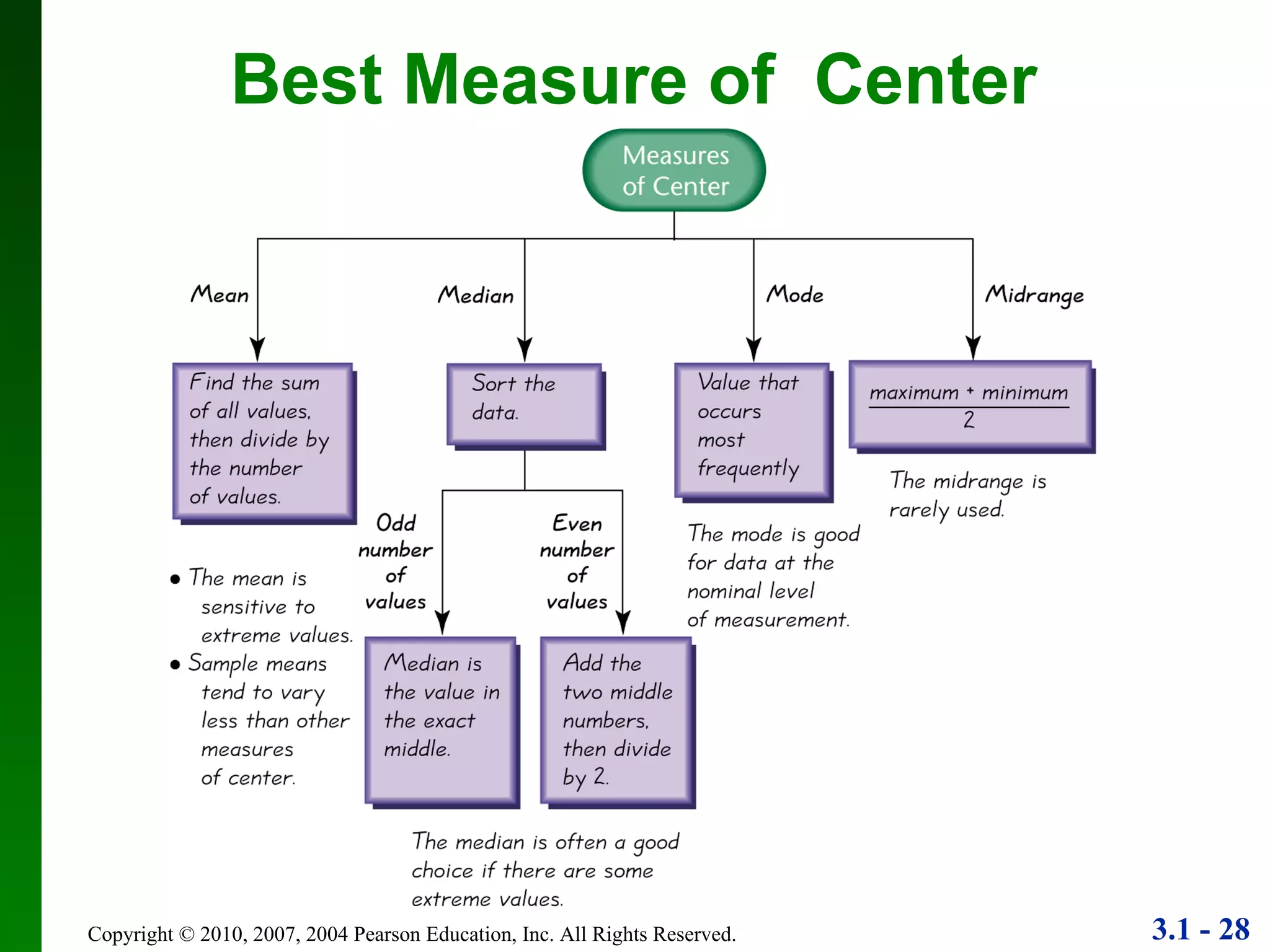
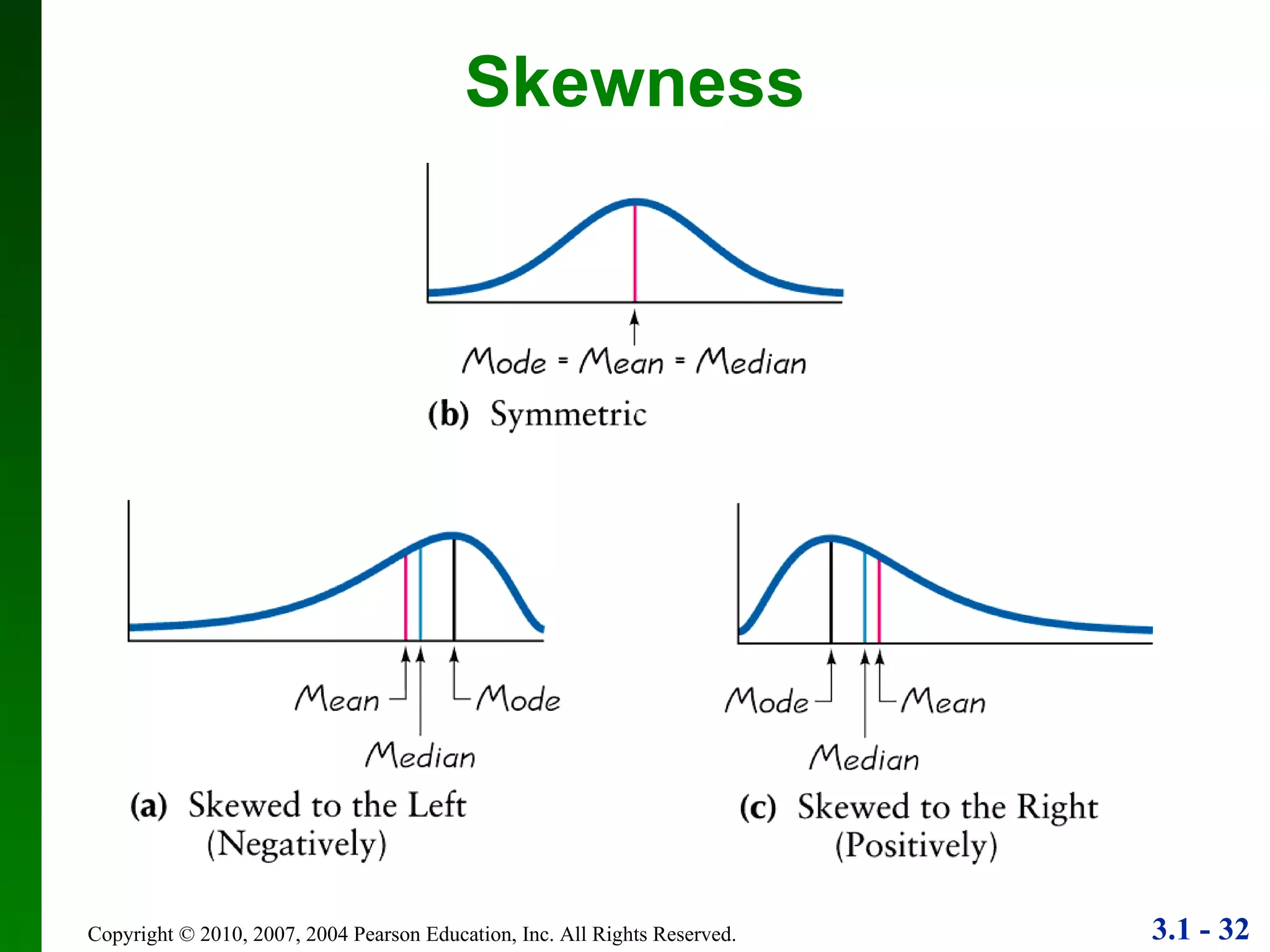
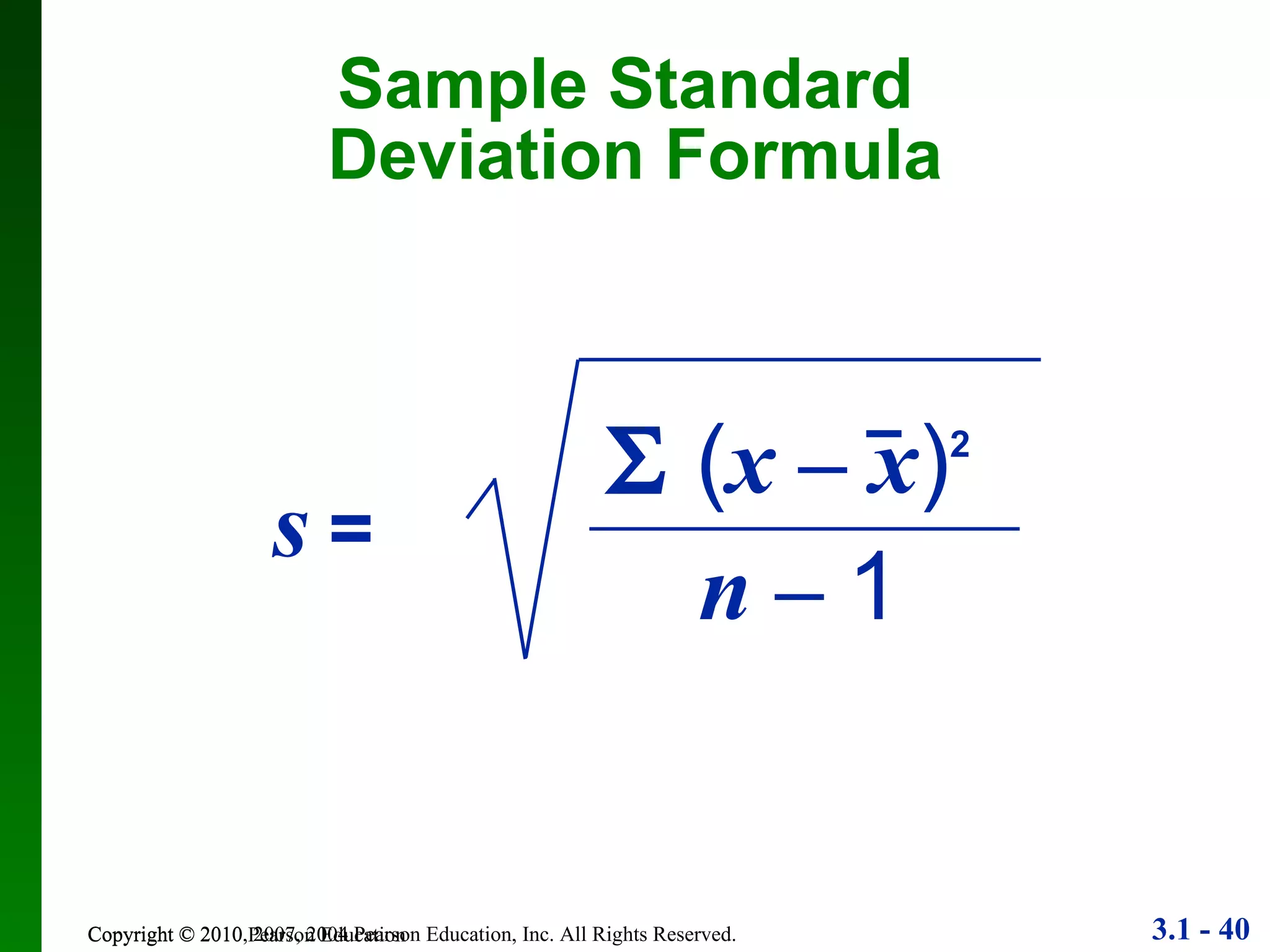
