Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Recruit Technologies
PPTX, PDF
26,839 views
Hadoopカンファレンス20140707
7月8日に行われた、Hadoop Conference Japan 2014で弊社石川が講演した資料になります。
Technology
◦
Read more
22
Save
Share
Embed
Embed presentation
Download
Downloaded 157 times
1
/ 58
2
/ 58
3
/ 58
4
/ 58
5
/ 58
6
/ 58
7
/ 58
8
/ 58
9
/ 58
10
/ 58
11
/ 58
12
/ 58
13
/ 58
14
/ 58
15
/ 58
16
/ 58
17
/ 58
18
/ 58
19
/ 58
20
/ 58
21
/ 58
22
/ 58
23
/ 58
24
/ 58
25
/ 58
26
/ 58
27
/ 58
28
/ 58
29
/ 58
30
/ 58
31
/ 58
32
/ 58
33
/ 58
34
/ 58
35
/ 58
36
/ 58
37
/ 58
38
/ 58
39
/ 58
40
/ 58
41
/ 58
42
/ 58
43
/ 58
44
/ 58
45
/ 58
46
/ 58
47
/ 58
48
/ 58
49
/ 58
50
/ 58
51
/ 58
52
/ 58
53
/ 58
54
/ 58
55
/ 58
56
/ 58
57
/ 58
58
/ 58
More Related Content
PPTX
基本設計+詳細設計の書き方 社内勉強会0304
by
furuCRM株式会社 CEO/Dreamforce Vietnam Founder
PDF
現場の声から生まれた障害対応ツール「Barry」
by
IIJ
PDF
ISID×MS_DLLAB_企業のデータ&AI活用をAzureで加速する
by
Miyuki Mochizuki
PDF
アジャイルコーチが現場で学んだプロダクトオーナーの実際と勘所 POの二番目に大事なことと
by
Yasui Tsutomu
PDF
心理的安全性の構造 デブサミ2019夏 structure of psychological safety
by
Tokoroten Nakayama
PDF
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
PDF
スペシャリストになるには
by
外道 父
PPTX
スケジュール遅延が当たり前な状況を少し良くしたいチームがその未来のためにScrumに”再”挑戦した話
by
Rakuten Commerce Tech (Rakuten Group, Inc.)
基本設計+詳細設計の書き方 社内勉強会0304
by
furuCRM株式会社 CEO/Dreamforce Vietnam Founder
現場の声から生まれた障害対応ツール「Barry」
by
IIJ
ISID×MS_DLLAB_企業のデータ&AI活用をAzureで加速する
by
Miyuki Mochizuki
アジャイルコーチが現場で学んだプロダクトオーナーの実際と勘所 POの二番目に大事なことと
by
Yasui Tsutomu
心理的安全性の構造 デブサミ2019夏 structure of psychological safety
by
Tokoroten Nakayama
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
スペシャリストになるには
by
外道 父
スケジュール遅延が当たり前な状況を少し良くしたいチームがその未来のためにScrumに”再”挑戦した話
by
Rakuten Commerce Tech (Rakuten Group, Inc.)
What's hot
PDF
これからのJDK 何を選ぶ?どう選ぶ? (v1.2) in 熊本
by
Takahiro YAMADA
PDF
JaSST Tokyo 2022 アジャイルソフトウェア開発への統計的品質管理の応用
by
Akinori SAKATA
PDF
プラクティス厨から始めるアジャイル開発
by
Arata Fujimura
PDF
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
PDF
【AgileJapan2022】アジャイルで進めるSDGs実現への歩み_稲葉涼太20221115.pdf
by
Ryota Inaba
PDF
ROSCon発表の振り返りとROSConの振り返り(ROS Japan UG #48 ROSCon 2022ふりかえり会)
by
Atsushi Hasegawa
PPTX
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
PDF
SoR 2.0 基幹システムの再定義と再構築
by
増田 亨
PPTX
「品質ダッシュボード」と「データによる意思決定」
by
Kohei Tomita
PDF
Cognitive Complexity でコードの複雑さを定量的に計測しよう
by
Shuto Suzuki
PDF
見えない壁を越えよう!アジャイルやマイクロサービスを阻む「今までのやり方」 - デブサミ夏2023
by
Yusuke Suzuki
PDF
協働ロボットCOROの開発における形式的仕様記述KMLの開発と適用
by
Life Robotics
PDF
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
PDF
研究の基本ツール
by
由来 藤原
PPTX
チャットコミュニケーションの問題と心理的安全性の課題 #EOF2019
by
Tokoroten Nakayama
PPTX
クラウドネイティブ時代の大規模ウォーターフォール開発(CloudNative Days Tokyo 2021 発表資料)
by
NTT DATA Technology & Innovation
PDF
Yahoo!ニュースにおけるBFFパフォーマンスチューニング事例
by
Yahoo!デベロッパーネットワーク
PPTX
Power BI をアプリに埋め込みたい? ならば Power BI Embedded だ!
by
Teruchika Yamada
PDF
Open Liberty: オープンソースになったWebSphere Liberty
by
Takakiyo Tanaka
PPTX
Spring Boot ユーザの方のための Quarkus 入門
by
tsukasamannen
これからのJDK 何を選ぶ?どう選ぶ? (v1.2) in 熊本
by
Takahiro YAMADA
JaSST Tokyo 2022 アジャイルソフトウェア開発への統計的品質管理の応用
by
Akinori SAKATA
プラクティス厨から始めるアジャイル開発
by
Arata Fujimura
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
【AgileJapan2022】アジャイルで進めるSDGs実現への歩み_稲葉涼太20221115.pdf
by
Ryota Inaba
ROSCon発表の振り返りとROSConの振り返り(ROS Japan UG #48 ROSCon 2022ふりかえり会)
by
Atsushi Hasegawa
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
SoR 2.0 基幹システムの再定義と再構築
by
増田 亨
「品質ダッシュボード」と「データによる意思決定」
by
Kohei Tomita
Cognitive Complexity でコードの複雑さを定量的に計測しよう
by
Shuto Suzuki
見えない壁を越えよう!アジャイルやマイクロサービスを阻む「今までのやり方」 - デブサミ夏2023
by
Yusuke Suzuki
協働ロボットCOROの開発における形式的仕様記述KMLの開発と適用
by
Life Robotics
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
研究の基本ツール
by
由来 藤原
チャットコミュニケーションの問題と心理的安全性の課題 #EOF2019
by
Tokoroten Nakayama
クラウドネイティブ時代の大規模ウォーターフォール開発(CloudNative Days Tokyo 2021 発表資料)
by
NTT DATA Technology & Innovation
Yahoo!ニュースにおけるBFFパフォーマンスチューニング事例
by
Yahoo!デベロッパーネットワーク
Power BI をアプリに埋め込みたい? ならば Power BI Embedded だ!
by
Teruchika Yamada
Open Liberty: オープンソースになったWebSphere Liberty
by
Takakiyo Tanaka
Spring Boot ユーザの方のための Quarkus 入門
by
tsukasamannen
Similar to Hadoopカンファレンス20140707
PDF
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter)
by
NTT DATA OSS Professional Services
PDF
サーバ性能改善事例
by
KLab Inc. / Tech
PPTX
ビッグデータ&データマネジメント展
by
Recruit Technologies
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
PDF
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PDF
20100916_EMRを使ったシステム構築案件
by
Kotaro Tsukui
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
PPTX
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
PDF
リクルート式Hadoopの使い方
by
Recruit Technologies
PDF
Asakusaによる分散分析基盤構築事例紹介
by
Kozo Fukugauchi
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
Hadoopを用いた大規模ログ解析
by
shuichi iida
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
by
NTT DATA Technology & Innovation
PPT
マーケティングテクノロジー勉強会
by
伊藤 孝
PDF
WDD2012_SC-004
by
Kuninobu SaSaki
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料)
by
NTT DATA Technology & Innovation
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter)
by
NTT DATA OSS Professional Services
サーバ性能改善事例
by
KLab Inc. / Tech
ビッグデータ&データマネジメント展
by
Recruit Technologies
Osc2012 spring HBase Report
by
Seiichiro Ishida
Facebookのリアルタイム Big Data 処理
by
maruyama097
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
20100916_EMRを使ったシステム構築案件
by
Kotaro Tsukui
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
リクルート式Hadoopの使い方
by
Recruit Technologies
Asakusaによる分散分析基盤構築事例紹介
by
Kozo Fukugauchi
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
Hadoopを用いた大規模ログ解析
by
shuichi iida
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
by
NTT DATA Technology & Innovation
マーケティングテクノロジー勉強会
by
伊藤 孝
WDD2012_SC-004
by
Kuninobu SaSaki
Cloudera大阪セミナー 20130219
by
Cloudera Japan
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料)
by
NTT DATA Technology & Innovation
More from Recruit Technologies
PDF
新卒2年目が鍛えられたコードレビュー道場
by
Recruit Technologies
PDF
カーセンサーで深層学習を使ってUX改善を行った事例とそこからの学び
by
Recruit Technologies
PDF
Rancherを活用した開発事例の紹介 ~Rancherのメリットと辛いところ~
by
Recruit Technologies
PDF
Tableau活用4年の軌跡
by
Recruit Technologies
PDF
HadoopをBQにマイグレしようとしてる話
by
Recruit Technologies
PDF
LT(自由)
by
Recruit Technologies
PDF
リクルートグループの現場事例から見る AI/ディープラーニング ビジネス活用の勘所
by
Recruit Technologies
PDF
Company Recommendation for New Graduates via Implicit Feedback Multiple Matri...
by
Recruit Technologies
PDF
リクルート式AIの活用法
by
Recruit Technologies
PDF
銀行ロビーアシスタント
by
Recruit Technologies
PDF
リクルートにおけるマルチモーダル Deep Learning Web API 開発事例
by
Recruit Technologies
PDF
ユーザー企業内製CSIRTにおける対応のポイント
by
Recruit Technologies
PDF
ユーザーからみたre:Inventのこれまでと今後
by
Recruit Technologies
PDF
Struggling with BIGDATA -リクルートおけるデータサイエンス/エンジニアリング-
by
Recruit Technologies
PDF
EMRでスポットインスタンスの自動入札ツールを作成する
by
Recruit Technologies
PDF
RANCHERを使ったDev(Ops)
by
Recruit Technologies
PDF
リクルートにおけるセキュリティ施策方針とCSIRT組織運営のポイント
by
Recruit Technologies
PDF
ユーザー企業内製CSIRTにおける対応のポイント
by
Recruit Technologies
PDF
リクルートテクノロジーズが語る 企業における、「AI/ディープラーニング」活用のリアル
by
Recruit Technologies
PDF
「リクルートデータセット」 ~公開までの道のりとこれから~
by
Recruit Technologies
新卒2年目が鍛えられたコードレビュー道場
by
Recruit Technologies
カーセンサーで深層学習を使ってUX改善を行った事例とそこからの学び
by
Recruit Technologies
Rancherを活用した開発事例の紹介 ~Rancherのメリットと辛いところ~
by
Recruit Technologies
Tableau活用4年の軌跡
by
Recruit Technologies
HadoopをBQにマイグレしようとしてる話
by
Recruit Technologies
LT(自由)
by
Recruit Technologies
リクルートグループの現場事例から見る AI/ディープラーニング ビジネス活用の勘所
by
Recruit Technologies
Company Recommendation for New Graduates via Implicit Feedback Multiple Matri...
by
Recruit Technologies
リクルート式AIの活用法
by
Recruit Technologies
銀行ロビーアシスタント
by
Recruit Technologies
リクルートにおけるマルチモーダル Deep Learning Web API 開発事例
by
Recruit Technologies
ユーザー企業内製CSIRTにおける対応のポイント
by
Recruit Technologies
ユーザーからみたre:Inventのこれまでと今後
by
Recruit Technologies
Struggling with BIGDATA -リクルートおけるデータサイエンス/エンジニアリング-
by
Recruit Technologies
EMRでスポットインスタンスの自動入札ツールを作成する
by
Recruit Technologies
RANCHERを使ったDev(Ops)
by
Recruit Technologies
リクルートにおけるセキュリティ施策方針とCSIRT組織運営のポイント
by
Recruit Technologies
ユーザー企業内製CSIRTにおける対応のポイント
by
Recruit Technologies
リクルートテクノロジーズが語る 企業における、「AI/ディープラーニング」活用のリアル
by
Recruit Technologies
「リクルートデータセット」 ~公開までの道のりとこれから~
by
Recruit Technologies
Hadoopカンファレンス20140707
1.
株式会社リクルートテクノロジーズ ITソリューション統括部 ビッグデータ2グループ 石川 信行 リクルート式Hadoopの使い方 3rd
Edition
2.
自己紹介 2 氏名 石川 信行 所属
RTC ITソリューション統括部 ビッグデータ2G 兼アドバンスドテクノロジーラボ 略歴 新卒入社6年目。カーセンサー.netで営業研修、 Javaを用いたシステム開発に参加し、その後Hadoop の導入検証に従事。主要事業にHadoopを導入したの ちビッグデータGに合流。現事業対応リーダー、画像 解析など技術開発に従事。 学歴 神戸大学大学院農学研究科 害虫制御学専攻 趣味etc 海水魚飼育 外国産昆虫飼育 スキューバダイビング
3.
アジェンダ 最近のデータ活用状況紹介1 データ利活用案件紹介2 データ解析基盤について3 技術導入の過程4 取り掛かり中の技術紹介5 まとめと今後6
4.
4 最近のデータ活用状況紹介
5.
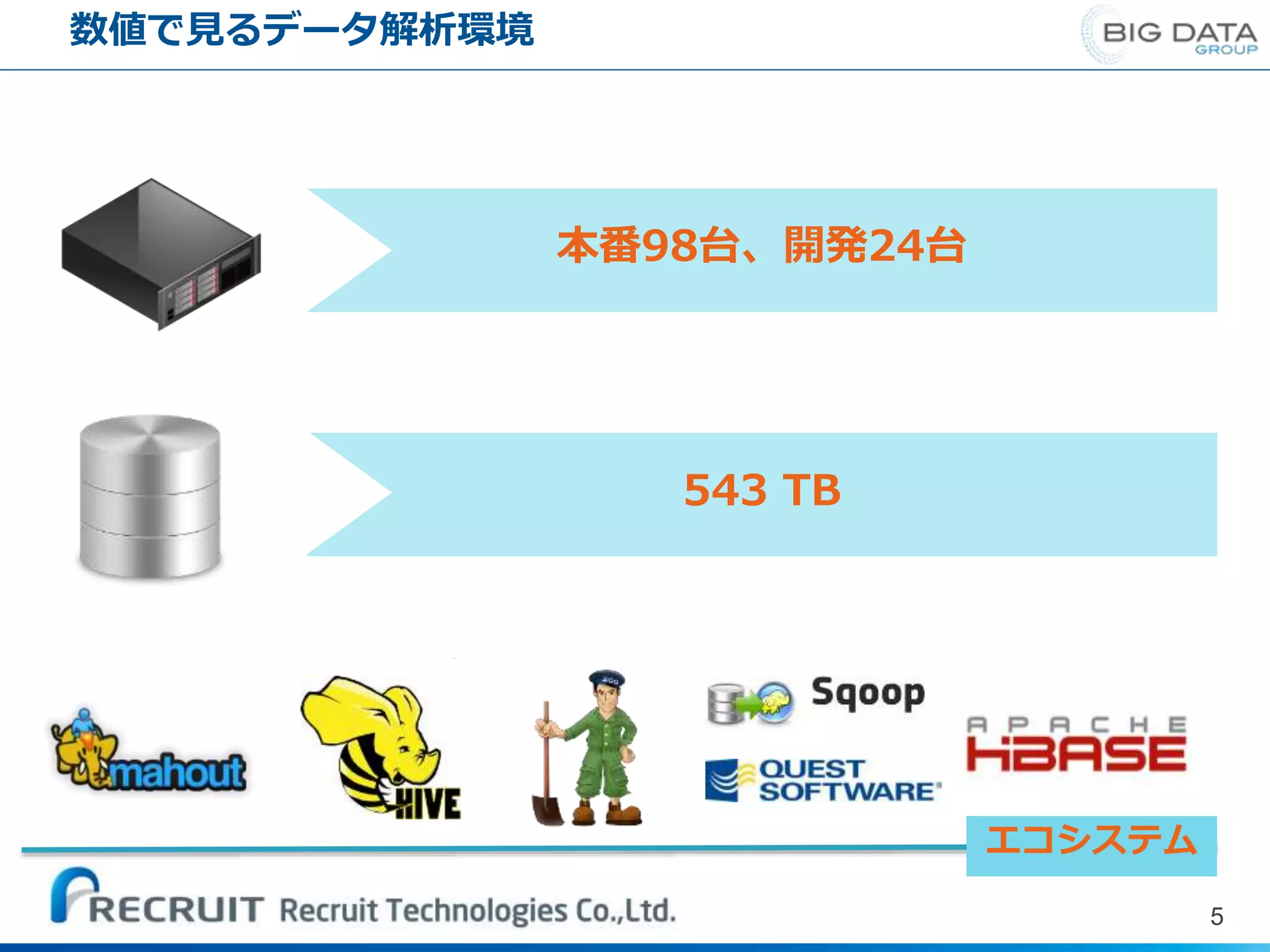
数値で見るデータ解析環境 5 本番98台、開発24台 543 TB エコシステム
6.
数値で見るHadoopの使われ方 6 28,344 295 1038 万 1日あたりの全JOBの数 1日あたりの全WebHiveクエリの数 1日あたりの全Hbaseクエリの数 ※6/23~6/24計測
7.
数値で見るデータ解析案件状況 7 200 155 データ解析案件数(年間) ビッグデータ部の案件従事人数 ぐらい
8.
8 データ利活用案件紹介
9.
