Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Makoto Yui
PDF, PPTX
4,413 views
Hivemall LT @ Machine Learning Casual Talks #3
Hivemall LT @ Machine Learning Casual Talks #3 http://mlct.connpass.com/event/13995/
Data & Analytics
◦
Read more
9
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 16
2
/ 16
3
/ 16
4
/ 16
5
/ 16
6
/ 16
7
/ 16
8
/ 16
9
/ 16
10
/ 16
11
/ 16
12
/ 16
13
/ 16
14
/ 16
15
/ 16
16
/ 16
More Related Content
PDF
Hivemall v0.3の機能紹介@1st Hivemall meetup
by
Makoto Yui
PDF
Hcj2014 myui
by
Makoto Yui
PDF
HivemallとSpark MLlibの比較
by
Makoto Yui
PDF
Hivemallで始める不動産価格推定サービス
by
Kentaro Yoshida
PPTX
Sano hmm 20150512
by
Masakazu Sano
PDF
hivemallを使って4日間で性別推定した話
by
eventdotsjp
PDF
R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜
by
Yasuyuki Sugai
PDF
16.02.08_Hadoop Conferece Japan 2016_データサイエンスにおける一次可視化からのSpark on Elasticsear...
by
LINE Corp.
Hivemall v0.3の機能紹介@1st Hivemall meetup
by
Makoto Yui
Hcj2014 myui
by
Makoto Yui
HivemallとSpark MLlibの比較
by
Makoto Yui
Hivemallで始める不動産価格推定サービス
by
Kentaro Yoshida
Sano hmm 20150512
by
Masakazu Sano
hivemallを使って4日間で性別推定した話
by
eventdotsjp
R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜
by
Yasuyuki Sugai
16.02.08_Hadoop Conferece Japan 2016_データサイエンスにおける一次可視化からのSpark on Elasticsear...
by
LINE Corp.
What's hot
PPTX
AWS IoT Eventsで遊んでみた
by
Ken'ichirou Kimura
PDF
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
PDF
ML Pipelineで実践機械学習
by
Kazuki Taniguchi
PDF
レコメンドバッチ高速化に向けたSpark/MapReduceの機械学習ライブラリ比較検証
by
Recruit Technologies
PDF
AWSによるグラフDB構築
by
Alexander Patrikalakis
AWS IoT Eventsで遊んでみた
by
Ken'ichirou Kimura
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
ML Pipelineで実践機械学習
by
Kazuki Taniguchi
レコメンドバッチ高速化に向けたSpark/MapReduceの機械学習ライブラリ比較検証
by
Recruit Technologies
AWSによるグラフDB構築
by
Alexander Patrikalakis
Viewers also liked
PDF
2nd Hivemall meetup 20151020
by
Makoto Yui
PDF
Hivemallmtup 20160908
by
Kazuki Ohmori
PDF
3rd Hivemall meetup
by
Makoto Yui
PDF
Hivemall meetup vol2 oisix
by
Taisuke Fukawa
PDF
20160908 hivemall meetup
by
Takeshi Yamamuro
PPTX
U-NEXTの動画配信ログ収集・分析、レコメンドエンジンを支えるトレジャーデータ
by
Takatoshi Kakimoto
2nd Hivemall meetup 20151020
by
Makoto Yui
Hivemallmtup 20160908
by
Kazuki Ohmori
3rd Hivemall meetup
by
Makoto Yui
Hivemall meetup vol2 oisix
by
Taisuke Fukawa
20160908 hivemall meetup
by
Takeshi Yamamuro
U-NEXTの動画配信ログ収集・分析、レコメンドエンジンを支えるトレジャーデータ
by
Takatoshi Kakimoto
Similar to Hivemall LT @ Machine Learning Casual Talks #3
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PDF
Hivemall Talk@SIGMOD-J Oct.4, 2014.
