独)産業技術総合研究所 情報技術研究部門
油井 誠
m.yui@aist.go.jp,@myui
Hivemall: Apache Hiveを用いたスケーラ
ブルな機械学習基盤
Hadoop Conference Japan 2014
English-version of this slide available on
bit.ly/hivemall-slide
1 / 42
2.
発表の構成
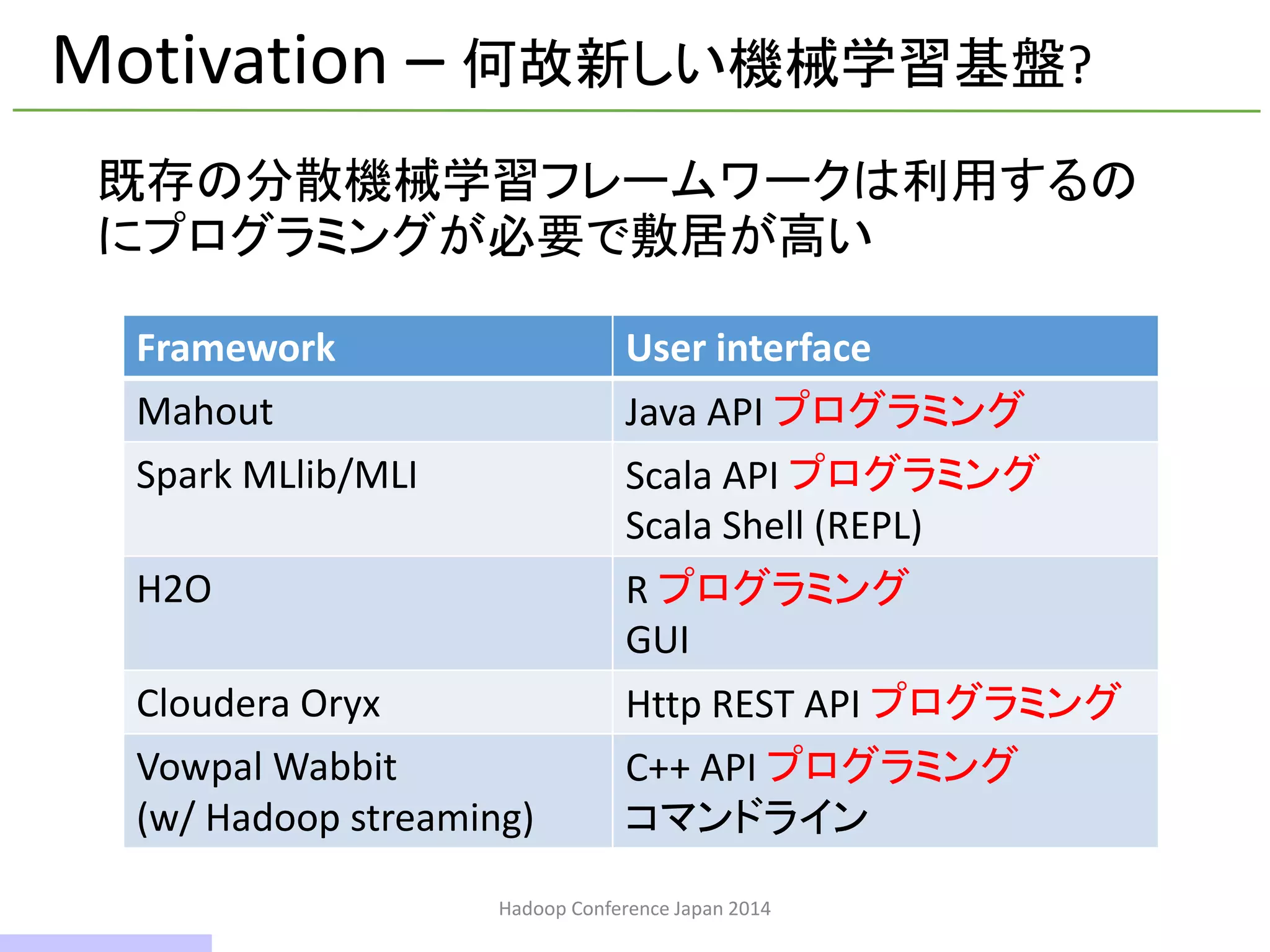
• What isHivemall
• Why Hivemall
• What Hivemall can do
• How to use Hivemall
• How Hivemall works
• イテレーションへの対処方法(Sparkと比較)
• 性能評価
• まとめ
Hadoop Conference Japan 2014
基本的にHadoop Summit 2014, San Jose
で喋った内容を踏襲しております
2 / 42
3.
What is Hivemall
•Hiveのユーザ定義関数またはユーザ定義テーブル
生成関数として実装された機械学習ライブラリ
• クラス分類と回帰分析
• 推薦
• K近傍探索
