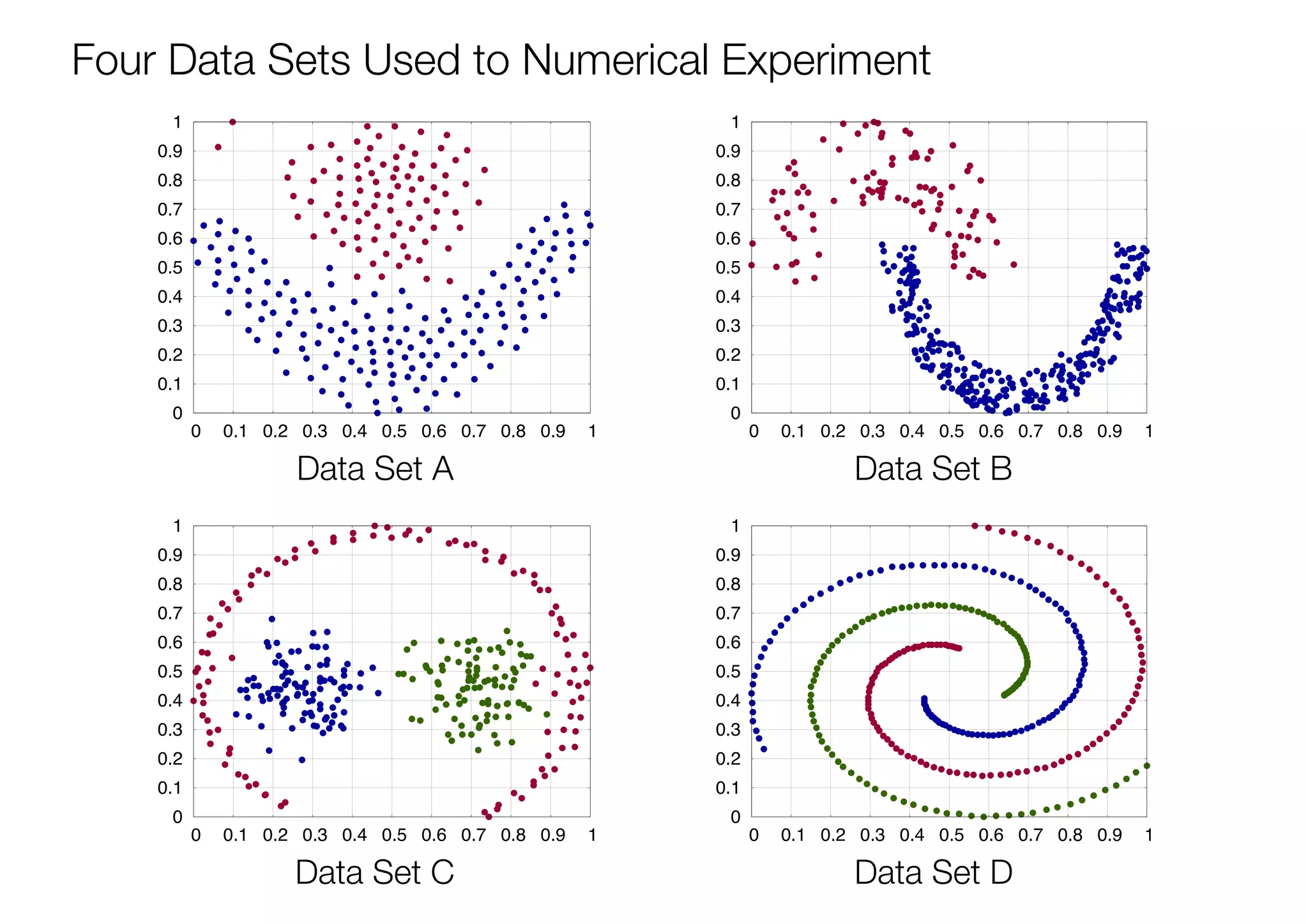
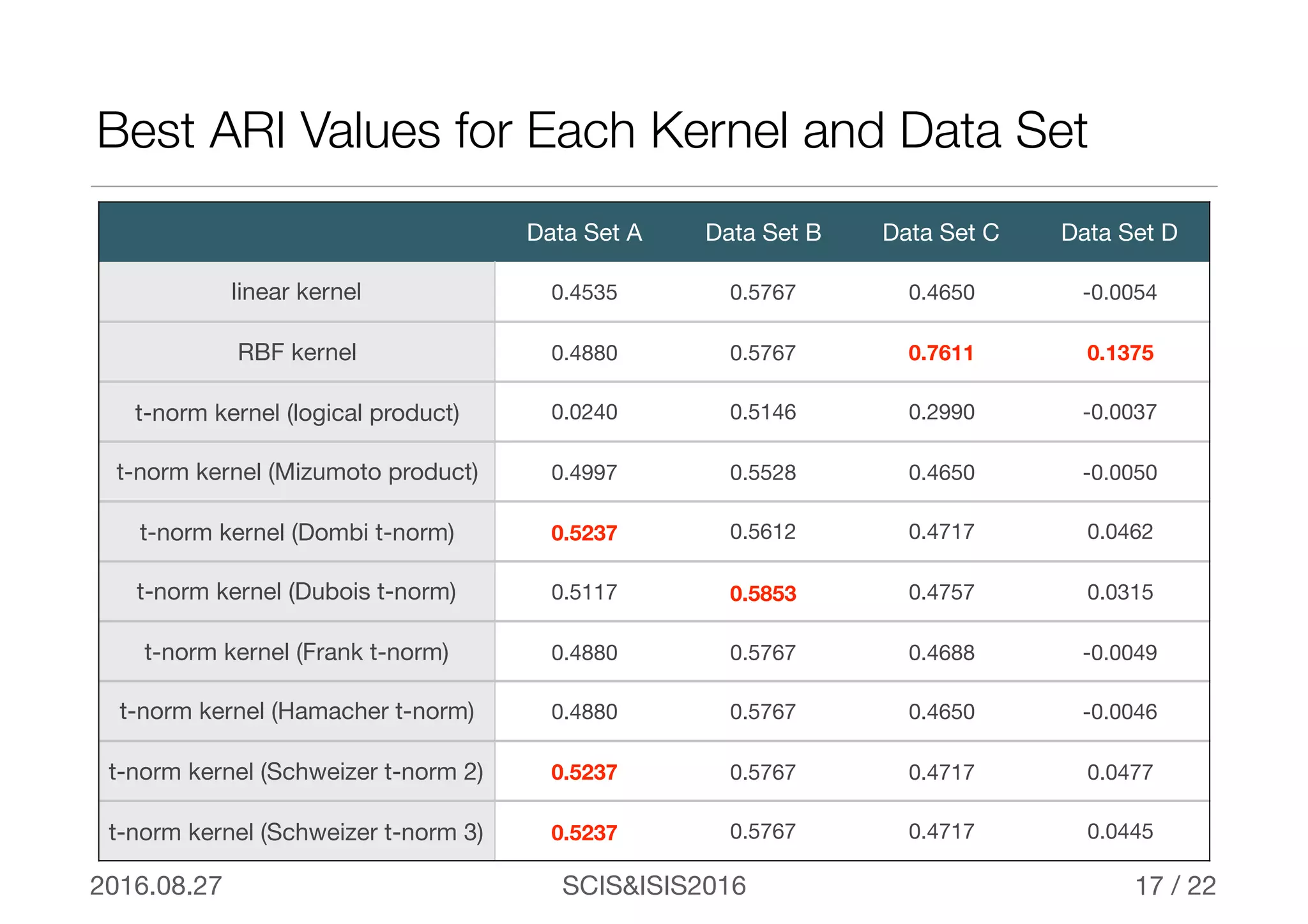
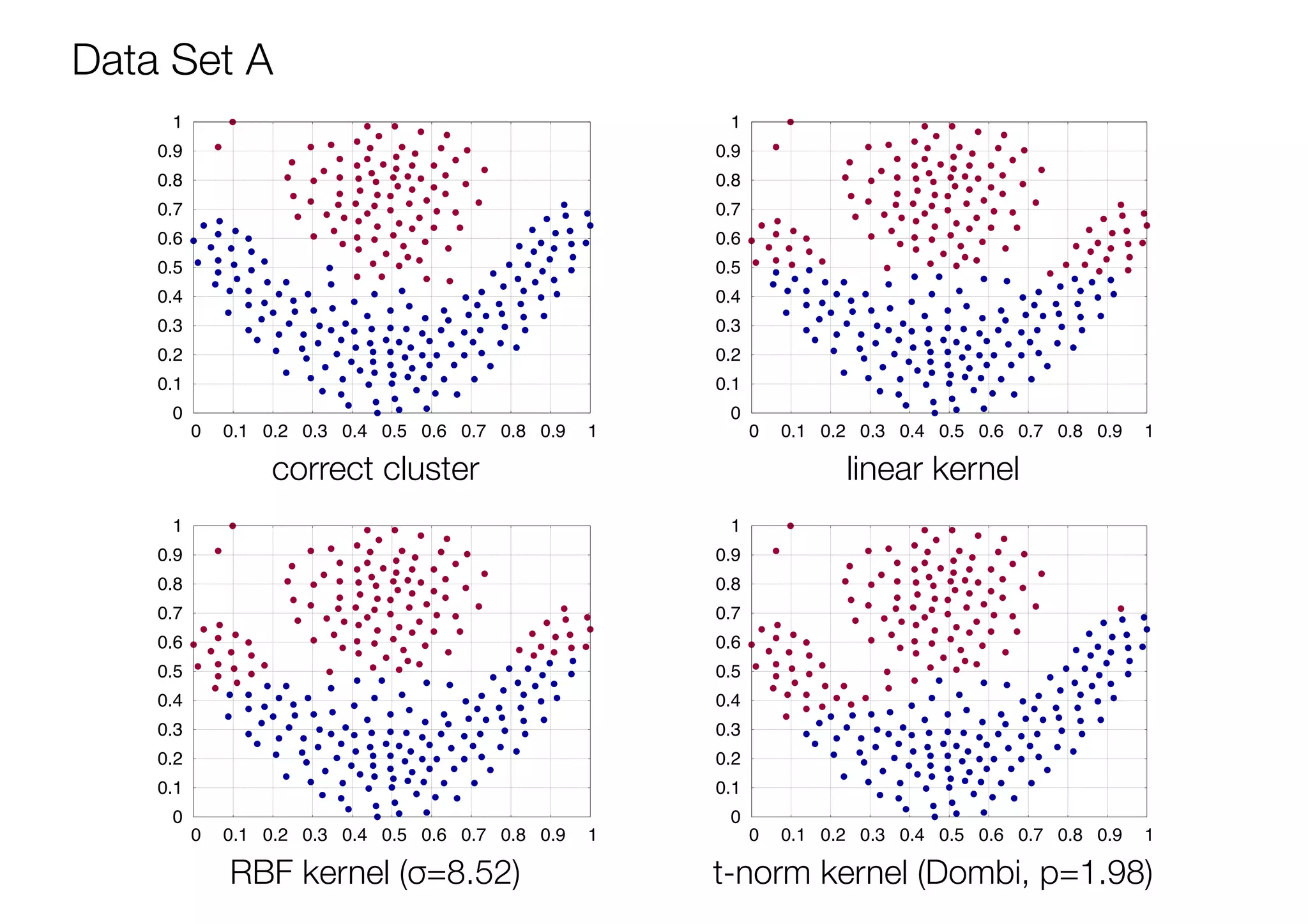
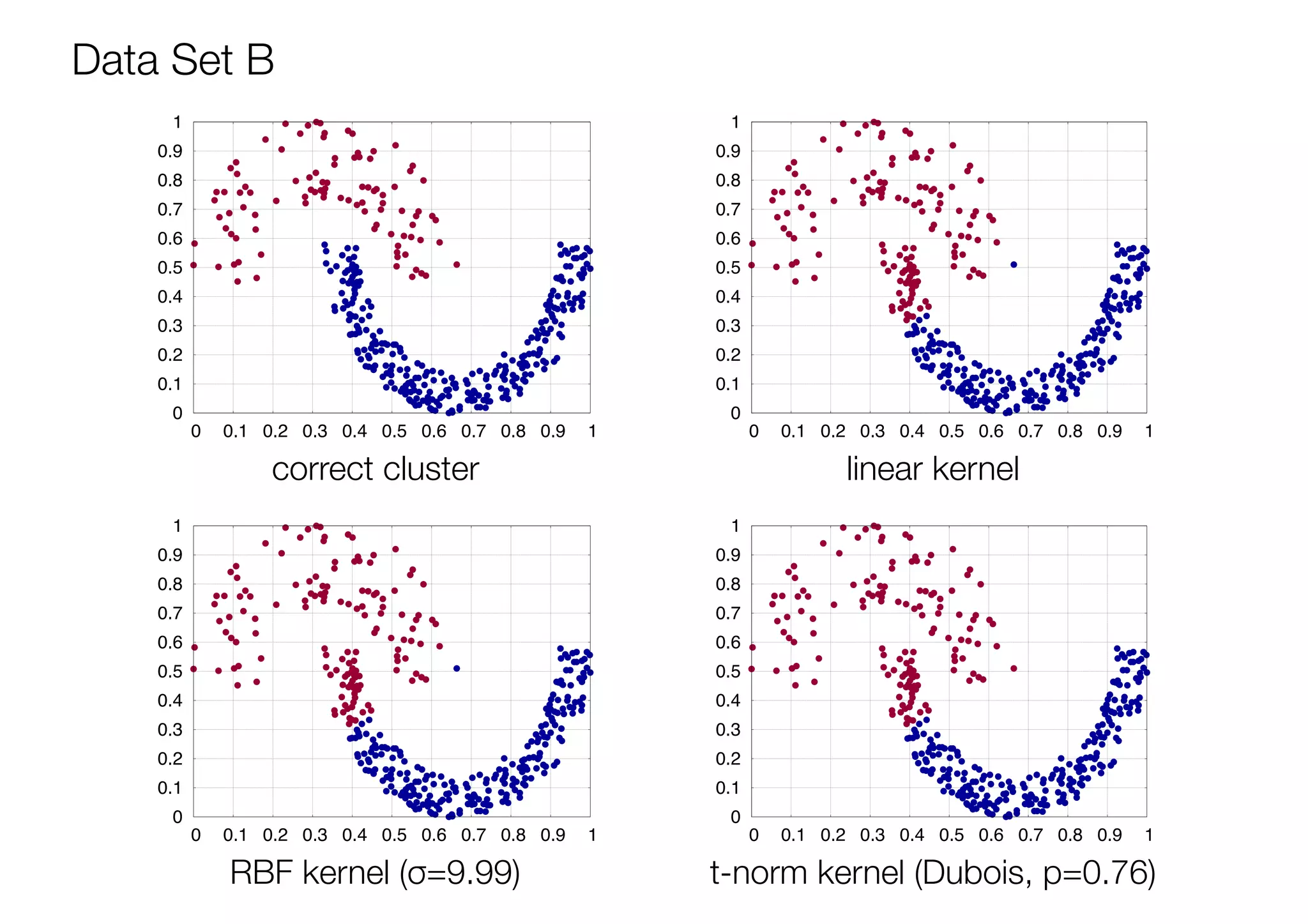