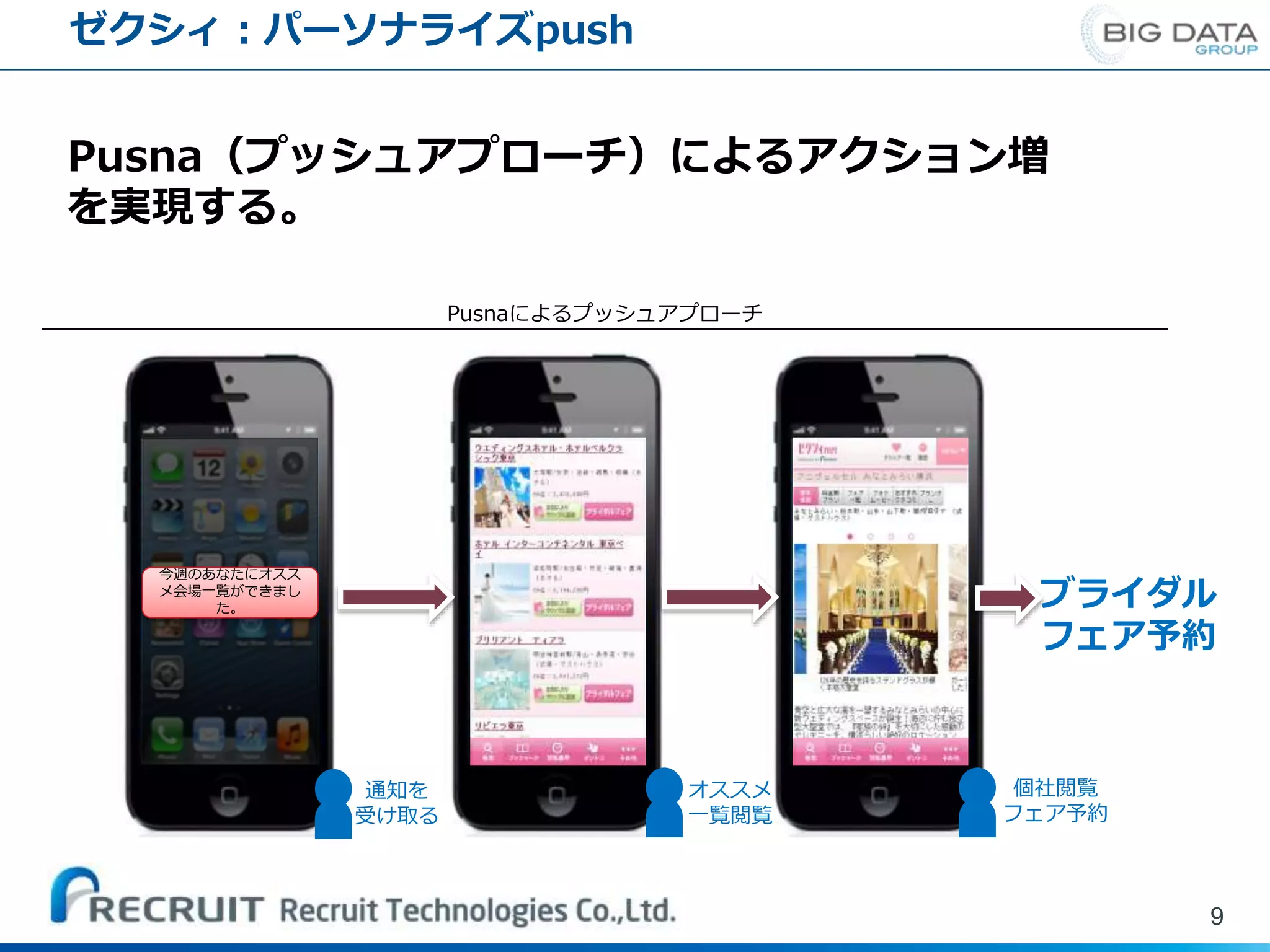
ゼクシィ:パーソナライズpush 今週のあなたにオスス メ会場一覧ができまし た。 オススメ 一覧閲覧 通知を 受け取る 個社閲覧 フェア予約 ブライダル フェア予約 Pusnaによるプッシュアプローチ Pusna(プッシュアプローチ)によるアクション増 を実現する。 9
10.
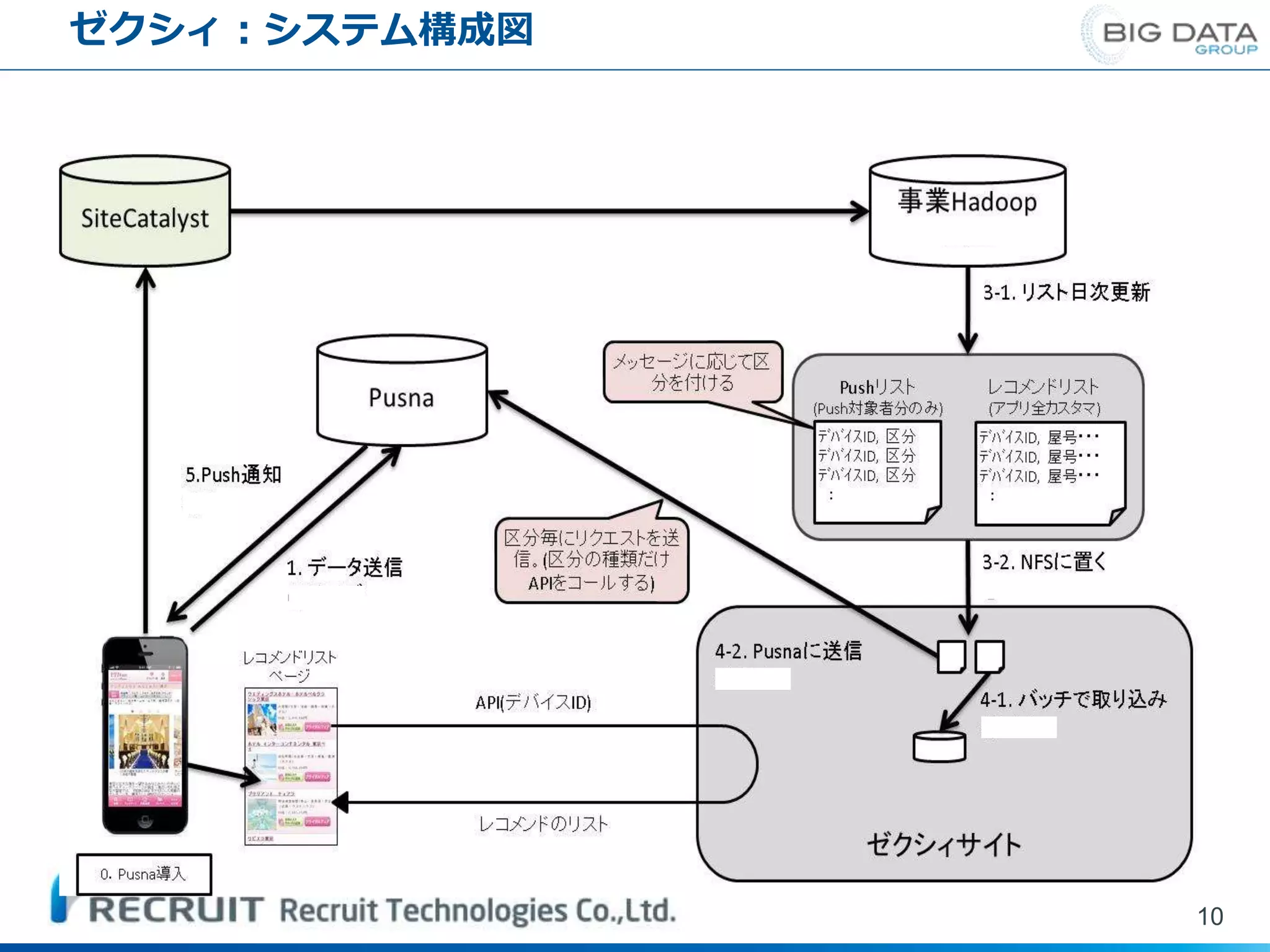
ゼクシィ:システム構成図 10
11.
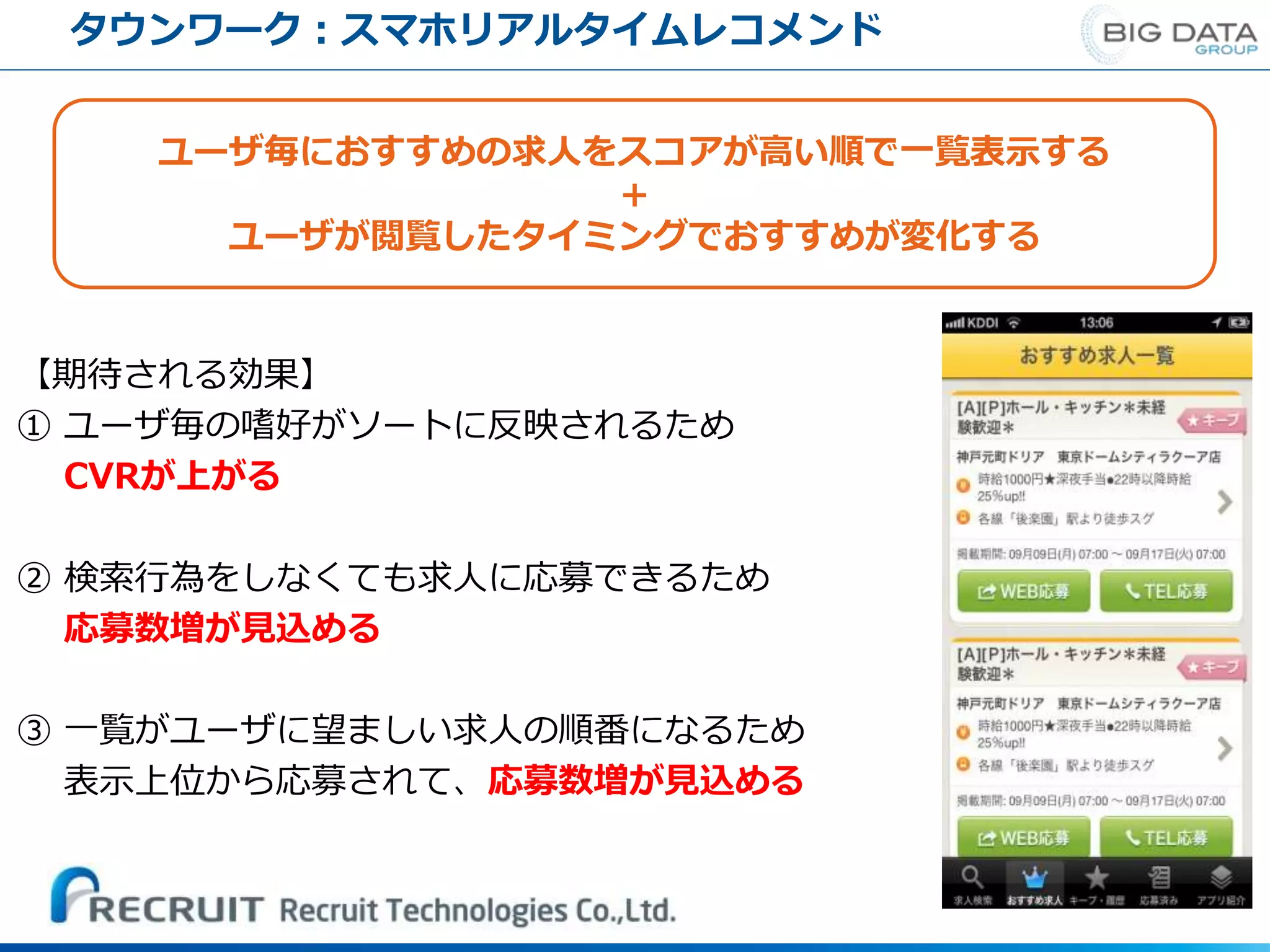
【期待される効果】 ① ユーザ毎の嗜好がソートに反映されるため CVRが上がる ② 検索行為をしなくても求人に応募できるため 応募数増が見込める ③
一覧がユーザに望ましい求人の順番になるため 表示上位から応募されて、応募数増が見込める ユーザ毎におすすめの求人をスコアが高い順で一覧表示する + ユーザが閲覧したタイミングでおすすめが変化する タウンワーク:スマホリアルタイムレコメンド
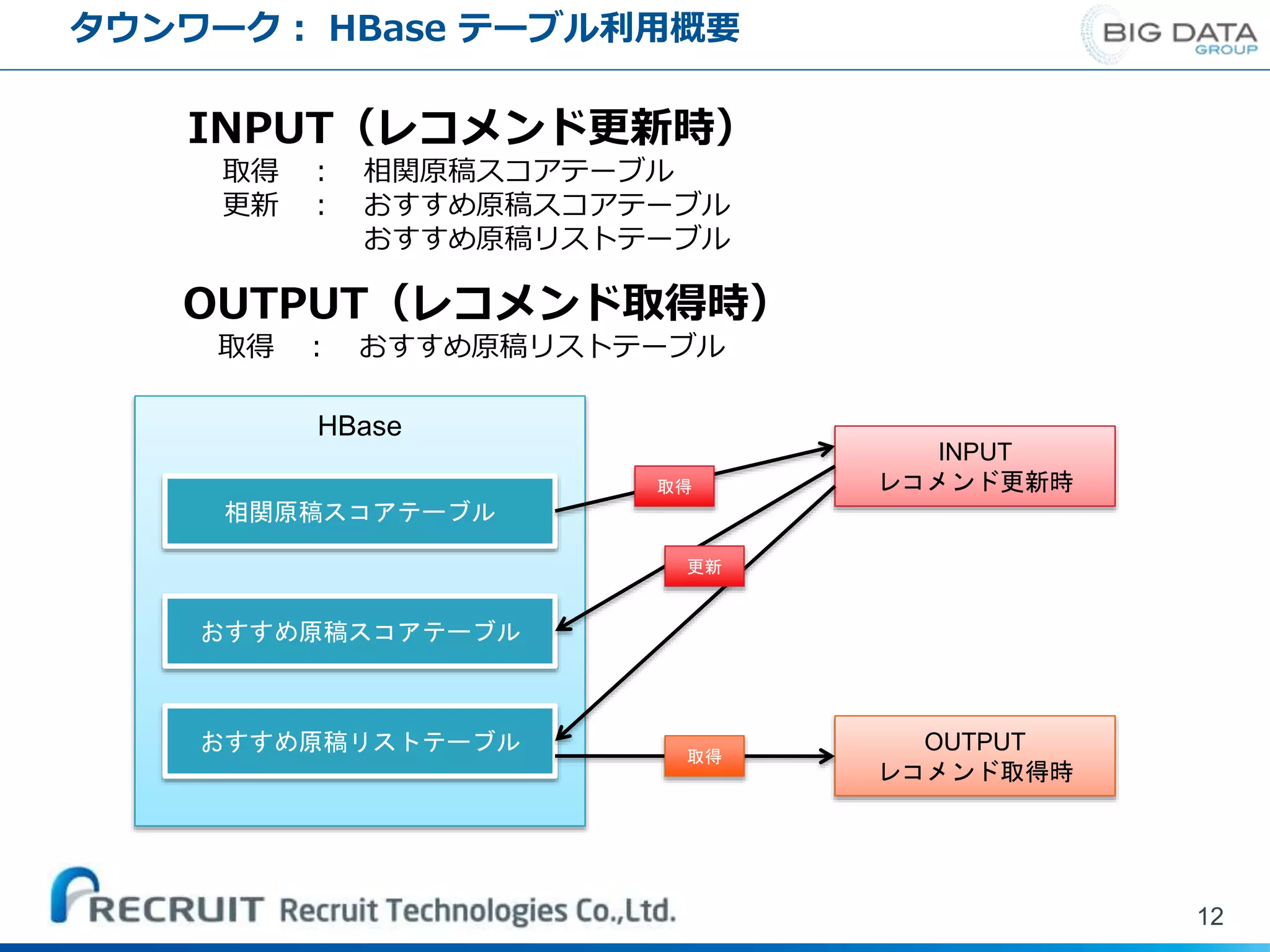
12.
タウンワーク: HBase テーブル利用概要 12 HBase 相関原稿スコアテーブル おすすめ原稿スコアテーブル おすすめ原稿リストテーブル INPUT レコメンド更新時 OUTPUT レコメンド取得時 取得 更新 取得 INPUT(レコメンド更新時) 取得
: 相関原稿スコアテーブル 更新 : おすすめ原稿スコアテーブル おすすめ原稿リストテーブル OUTPUT(レコメンド取得時) 取得 : おすすめ原稿リストテーブル
13.
ポンパレモールアイテムレコメンド 13 6/23にポイント確認画面を借りて ポンパレモールへパーソナライズレコメンドを実装
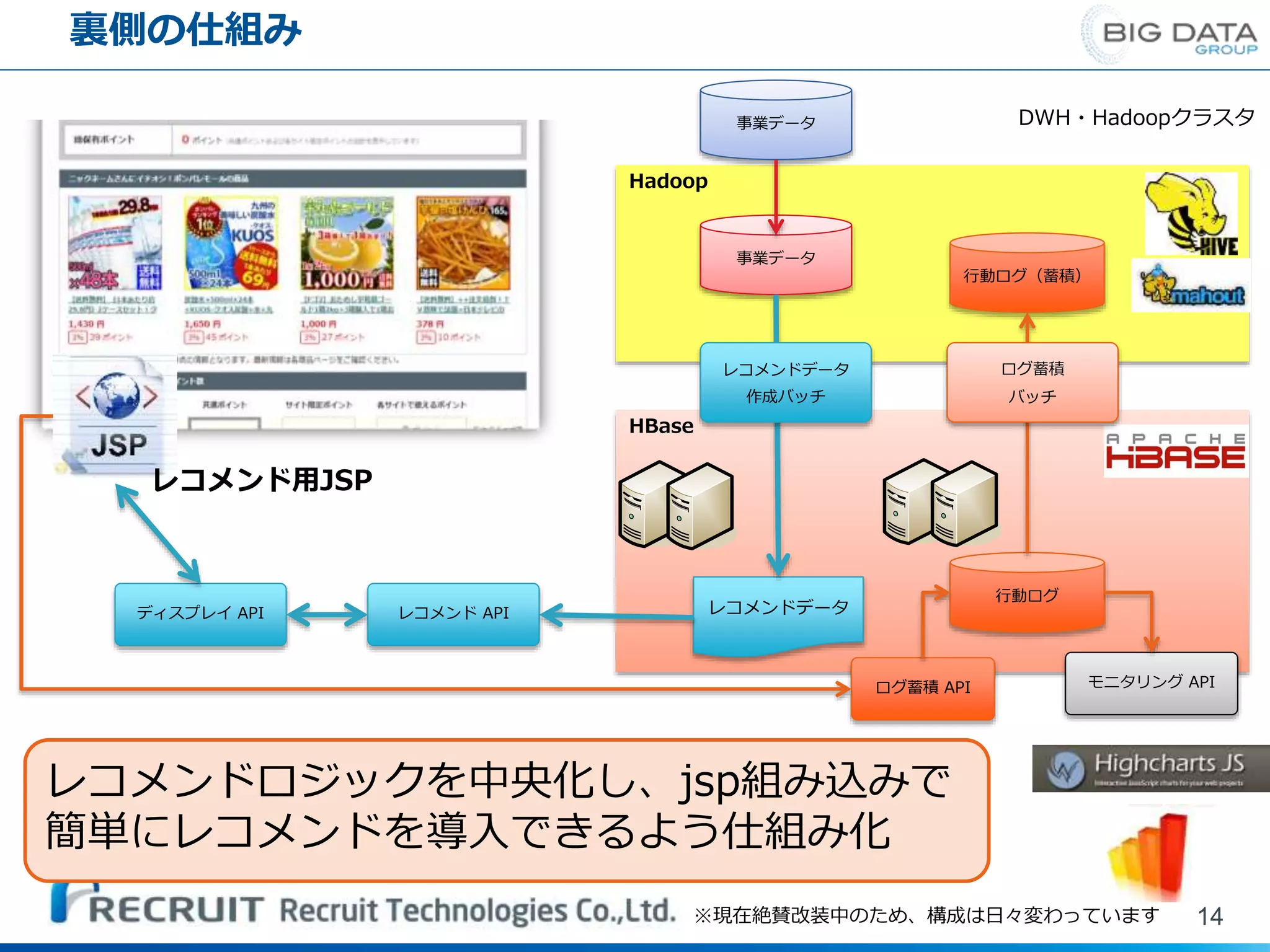
14.