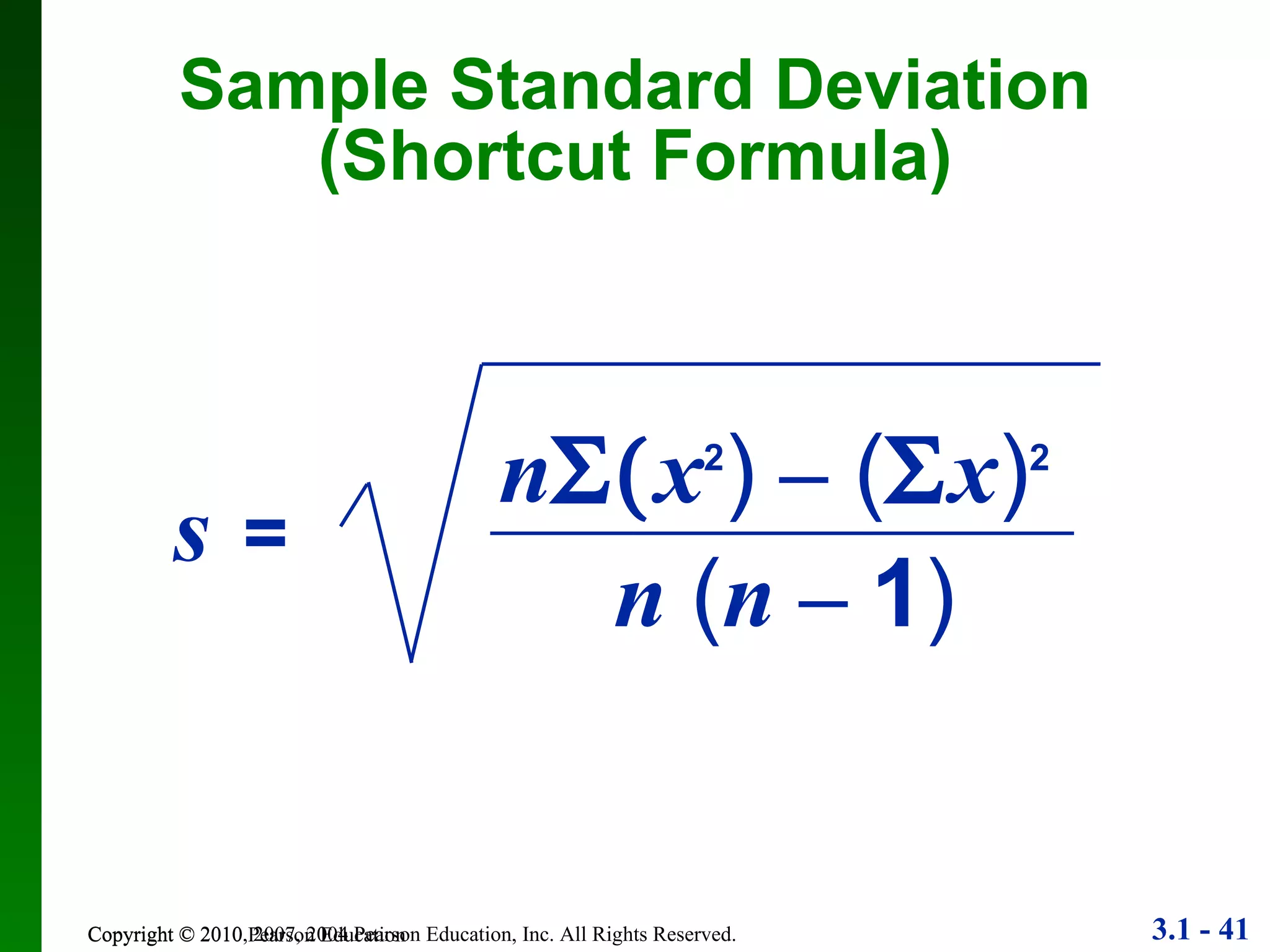
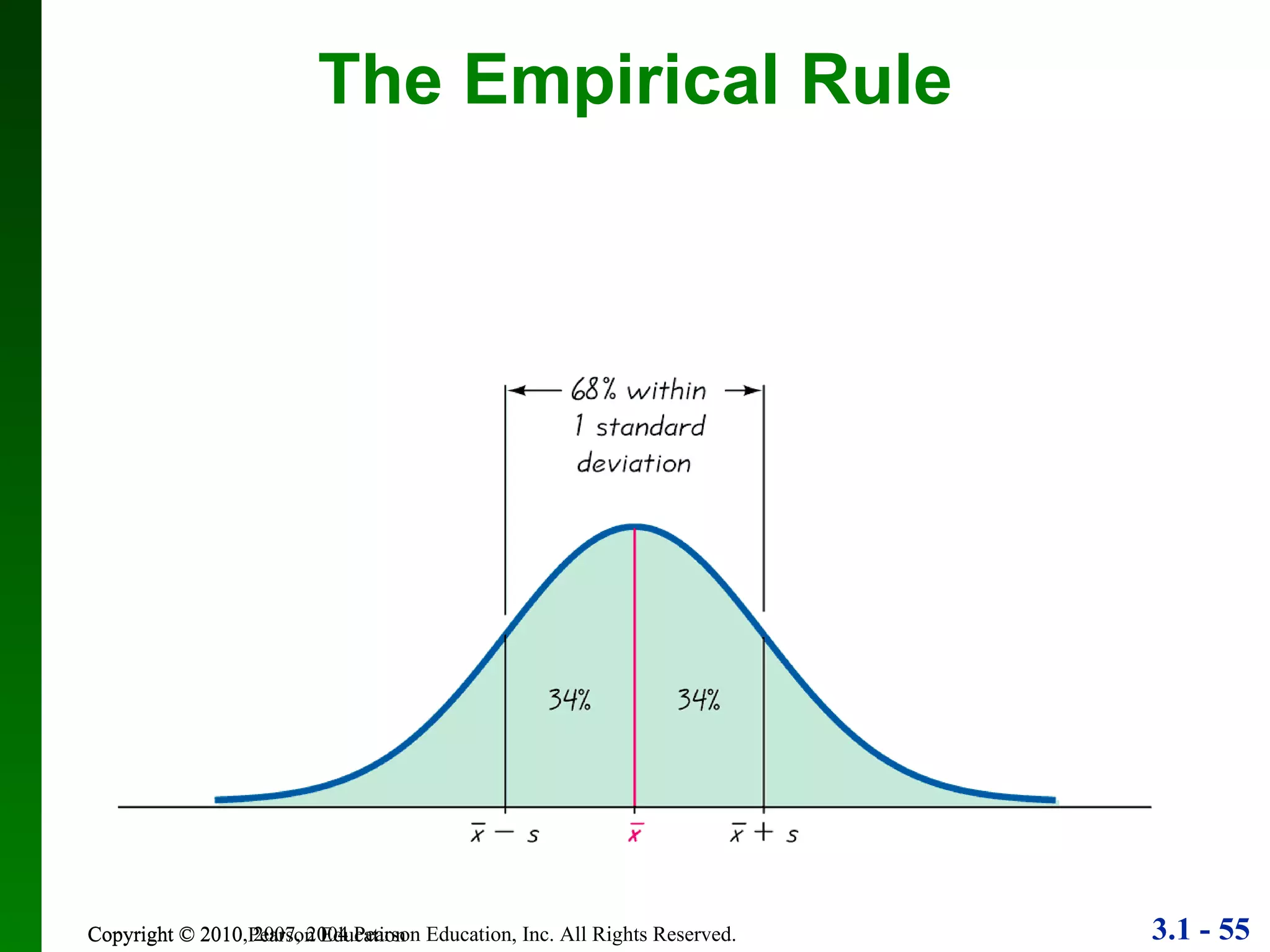