.. and more
• オープンソースプロジェクト
• LGPLライセンス
• github.com/myui/hivemall (bit.ly/hivemall)
• コントリビュータは現在4人
Hadoop Conference Japan 2014
3 / 42
Hadoop Conference Japan2014
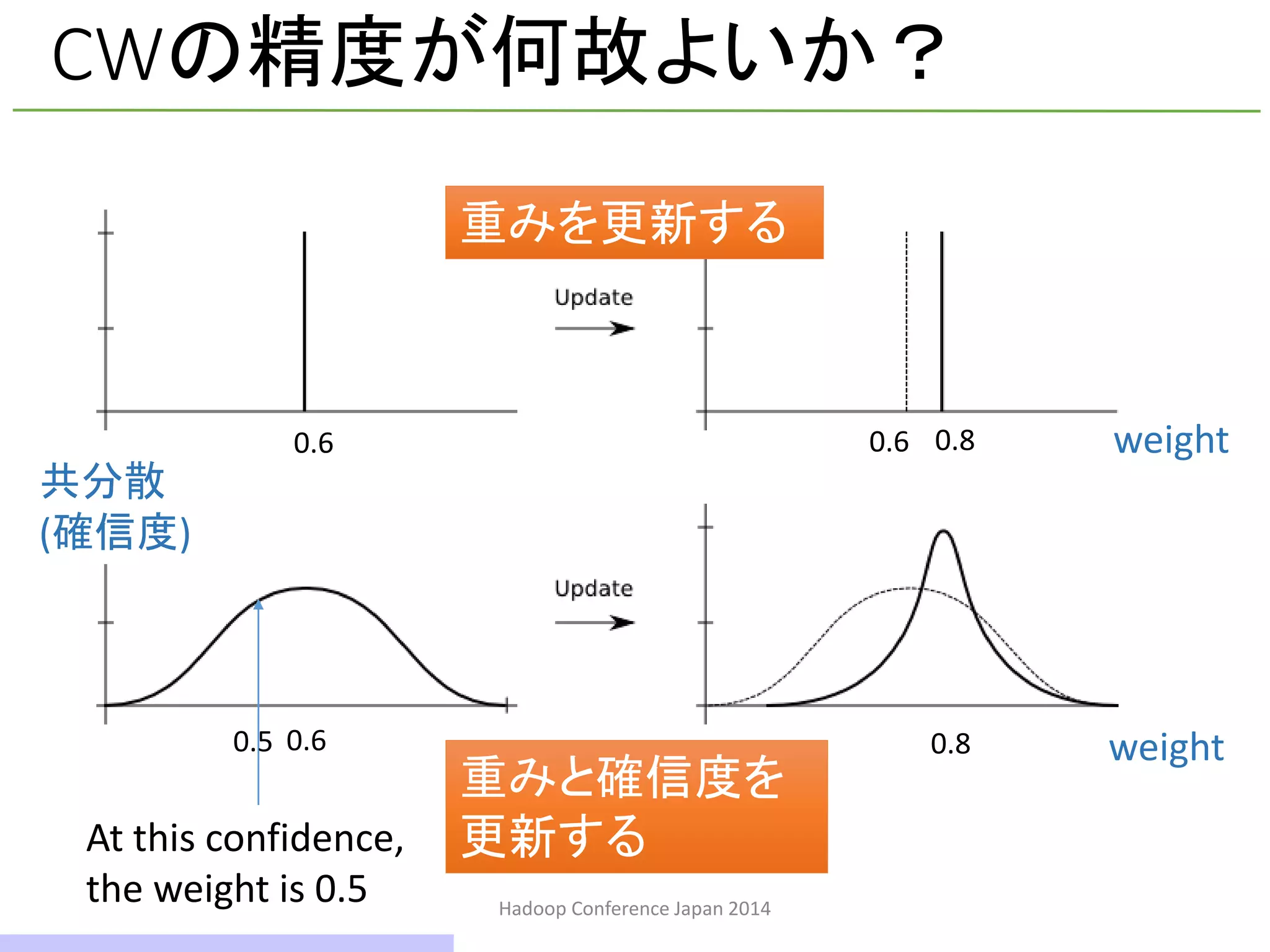
CWの精度が何故よいか?
文章をpositiveかnegativeかに分類する二値分類
を想定してみる
→ 単語(特徴)ごとに重みを計算する
I like this authorPositive
I like this author, but found this book dullNegative
Label Feature Vector(特徴ベクトル)
ナイーブな学習手法では重み を同様に更新するWlike Wdull
CWでは重みごとに異なる更新を行う
14 / 42
15.
Hadoop Conference Japan2014
CWの精度が何故よいか?
weight
weight
重みを更新する
重みと確信度を
更新する
0.6 0.80.6
0.80.6
At this confidence,