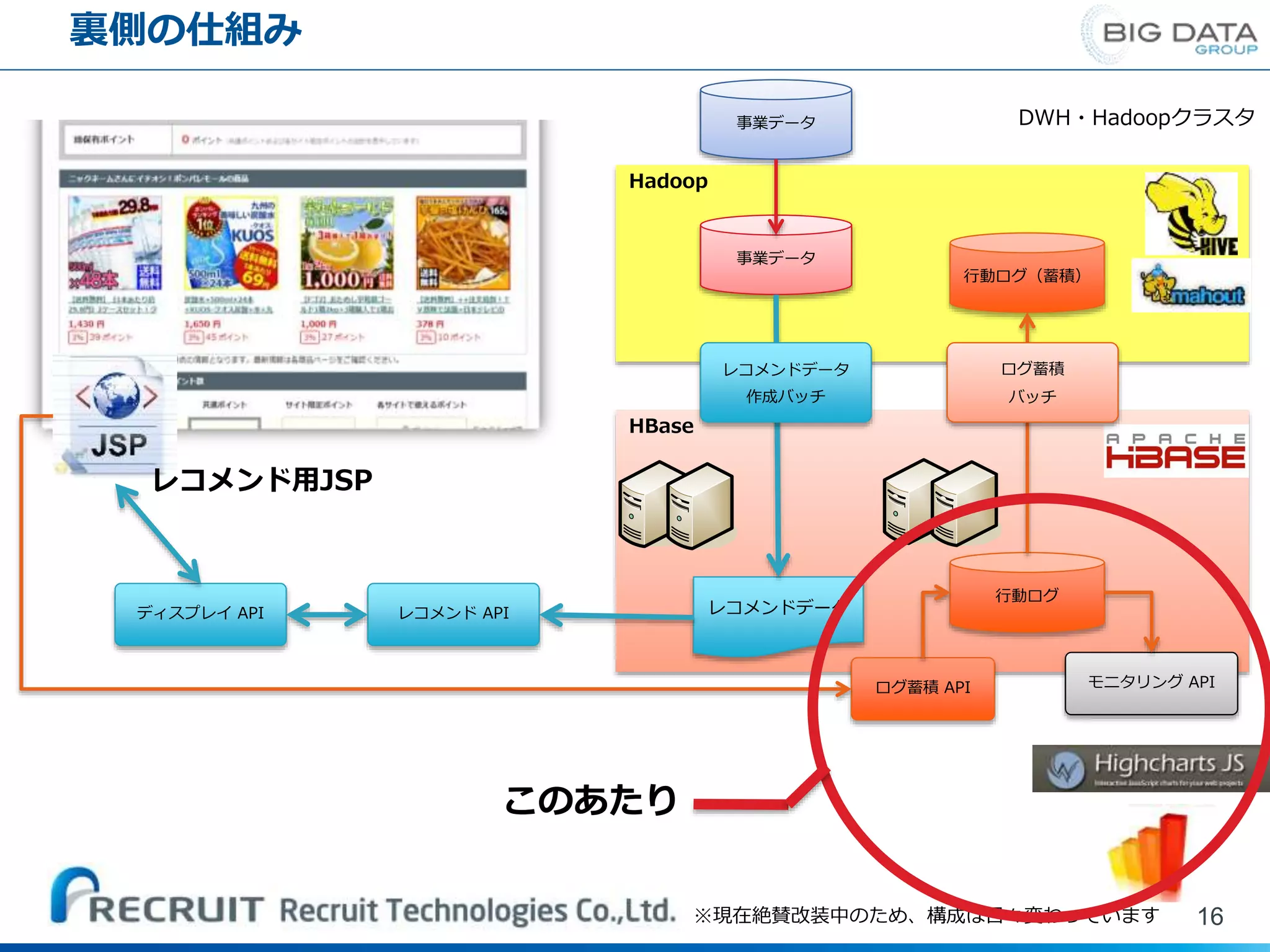
裏側の仕組み 14 レコメンド用JSP Hadoop HBase 行動ログ モニタリング API 行動ログ(蓄積) DWH・Hadoopクラスタ 事業データ 事業データ ディスプレイ API
レコメンド API レコメンドデータ レコメンドデータ 作成バッチ ログ蓄積 API ログ蓄積 バッチ ※現在絶賛改装中のため、構成は日々変わっています レコメンドロジックを中央化し、jsp組み込みで 簡単にレコメンドを導入できるよう仕組み化
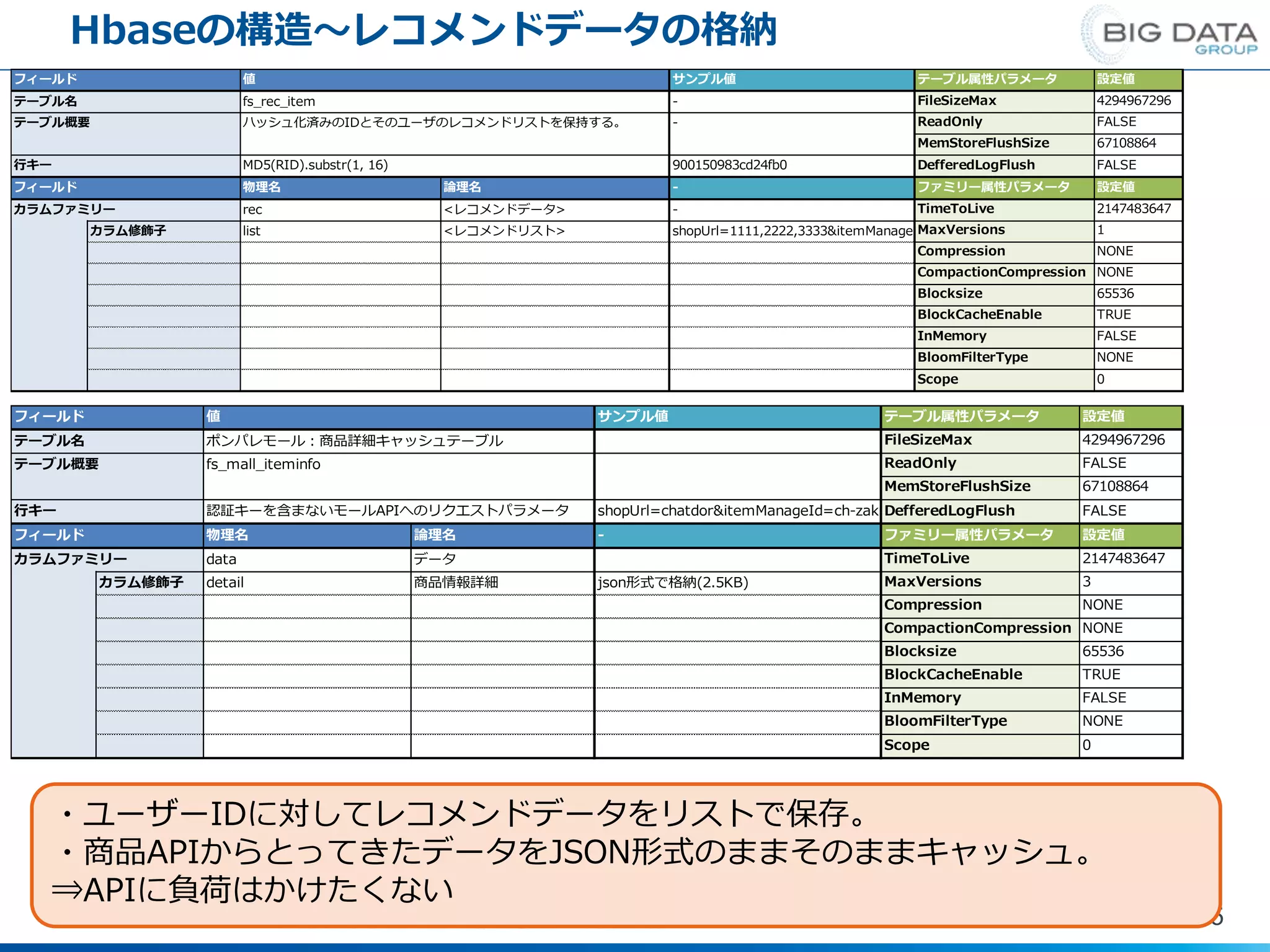
15.
Hbaseの構造~レコメンドデータの格納 15 フィールド 値 サンプル値 テーブル名
fs_rec_item - テーブル概要 ハッシュ化済みのIDとそのユーザのレコメンドリストを保持する。 - 行キー MD5(RID).substr(1, 16) 900150983cd24fb0 フィールド 物理名 論理名 - カラムファミリー rec <レコメンドデータ> - カラム修飾子 list <レコメンドリスト> shopUrl=1111,2222,3333&itemManageId=aaaa,bbbb,cccc InMemory FALSE BloomFilterType NONE Scope 0 CompactionCompression NONE Blocksize 65536 BlockCacheEnable TRUE TimeToLive 2147483647 MaxVersions 1 Compression NONE MemStoreFlushSize 67108864 DefferedLogFlush FALSE ファミリー属性パラメータ 設定値 テーブル属性パラメータ 設定値 FileSizeMax 4294967296 ReadOnly FALSE ・ユーザーIDに対してレコメンドデータをリストで保存。 ・商品APIからとってきたデータをJSON形式のままそのままキャッシュ。 ⇒APIに負荷はかけたくない フィールド 値 サンプル値 テーブル名 ポンパレモール:商品詳細キャッシュテーブル テーブル概要 fs_mall_iteminfo 行キー 認証キーを含まないモールAPIへのリクエストパラメータ shopUrl=chatdor&itemManageId=ch-zakuro150&imgSize=96 フィールド 物理名 論理名 - カラムファミリー data データ カラム修飾子 detail 商品情報詳細 json形式で格納(2.5KB) Compression NONE CompactionCompression NONE Blocksize 65536 Scope 0 BlockCacheEnable TRUE InMemory FALSE BloomFilterType NONE テーブル属性パラメータ 設定値 FileSizeMax 4294967296 ReadOnly FALSE MemStoreFlushSize 67108864 DefferedLogFlush FALSE ファミリー属性パラメータ 設定値 TimeToLive 2147483647 MaxVersions 3
16.
裏側の仕組み 16 レコメンド用JSP Hadoop HBase 行動ログ モニタリング API 行動ログ(蓄積) DWH・Hadoopクラスタ 事業データ 事業データ ディスプレイ API
レコメンド API レコメンドデータ レコメンドデータ 作成バッチ ログ蓄積 API ログ蓄積 バッチ ※現在絶賛改装中のため、構成は日々変わっています このあたり
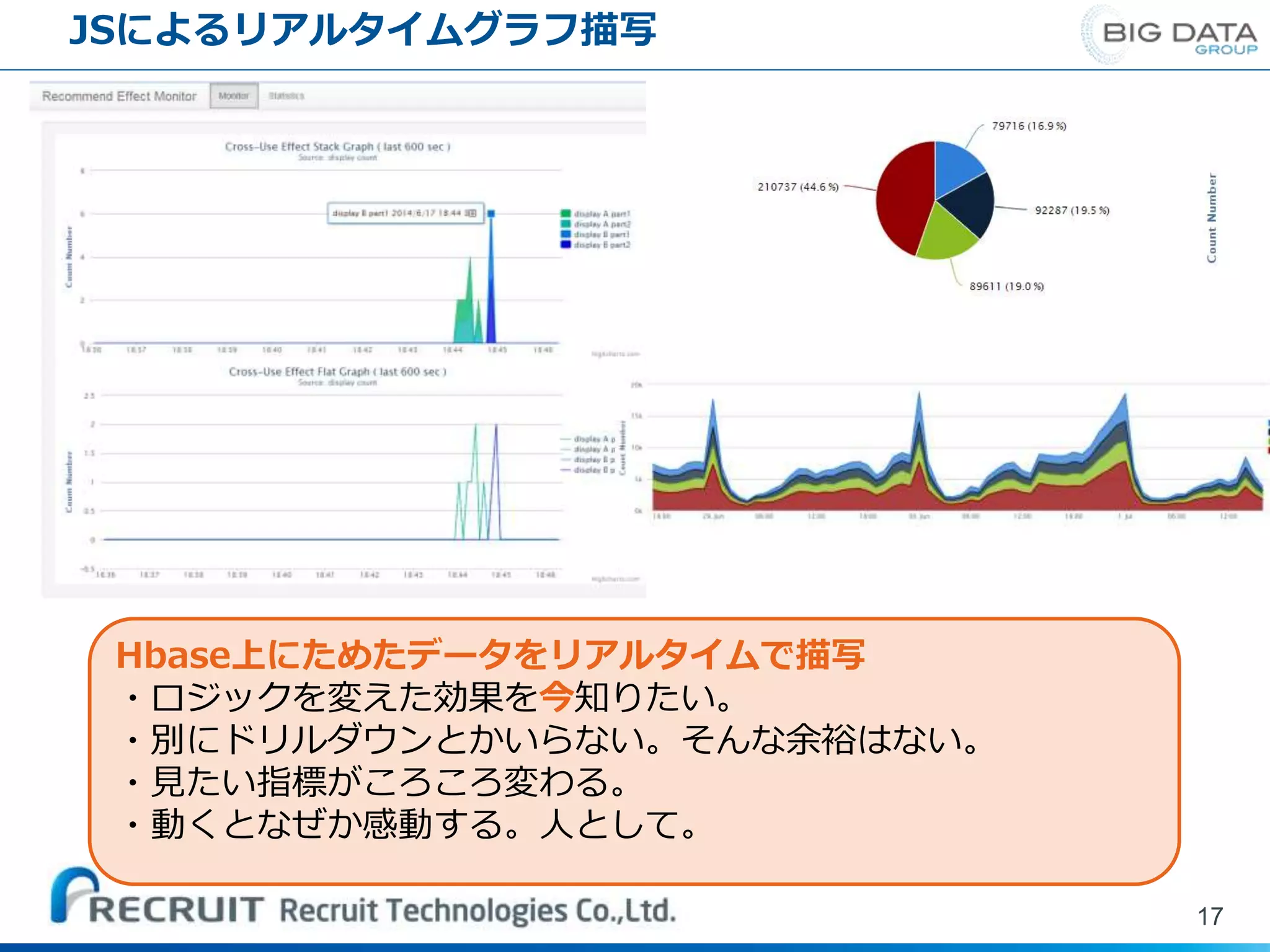
17.
JSによるリアルタイムグラフ描写 17 Hbase上にためたデータをリアルタイムで描写 ・ロジックを変えた効果を今知りたい。 ・別にドリルダウンとかいらない。そんな余裕はない。 ・見たい指標がころころ変わる。 ・動くとなぜか感動する。人として。
18.
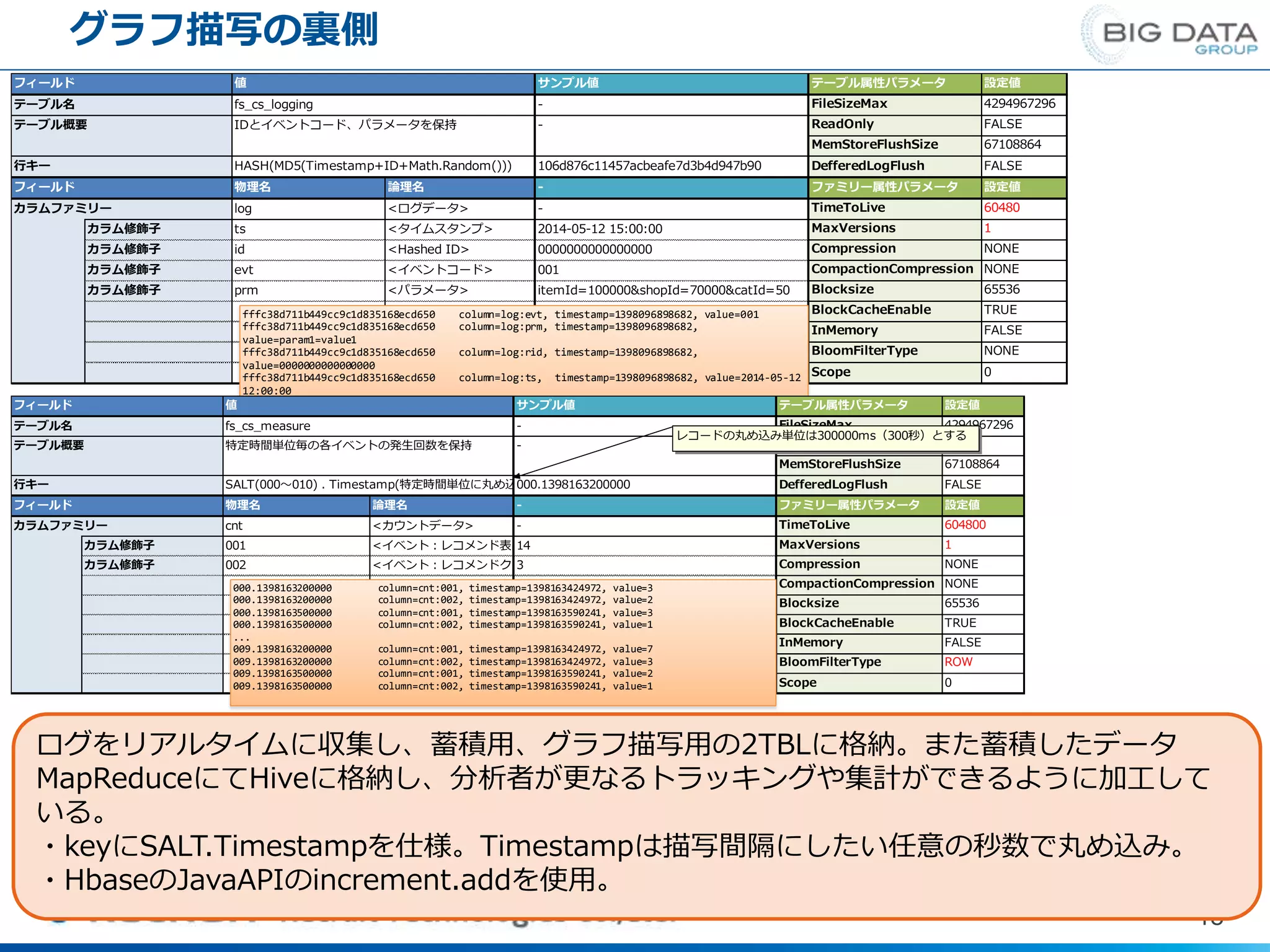
グラフ描写の裏側 18 ログをリアルタイムに収集し、蓄積用、グラフ描写用の2TBLに格納。また蓄積したデータ MapReduceにてHiveに格納し、分析者が更なるトラッキングや集計ができるように加工して いる。 ・keyにSALT.Timestampを仕様。Timestampは描写間隔にしたい任意の秒数で丸め込み。 ・HbaseのJavaAPIのincrement.addを使用。 フィールド 値 サンプル値 テーブル名
fs_cs_logging - テーブル概要 IDとイベントコード、パラメータを保持 - 行キー HASH(MD5(Timestamp+ID+Math.Random())) 106d876c11457acbeafe7d3b4d947b90 フィールド 物理名 論理名 - カラムファミリー log <ログデータ> - カラム修飾子 ts <タイムスタンプ> 2014-05-12 15:00:00 カラム修飾子 id <Hashed ID> 0000000000000000 カラム修飾子 evt <イベントコード> 001 カラム修飾子 prm <パラメータ> itemId=100000&shopId=70000&catId=50 BlockCacheEnable TRUE 設定値 Blocksize ReadOnly NONE FALSE NONE 1 CompactionCompression テーブル属性パラメータ 設定値 FileSizeMax 4294967296 TimeToLive 60480 67108864 FALSE MemStoreFlushSize ファミリー属性パラメータ Scope 0 Compression DefferedLogFlush InMemory BloomFilterType NONE 65536 MaxVersions FALSE fffc38d711b449cc9c1d835168ecd650 column=log:evt, timestamp=1398096898682, value=001 fffc38d711b449cc9c1d835168ecd650 column=log:prm, timestamp=1398096898682, value=param1=value1 fffc38d711b449cc9c1d835168ecd650 column=log:rid, timestamp=1398096898682, value=0000000000000000 fffc38d711b449cc9c1d835168ecd650 column=log:ts, timestamp=1398096898682, value=2014-05-12 12:00:00 ... fffc38d711b449cc9c1d835168ecd650 column=log:evt, timestamp=1398096898682, value=001 fffc38d711b449cc9c1d835168ecd650 column=log:prm, timestamp=1398096898682, フィールド 値 サンプル値 テーブル名 fs_cs_measure - テーブル概要 特定時間単位毎の各イベントの発生回数を保持 - 行キー SALT(000~010) . Timestamp(特定時間単位に丸め込まれている)000.1398163200000 フィールド 物理名 論理名 - カラムファミリー cnt <カウントデータ> - カラム修飾子 001 <イベント:レコメンド表出>14 カラム修飾子 002 <イベント:レコメンドクリック>3 InMemory FALSE BloomFilterType ROW Scope 0 CompactionCompression NONE Blocksize 65536 BlockCacheEnable TRUE TimeToLive 604800 MaxVersions 1 Compression NONE MemStoreFlushSize 67108864 DefferedLogFlush FALSE ファミリー属性パラメータ 設定値 テーブル属性パラメータ 設定値 FileSizeMax 4294967296 ReadOnly FALSE 000.1398163200000 column=cnt:001, timestamp=1398163424972, value=3 000.1398163200000 column=cnt:002, timestamp=1398163424972, value=2 000.1398163500000 column=cnt:001, timestamp=1398163590241, value=3 000.1398163500000 column=cnt:002, timestamp=1398163590241, value=1 ... 009.1398163200000 column=cnt:001, timestamp=1398163424972, value=7 009.1398163200000 column=cnt:002, timestamp=1398163424972, value=3 009.1398163500000 column=cnt:001, timestamp=1398163590241, value=2 009.1398163500000 column=cnt:002, timestamp=1398163590241, value=1 レコードの丸め込み単位は300000ms(300秒)とする
19.
