SQLベースの宣言的かつ容易な記述
5
Hivemallの特徴
Mahoutによるプログラミング
CREATE TABLE lr_modelAS
SELECT
feature, --reducers perform model averaging in parallel
avg(weight) as weight
FROM (
SELECT logress(features,label,..) as (feature,weight)
FROM train
) t --map-only task
GROUP BY feature; --shuffled to reducers
一般的なエンジニアでも機械学習を扱える
WebDB forum 2014
5 / 10
12
SIGMOD Testof Time Awardからのピックアップ
A Case for Redundant Arrays of Inexpensive Disks (RAID). David A. Patterson, Garth A. Gibson, and Randy H. Katz, In Proc.SIGMOD, 1988.
引用数3281
Encapsulation of Parallelism in the Volcano Query Processing System. Goetz Graefe, In Proc. SIGMOD, 1990.
引用元383
Mining Association Rules Between Sets of Items in Large Databases. Rakesh Agrawal, Tomasz Imielinski, and Arun Swam
引用元15008
RAIDの提案、ストレージビジネスへの影響大
Volcano Iterator Modelの提案
多くのRDBMS(Postgres/MySQLも)がこの実行モデルに基づく
Aprioriアルゴリズムの提案
Data miningon RDBMSの草分け
WebDB forum 2014
•J Dean, SGhemawat, "MapReduce: Simplified Data Processing on Large Clusters", Proc. OSDI, 2004.
•MateiZaharia, MosharafChowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica, “Spark: cluster computing with working sets”, Proc. HotCloud(USENIX workshop), 2010.
14
AMPLabの学生は初期は論文はあまり出ないかもしれないが
プロジェクトに集中するように言われていたらしい.
研究よりも実装が研究面への注目を喚起している
産業界への影響,学術面での影響を考慮しても外せない
オープンソース実装Hadoopが登場したことも大きい
(BigQueryの基礎となっているDremelは代替実装が生まれていない)
OS系会議からのピックアップ
DB系だとビジネス創生、OS系会議だとオープンソース実装が重要
WebDB forum 2014
15.
既に登場しているもの
•仮想化技術+ DB
•FPGA + DB
•InfinibandRDMA + DB
•KVS + FPGA / InfinibandRDMA
•H/Wトランザクショナルメモリ+DB
まだ登場していないもの
•機械学習+ アクセラレータ/FPGA
•機械学習+ 高速ネットワーク
•NVRAM + DBMS
•組込み/IoT用データ処理
•Query shipping/Continuous queries処理のオフロード
•TCP/IP、MQTTの代替プロトコルfor IoT-DB
15
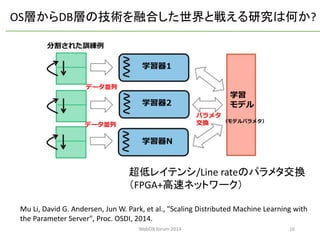
OS層からDB層の技術を融合した世界と戦える研究は何か?
WebDB forum 2014
16.
16
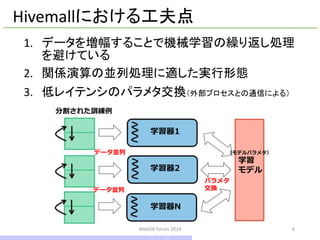
学習器1
学習器2
学習器N
パラメタ
交換
学習
モデル
分割された訓練例
データ並列
データ並列
(モデルパラメタ)
Mu Li, David G. Andersen, Jun W. Park, et al.,"Scaling Distributed Machine Learning with the Parameter Server", Proc. OSDI, 2014.
OS層からDB層の技術を融合した世界と戦える研究は何か?
超低レイテンシ/Line rateのパラメタ交換
(FPGA+高速ネットワーク)
WebDB forum 2014

















![[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e28hadoopdatalake-181004235141-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...](https://cdn.slidesharecdn.com/ss_thumbnails/e23-170912023826-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...](https://cdn.slidesharecdn.com/ss_thumbnails/d35-170912024713-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] A32: Attunity Replicate + Kafka + Hadoop マルチデータ...](https://cdn.slidesharecdn.com/ss_thumbnails/attunityreplicatekafkahadoop-170911072451-thumbnail.jpg?width=640&height=640&fit=bounds)











































