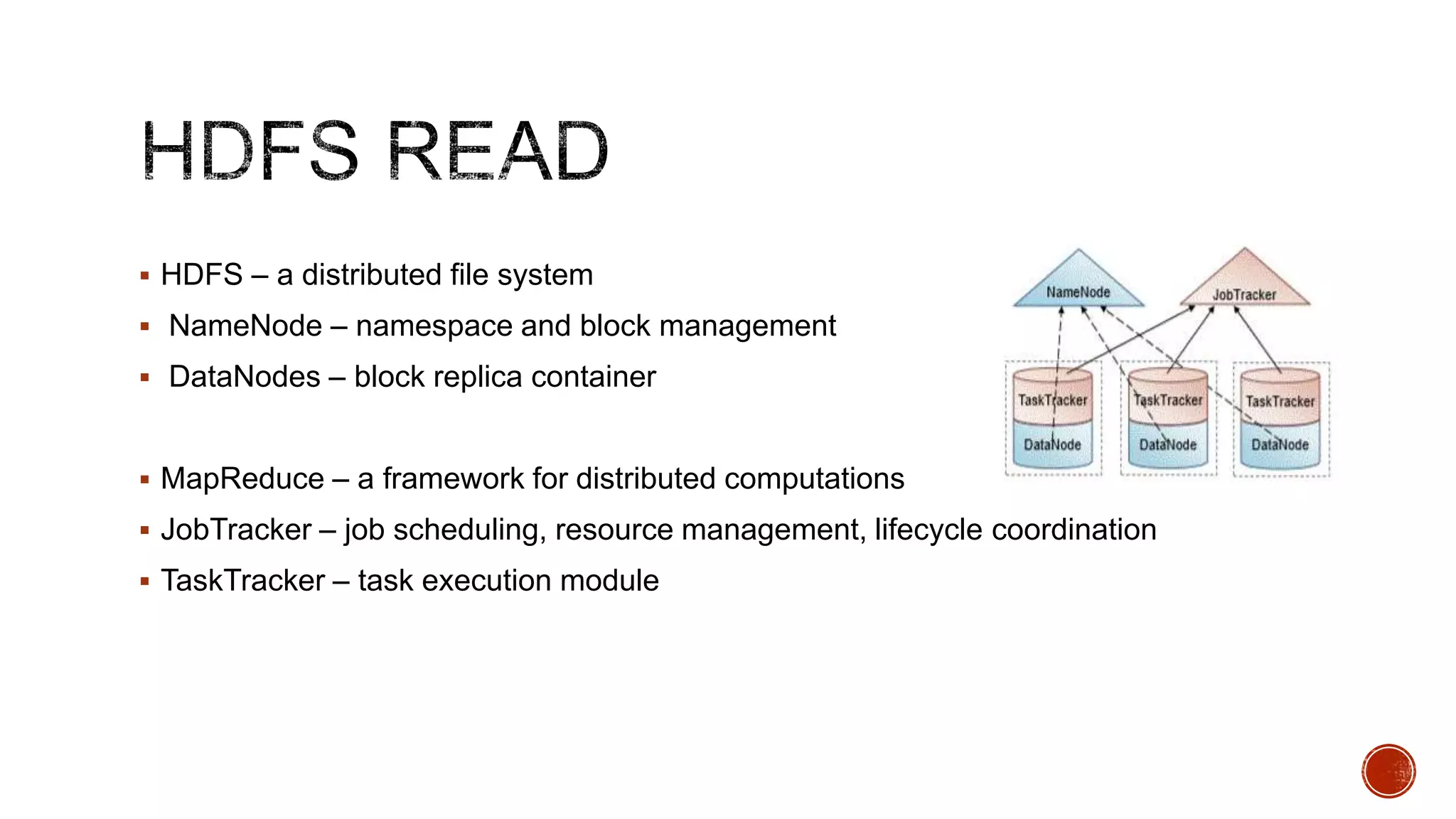





Hadoop is a distributed processing framework for large data sets across clusters of commodity hardware. It has two main components: HDFS for reliable data storage, and MapReduce for distributed processing of large data sets. Hadoop can scale from single servers to thousands of machines, handling data measuring petabytes with very high throughput. It provides reliability even if individual machines fail, and is easy to set up and manage.







































