Hbaseをもっと活かしたい! 19 リアルタイムに蓄積されたデータをロジックに フィードバックする。 もっと非構造データを格納し、利用する。 ストリーム処理に対するキャッシュ機構。
20.
20 データ解析基盤について
21.
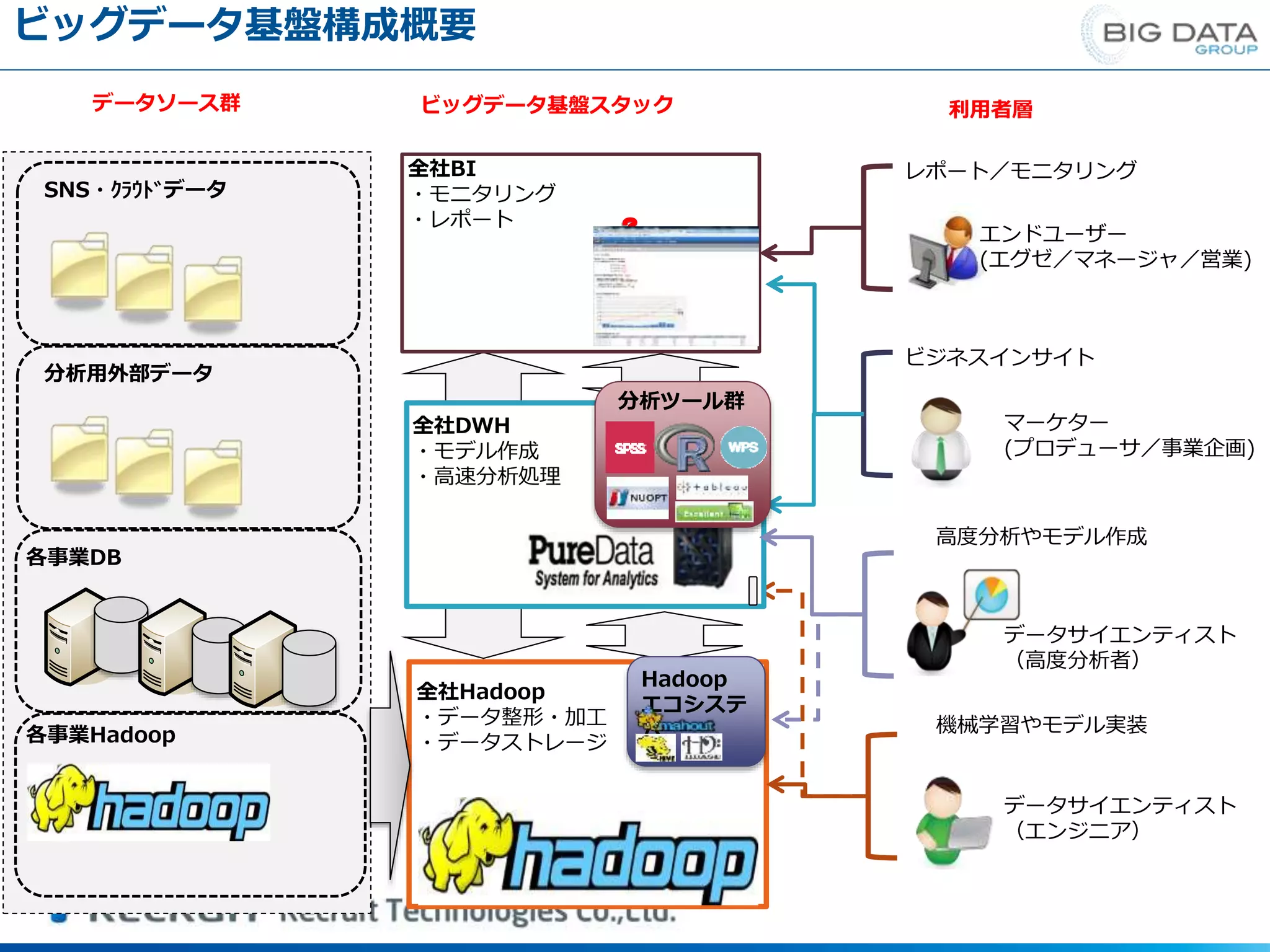
全社Hadoop ・データ整形・加工 ・データストレージ 各事業DB 全社DWH ・モデル作成 ・高速分析処理 全社BI ・モニタリング ・レポート 各事業Hadoop 分析用外部データ SNS・クラウドデータ データソース群 ビッグデータ基盤スタック 利用者層 高度分析やモデル作成 レポート/モニタリング エンドユーザー (エグゼ/マネージャ/営業) ビジネスインサイト マーケター (プロデューサ/事業企画) データサイエンティスト (高度分析者) 機械学習やモデル実装 データサイエンティスト (エンジニア) 分析ツール群 Hadoop エコシステ ム ビッグデータ基盤構成概要
22.
ビッグデータへの取り組み 2012年 Hadoop活用拡大 DWH導入展開 リアルタイム研究 分析と技術の組織統合 ほぼ全ての事業で Hadoopの活用を実施 ビッグデータ活用基盤 を拡充(DWH等) 2011年 Hadoopの本格展開 各サイトで本格展開を 開始、11事業40案件 に適用 Hadoopカンファレンス をR後援で開催 2010年 高速集計基盤の研究 Hadoopのリサーチを 開始、この段階の投資 は最小限に抑えサーバ はWebオークションで 調達 2013年 全社規模BI導入展開 全社データ集約環境 「TotalDB」の推進 リサーチ環境 第1世代Hadoop 第2世代Hadoop DWH BI基盤
23.
ビッグデータへの取り組み(2014年) 2014年 Nod e5 Nod e6 Nod e7 Nod e8 Nod e1 Nod e2 Nod e3 Nod e4 将来のあるべき姿から HW、アーキテクチャーなどを検討する 第三世代Hadoopの検討 ? アドホック分析基盤の導入
24.
24 技術導入の過程
25.
25 いつもの体制図 (「コンサル型」+「エンジニア型」)×マーケター コンサル型 エンジニア型 事業担当者 ≒マーケタービッグデータグループ Hadoopエンジニア 分析者
26.
26 データドリブンの意思決定・施策数が増加 カスタマサイド、クライアントサイド、メール、PUSH、社 内システム、社内帳票など利用シーンも多岐に。 施策ひとつひとつがより難易度高くかつ長期施策となり質が 増加。シナリオマーケ、リアルタイムレコメンド、テキスト 解析、機械学習などがお互い理解しやすくなった。 事業担当者 ≒マーケター の知識向上、データドリブン施策の 重要性が認識・拡散。 ここ数年での変化
27.
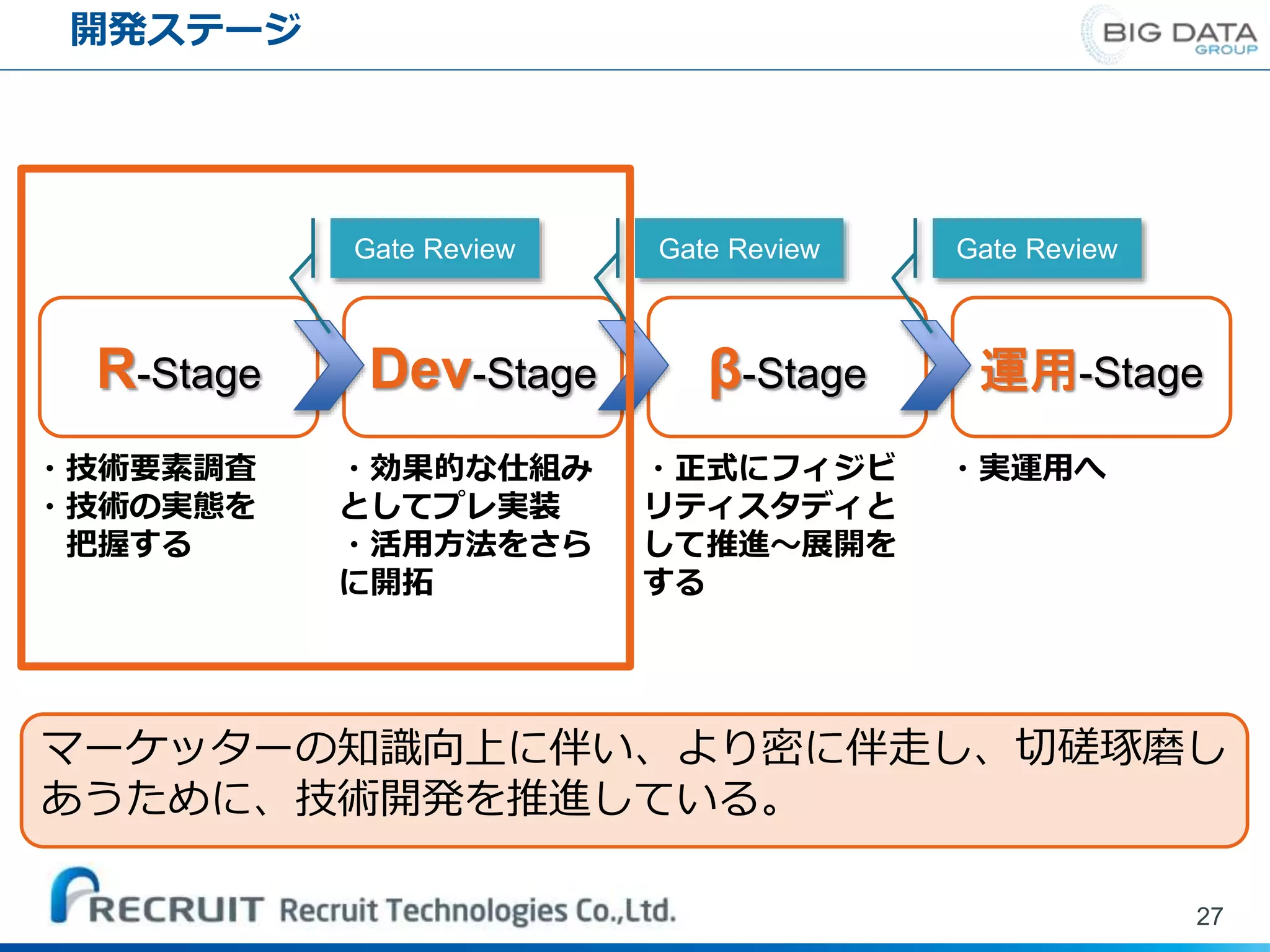
開発ステージ 27 R-Stage Dev-Stage β-Stage
運用-Stage ・技術要素調査 ・技術の実態を 把握する ・効果的な仕組み としてプレ実装 ・活用方法をさら に開拓 ・正式にフィジビ リティスタディと して推進~展開を する ・実運用へ Gate Review Gate Review Gate Review マーケッターの知識向上に伴い、より密に伴走し、切磋琢磨し あうために、技術開発を推進している。
28.
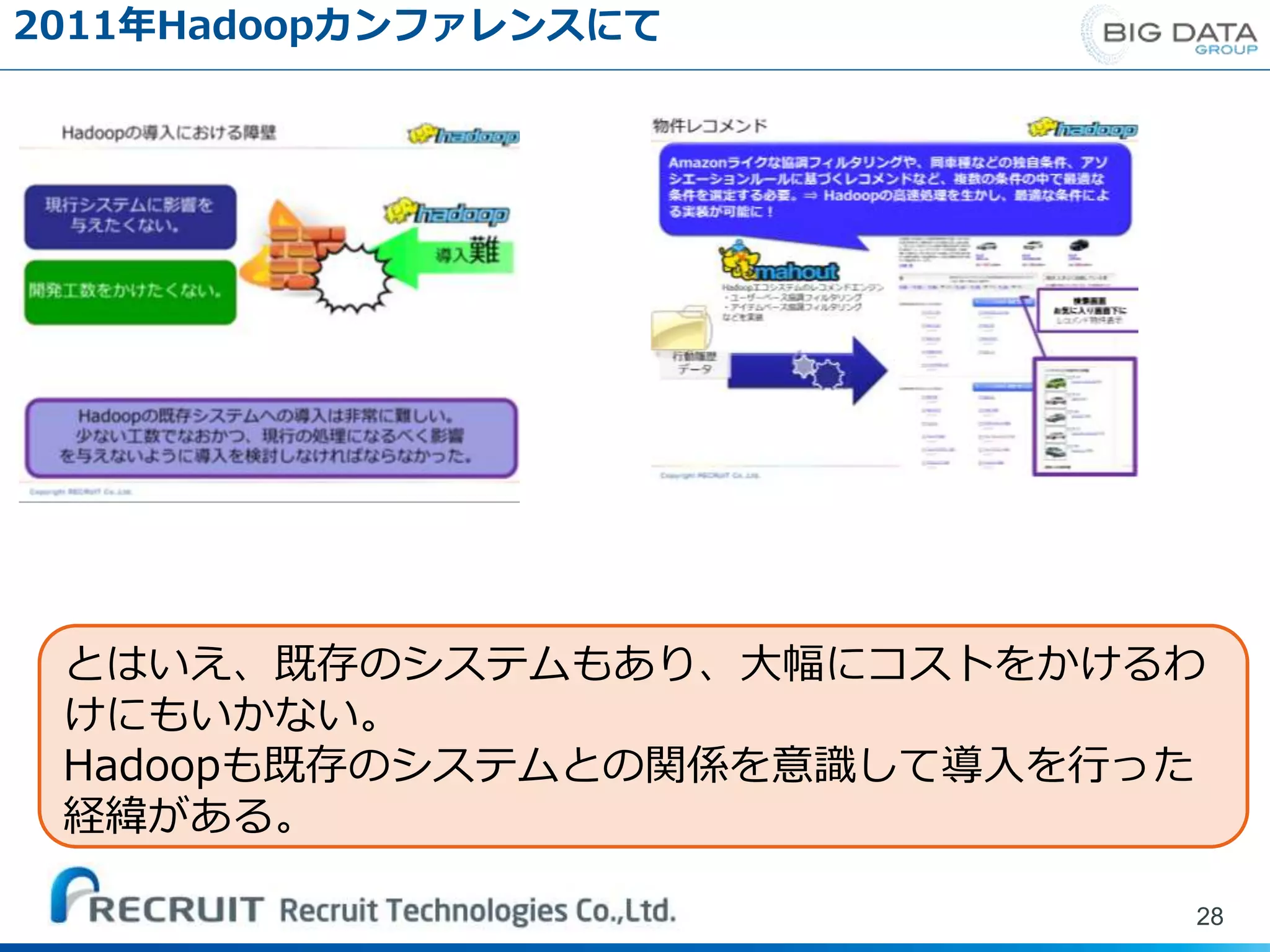
2011年Hadoopカンファレンスにて 28 とはいえ、既存のシステムもあり、大幅にコストをかけるわ けにもいかない。 Hadoopも既存のシステムとの関係を意識して導入を行った 経緯がある。
29.