the weight is 0.5
共分散
(確信度)
0.5
15 / 42
発表の構成
• What isHivemall
• Why Hivemall
• What Hivemall can do
• How to use Hivemall
• How Hivemall works
• イテレーションへの対処方法(Sparkと比較)
• 性能評価
• まとめ
Hadoop Conference Japan 2014
17 / 42
Hadoop Conference Japan2014
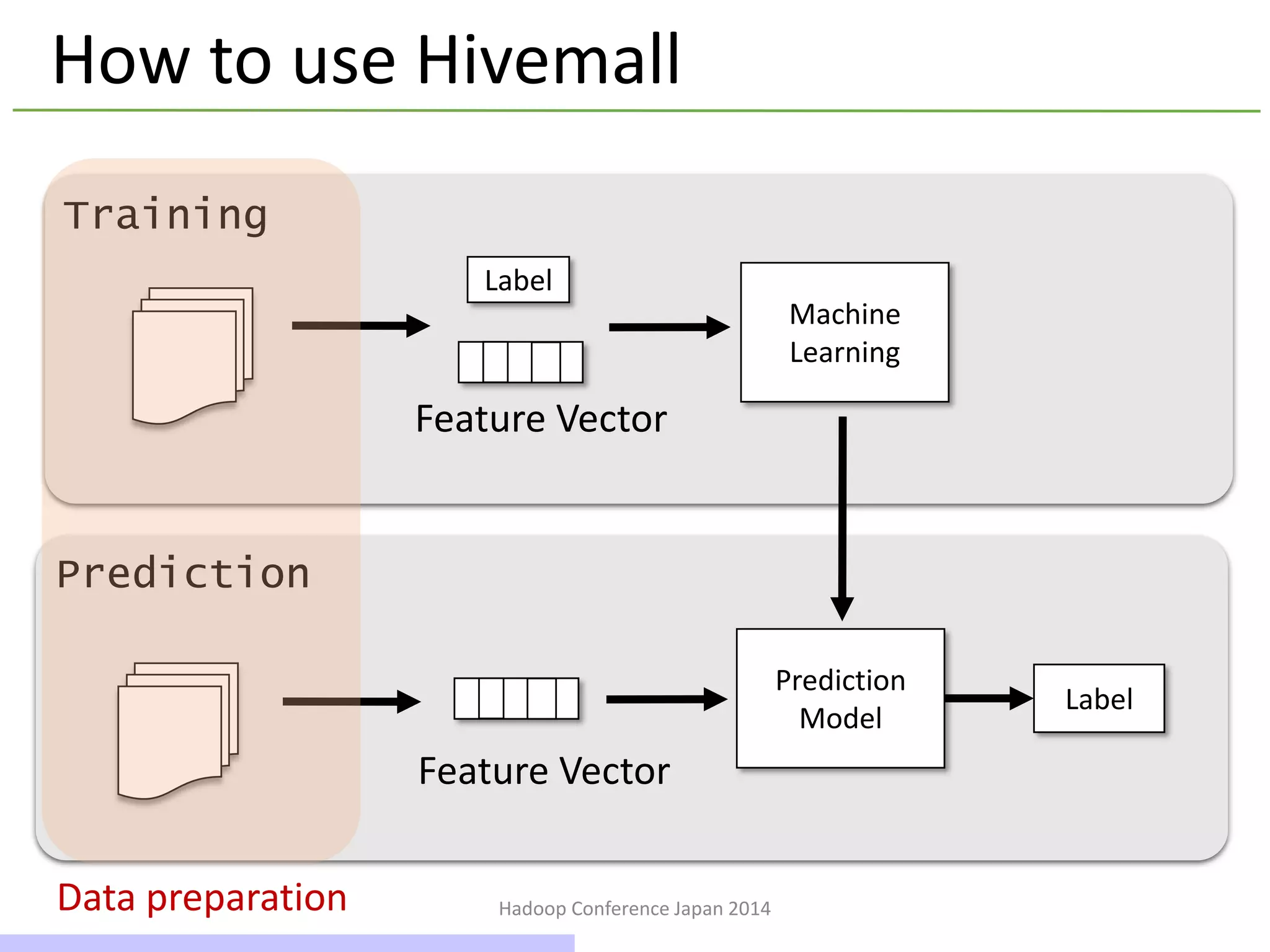
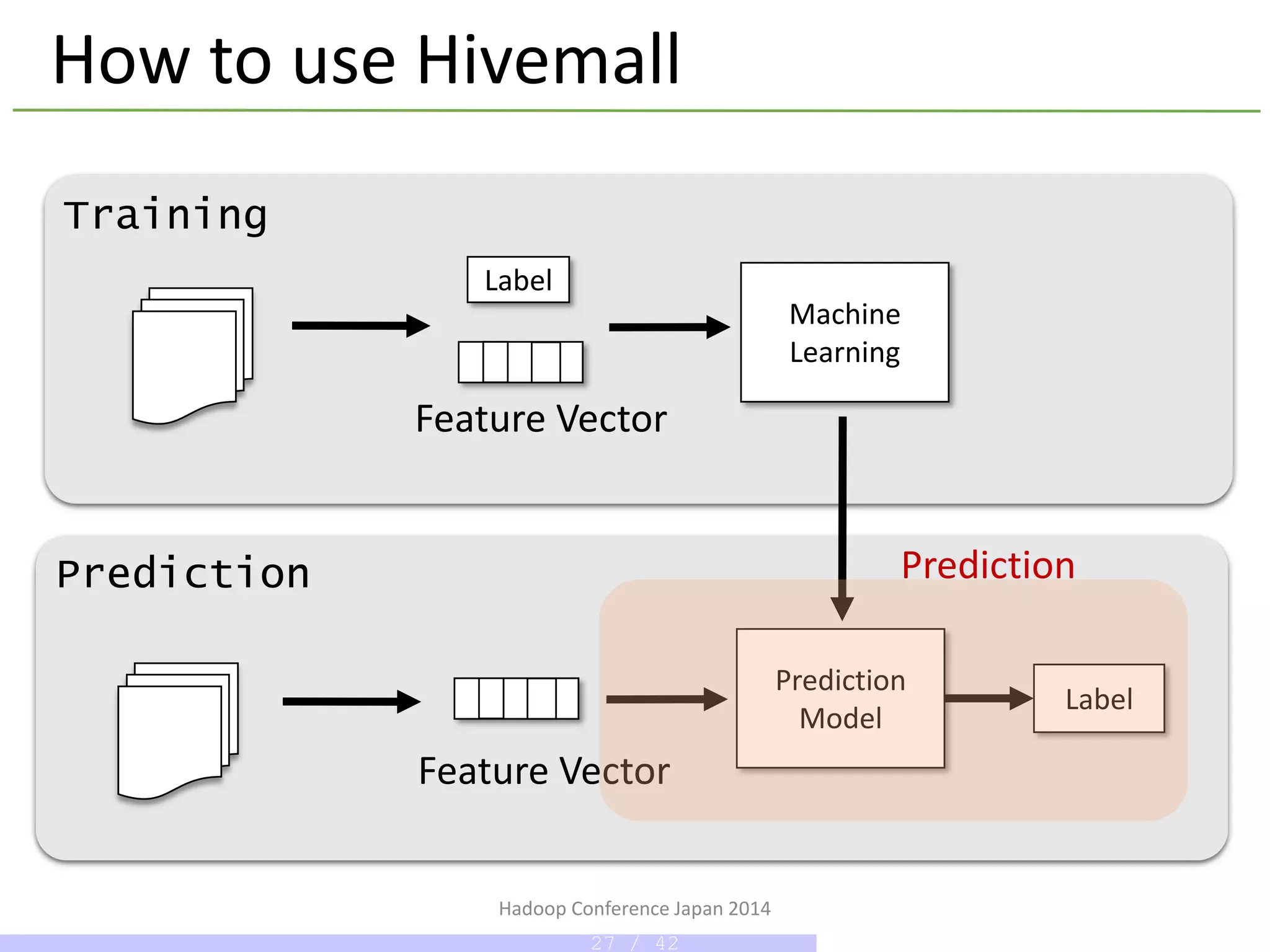
How to use Hivemall
Machine
Learning
Training
Prediction
Prediction
Model
Label
Feature Vector
Feature Vector
Label
Data preparation
19 / 42
20.
Hadoop Conference Japan2014
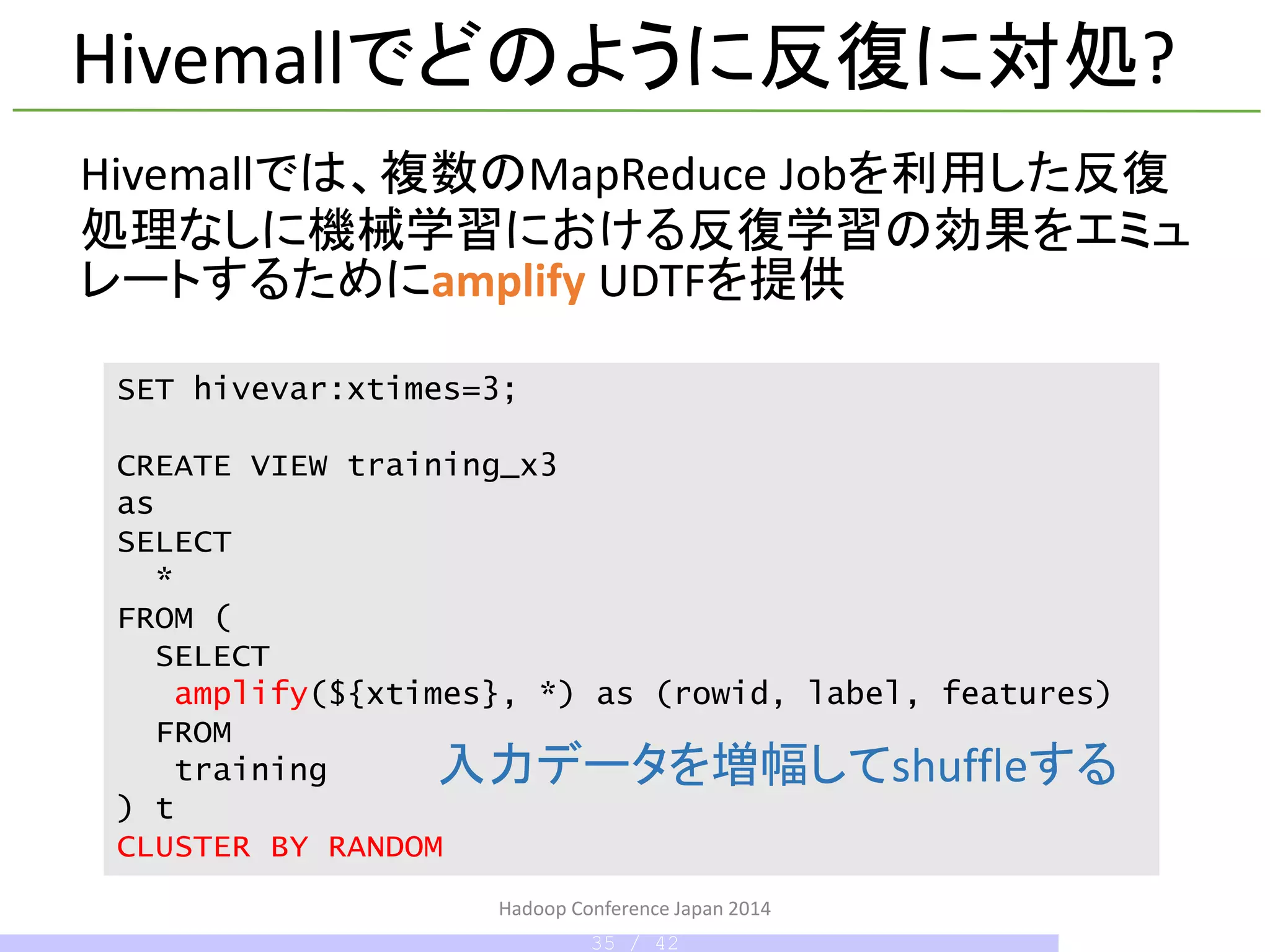