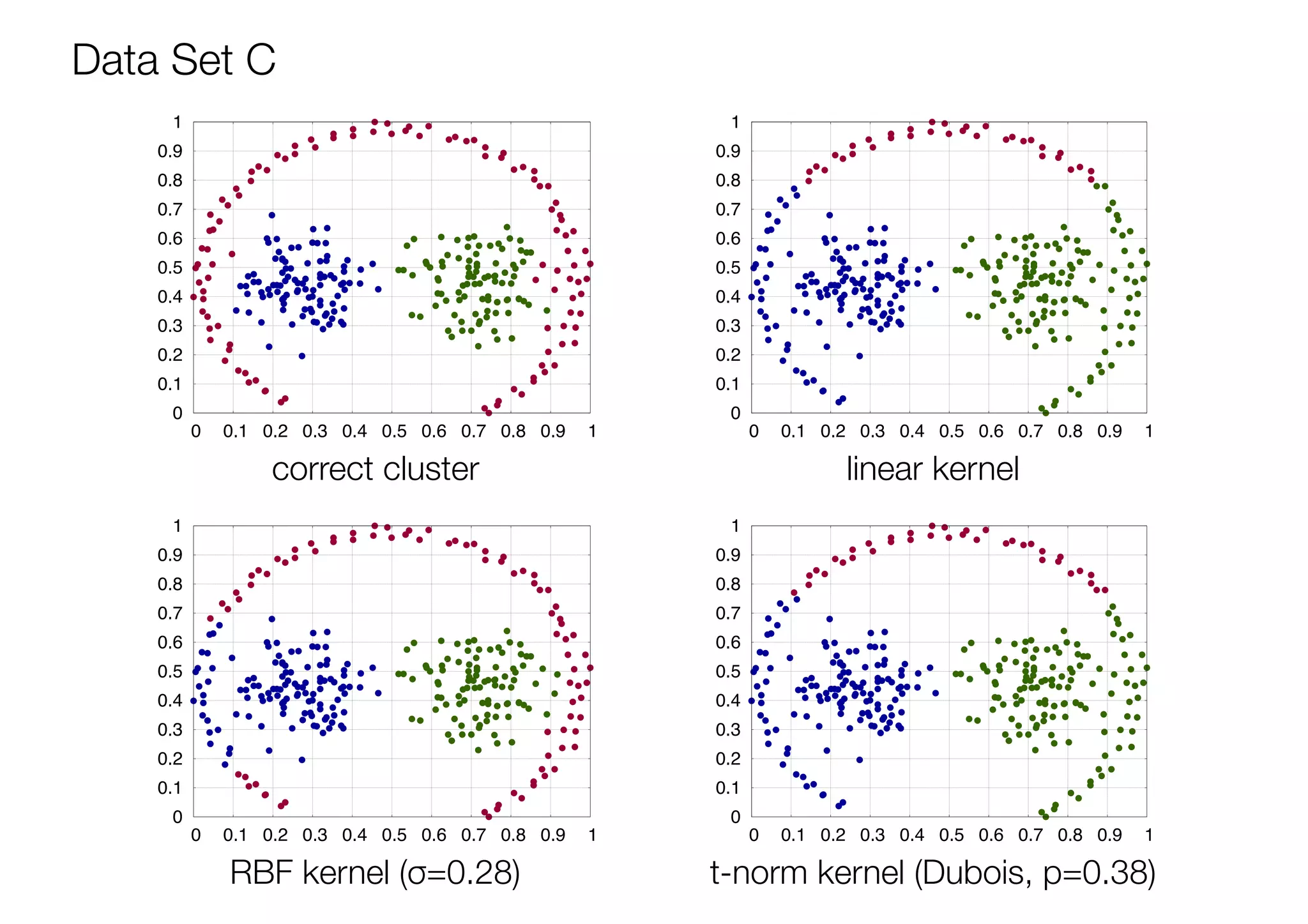
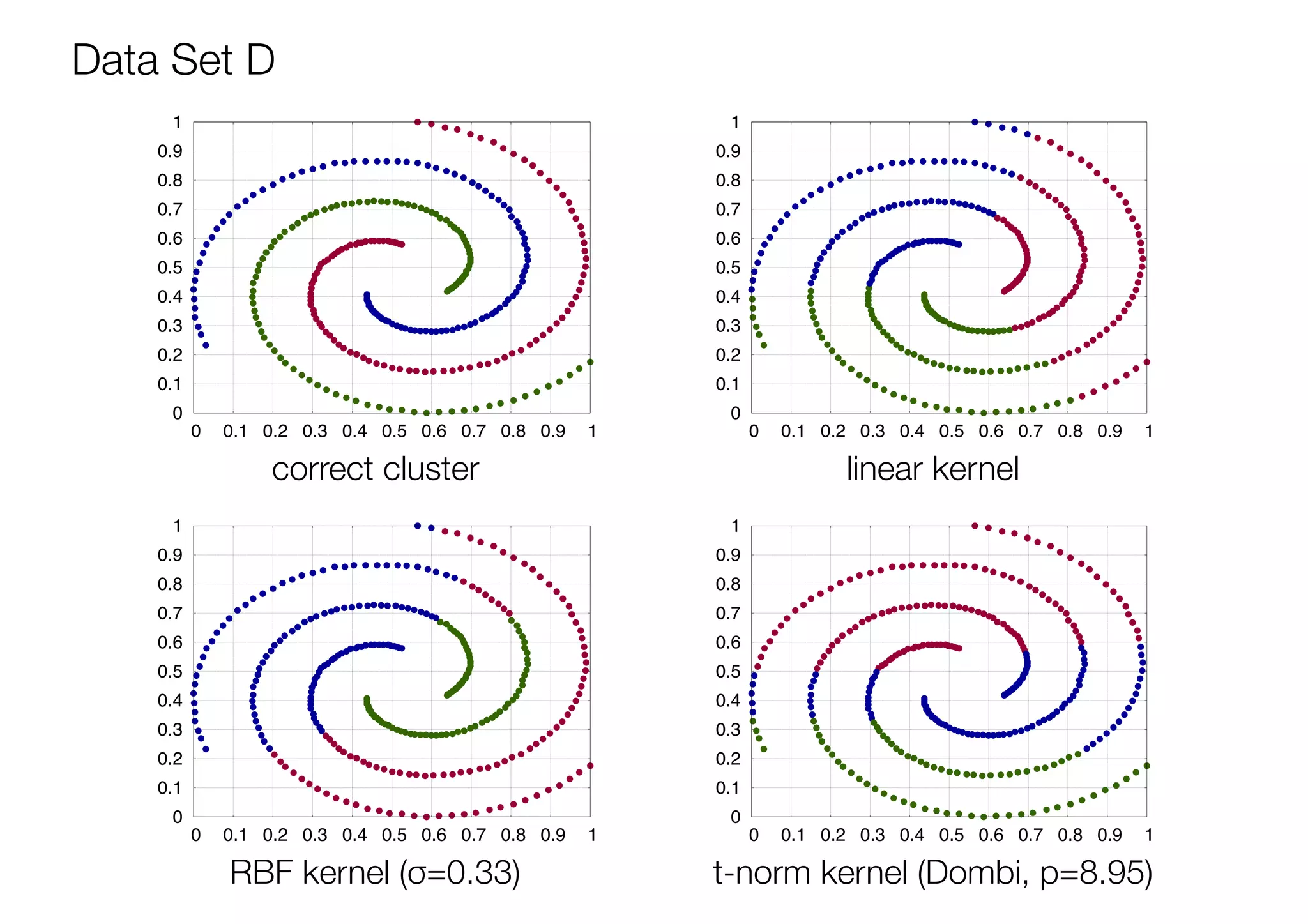
The document discusses triangular norm (t-norm) based kernel functions and their application to kernel k-means clustering. It introduces common kernel functions and describes how t-norms can be used to create new kernel functions. Several parameterized and non-parameterized t-norm based kernel functions are presented. The document then details experiments applying various kernel functions including t-norm kernels to four datasets, evaluating the results using adjusted rand index scores. The best performing kernels for each dataset are identified, with some t-norm kernels performing comparably or better than traditional kernels.