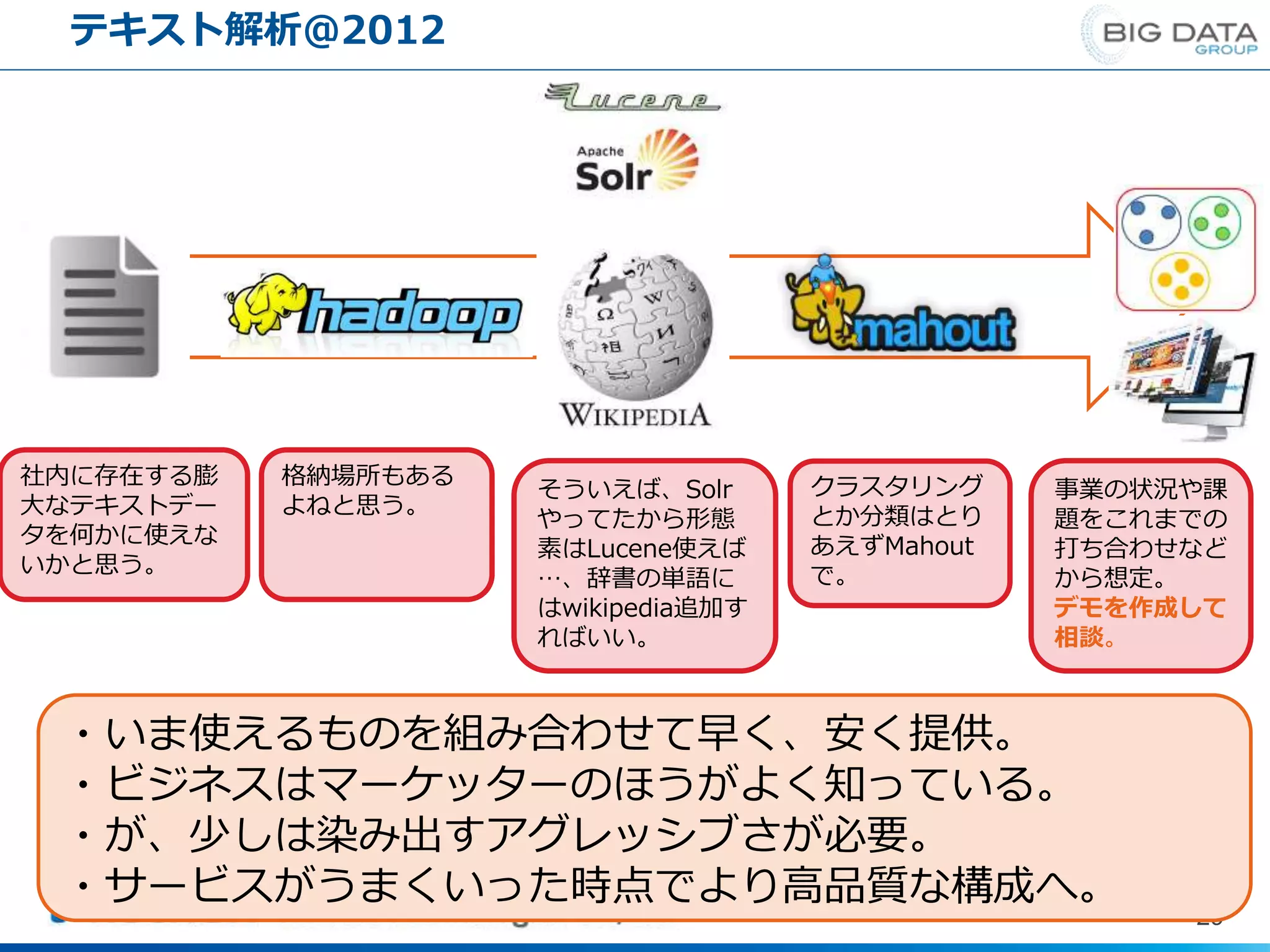
テキスト解析@2012 29 ・いま使えるものを組み合わせて早く、安く提供。 ・ビジネスはマーケッターのほうがよく知っている。 ・が、少しは染み出すアグレッシブさが必要。 ・サービスがうまくいった時点でより高品質な構成へ。 社内に存在する膨 大なテキストデー タを何かに使えな いかと思う。 格納場所もある よねと思う。 そういえば、Solr やってたから形態 素はLucene使えば …、辞書の単語に はwikipedia追加す ればいい。 クラスタリング とか分類はとり あえずMahout で。 事業の状況や課 題をこれまでの 打ち合わせなど から想定。 デモを作成して 相談。
30.
30 取り掛かり中の技術紹介
31.
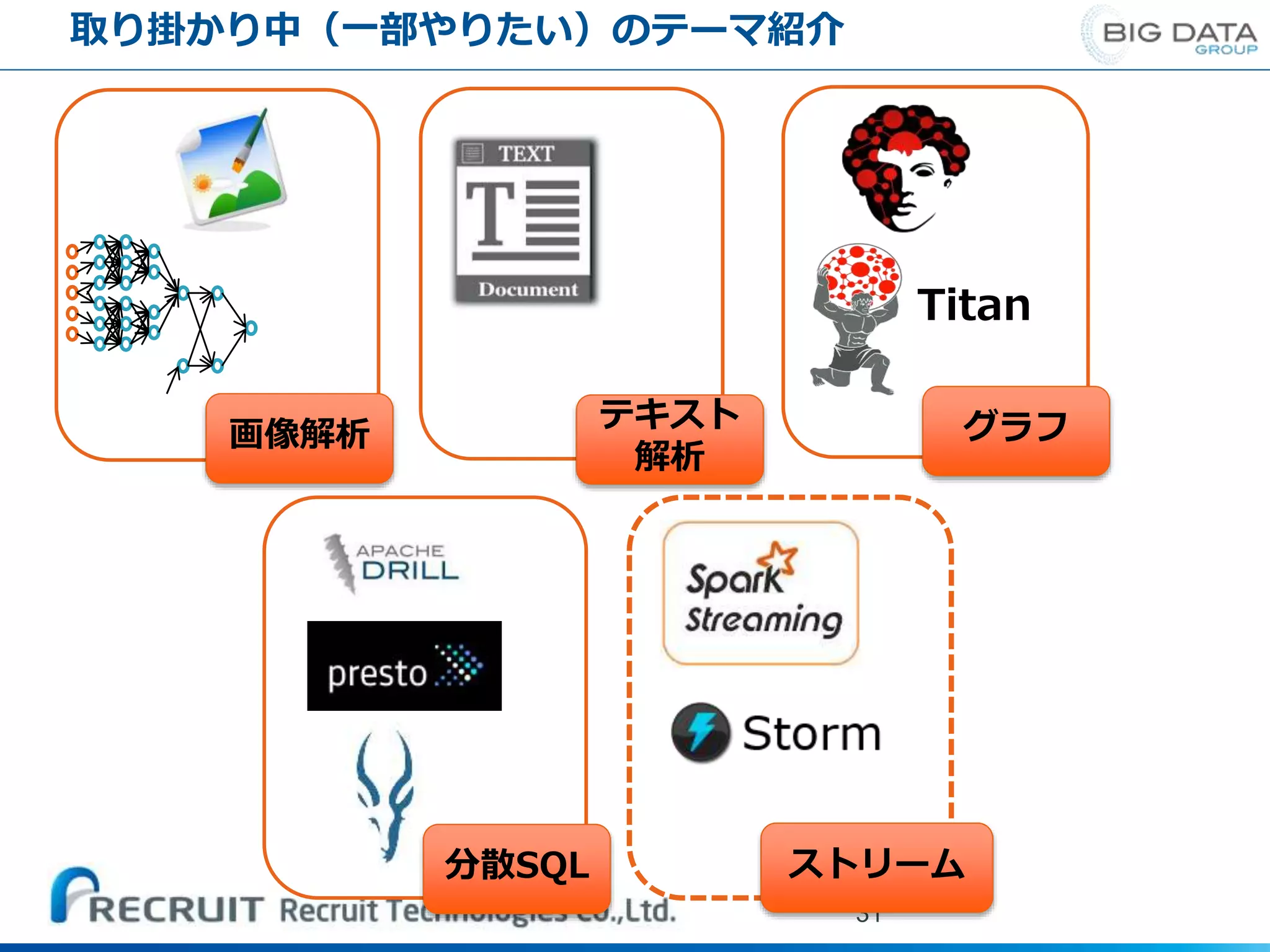
取り掛かり中(一部やりたい)のテーマ紹介 31 Titan グラフ画像解析 テキスト 解析 ストリーム分散SQL
32.
注意 32 http://ha-chi.biz/big.php?no=303 これから話す内容は あくまでも開発中のため、 実際にサービス化されるまで 詳細はお話できません。 世に出てからのお楽しみとしてください。
33.
社内に眠るデータの可能性 33 543 TB(レプリケート時) Hadoopに格納されているデータはまだわずか。 リクルート内はまだまだ大量のデータがさまざまな場所に散在 している。 ・原稿情報 ・営業日報 ・商品・店舗画像 ・位置情報 ・議事録 etc ただ、貯めるというだけでもコスト。 利用用途をある程度想定し、技術的 にも扱えることを想起しておかなけ ればならない。
34.
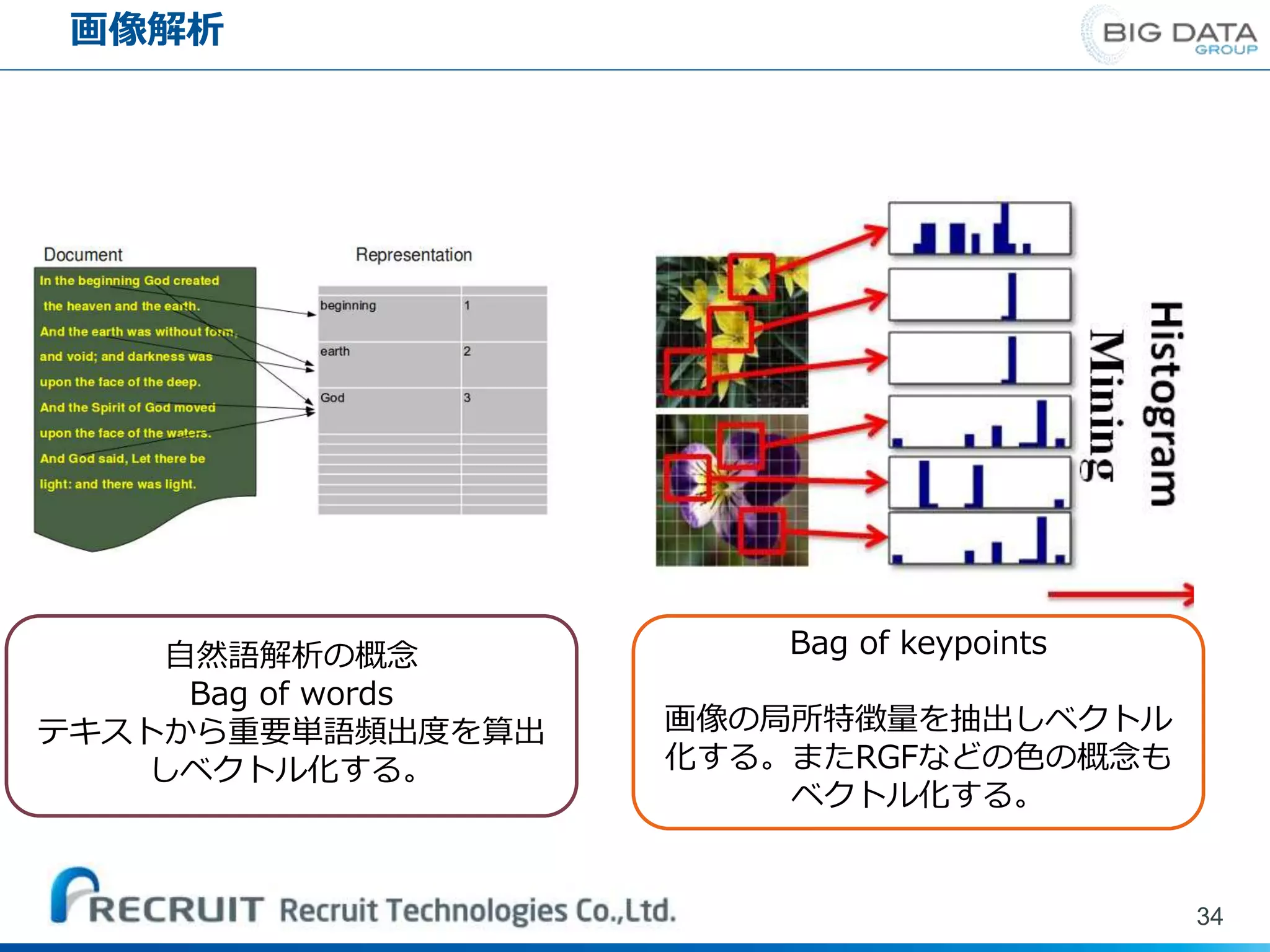
画像解析 34 自然語解析の概念 Bag of words テキストから重要単語頻出度を算出 しベクトル化する。 Bag
of keypoints 画像の局所特徴量を抽出しベクトル 化する。またRGFなどの色の概念も ベクトル化する。
35.
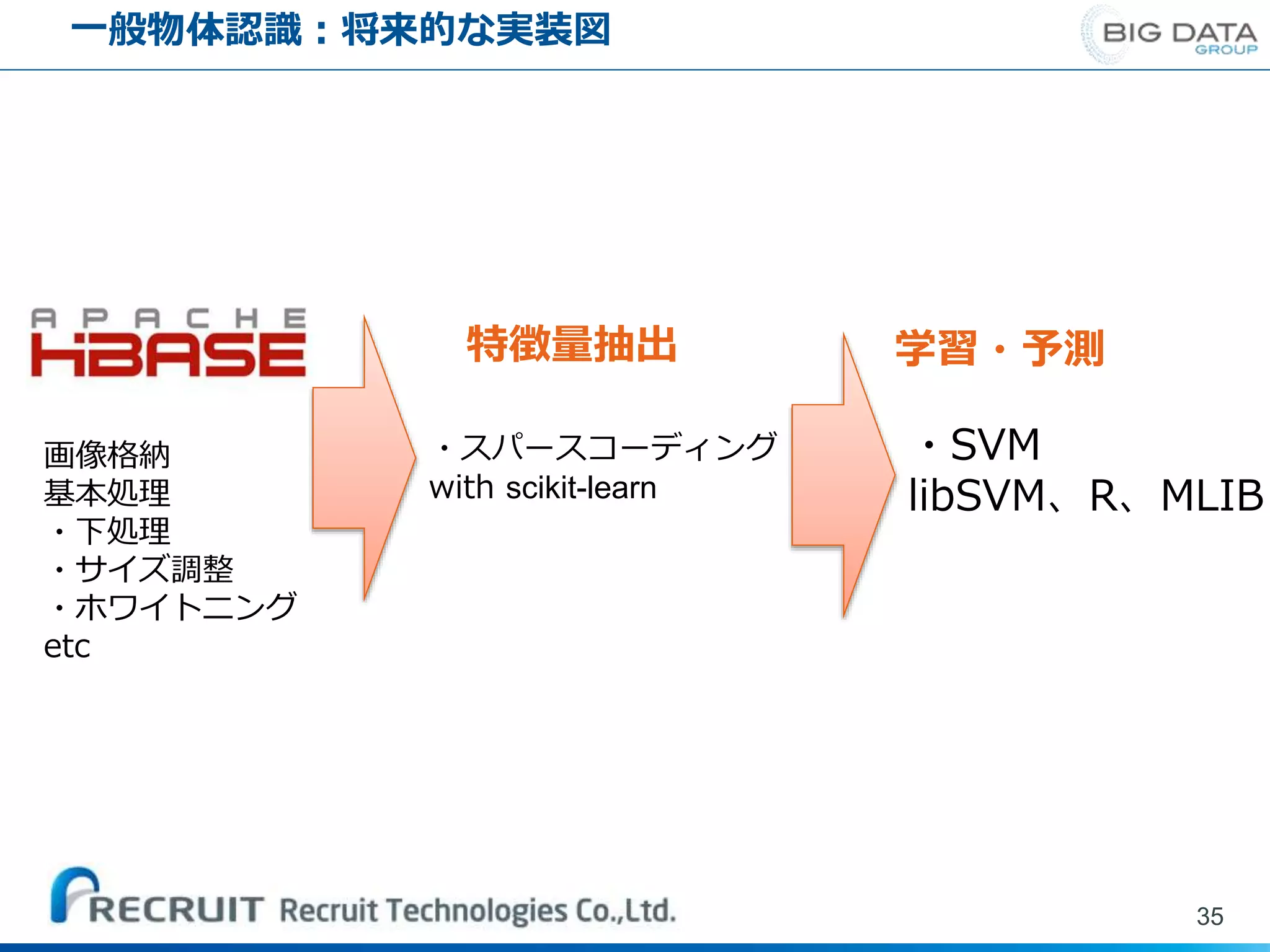
一般物体認識:将来的な実装図 35 画像格納 基本処理 ・下処理 ・サイズ調整 ・ホワイトニング etc 特徴量抽出 学習・予測 ・スパースコーディング with scikit-learn ・SVM libSVM、R、MLIB
36.
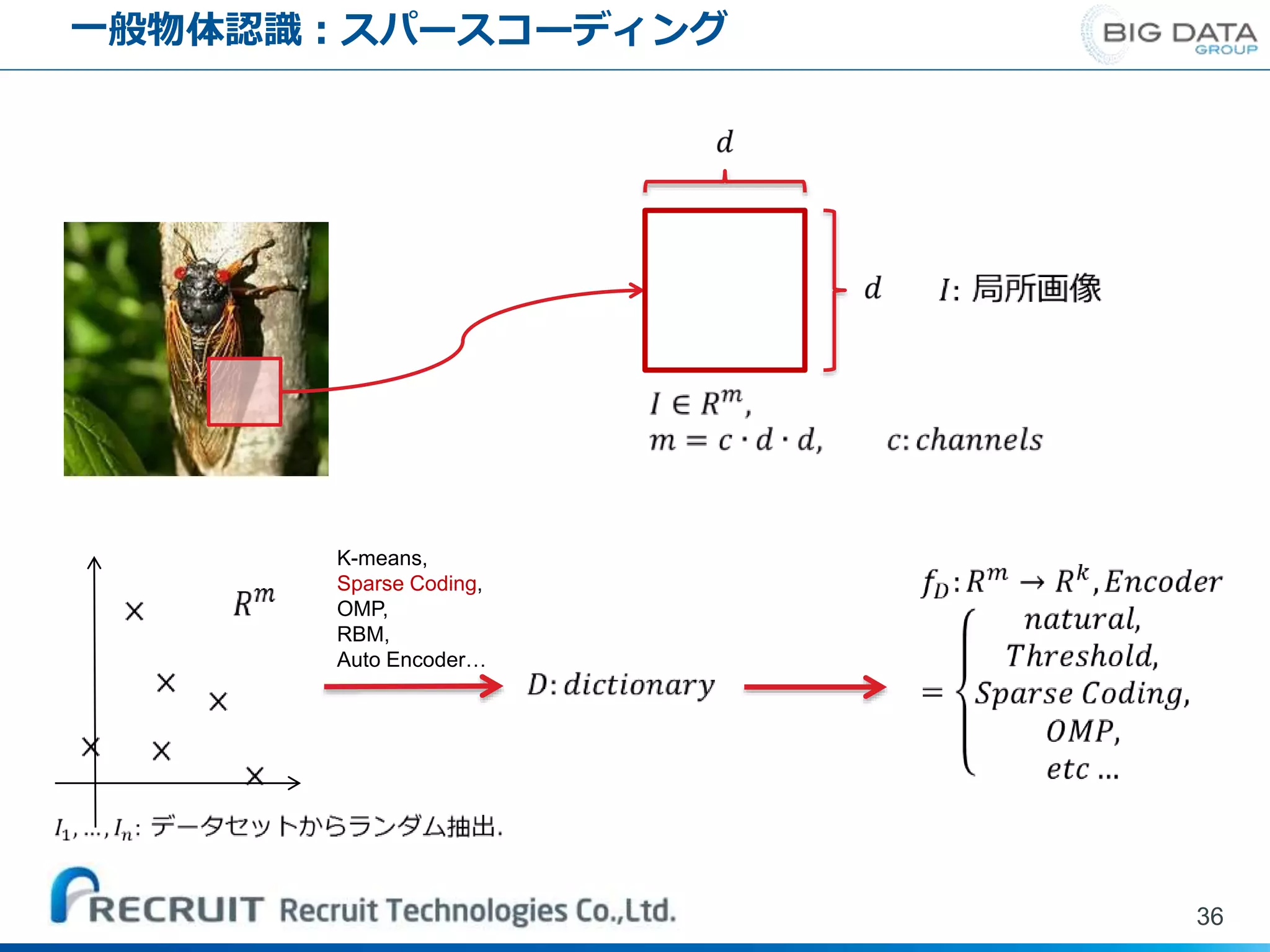
一般物体認識:スパースコーディング 36 K-means, Sparse Coding, OMP, RBM, Auto Encoder…
37.
