Downloaded 136 times








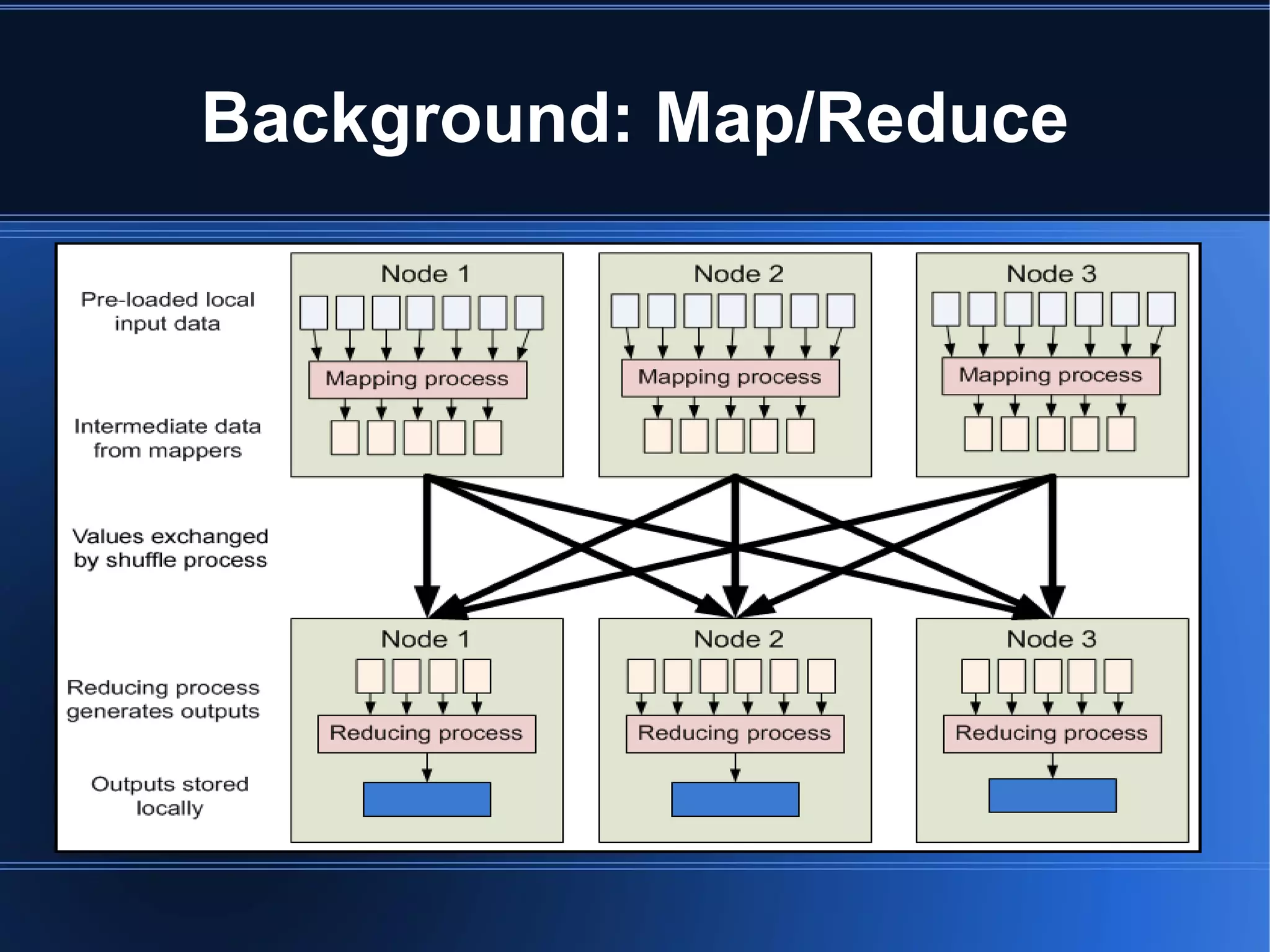




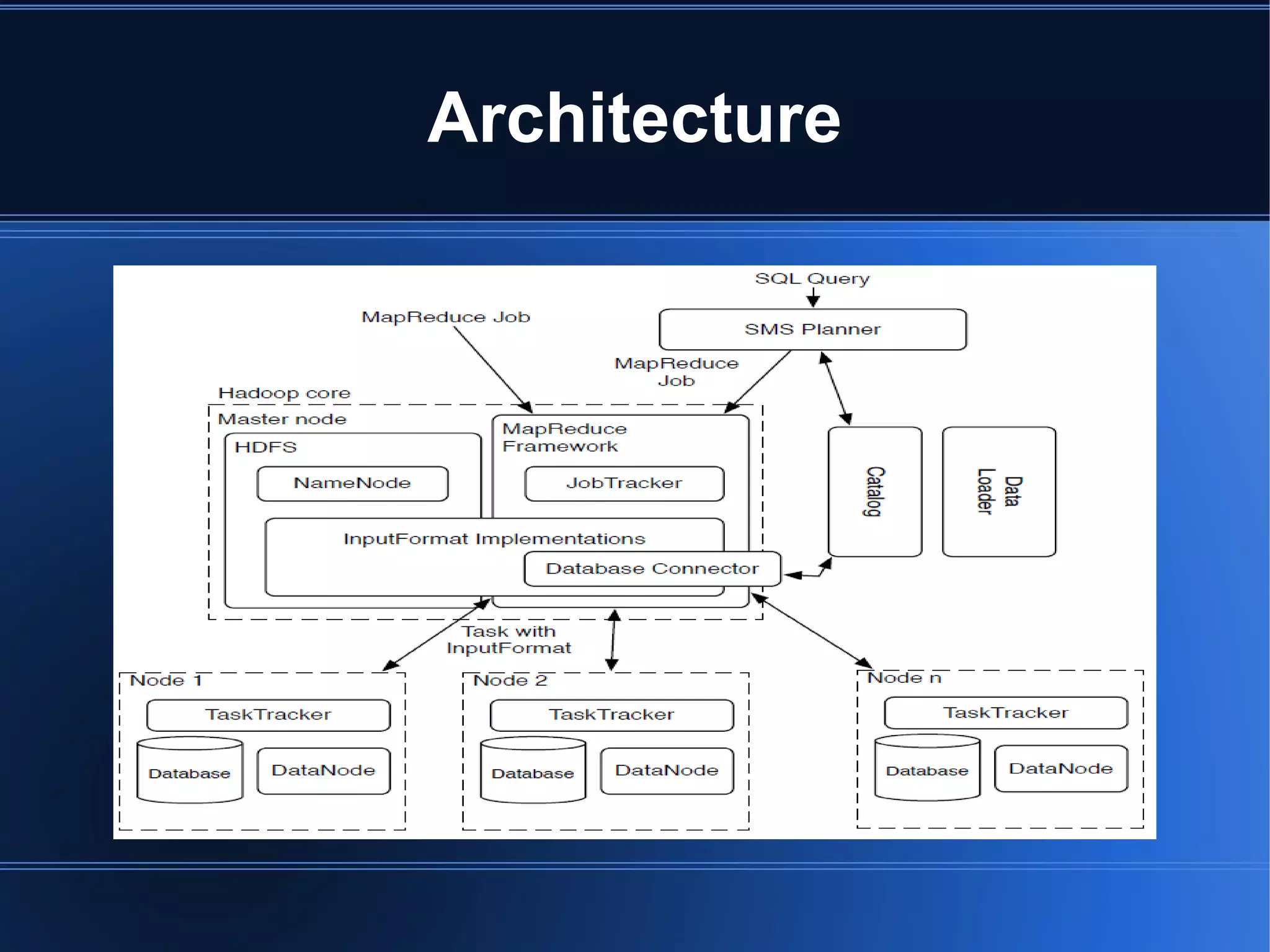