by
Makoto Yui
PPT
Big data解析ビジネス
by
Mie Mori
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PDF
Log解析の超入門
by
菊池 佑太
PDF
Panel Discussion@WebDB forum 2014
by
Makoto Yui
PDF
データ・テキストマイニング
by
Hiroshi Ono
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
JAWSDAYS 2014 ACEに聞け! EMR編
by
陽平 山口
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
PPTX
20140711 evf2014 hadoop_recommendmachinelearning
by
Takumi Yoshida
PDF
Apache Drill でたしなむ セルフサービスデータ探索 - 2014/11/06 Cloudera World Tokyo 2014 LTセッション
by
MapR Technologies Japan
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
PPTX
2020/11/19 Global AI on Tour - Toyama プログラマーのための機械学習入門
by
Daiyu Hatakeyama
PPTX
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
PPTX
MLaPP輪講 Chapter 1
by
ryuhmd
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
1028 TECH & BRIDGE MEETING
by
健司 亀本
Hivemall Talk@SIGMOD-J Oct.4, 2014.
by
Makoto Yui
Big data解析ビジネス
by
Mie Mori
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
Log解析の超入門
by
菊池 佑太
Panel Discussion@WebDB forum 2014
by
Makoto Yui
データ・テキストマイニング
by
Hiroshi Ono
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
JAWSDAYS 2014 ACEに聞け! EMR編
by
陽平 山口
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
20140711 evf2014 hadoop_recommendmachinelearning
by
Takumi Yoshida
Apache Drill でたしなむ セルフサービスデータ探索 - 2014/11/06 Cloudera World Tokyo 2014 LTセッション
by
MapR Technologies Japan
第1回 Jubatusハンズオン
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
2020/11/19 Global AI on Tour - Toyama プログラマーのための機械学習入門
by
Daiyu Hatakeyama
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
MLaPP輪講 Chapter 1
by
ryuhmd
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
More from Makoto Yui
PDF
Apache Hivemall and my OSS experience
by
Makoto Yui
PDF
Introduction to Apache Hivemall v0.5.2 and v0.6
by
Makoto Yui
PDF
Introduction to Apache Hivemall v0.5.0
by
Makoto Yui
PDF
Idea behind Apache Hivemall
by
Makoto Yui
PDF
Introduction to Apache Hivemall v0.5.0
by
Makoto Yui
PDF
What's new in Hivemall v0.5.0
by
Makoto Yui
PDF
What's new in Apache Hivemall v0.5.0
by
Makoto Yui
PDF
Revisiting b+-trees
by
Makoto Yui
PDF
Incubating Apache Hivemall
by
Makoto Yui
PDF
Hivemall meets Digdag @Hackertackle 2018-02-17
by
Makoto Yui
PDF
Apache Hivemall @ Apache BigData '17, Miami
by
Makoto Yui
PDF
機械学習のデータ並列処理@第7回BDI研究会
by
Makoto Yui
PDF
Podling Hivemall in the Apache Incubator
by
Makoto Yui
PDF
Dots20161029 myui
by
Makoto Yui
PDF
Hadoopsummit16 myui
by
Makoto Yui
PDF
HadoopCon'16, Taipei @myui
by
Makoto Yui
PDF
Recommendation 101 using Hivemall
by
Makoto Yui
PDF
Hivemall dbtechshowcase 20160713 #dbts2016
by
Makoto Yui
PDF
Introduction to Hivemall
by
Makoto Yui
PDF
Tdtechtalk20160425myui
by
Makoto Yui
Apache Hivemall and my OSS experience
by
Makoto Yui
Introduction to Apache Hivemall v0.5.2 and v0.6
by
Makoto Yui
Introduction to Apache Hivemall v0.5.0
by
Makoto Yui
Idea behind Apache Hivemall
by
Makoto Yui
Introduction to Apache Hivemall v0.5.0
by
Makoto Yui
What's new in Hivemall v0.5.0
by
Makoto Yui
What's new in Apache Hivemall v0.5.0
by
Makoto Yui
Revisiting b+-trees
by
Makoto Yui
Incubating Apache Hivemall
by
Makoto Yui
Hivemall meets Digdag @Hackertackle 2018-02-17
by
Makoto Yui
Apache Hivemall @ Apache BigData '17, Miami
by
Makoto Yui
機械学習のデータ並列処理@第7回BDI研究会
by
Makoto Yui
Podling Hivemall in the Apache Incubator
by
Makoto Yui
Dots20161029 myui
by
Makoto Yui
Hadoopsummit16 myui
by
Makoto Yui
HadoopCon'16, Taipei @myui
by
Makoto Yui
Recommendation 101 using Hivemall
by
Makoto Yui
Hivemall dbtechshowcase 20160713 #dbts2016
by
Makoto Yui
Introduction to Hivemall
by
Makoto Yui
Tdtechtalk20160425myui
by
Makoto Yui
Hivemall LT @ Machine Learning Casual Talks #3
1.