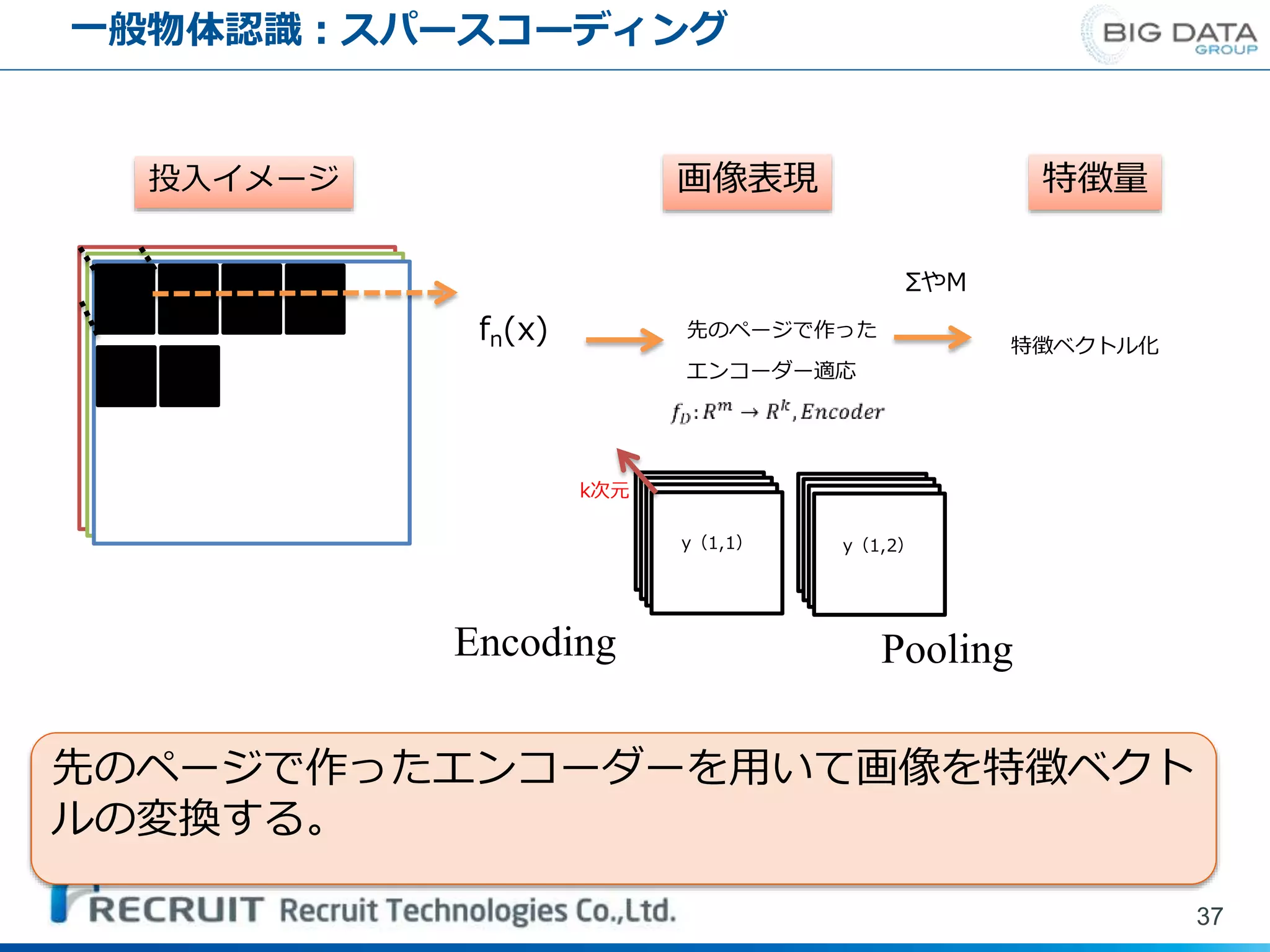
一般物体認識:スパースコーディング 37 Encoding Pooling fn(x) 先のページで作った エンコーダー適応 ΣやM 特徴ベクトル化 y(1,1)
y(1,2) k次元 先のページで作ったエンコーダーを用いて画像を特徴ベクト ルの変換する。 投入イメージ 画像表現 特徴量
38.
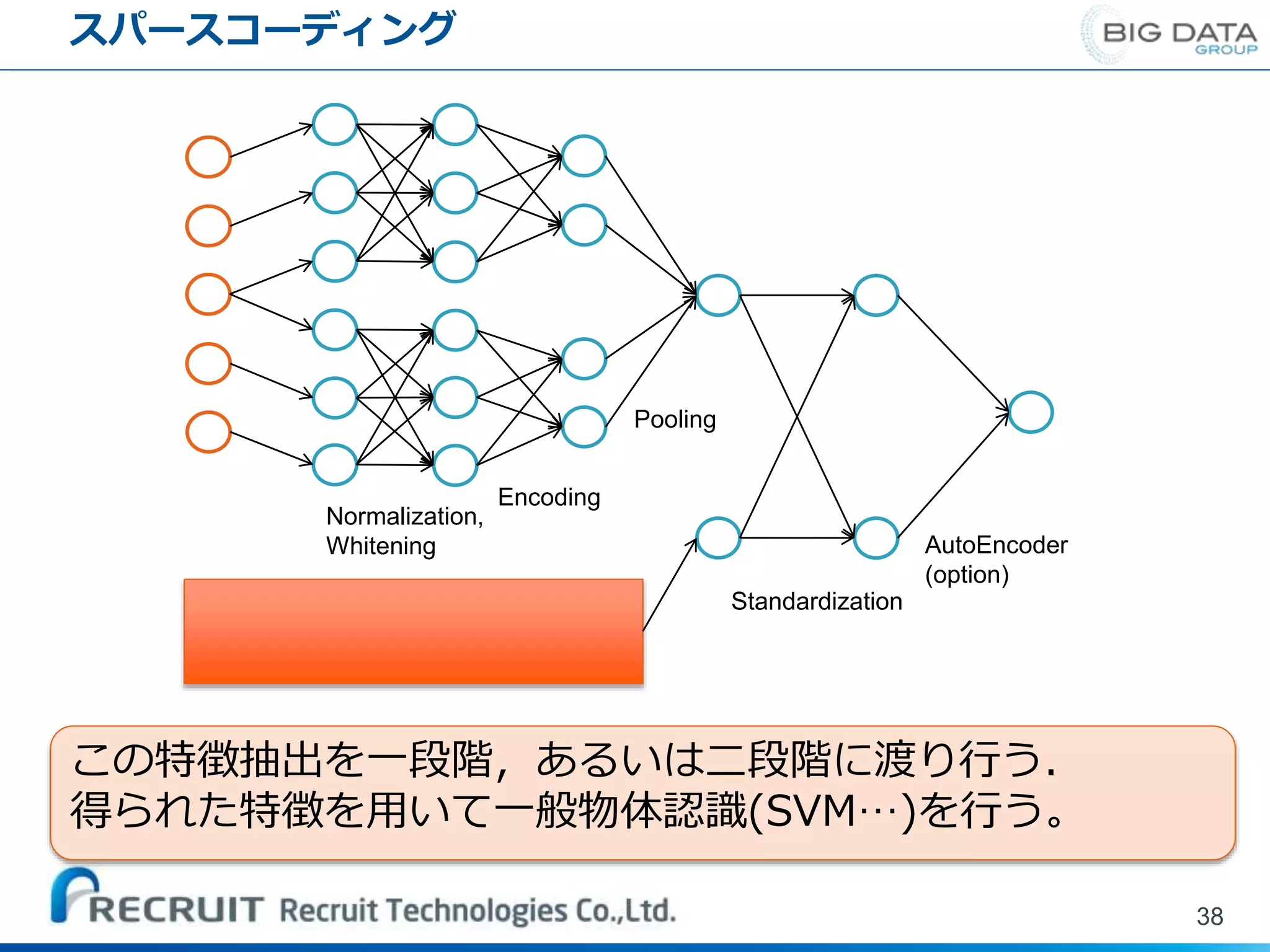
スパースコーディング 38 Normalization, Whitening Encoding Pooling Standardization AutoEncoder (option) この特徴抽出を一段階,あるいは二段階に渡り行う. 得られた特徴を用いて一般物体認識(SVM…)を行う。
39.
利用展開予定 39 画像に自動でタグをつけることで検索効率をあげる。 ※往々にして人手で入力するのはコストがかかる。 類似画像を検索できる。 カラーヒストグラムなどをベクトル演算に加え、「色」や 「形状」による検索をできるようにする。
40.
テキスト解析のNEXT 40 これまで様々なテキスト分析を行ってきた。 ・TF-IDF⇒LDAによるTopicクラスタリング ・TF-IDF⇒SVM、RandomForestによる分類 ・係り受け分析 ・文章要約 割と一過性のレポートであったり、レコメンドの1変数作成程 度の利用が多かった。 まだまだテキストデータの可能性を出し切れておらず、もう 少し機械学習チックに利用しサービスに役立てたいと考えて いる。 (競合スタートアップも出始めているので。)
41.
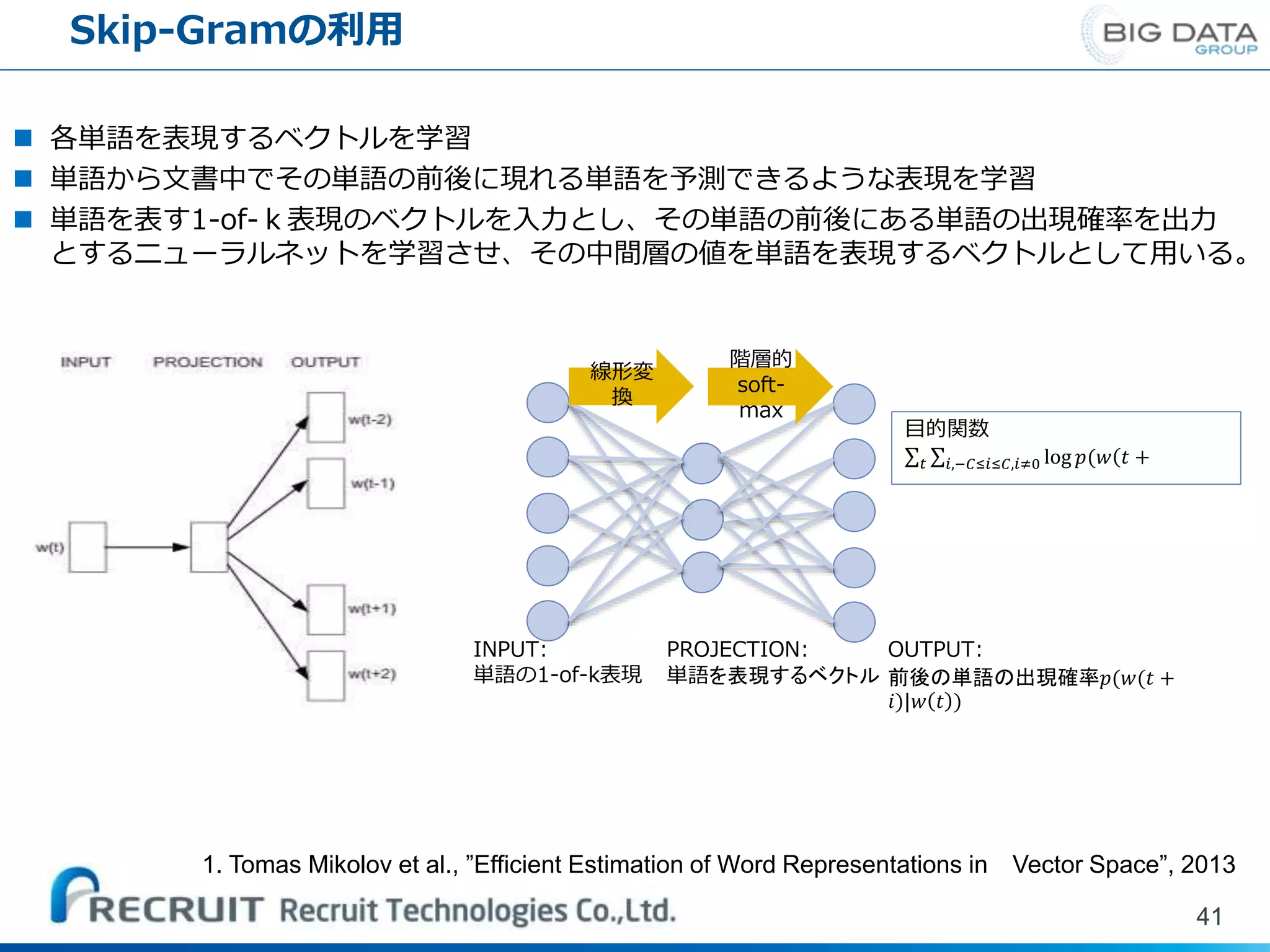
Skip-Gramの利用 41 各単語を表現するベクトルを学習 単語から文書中でその単語の前後に現れる単語を予測できるような表現を学習
単語を表す1-of-k表現のベクトルを入力とし、その単語の前後にある単語の出現確率を出力 とするニューラルネットを学習させ、その中間層の値を単語を表現するベクトルとして用いる。 目的関数 𝑡 𝑖,−𝐶≤𝑖≤𝐶,𝑖≠0 log 𝑝(𝑤(𝑡 + OUTPUT: 前後の単語の出現確率𝑝(𝑤(𝑡 + 𝑖)|𝑤 𝑡 ) INPUT: 単語の1-of-k表現 PROJECTION: 単語を表現するベクトル 線形変 換 階層的 soft- max 1. Tomas Mikolov et al., ”Efficient Estimation of Word Representations in Vector Space”, 2013
42.
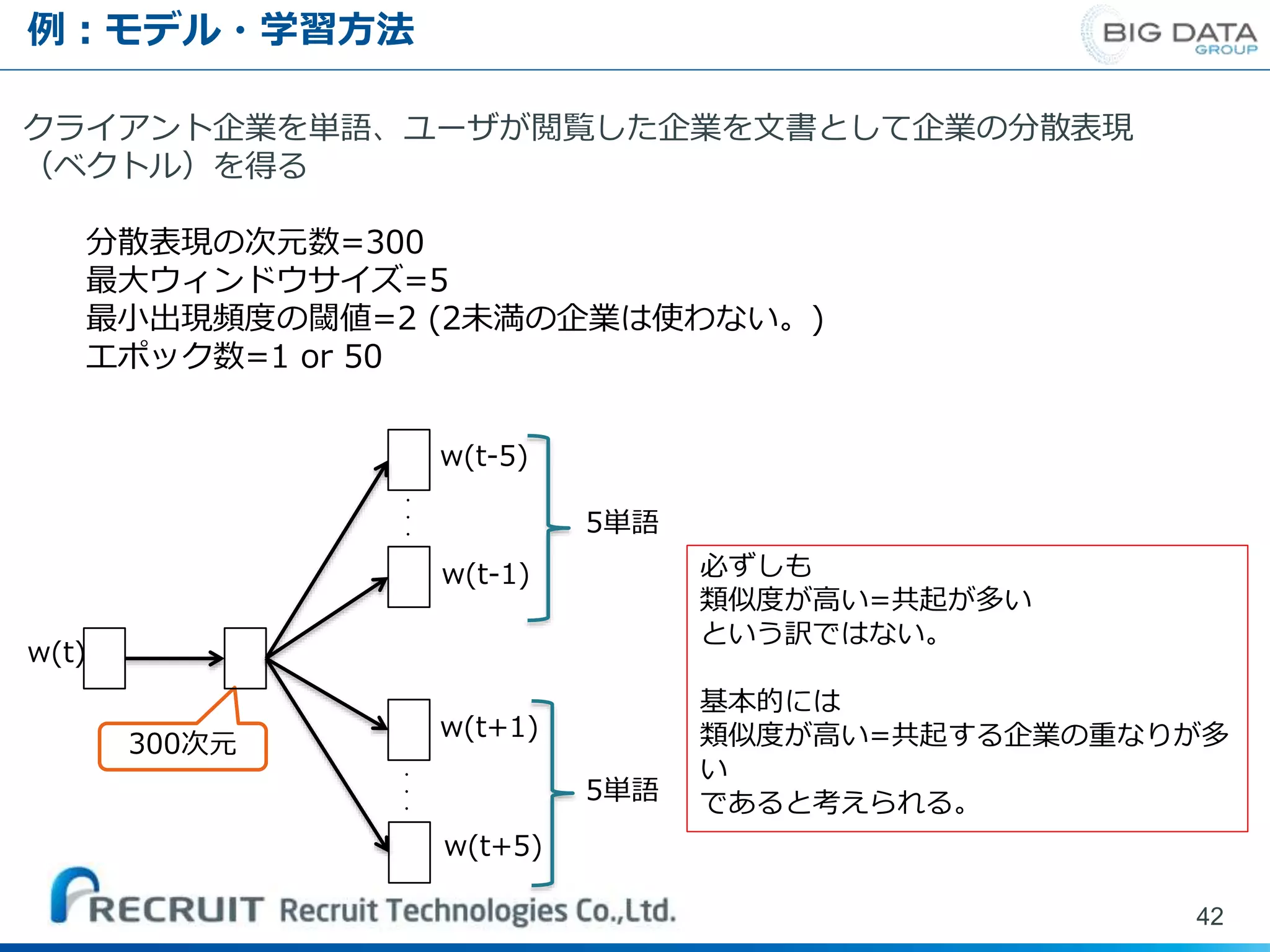
例:モデル・学習方法 42 クライアント企業を単語、ユーザが閲覧した企業を文書として企業の分散表現 (ベクトル)を得る 分散表現の次元数=300 最大ウィンドウサイズ=5 最小出現頻度の閾値=2 (2未満の企業は使わない。) エポック数=1 or
50 ・ ・ ・ 300次元 ・ ・ ・ 5単語 5単語 w(t) w(t-1) w(t+1) w(t+5) w(t-5) 必ずしも 類似度が高い=共起が多い という訳ではない。 基本的には 類似度が高い=共起する企業の重なりが多 い であると考えられる。
43.
利用展開予定 43 単語をベクトル表現できるところが大変面白い。 よってベクトル計算によるクラスタリングや距離計算ができ る。 ベクトル化された単語の足し引きによって本人が気づきにく い潜在的なレコメンドができる…はず。
44.