Create external table e2006tfidf_train (
rowid int,
label float,
features ARRAY<STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '¥t'
COLLECTION ITEMS TERMINATED BY ",“
STORED AS TEXTFILE LOCATION '/dataset/E2006-
tfidf/train';
How to use Hivemall – データの準備
訓練とテストデータ用のテーブルを定義
HDFSに置いた(HiveのSERDEでパース可能な)任意フォー
マットのデータを利用可能
20 / 42
21.
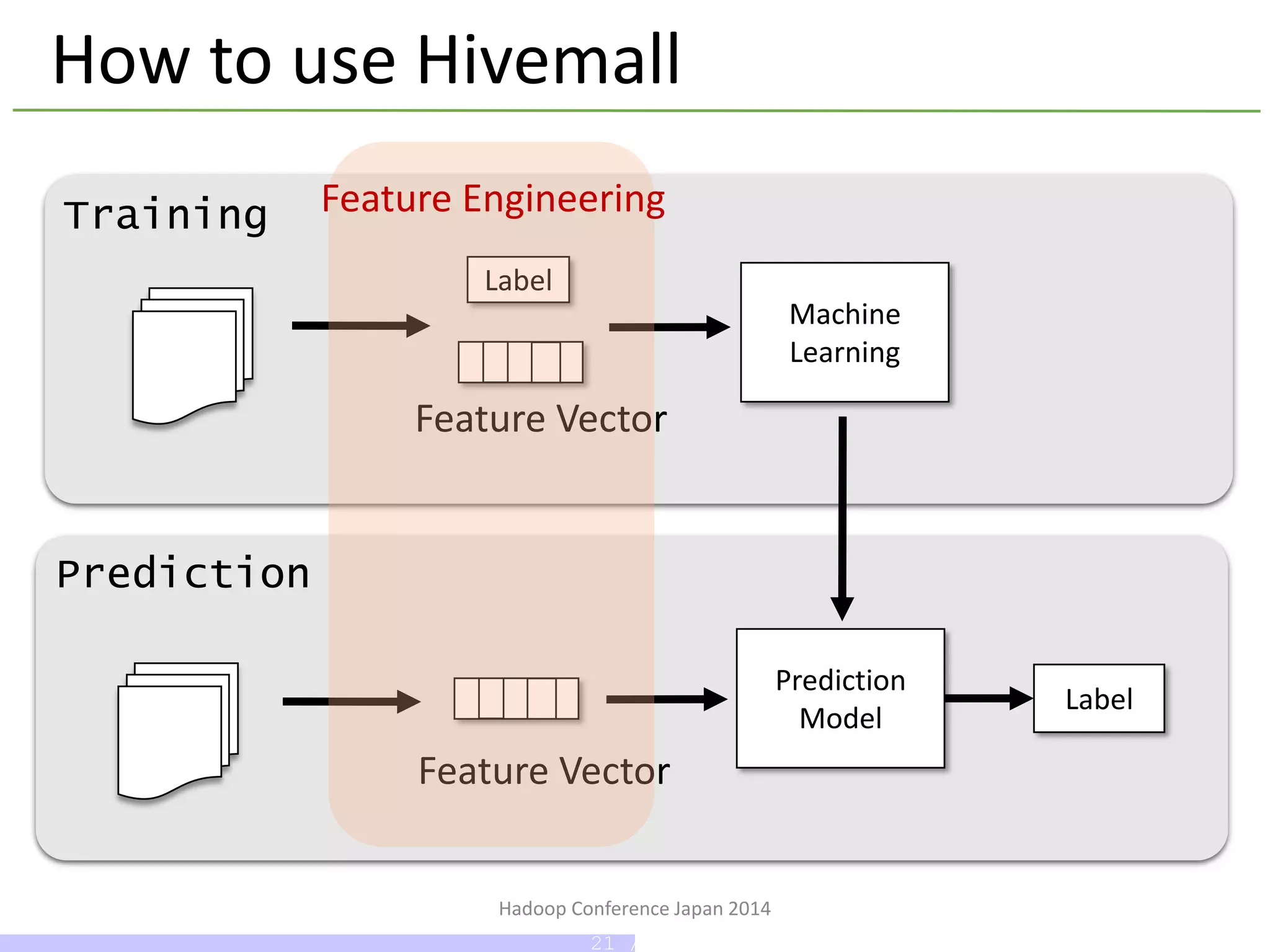
Hadoop Conference Japan2014
How to use Hivemall
Machine
Learning
Training
Prediction
Prediction
Model
Label
Feature Vector
Feature Vector
Label
Feature Engineering
21 / 42
22.