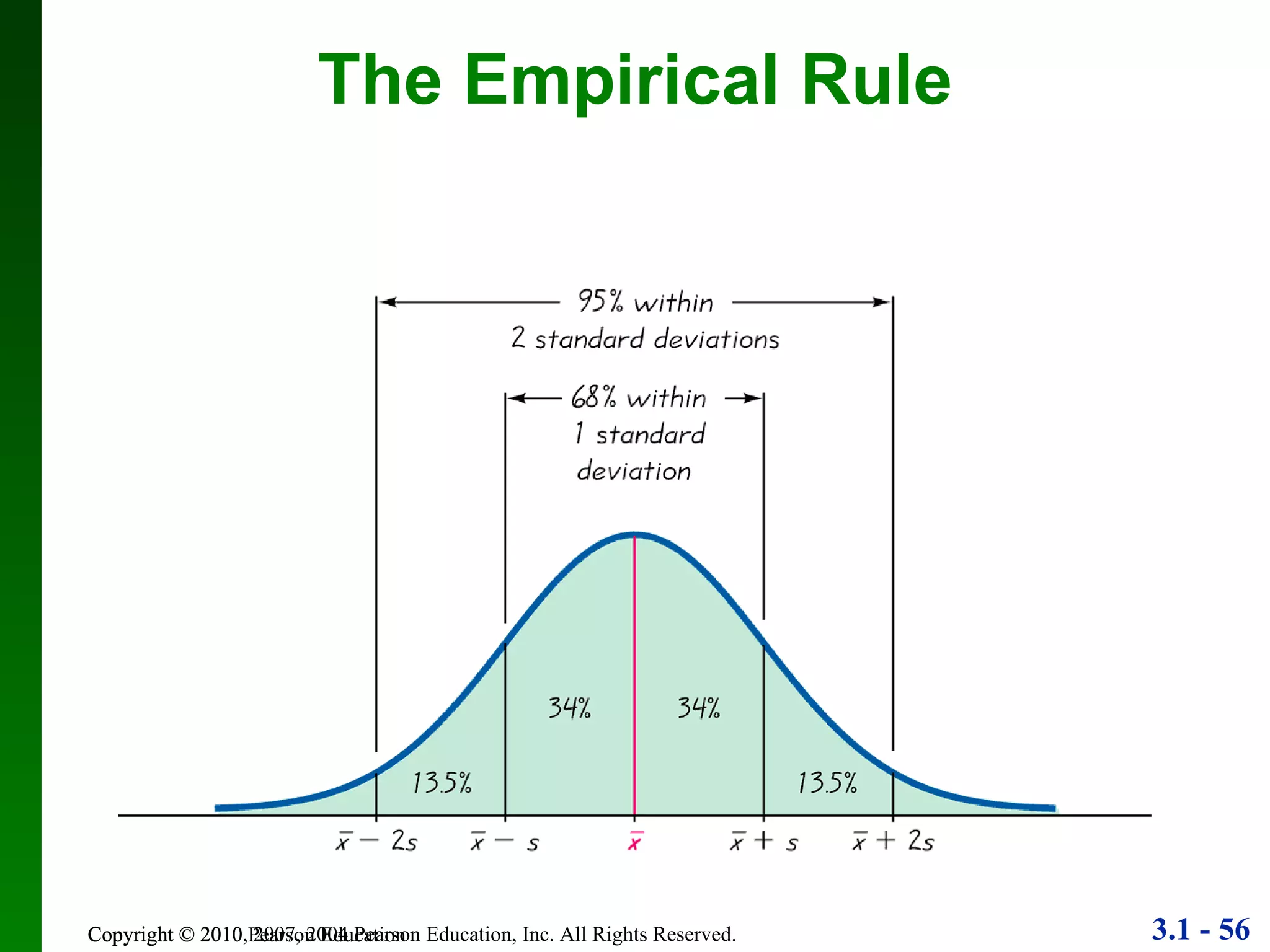
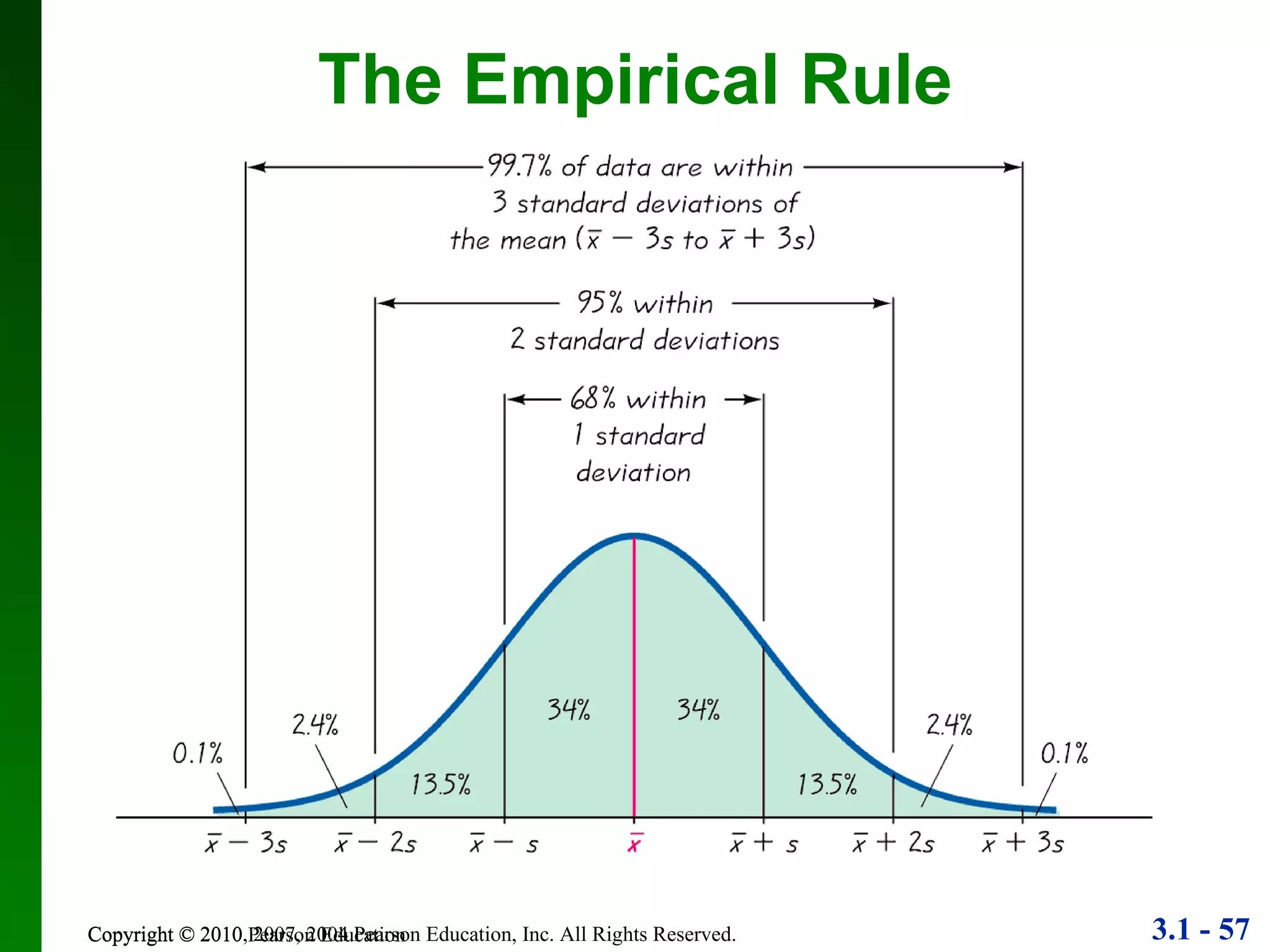
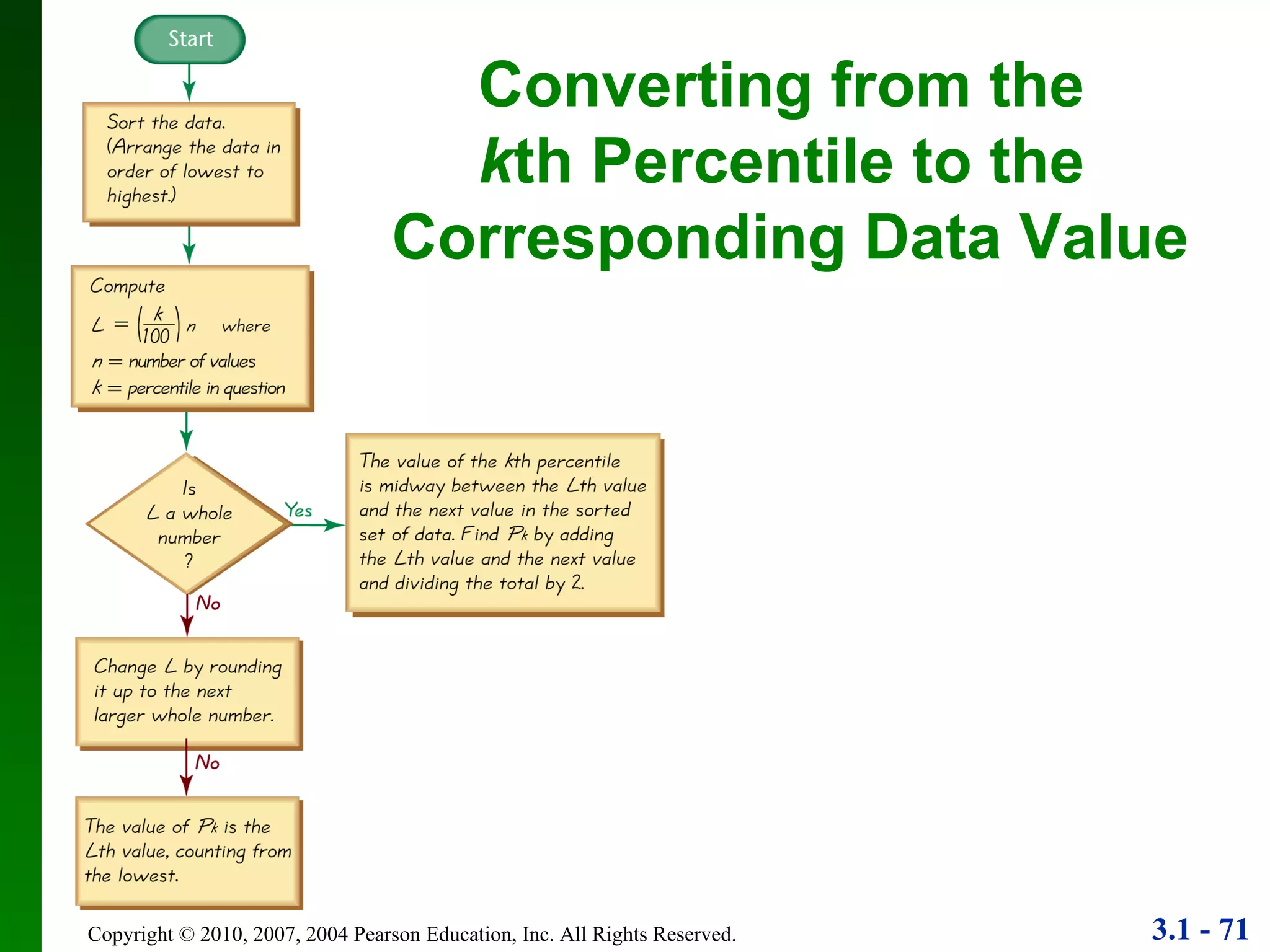