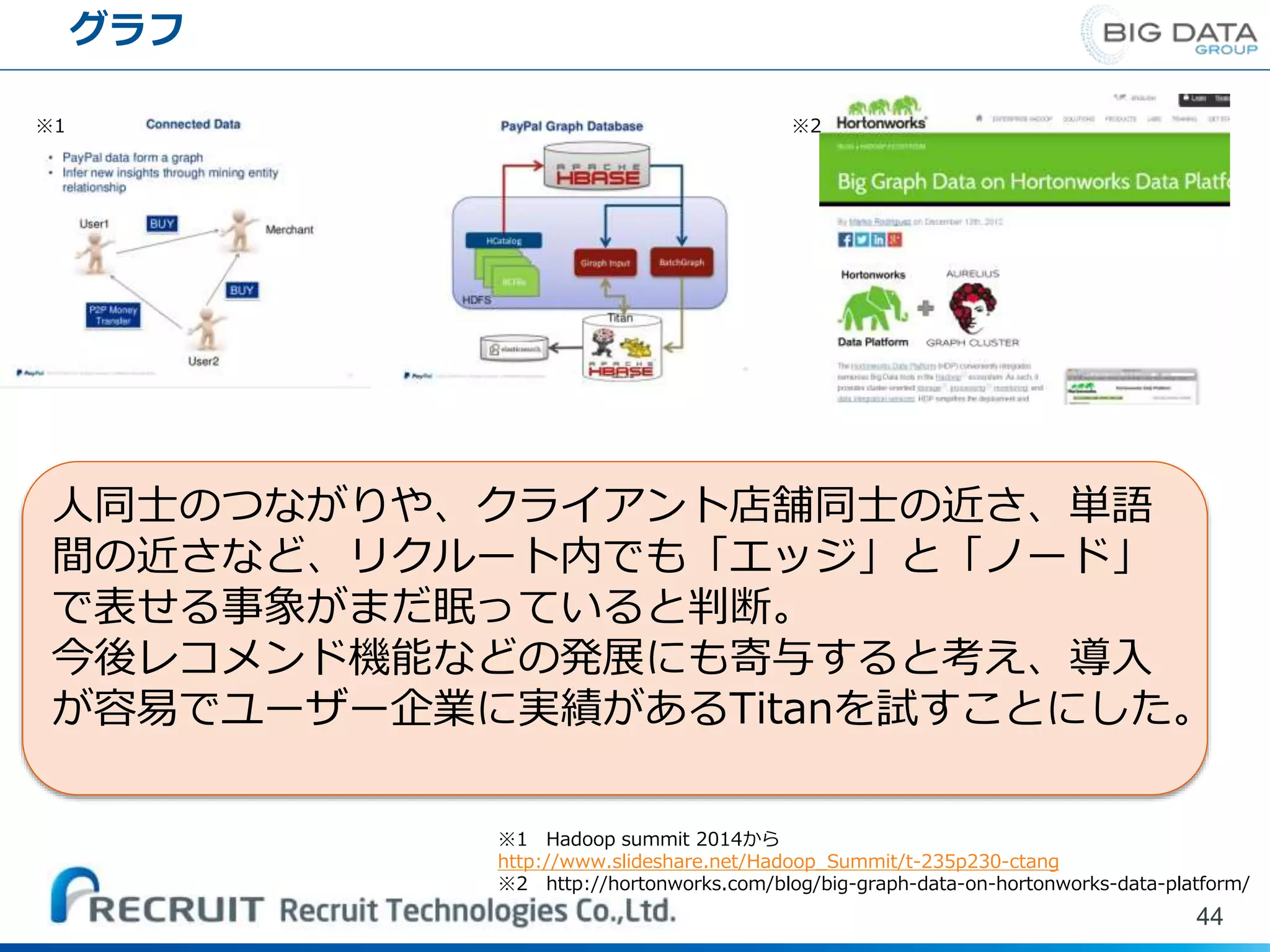
グラフ 44 ※1 Hadoop summit
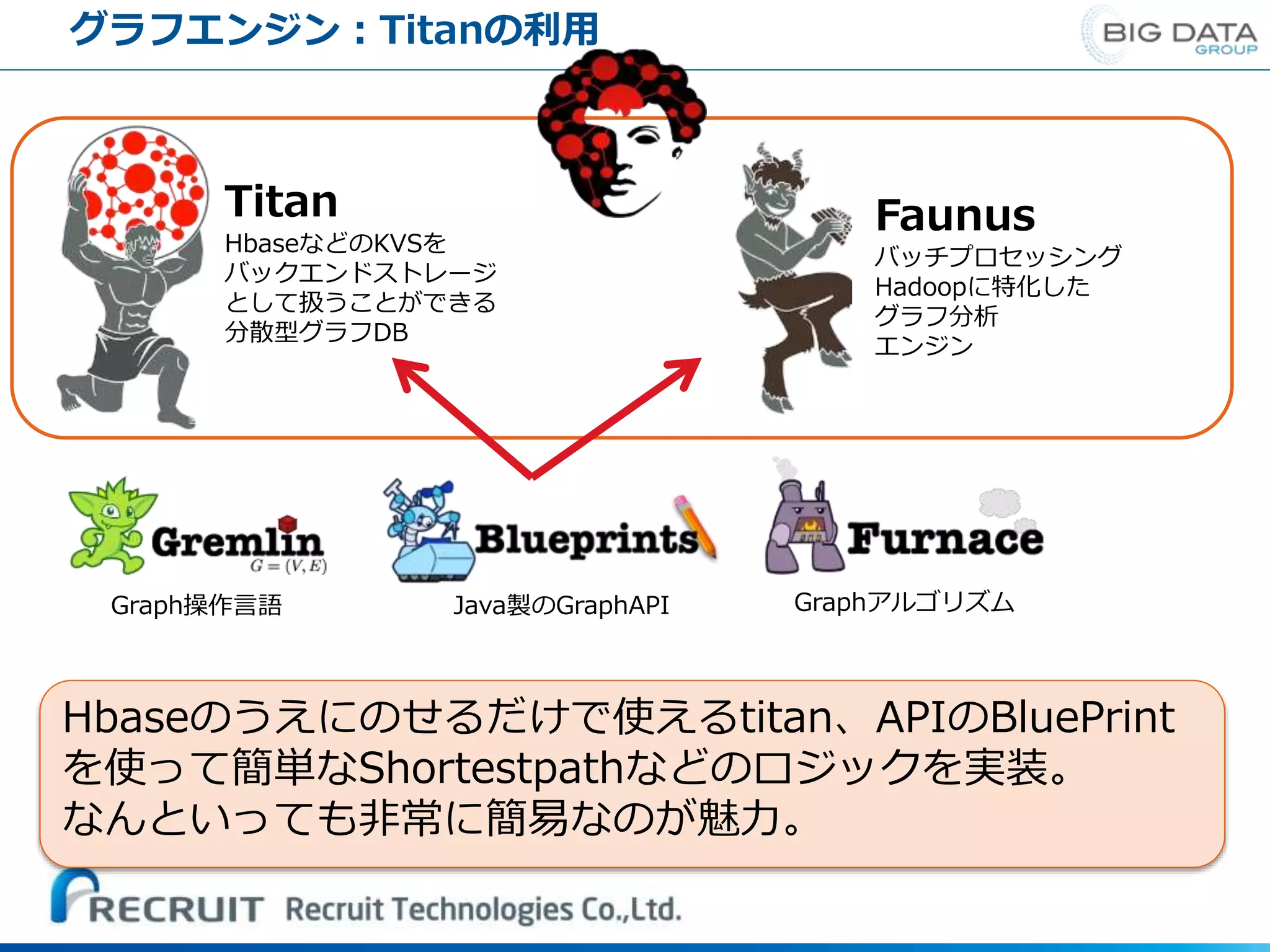
2014から http://www.slideshare.net/Hadoop_Summit/t-235p230-ctang ※2 http://hortonworks.com/blog/big-graph-data-on-hortonworks-data-platform/ ※1 ※2 人同士のつながりや、クライアント店舗同士の近さ、単語 間の近さなど、リクルート内でも「エッジ」と「ノード」 で表せる事象がまだ眠っていると判断。 今後レコメンド機能などの発展にも寄与すると考え、導入 が容易でユーザー企業に実績があるTitanを試すことにした。
45.
Titan HbaseなどのKVSを バックエンドストレージ として扱うことができる 分散型グラフDB Faunus バッチプロセッシング Hadoopに特化した グラフ分析 エンジン Java製のGraphAPI グラフエンジン:Titanの利用 GraphアルゴリズムGraph操作言語 Hbaseのうえにのせるだけで使えるtitan、APIのBluePrint を使って簡単なShortestpathなどのロジックを実装。 なんといっても非常に簡易なのが魅力。
46.
46 Titan・Gremlinコンソール画面
47.
サンプルデモ
48.
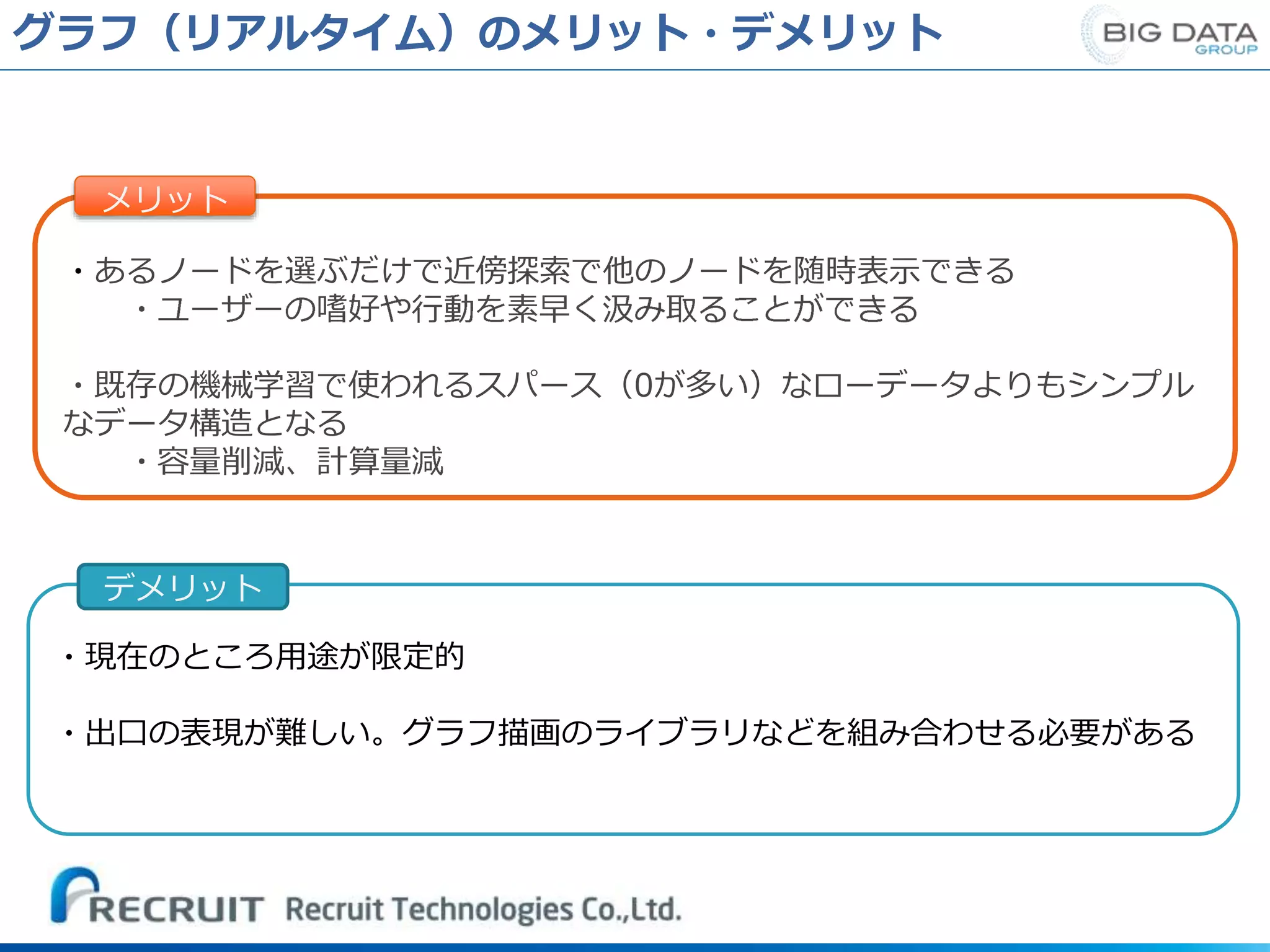
グラフ(リアルタイム)のメリット・デメリット ・あるノードを選ぶだけで近傍探索で他のノードを随時表示できる ・既存の機械学習で使われるスパース(0が多い)なローデータよりもシンプル なデータ構造となる メリット ・現在のところ用途が限定的 ・出口の表現が難しい。グラフ描画のライブラリなどを組み合わせる必要がある デメリット
49.
Hiveの使用が多い 49 28,344 295 1日あたりの全JOBの数 1日あたりの全WebHiveクエリの数 リクルートでもっとも使われているエコシステム はHiveである。MapRedcue直書きは少ない。 社内でのSQLクエリとの親和性は高く、その高速化は課題である。 ※Sparkよりも優先したい理由もここにある。
50.
製品名 Presto Drill
Impala 提供元 Facebook社 Apache プロジェクト(MapR 社) Cloudera社 問合せ言語 SQL SQL、DrQL、MongoQL、DSL HiveQL データソース Hive(CDH4、Apache Hadoop 1.x/2.x)、Cassandra (プラガブル) HDFS、Hbase、MapR、 MongoDB、Cassandra、 RDBMS、等 (プラガブル) HDFS、Hbase 接続方法 JDBC REST、JDBC、ODBC JDBC、ODBC 実装言語 Java Java C++ ライセンス Apache License 2.0 Apache License 2.0 Apache License 所感 ・そこまで早くない。小規模カウ ントなどはHiveに負けることが ある。 ・CREATE TABLEや大規模テー ブルの自己結合でエラーが発生し ている ・MapRの公式サポートなし。 ・独立で構築可能、かつプラガブ ルは柔軟性が高く、リクルートで は余剰リソース活用で相性がよい かもしれない。 ・βプログラム参加予定 ・米MapR社から継続的に情報を 入手しており、それを聞くぶんに は正直一番期待している。 ・Hiveを(一部を除いて)単純 に移行できるのは敷居が低い。 ・Hiveに対して5~10倍程度、安 定的に速い ・柔軟性にかける。 クラスタ環境 Hadoopとは独立で構築可能 Hadoopとは独立で構築可能 Hadoopクラスタ上に構築 分散SQL比較 50
51.
処理時間比較:Hive VS Presto
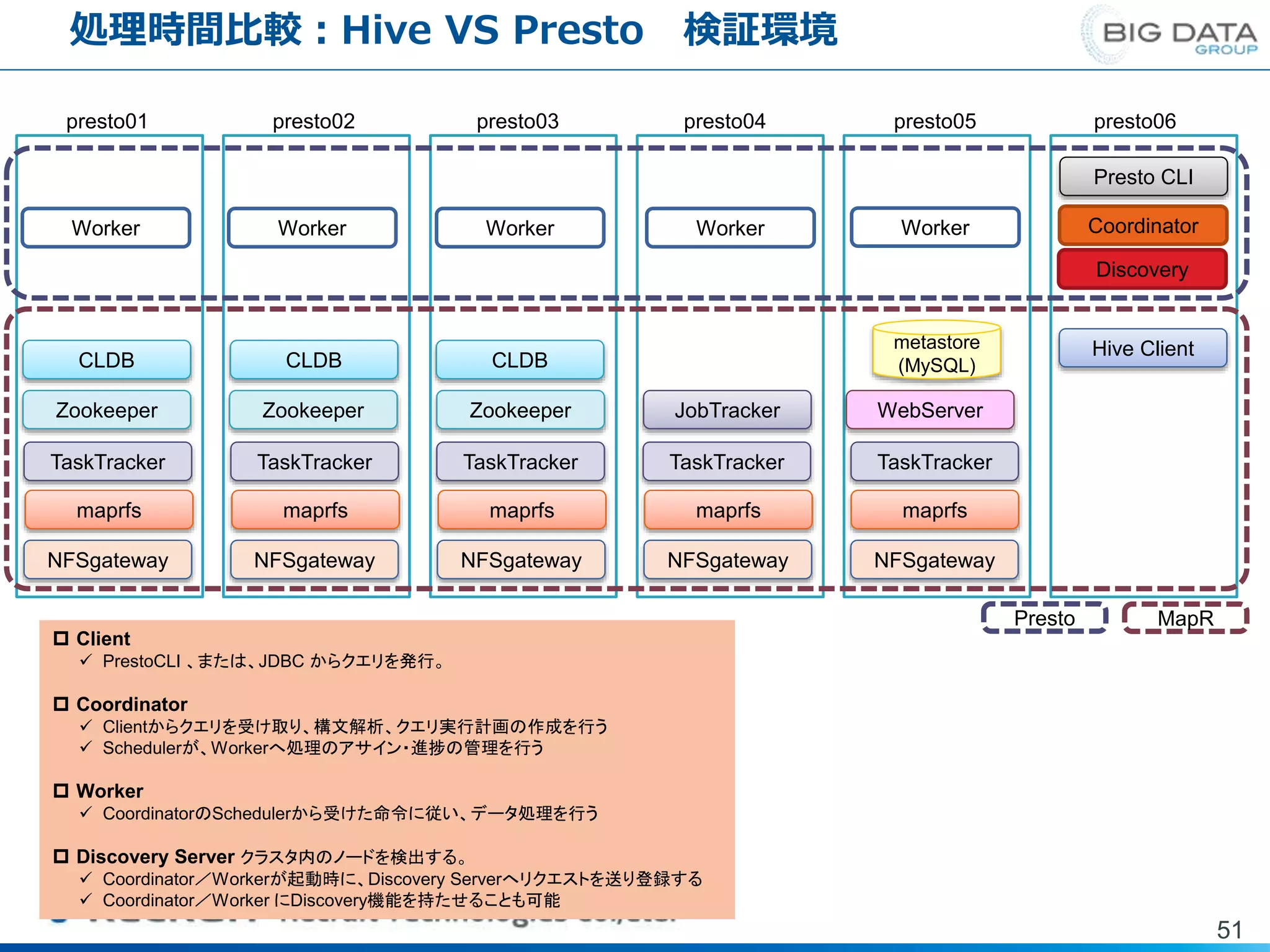
検証環境 51 presto01 presto02 presto03 presto04 presto05 presto06 CLDB CLDB CLDB Zookeeper Zookeeper Zookeeper JobTracker TaskTracker TaskTracker TaskTracker TaskTracker TaskTracker maprfs maprfs maprfs maprfs maprfs NFSgateway NFSgateway NFSgateway NFSgateway NFSgateway WebServer metastore (MySQL) Presto CLI Worker Worker Worker Worker Coordinator Discovery Presto MapR Hive Client Worker Client PrestoCLI 、または、JDBC からクエリを発行。 Coordinator Clientからクエリを受け取り、構文解析、クエリ実行計画の作成を行う Schedulerが、Workerへ処理のアサイン・進捗の管理を行う Worker CoordinatorのSchedulerから受けた命令に従い、データ処理を行う Discovery Server クラスタ内のノードを検出する。 Coordinator/Workerが起動時に、Discovery Serverへリクエストを送り登録する Coordinator/Worker にDiscovery機能を持たせることも可能
52.