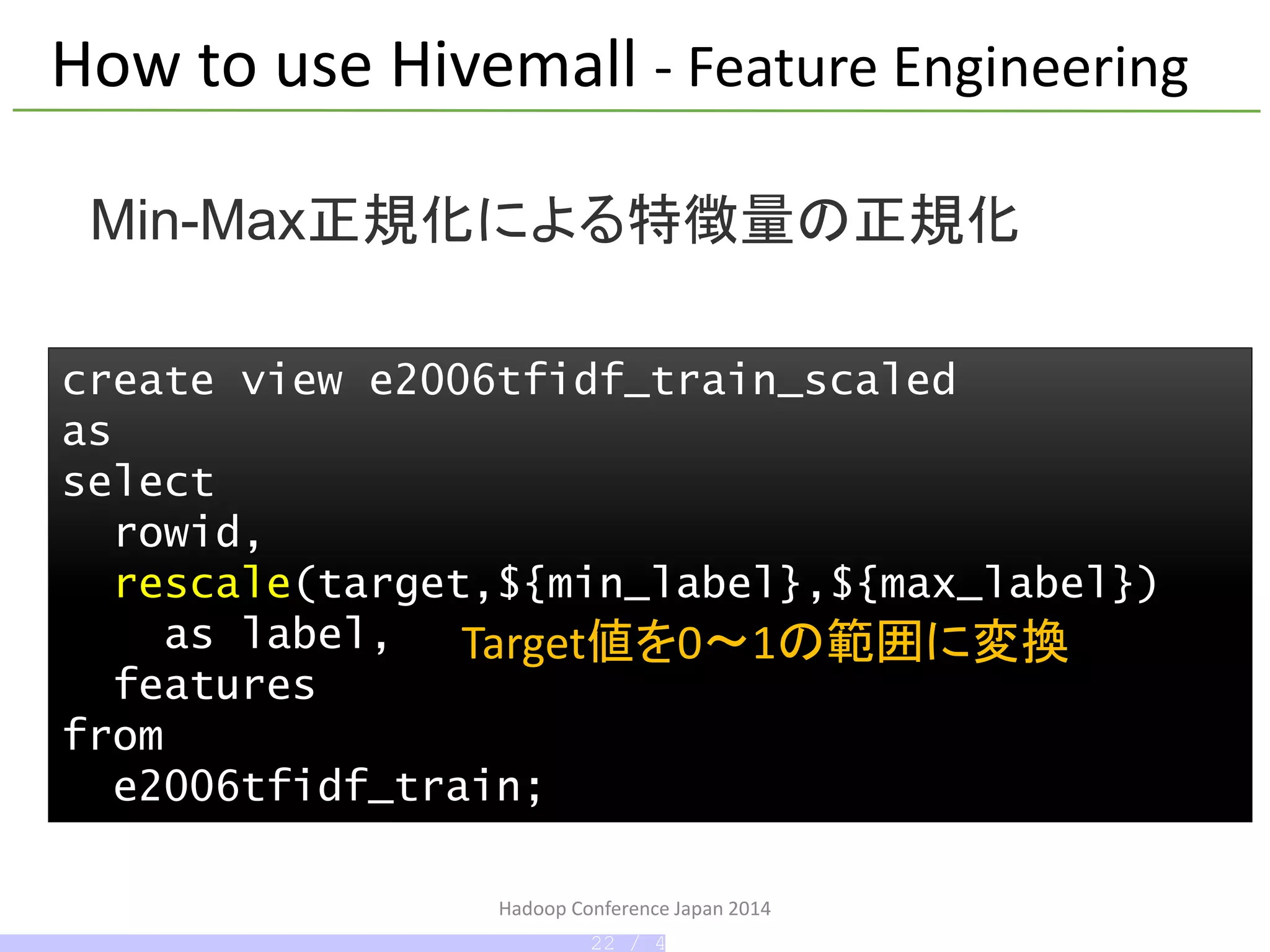
Hadoop Conference Japan2014
create view e2006tfidf_train_scaled
as
select
rowid,
rescale(target,${min_label},${max_label})
as label,
features
from
e2006tfidf_train;
Min-Max正規化による特徴量の正規化
How to use Hivemall - Feature Engineering
Target値を0~1の範囲に変換
22 / 42
23.
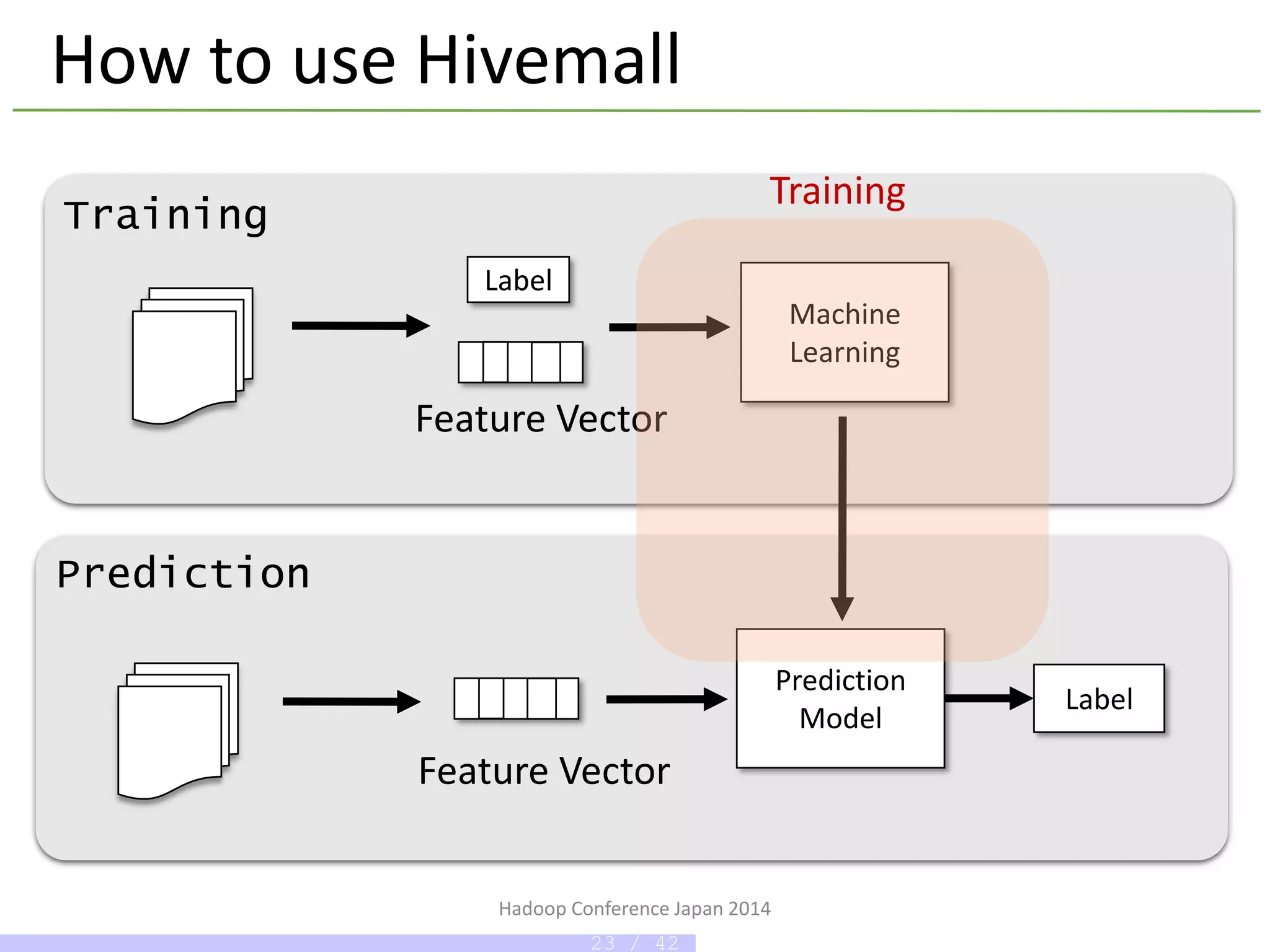
Hadoop Conference Japan2014
How to use Hivemall
Machine
Learning
Training
Prediction
Prediction
Model
Label
Feature Vector
Feature Vector
Label
Training
23 / 42
24.