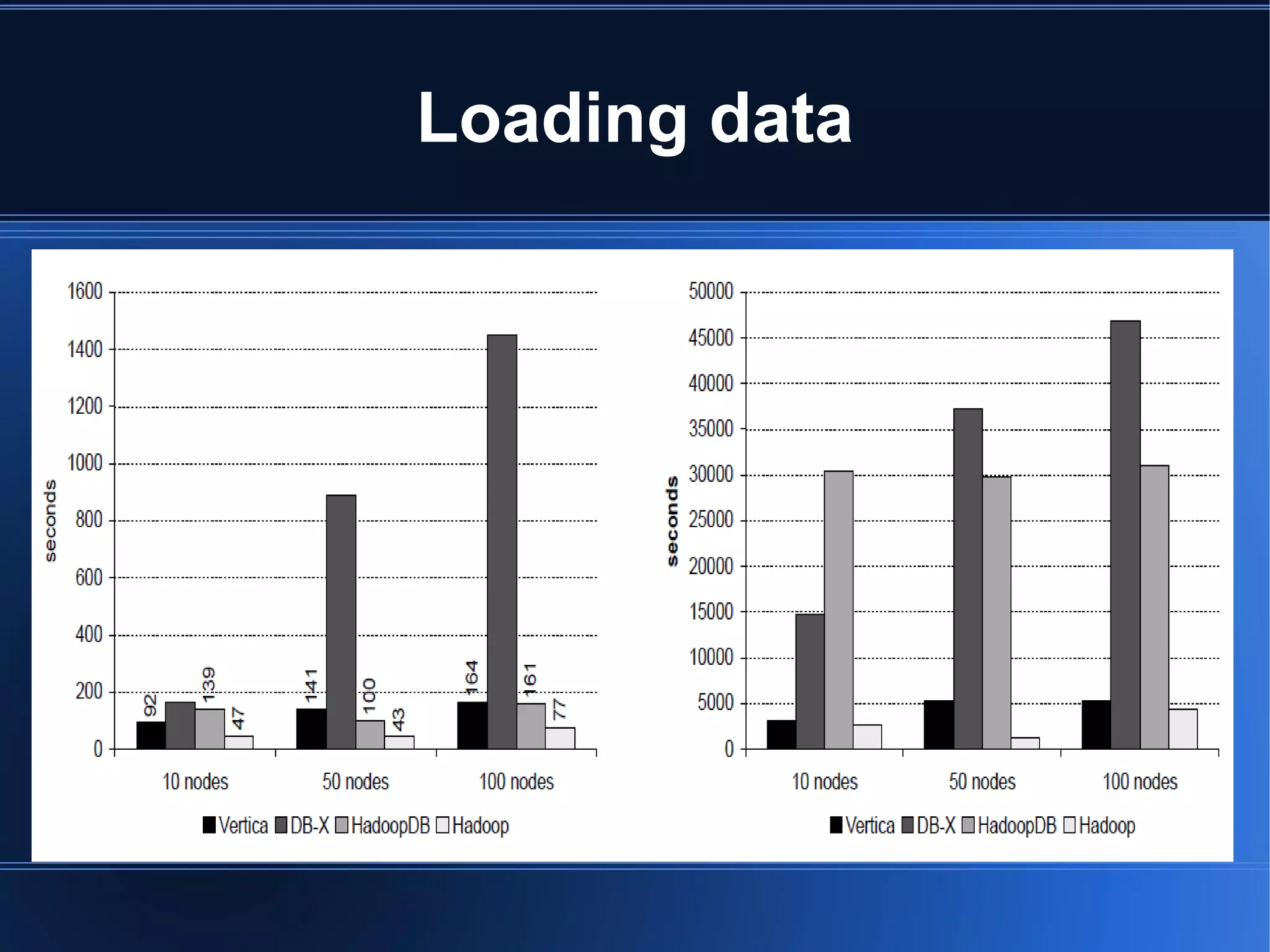
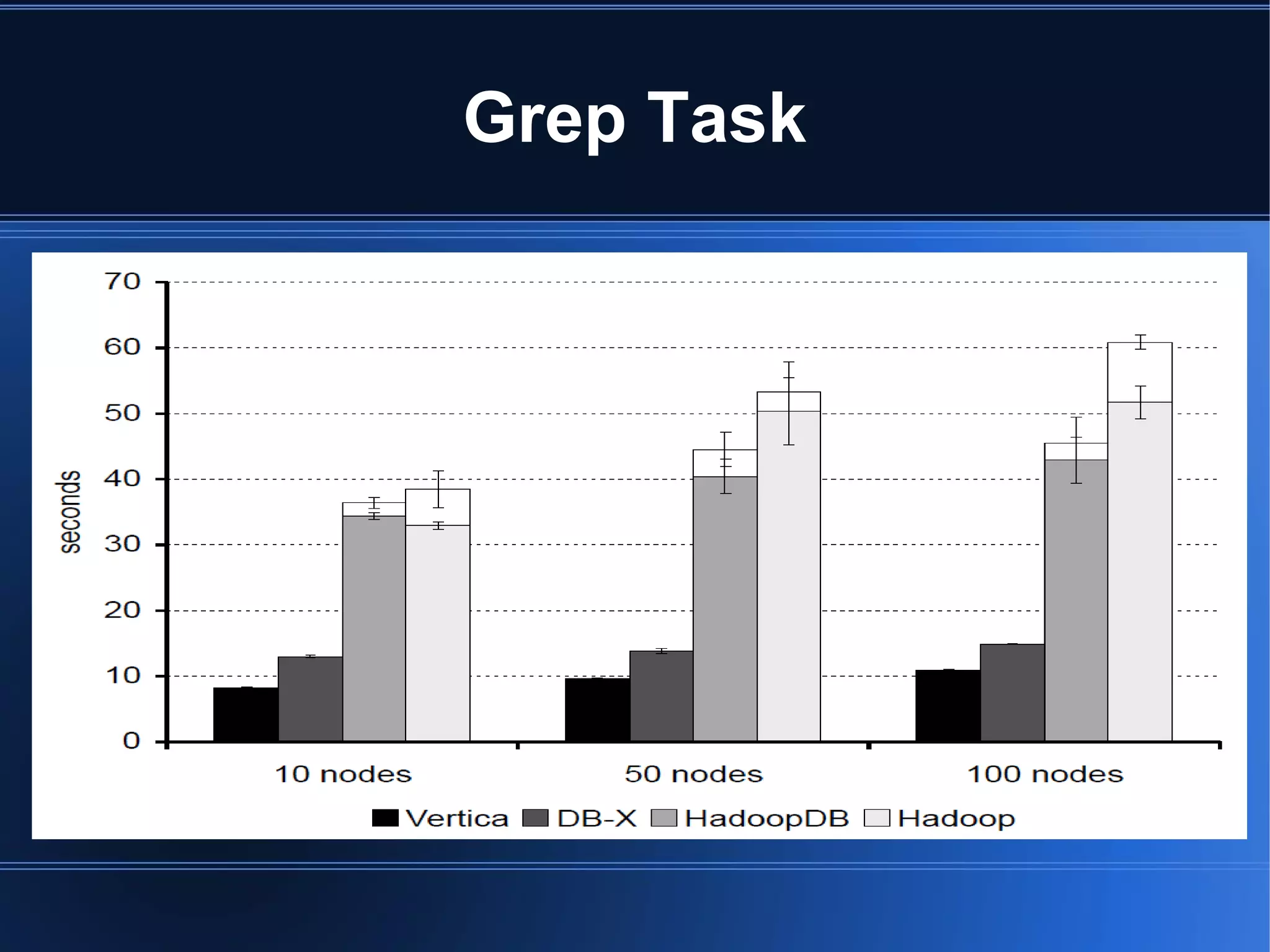