![SCIS&ISIS20162016.08.27 / 22
Triangular norm (t-norm)
6
A function is called t-norm if and only ifT
T(x, 1) = x
T(x, y) = T(y, x)
T(x, T(y, z)) = T(T(x, y), z)
T(x, y) T(x, z) y zif
1)
2)
3)
4)
T : [0, 1] ⇥ [0, 1] −! [0, 1] 8x, y, z 2 [0, 1]
According to fuzzy logic, t-norms represent intersection operations](https://image.slidesharecdn.com/presentationslideshare-161013105634/75/Families-of-Triangular-Norm-Based-Kernel-Function-and-Its-Application-to-Kernel-k-means-6-2048.jpg)
![SCIS&ISIS20162016.08.27 / 22
Example of t-norms
7
Hamacher t-norm
(p = 0.4)
0 0.2 0.4 0.6 0.8 1 0
0.2
0.4
0.6
0.8
1
0
0.2
0.4
0.6
0.8
1
x
y
Dubois t-norm
(p = 0.4)
0 0.2 0.4 0.6 0.8 1 0
0.2
0.4
0.6
0.8
1
0
0.2
0.4
0.6
0.8
1
x
y
Hamacher t-norm
Dubois t-norm Tdb(x, y) =
xy
max {x, y, p}
Th(x, y) =
xy
p + (1 − p)(x + y − xy)
p 2 [0, 1]
p 2 [0, 1]](https://image.slidesharecdn.com/presentationslideshare-161013105634/75/Families-of-Triangular-Norm-Based-Kernel-Function-and-Its-Application-to-Kernel-k-means-7-2048.jpg)
![SCIS&ISIS20162016.08.27 / 22
all principal minors of is
Is t-norm Positive Semi-Definite on [0, 1] ?
8
A =
0
B
B
B
@
T(x1, x1) T(x1, x2) · · · T(x1, xm)
T(x2, x1) T(x2, x2) · · · T(x2, xm)
...
...
...
...
T(xm, x1) T(xm, x2) · · · T(xm, xm)
1
C
C
C
A
Condition of positive semi-definite
A ≥ 0
8ci, cj 2 R 8m 2 N+
()A is positive semi-definite
mX
i=1
mX
j=1
cicjT(xi, xj)](https://image.slidesharecdn.com/presentationslideshare-161013105634/75/Families-of-Triangular-Norm-Based-Kernel-Function-and-Its-Application-to-Kernel-k-means-8-2048.jpg)
![SCIS&ISIS20162016.08.27 / 22
Is t-norm Positive Semi-Definite on [0, 1] ?
9
m = 2
✓
T(x1, x1) T(x1, x2)
T(x2, x1) T(x2, x2)
◆
|T(x1, x1)| ≥ 0
|T(x2, x2)| ≥ 0
T(x1, x1) T(x1, x2)
T(x2, x1) T(x2, x2)
m = 1
1X
i=1
1X
j=1
cicjT(xi, xi) = c2
i T(xi, xi) ≥ 0
all principal minors of are ≥ 0](https://image.slidesharecdn.com/presentationslideshare-161013105634/75/Families-of-Triangular-Norm-Based-Kernel-Function-and-Its-Application-to-Kernel-k-means-9-2048.jpg)
![SCIS&ISIS20162016.08.27 / 22
Is t-norm Positive Semi-Definite on [0, 1] ?
10
T(x1, x1) T(x1, x2)
T(x2, x1) T(x2, x2)
= T(x1, x1)T(x2, x2) − T2
(x1, x2)
T(x, y) ≥ Ta(x, y) = xy8x, y z · T(x, y) T(x, zy)=)
T(0, x2) = 0 < x1 < x2 = T(1, x2) x1 = T(w, x2)
T(x1, x2)
T(x2, x2)
T(w, T(x2, x2)) T(w, T(x1, x2))
T(x2, x2)
T(x1, x2)
≥
T(w, T(x2, x2))
T(w, T(x1, x2))
=
T(T(w, x2), x2)
T(T(w, x2), x1)
=
T(x1, x2)
T(x1, x1)](https://image.slidesharecdn.com/presentationslideshare-161013105634/75/Families-of-Triangular-Norm-Based-Kernel-Function-and-Its-Application-to-Kernel-k-means-10-2048.jpg)