Hadoop Conference Japan2014
How to use Hivemall - Training
CREATE TABLE lr_model AS
SELECT
feature,
avg(weight) as weight
FROM (
SELECT logress(features,label,..)
as (feature,weight)
FROM train
) t
GROUP BY feature
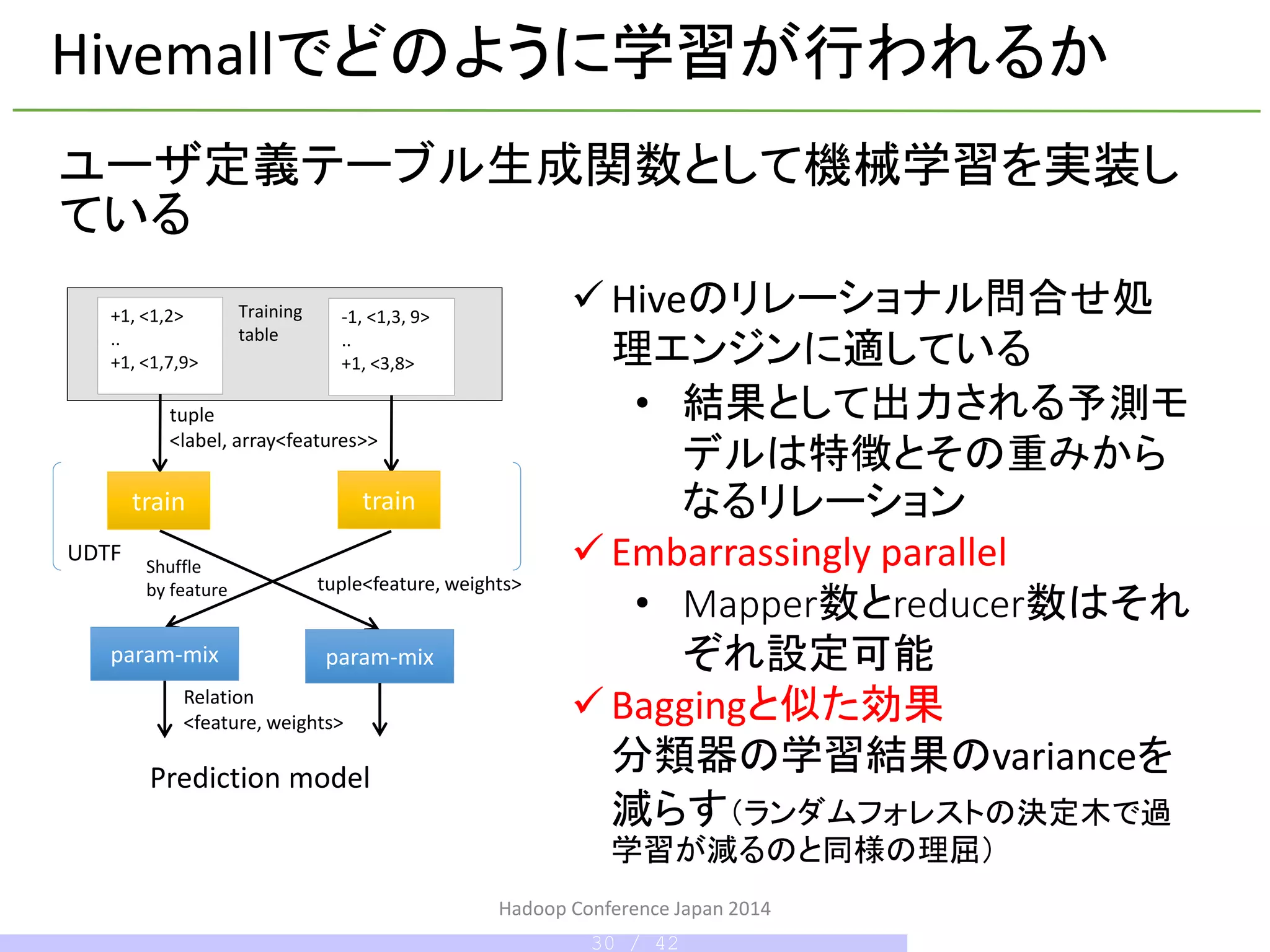
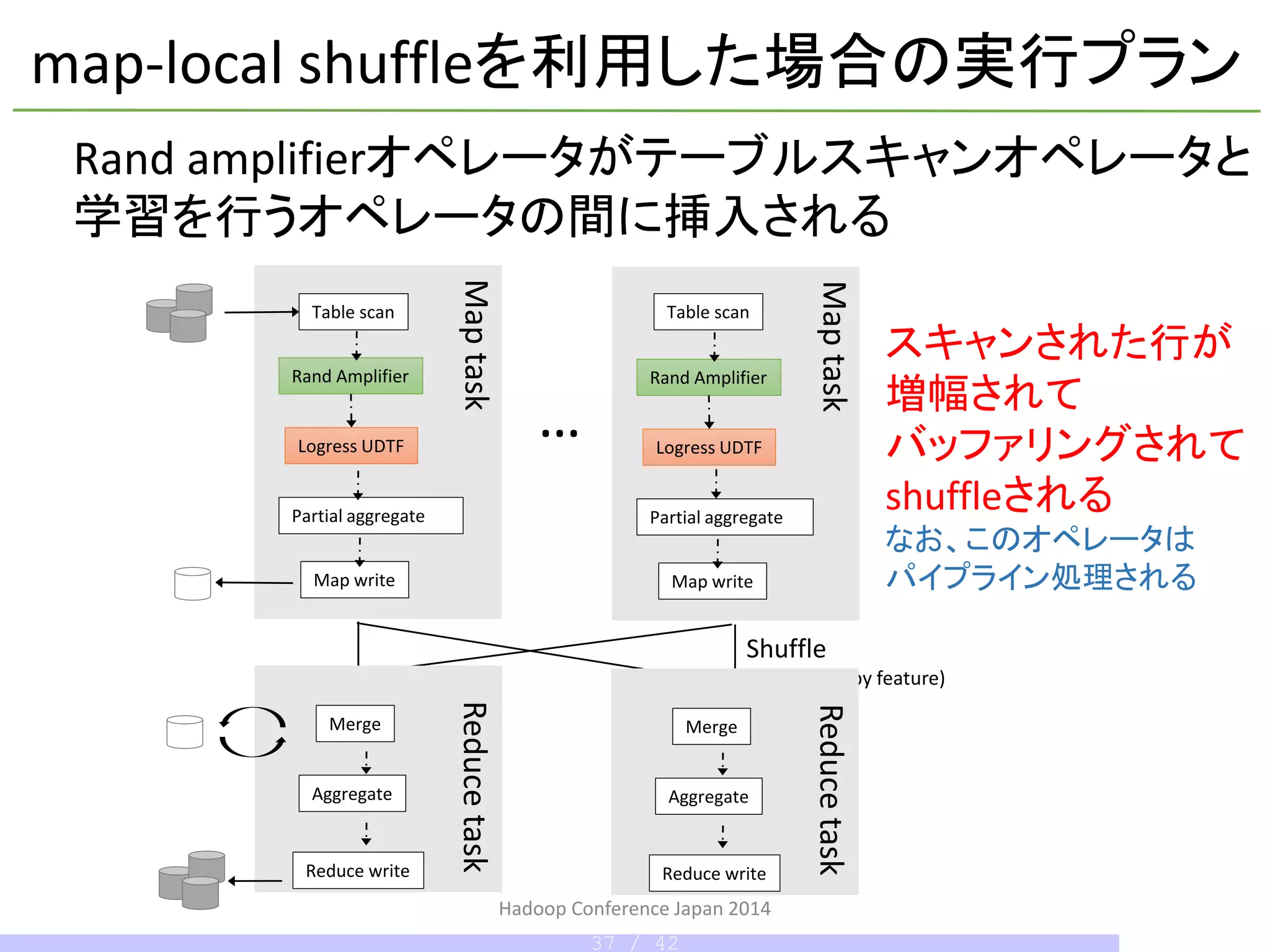
ロジスティック回帰による学習
予測モデルを学習するmap-onlyのtask
Featureの値によってmap出力結果をreducerに
Shuffle
特徴ごとに学習した重みの平均
を取る処理をreducer側で並列に処理
24 / 42
25.
Hadoop Conference Japan2014
How to use Hivemall - Training
CREATE TABLE news20b_cw_model1 AS
SELECT
feature,
voted_avg(weight) as weight
FROM
(SELECT
train_cw(features,label)
as (feature,weight)
FROM
news20b_train
) t
GROUP BY feature
Confidence Weightedによる学習
投票に基づきPositive or Negativeな
重みの平均
+0.7, +0.3, +0.2, -0.1, +0.7
CWクラス分類器による学習
25 / 42
26.
Hadoop Conference Japan2014
create table news20mc_ensemble_model1 as
select
label,
cast(feature as int) as feature,
cast(voted_avg(weight) as float) as weight
from
(select
train_multiclass_cw(addBias(features),label)
as (label,feature,weight)
from
news20mc_train_x3
union all
select
train_multiclass_arow(addBias(features),label)
as (label,feature,weight)
from
news20mc_train_x3
union all
select
train_multiclass_scw(addBias(features),label)
as (label,feature,weight)
from
news20mc_train_x3
) t
group by label, feature;
アンサンブル学習 for stable prediction performance
個別に学習した予測モデルを
Union allでまとめる
26 / 42
27.
Hadoop Conference Japan2014
How to use Hivemall
Machine
Learning
Training
Prediction
Prediction
Model
Label
Feature Vector
Feature Vector
Label
Prediction
27 / 42
28.
Hadoop Conference Japan2014
How to use Hivemall - Prediction