Copyright ©2016 Treasure
Data. All Rights Reserved. Treasure Data Inc. Research Engineer 油井 誠 @myui 2015/04/30 Machine Learning Casual Talk #3 1 Hivemall v0.3の新機能の紹介 http://myui.github.io/
2.
Copyright ©2016 Treasure
Data. All Rights Reserved. Ø2015/04 トレジャーデータ入社 Ø第1号のリサーチエンジニア ØML as a Service (MLaaS)に従事(?) Ø2015/03 産業技術総合研究所 情報技術研究部 門 主任研究員 Ø大規模機械学習および並列データベースの研究に従 事 Ø2009/03 NAIST 博士課程修了 博士(工学) ØXMLネイティブデータベースおよび超並列データベース の研究に従事 ØH14未踏ユース第1期スーパクリエイタ 2 自己紹介
3.
Copyright ©2016 Treasure
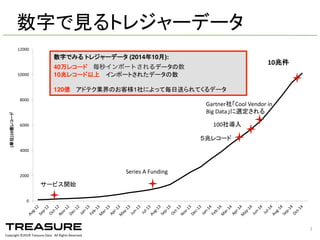
Data. All Rights Reserved. 3 0 2000 4000 6000 8000 10000 12000 Aug-‐12 Sep-‐12 Oct-‐12 Nov-‐12 Dec-‐12 Jan-‐13 Feb-‐13 M ar-‐13 Apr-‐13M ay-‐13 Jun-‐13 Jul-‐13 Aug-‐13 Sep-‐13 Oct-‐13 Nov-‐13 Dec-‐13 Jan-‐14 Feb-‐14 M ar-‐14 Apr-‐14M ay-‐14 Jun-‐14 Jul-‐14 Aug-‐14 Sep-‐14 Oct-‐14 (単位)10億レコード サービス開始 Series A Funding 100社導入 Gartner社「Cool Vendor in Big Data」に選定される 10兆件 5兆レコード 数字でみる トレジャーデータ (2014年10月): 40万レコード 毎秒インポートされるデータの数 10兆レコード以上 インポートされたデータの数 120億 アドテク業界のお客様1社によって毎日送られてくるデータ 数字で見るトレジャーデータ
4.
Copyright ©2016 Treasure
Data. All Rights Reserved. 数字で見る現在のトレジャーデータ 100+ 日本の顧客社数 15兆 保存されている データ件数 4,000 一社が所有する最大 サーバー数 500,000 1秒間に保存される データ件数 4
5.
Copyright ©2016 Treasure
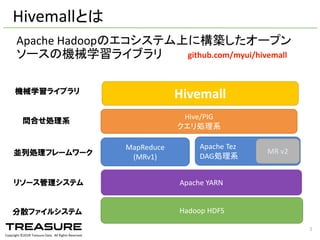
Data. All Rights Reserved. Hivemallとは Apache Hadoopのエコシステム上に構築したオープン ソースの機械学習ライブラリ Hadoop HDFS MapReduce (MRv1) Hive/PIG クエリ処理系 Hivemall Apache YARN Apache Tez DAG処理系 MR v2 分散ファイルシステム リソース管理システム 並列処理フレームワーク 問合せ処理系 機械学習ライブラリ github.com/myui/hivemall 5
6.
Copyright ©2016 Treasure
Data. All Rights Reserved. SQLベースの宣言的かつ容易な記述 Hivemallの特徴 何十行もの プログラム Mahoutによるプログラミング CREATE TABLE lr_model AS SELECT feature, -‐-‐ reducers perform model averaging in parallel avg(weight) as weight FROM ( SELECT logress(features,label,..) as (feature,weight) FROM train ) t -‐-‐ map-‐only task GROUP BY feature; -‐-‐ shuffled to reducers ü 一般的なエンジニアでも機械学習を扱える ü API抽象度がHiveQLと高いのでAPIがかなりstable (Sparkはまだ結構unstable) このような問合せを書くと学習処理が Hadoop上で並列実行される 6
7.
