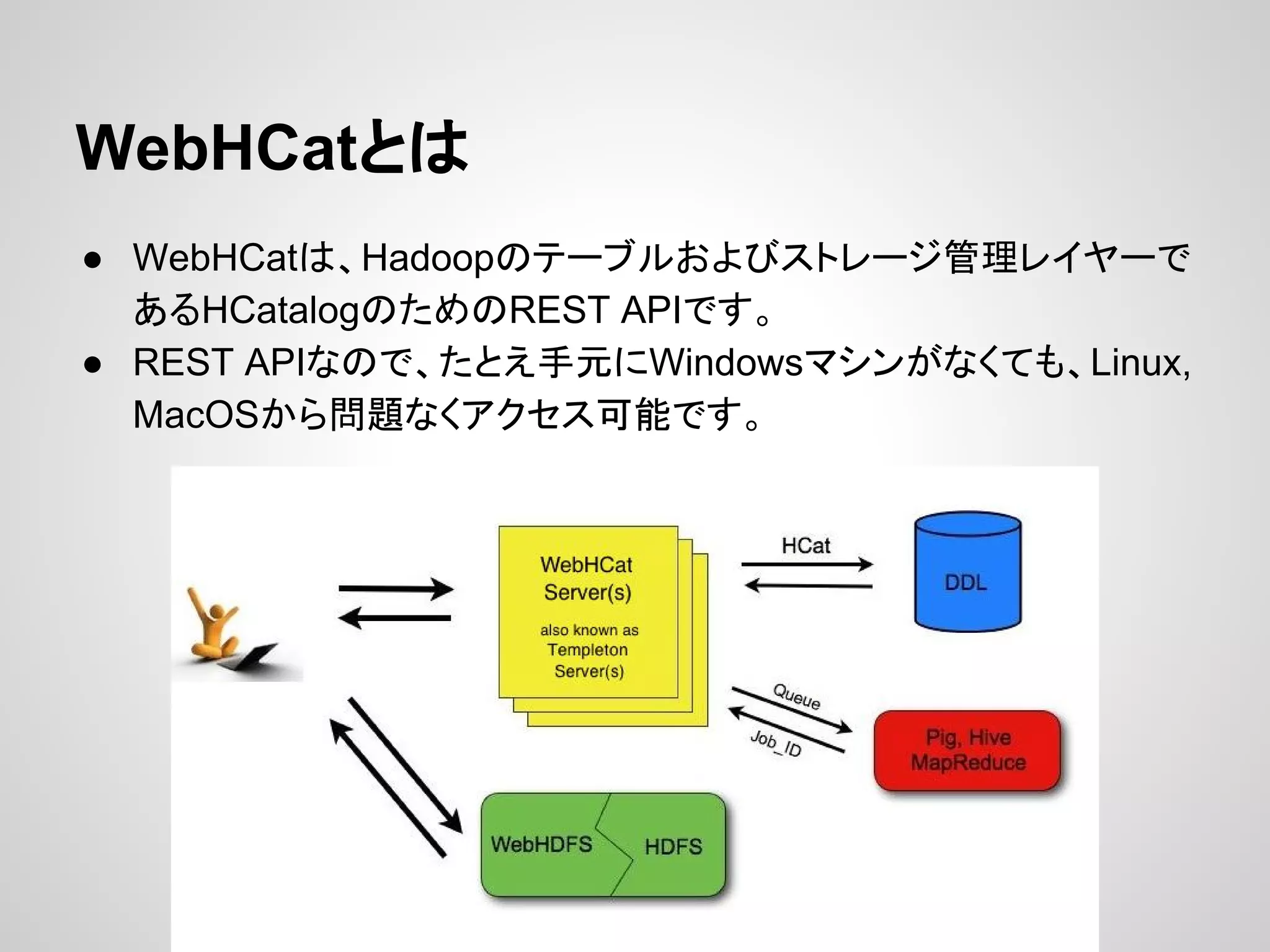
F#でも使いたい! (HadoopFsとは)
● HadoopFsとは
○Hadoop(HDInsightも含む)を、F#から使うためのライブラリ
○ githubでソースコードが公開されています
○ https://github.com/isaacabraham/HadoopFs
● The existing .NET APIs for Hadoop that runs on e.g. HDInsight are somewhat
awkward from an F# point of view: -
○ Requires inheriting from abstract classes
○ Inpure style makes code harder to test
● HadoopFs makes life easier for the F# developer that wants to develop map/reduce
jobs: -
○ No base class hierarchy for your map / reduce functions to adhere to
○ Support for both optional single-instance outputs and output collections
○ Support for easily testing inputs and outputs from file system as well as
in-memory data source, or you can supply your own
○ Easy to test your map and reduce functions - no need for external Hadoop test
libraries




































































![[D22] Pivotal HD 2.0 -業界最高レベルSQL on Hadoop技術「HAWQ」解説- by Masayuki Matsushita](https://cdn.slidesharecdn.com/ss_thumbnails/d22pivotal-140709032745-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