CREATE TABLE lr_predict
as
SELECT
t.rowid,
sigmoid(sum(m.weight)) as prob
FROM
testing_exploded t LEFT OUTER JOIN
lr_model m ON (t.feature = m.feature)
GROUP BY
t.rowid
予測はテスト事例と予測モデルの
LEFT OUTER JOINによって行う
予測モデル全体をメモリに載せる必要がない
28 / 42
29.
発表の構成
• What isHivemall
• Why Hivemall
• What Hivemall can do
• How to use Hivemall
• How Hivemall works
• イテレーションへの対処方法(Sparkと比較)
• 性能評価
• まとめ
Hadoop Conference Japan 2014
29 / 42
val data =spark.textFile(...).map(readPoint).cache()
for (i <- 1 to ITERATIONS) {
val gradient = data.map(p =>
(1 / (1 + exp(-p.y*(w dot p.x))) - 1) * p.y * p.x
).reduce(_ + _)
w -= gradient
}
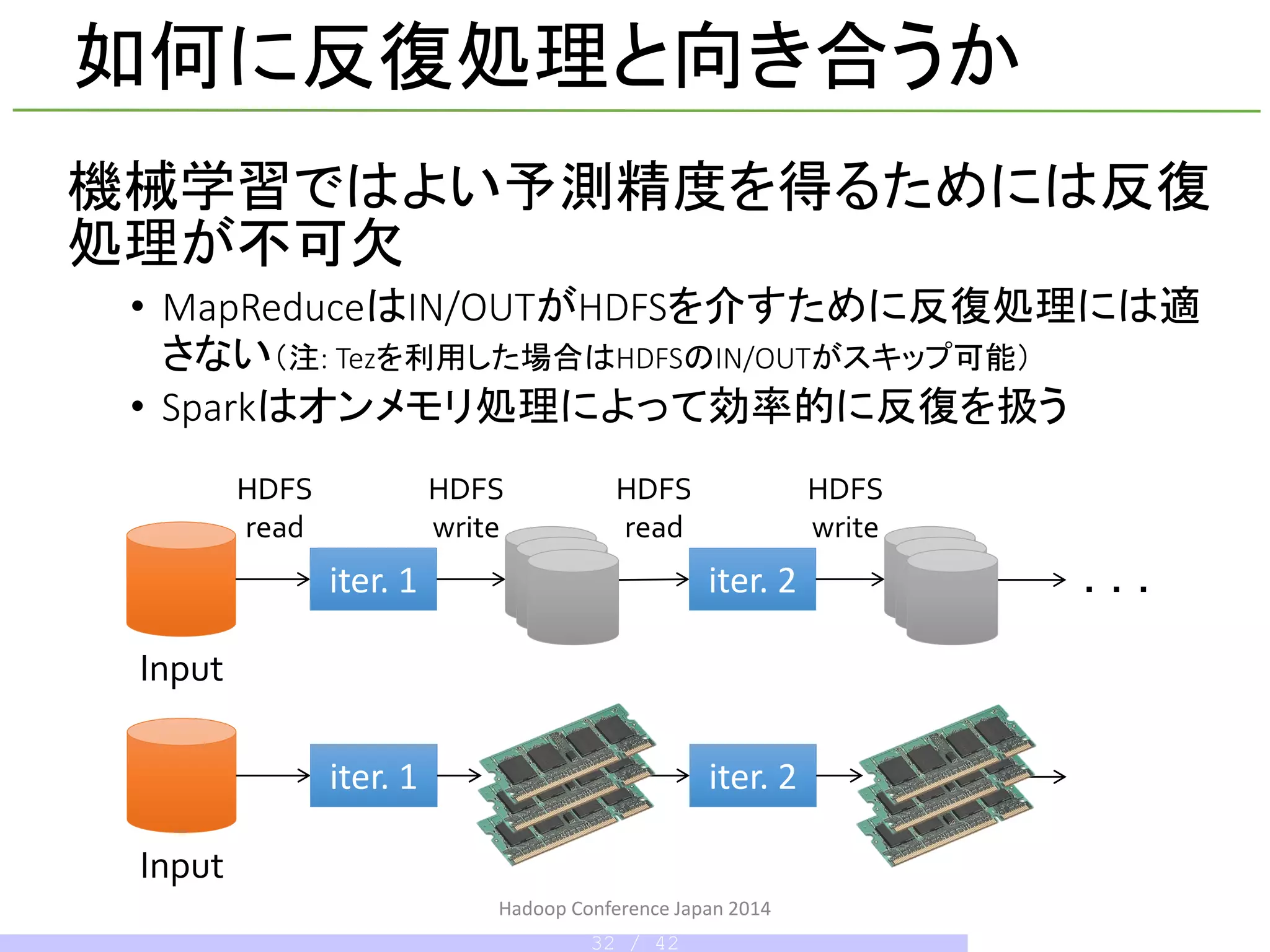
反復的なMapReduceで
勾配降下を行う
個々のノードで担当パーティ
ションをメモリにキャッシュ
これは単なるtoy example! Why?
Sparkにおける反復学習
Logistic Regression example of Spark
勾配の計算に使う訓練例は反復ごとに異なるものを利用する
必要がある(そうしないと精度がでないし、より多くの反復が必要となる)
Hadoop Conference Japan 2014
33 / 42
34.
Hadoop Conference Japan2014
Spark Mllibでは実際どうなっている?
Val data = ..
for (i <- 1 to numIterations) {
val sampled =
val gradient =
w -= gradient
}
サンプリングを利用したMini-batch勾配降下法
それぞれのイテレーションではデータの一部だけを
利用するため、反復処理は学習の収束に不可欠
GradientDescent.scala
bit.ly/spark-gd
データのサブセットをサンプリング
Spark MapReduceを利用してSampled[1..N]の勾配をN個のワー
カで並列に計算してN個の予測モデルを構築し、N個のご予測モデルを
マスターノードで(逐次的に)マージ
34 / 42
Wは次のイテレーションで各ワーカに送信される
発表の構成
• What isHivemall
• Why Hivemall
• What Hivemall can do
• How to use Hivemall
• How Hivemall works
• イテレーションへの対処方法(Sparkと比較)
• 性能評価
• まとめ
Hadoop Conference Japan 2014
39 / 42








![Hadoop Conference Japan 2014
Why Hivemall
4. 最新のオンライン学習アルゴリズムをサポー
ト(クラス分類)
• ハイパーパラメータ/設定の細かい調整をしなくて
も十分な精度が出る (確率的勾配降下法ベースの場