Copyright ©2016 Treasure
Data. All Rights Reserved. Hivemall v0.3で提供している機能 7 • クラス分類(二値分類/多値 分類) ü Perceptron ü Passive Aggressive (PA) ü Confidence Weighted (CW) ü Adaptive Regularization of Weight Vectors (AROW) ü Soft Confidence Weighted (SCW) ü AdaGrad+RDA • 回帰分析 ü 確率的勾配降下法に基づくロジス ティック回帰 ü PA Regression ü AROW Regression ü AdaGrad ü AdaDELTA • K近傍法 & レコメンデーション ü Minhashとb-‐Bit Minhash (LSH variant) ü 類似度に基づくK近傍探索 ü Matrix Factorization • Feature engineering ü Feature hashing ü Feature scaling (normalization, z-‐score) ü TF-‐IDF vectorizer トレジャーデータでもv0.3を5月中に サポート予定
8.
Copyright ©2016 Treasure
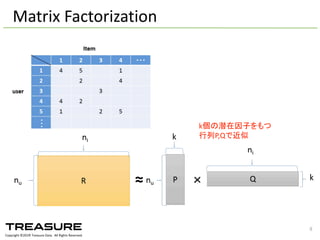
Data. All Rights Reserved. 8 Matrix Factorization k個の潜在因子をもつ 行列P,Qで近似
9.
Copyright ©2016 Treasure
Data. All Rights Reserved. 9 評価値の 平均 Matrix Factorization 正則化項 ユーザおよび商品ごとの 評価バイアスを考慮 Biased MFのSGDおよびAdagradによる最適化
10.
Copyright ©2016 Treasure
Data. All Rights Reserved. 10 Matrix Factorizationの学習 ローカルディスクに訓練事例を書き出すことで学習が収束するまでの 繰り返し学習に対応(全体最適化のためにパラメタ交換が必要)
11.
Copyright ©2016 Treasure
Data. All Rights Reserved. 11 Matrix Factorizationの予測/評価
12.
Copyright ©2016 Treasure
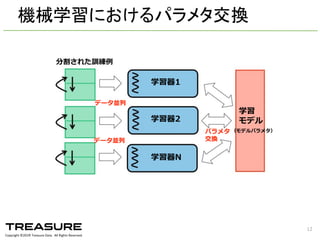
Data. All Rights Reserved. 機械学習におけるパラメタ交換 12 学習器1 学習器2 学習器N パラメタ 交換 学習 モデル 分割された訓練例例 データ並列列 データ並列列 (モデルパラメタ)
13.
Copyright ©2016 Treasure
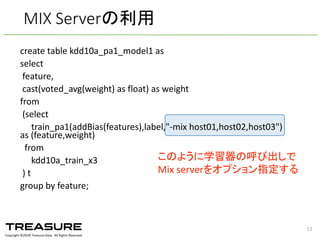
Data. All Rights Reserved. create table kdd10a_pa1_model1 as select feature, cast(voted_avg(weight) as float) as weight from (select train_pa1(addBias(features),label,"-‐mix host01,host02,host03") as (feature,weight) from kdd10a_train_x3 ) t group by feature; MIX Serverの利用 このように学習器の呼び出しで Mix serverをオプション指定する 13
14.
Copyright ©2016 Treasure
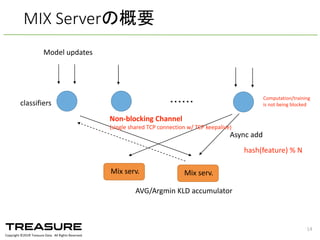
Data. All Rights Reserved. ・・・・・・ Model updates Async add AVG/Argmin KLD accumulator hash(feature) % N Non-‐blocking Channel (single shared TCP connection w/ TCP keepalive) classifiers Mix serv.Mix serv. Computation/training is not being blocked MIX Serverの概要 14
15.
Copyright ©2016 Treasure
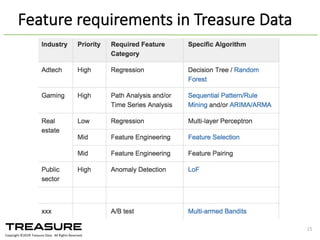
Data. All Rights Reserved. 15 Feature requirements in Treasure Data
16.
Copyright ©2016 Treasure
Data. All Rights Reserved. 16 Treasure Dataでは、機械学習の実装に強い人/Kaggle Master/Data Scientistsも募集しております! Hiringの一覧にはまだ出ていないので、興味のある方は myui@treasure-‐data.com または @myui に連絡ください
Download