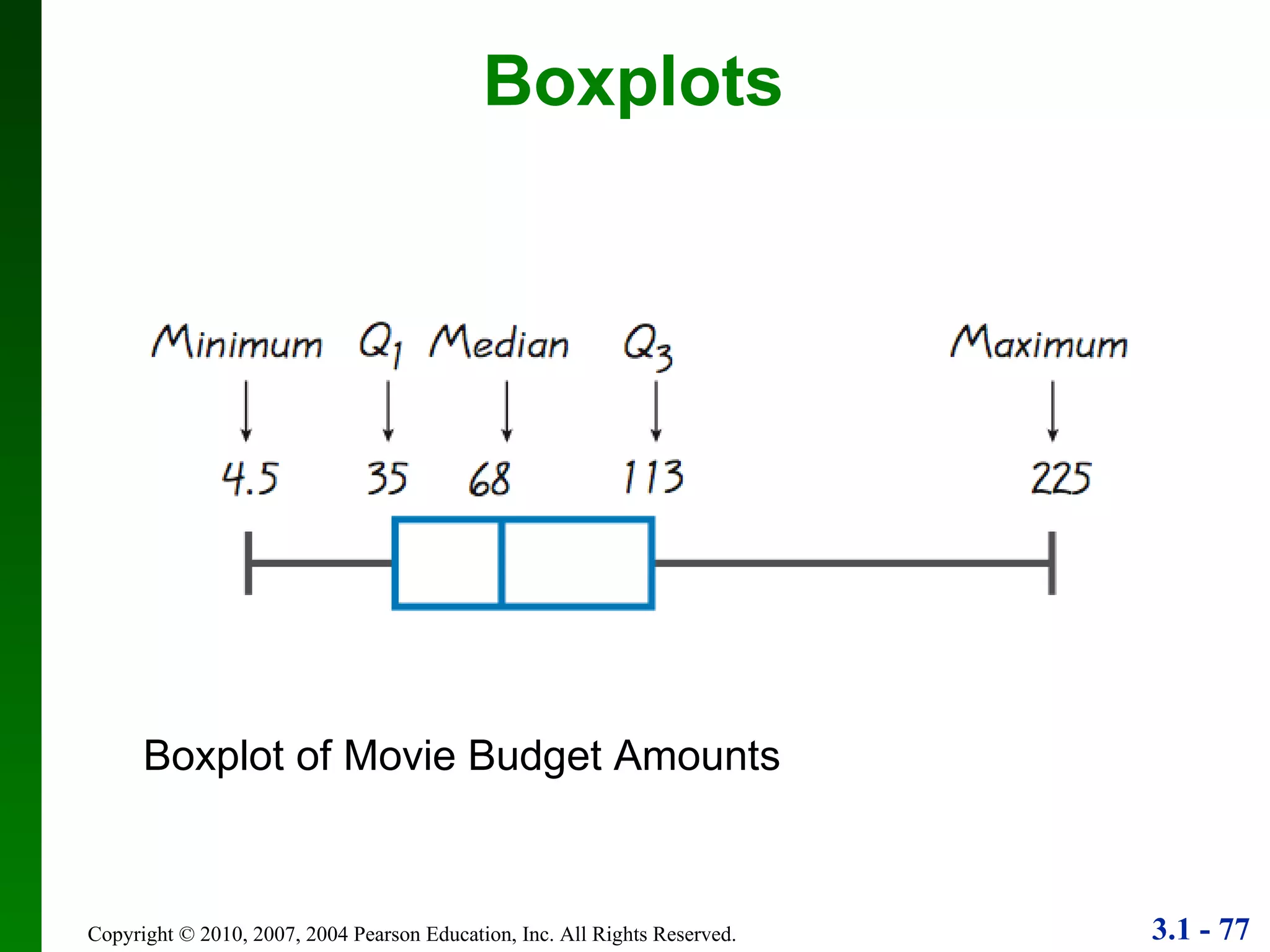
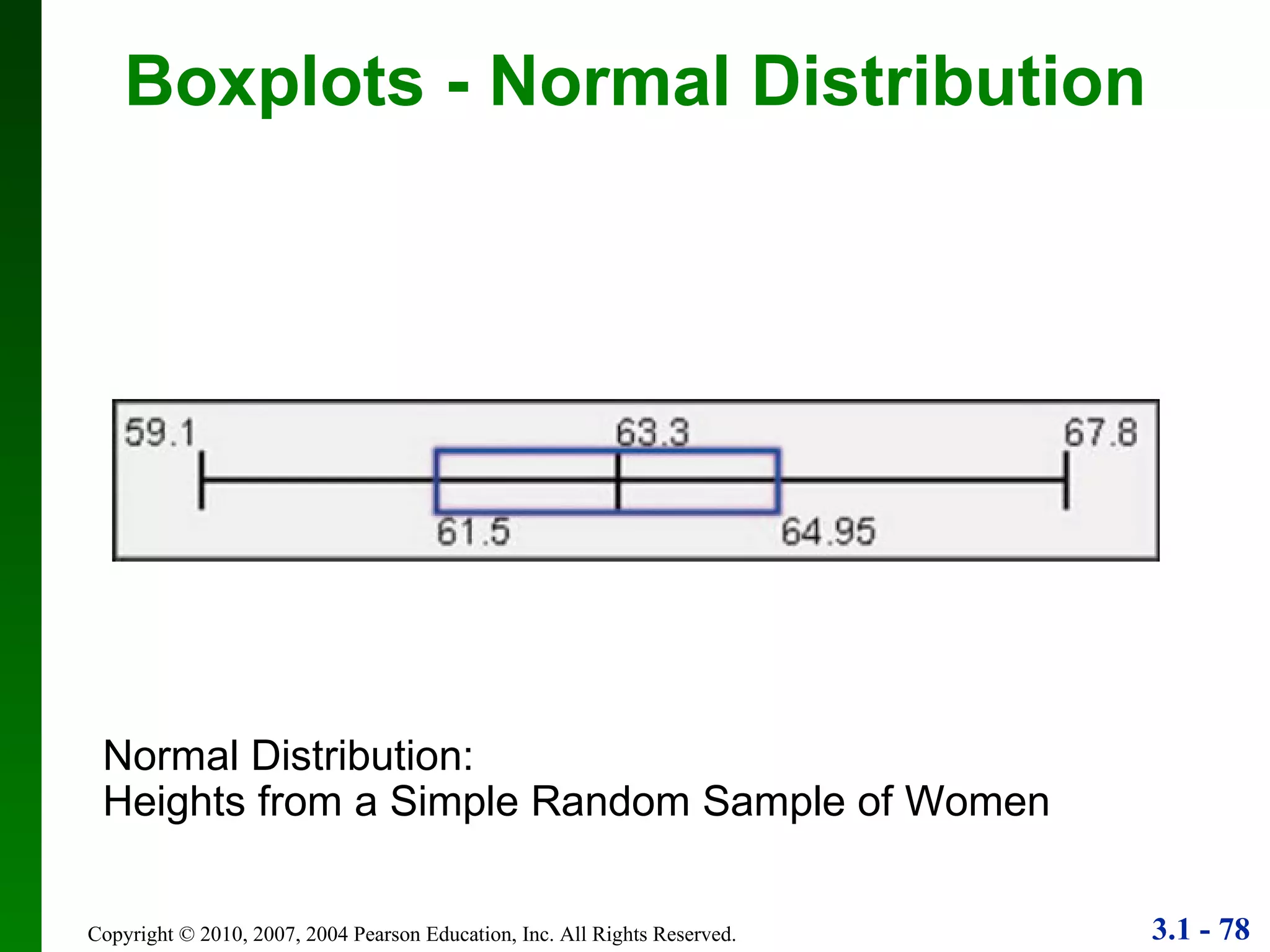
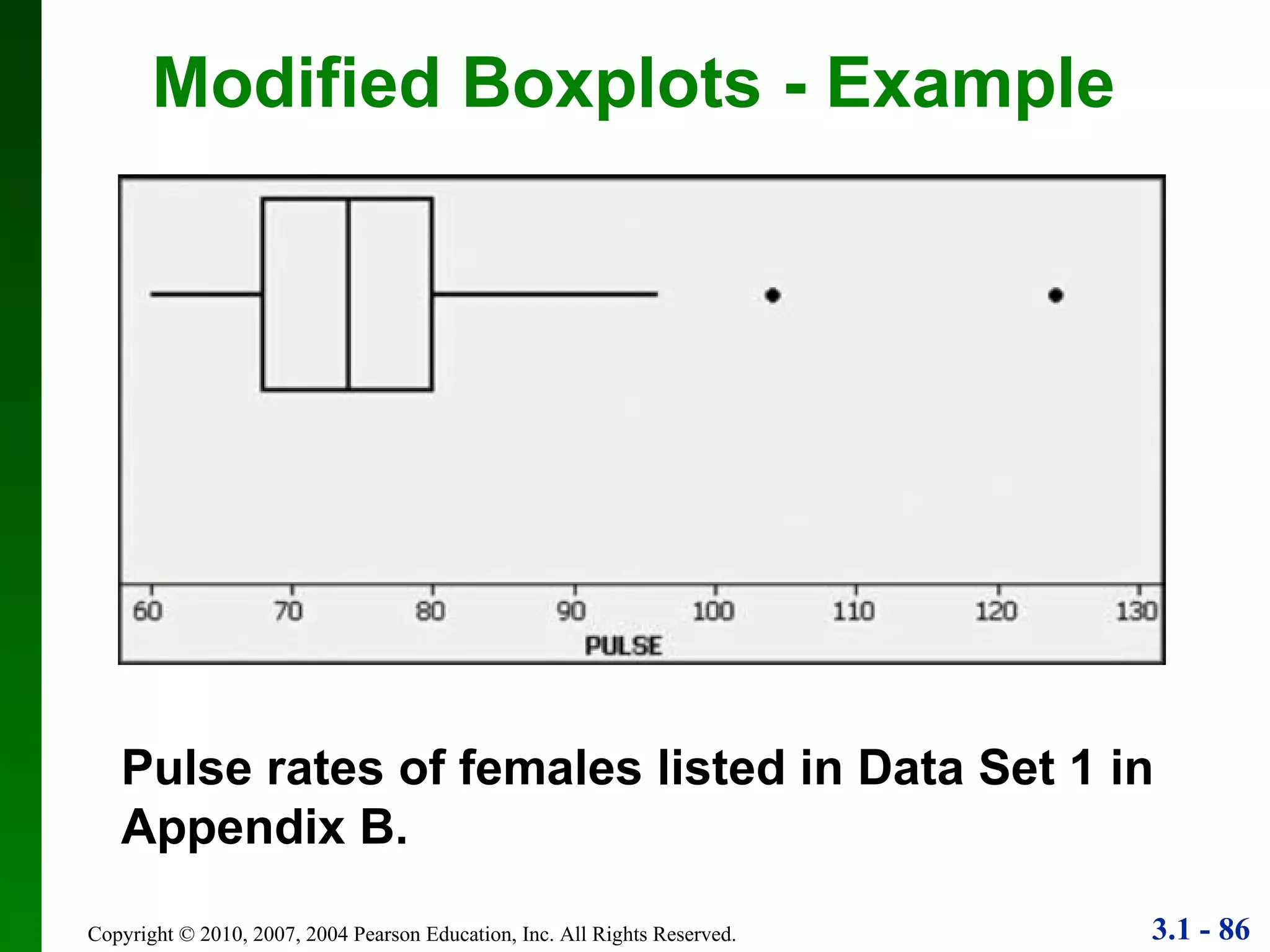
This document provides an overview of key concepts in descriptive statistics, including measures of center, variation, and relative standing. It discusses the mean, median, mode, range, standard deviation, z-scores, percentiles, quartiles, interquartile range, and boxplots. Formulas and properties of these statistical concepts are presented along with guidelines for interpreting and applying them to describe data distributions.