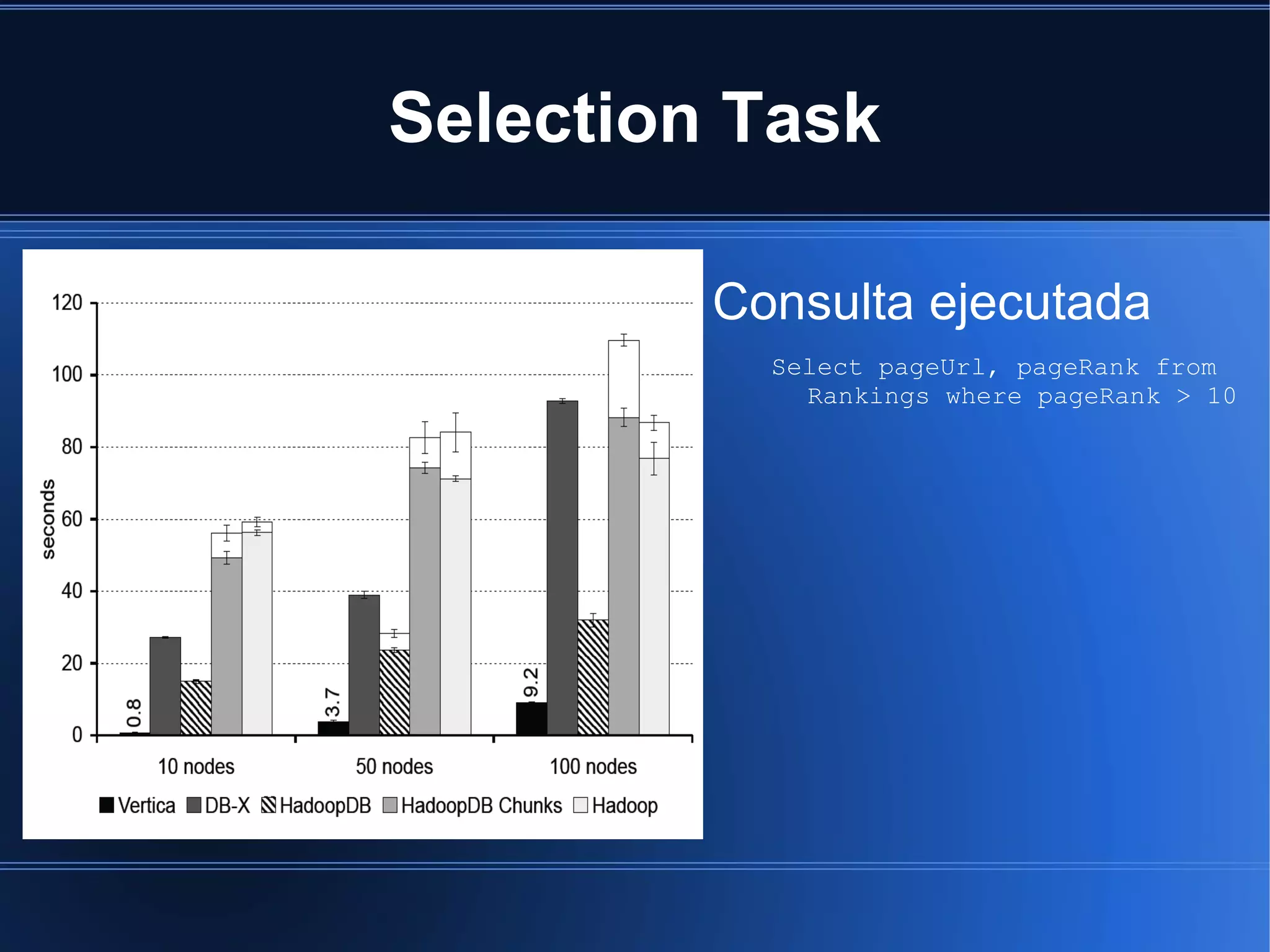