合は学習率の調整が困難)
• CW, AROW[1], SCW[2]のような最先端の機械学
習アルゴリズムはMahout/Sparkではサポートさ
れていない
• 学習の収束が高速
• 一般的には10イテレーションが必要なところでもCW以
降では2~3イテレーションもあれば収束する
1. Adaptive Regularization of Weight Vectors (AROW), Crammer et al., NIPS 2009
2. Exact Soft Confidence-Weighted Learning (SCW), Wang et al., ICML 2012
12 / 42](https://image.slidesharecdn.com/hdj2014-myui-140707233222-phpapp01/75/Hcj2014-myui-12-2048.jpg)
![Hadoop Conference Japan 2014
Why Hivemall
Algorithms
News20.binary
Classification Accuracy
Perceptron 0.9460
Passive-Aggressive
(a.k.a. Online-SVM)
0.9604
LibLinear 0.9636
LibSVM/TinySVM 0.9643
Confidence Weighted (CW) 0.9656
AROW [1] 0.9660
SCW [2] 0.9662
精度が
良い
4. 最新のオンライン学習アルゴリズムを
サポート(クラス分類)
CWやその改良は賢いオンライン機械学習アルゴリズム
13 / 42](https://image.slidesharecdn.com/hdj2014-myui-140707233222-phpapp01/75/Hcj2014-myui-13-2048.jpg)











![Hadoop Conference Japan 2014
Spark Mllibでは実際どうなっている?
Val data = ..
for (i <- 1 to numIterations) {
val sampled =
val gradient =
w -= gradient
}
サンプリングを利用したMini-batch勾配降下法
それぞれのイテレーションではデータの一部だけを
利用するため、反復処理は学習の収束に不可欠
GradientDescent.scala
bit.ly/spark-gd
データのサブセットをサンプリング
Spark MapReduceを利用してSampled[1..N]の勾配をN個のワー
カで並列に計算してN個の予測モデルを構築し、N個のご予測モデルを
マスターノードで(逐次的に)マージ
34 / 42
Wは次のイテレーションで各ワーカに送信される](https://image.slidesharecdn.com/hdj2014-myui-140707233222-phpapp01/75/Hcj2014-myui-34-2048.jpg)









































![[D22] Pivotal HD 2.0 -業界最高レベルSQL on Hadoop技術「HAWQ」解説- by Masayuki Matsushita](https://cdn.slidesharecdn.com/ss_thumbnails/d22pivotal-140709032745-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