処理時間比較:Hive VS Presto 52 処理番号
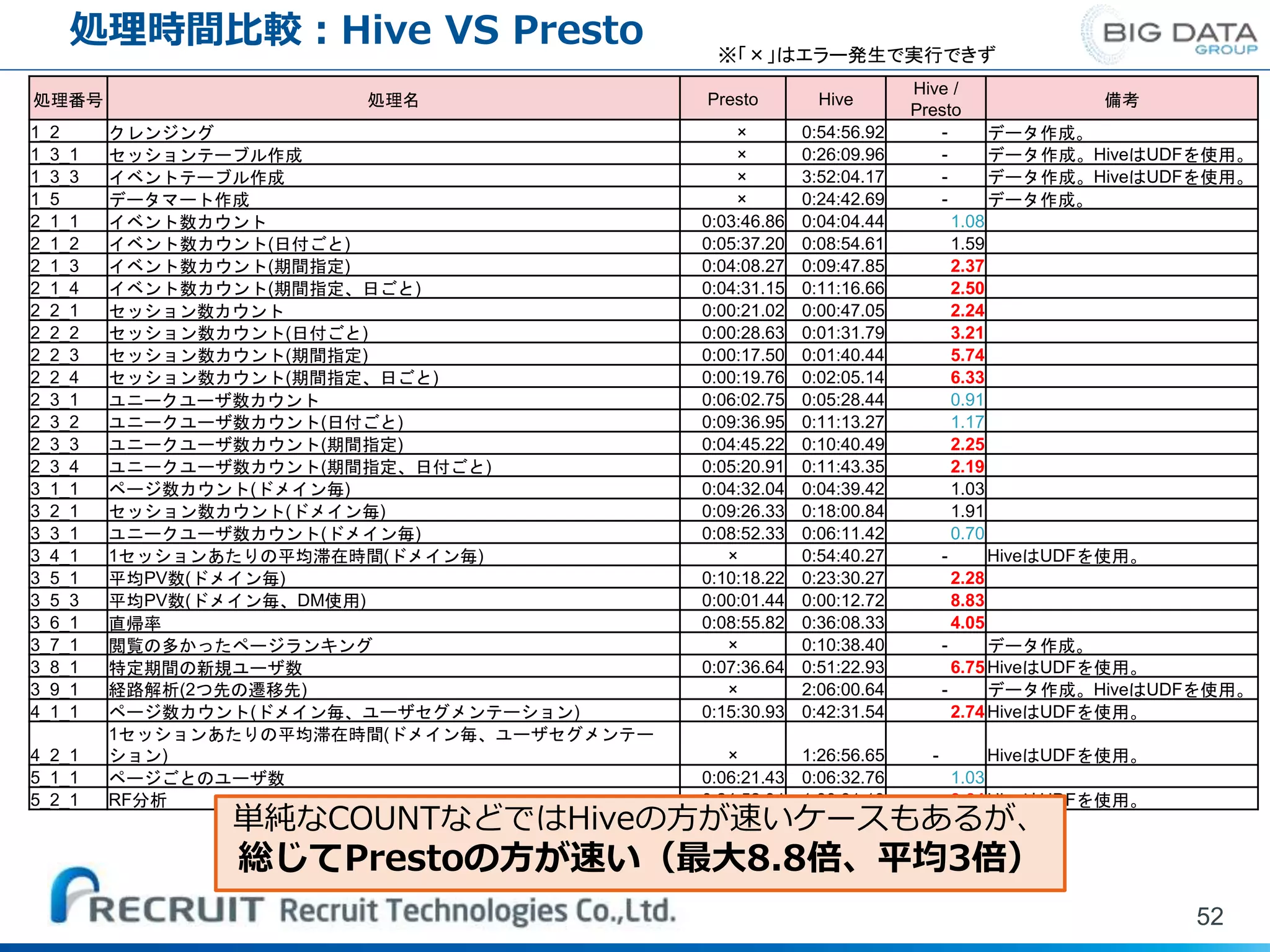
処理名 Presto Hive Hive / Presto 備考 1_2 クレンジング × 0:54:56.92 - データ作成。 1_3_1 セッションテーブル作成 × 0:26:09.96 - データ作成。HiveはUDFを使用。 1_3_3 イベントテーブル作成 × 3:52:04.17 - データ作成。HiveはUDFを使用。 1_5 データマート作成 × 0:24:42.69 - データ作成。 2_1_1 イベント数カウント 0:03:46.86 0:04:04.44 1.08 2_1_2 イベント数カウント(日付ごと) 0:05:37.20 0:08:54.61 1.59 2_1_3 イベント数カウント(期間指定) 0:04:08.27 0:09:47.85 2.37 2_1_4 イベント数カウント(期間指定、日ごと) 0:04:31.15 0:11:16.66 2.50 2_2_1 セッション数カウント 0:00:21.02 0:00:47.05 2.24 2_2_2 セッション数カウント(日付ごと) 0:00:28.63 0:01:31.79 3.21 2_2_3 セッション数カウント(期間指定) 0:00:17.50 0:01:40.44 5.74 2_2_4 セッション数カウント(期間指定、日ごと) 0:00:19.76 0:02:05.14 6.33 2_3_1 ユニークユーザ数カウント 0:06:02.75 0:05:28.44 0.91 2_3_2 ユニークユーザ数カウント(日付ごと) 0:09:36.95 0:11:13.27 1.17 2_3_3 ユニークユーザ数カウント(期間指定) 0:04:45.22 0:10:40.49 2.25 2_3_4 ユニークユーザ数カウント(期間指定、日付ごと) 0:05:20.91 0:11:43.35 2.19 3_1_1 ページ数カウント(ドメイン毎) 0:04:32.04 0:04:39.42 1.03 3_2_1 セッション数カウント(ドメイン毎) 0:09:26.33 0:18:00.84 1.91 3_3_1 ユニークユーザ数カウント(ドメイン毎) 0:08:52.33 0:06:11.42 0.70 3_4_1 1セッションあたりの平均滞在時間(ドメイン毎) × 0:54:40.27 - HiveはUDFを使用。 3_5_1 平均PV数(ドメイン毎) 0:10:18.22 0:23:30.27 2.28 3_5_3 平均PV数(ドメイン毎、DM使用) 0:00:01.44 0:00:12.72 8.83 3_6_1 直帰率 0:08:55.82 0:36:08.33 4.05 3_7_1 閲覧の多かったページランキング × 0:10:38.40 - データ作成。 3_8_1 特定期間の新規ユーザ数 0:07:36.64 0:51:22.93 6.75HiveはUDFを使用。 3_9_1 経路解析(2つ先の遷移先) × 2:06:00.64 - データ作成。HiveはUDFを使用。 4_1_1 ページ数カウント(ドメイン毎、ユーザセグメンテーション) 0:15:30.93 0:42:31.54 2.74HiveはUDFを使用。 4_2_1 1セッションあたりの平均滞在時間(ドメイン毎、ユーザセグメンテー ション) × 1:26:56.65 - HiveはUDFを使用。 5_1_1 ページごとのユーザ数 0:06:21.43 0:06:32.76 1.03 5_2_1 RF分析 0:24:52.94 1:30:31.13 3.64HiveはUDFを使用。 単純なCOUNTなどではHiveの方が速いケースもあるが、 総じてPrestoの方が速い(最大8.8倍、平均3倍) ※「×」はエラー発生で実行できず
53.
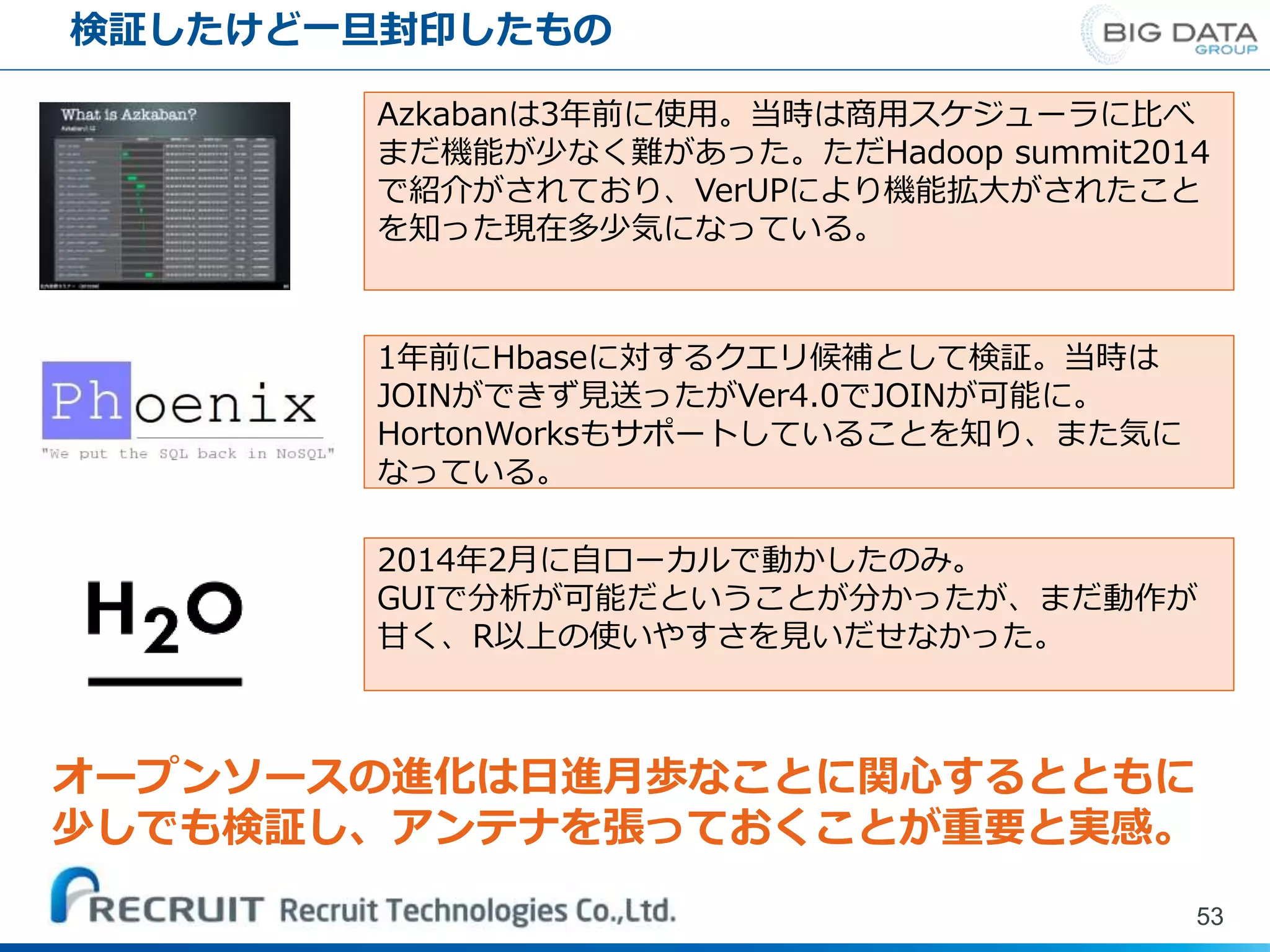
検証したけど一旦封印したもの 53 Azkabanは3年前に使用。当時は商用スケジューラに比べ まだ機能が少なく難があった。ただHadoop summit2014 で紹介がされており、VerUPにより機能拡大がされたこと を知った現在多少気になっている。 1年前にHbaseに対するクエリ候補として検証。当時は JOINができず見送ったがVer4.0でJOINが可能に。 HortonWorksもサポートしていることを知り、また気に なっている。 2014年2月に自ローカルで動かしたのみ。 GUIで分析が可能だということが分かったが、まだ動作が 甘く、R以上の使いやすさを見いだせなかった。 オープンソースの進化は日進月歩なことに関心するとともに 少しでも検証し、アンテナを張っておくことが重要と実感。
54.
54 まとめと今後
55.
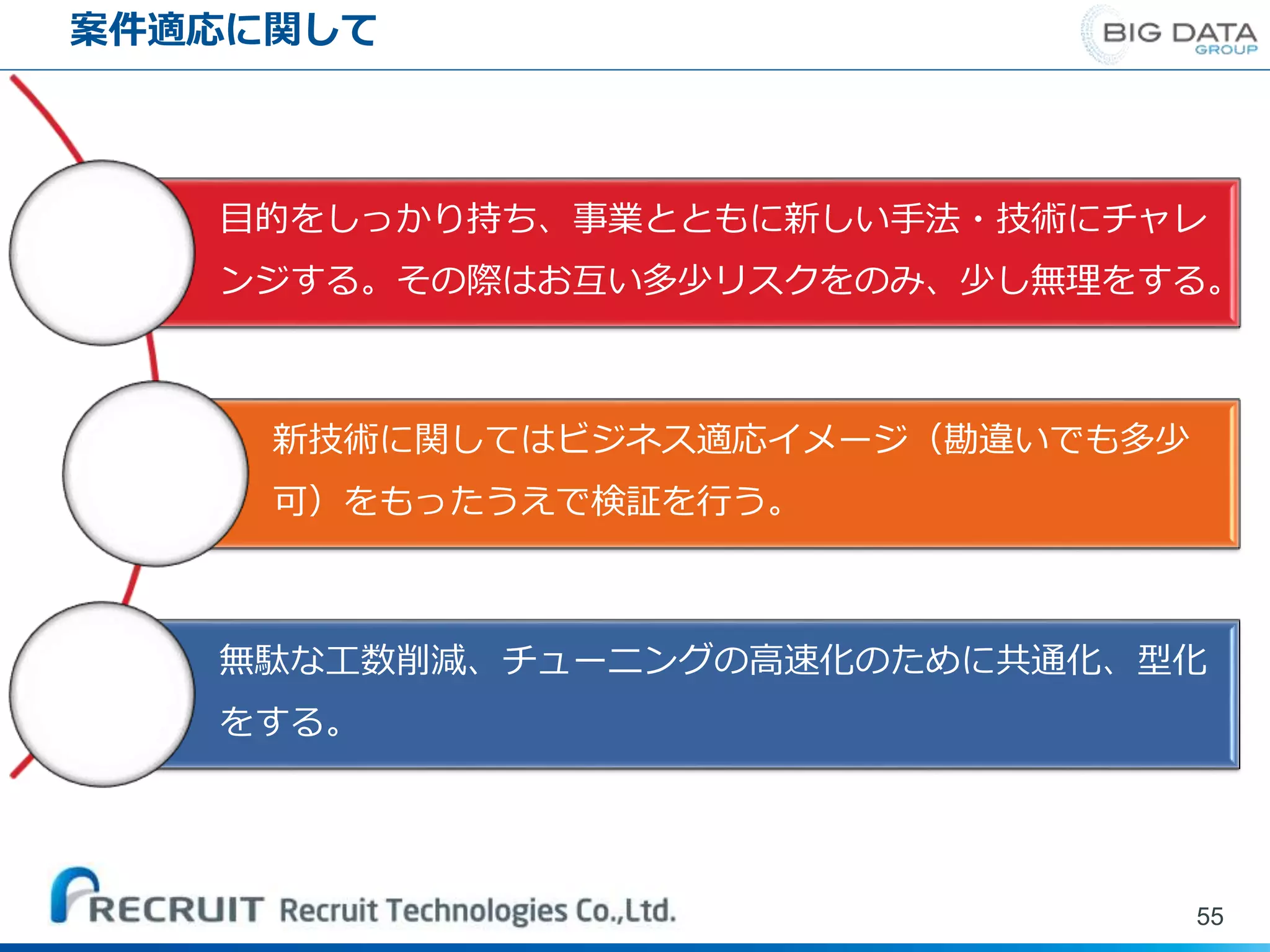
案件適応に関して 55 目的をしっかり持ち、事業とともに新しい手法・技術にチャレ ンジする。その際はお互い多少リスクをのみ、少し無理をする。 新技術に関してはビジネス適応イメージ(勘違いでも多少 可)をもったうえで検証を行う。 無駄な工数削減、チューニングの高速化のために共通化、型化 をする。
56.
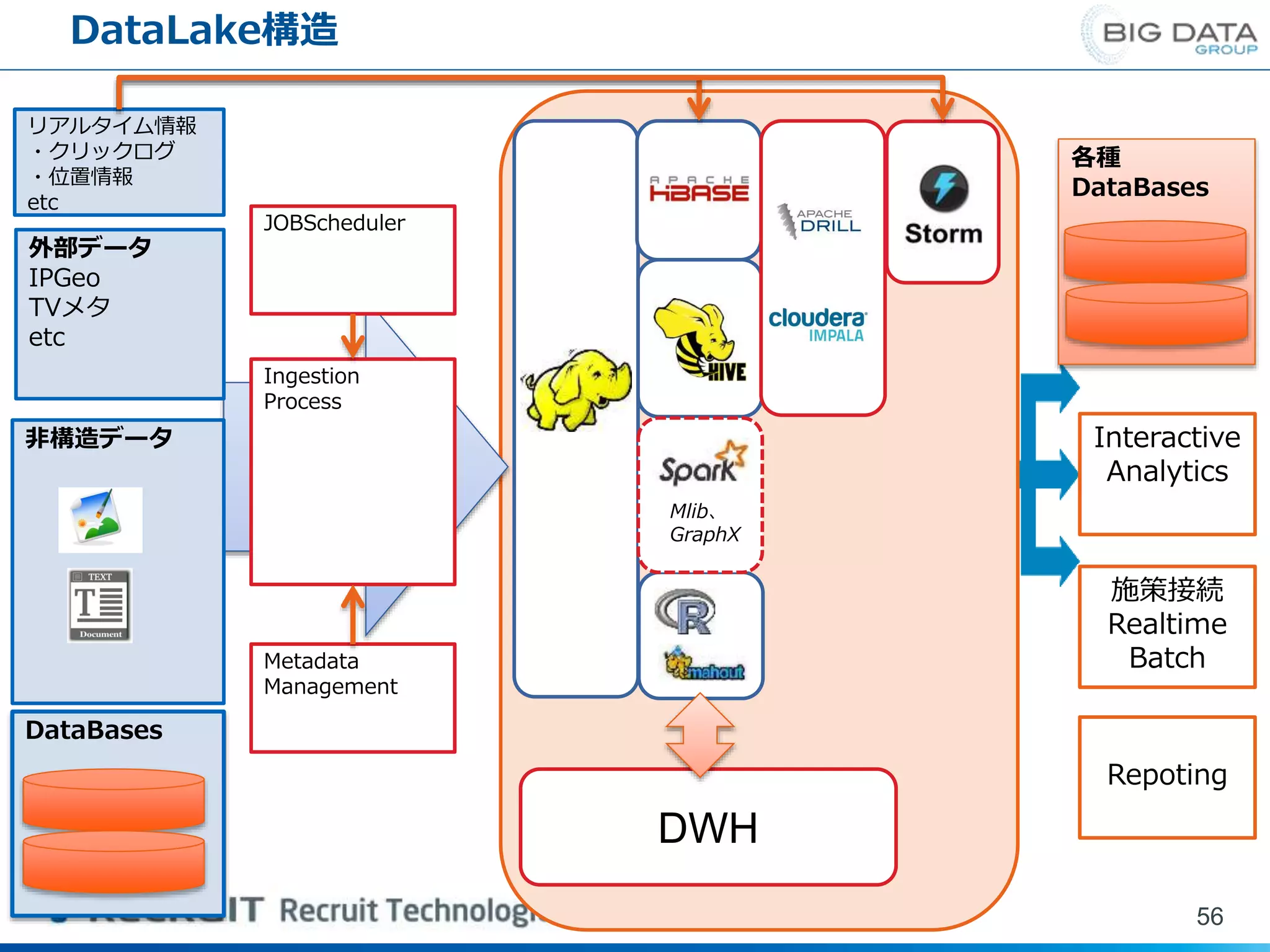
非構造データ DataLake構造 56 DataBases 外部データ IPGeo TVメタ etc JOBScheduler Ingestion Process Metadata Management リアルタイム情報 ・クリックログ ・位置情報 etc DWH 各種 DataBases Interactive Analytics 施策接続 Realtime Batch Repoting Mlib、 GraphX
57.
戦友をさがしています。 57 石川 信行 Nobuyuki Ishikawa ビジネスを踏まえて 泥臭くかつアグレッシブに 分析・エンジニアリング ができる方。 ご連絡ください。 Yes,
We Are Hiring!
58.
ご清聴ありがとうございました リクルートテクノロジーズ
Download