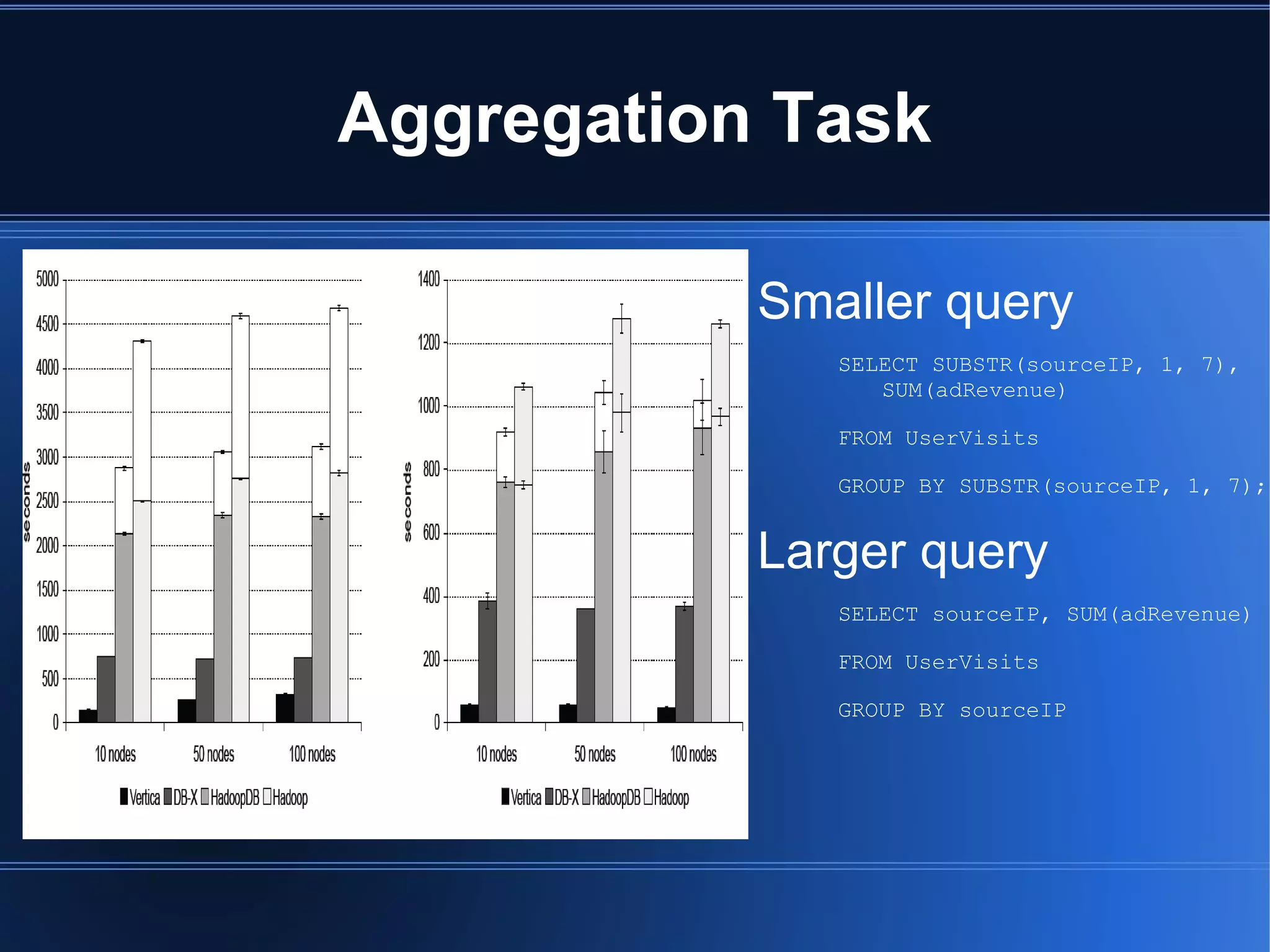
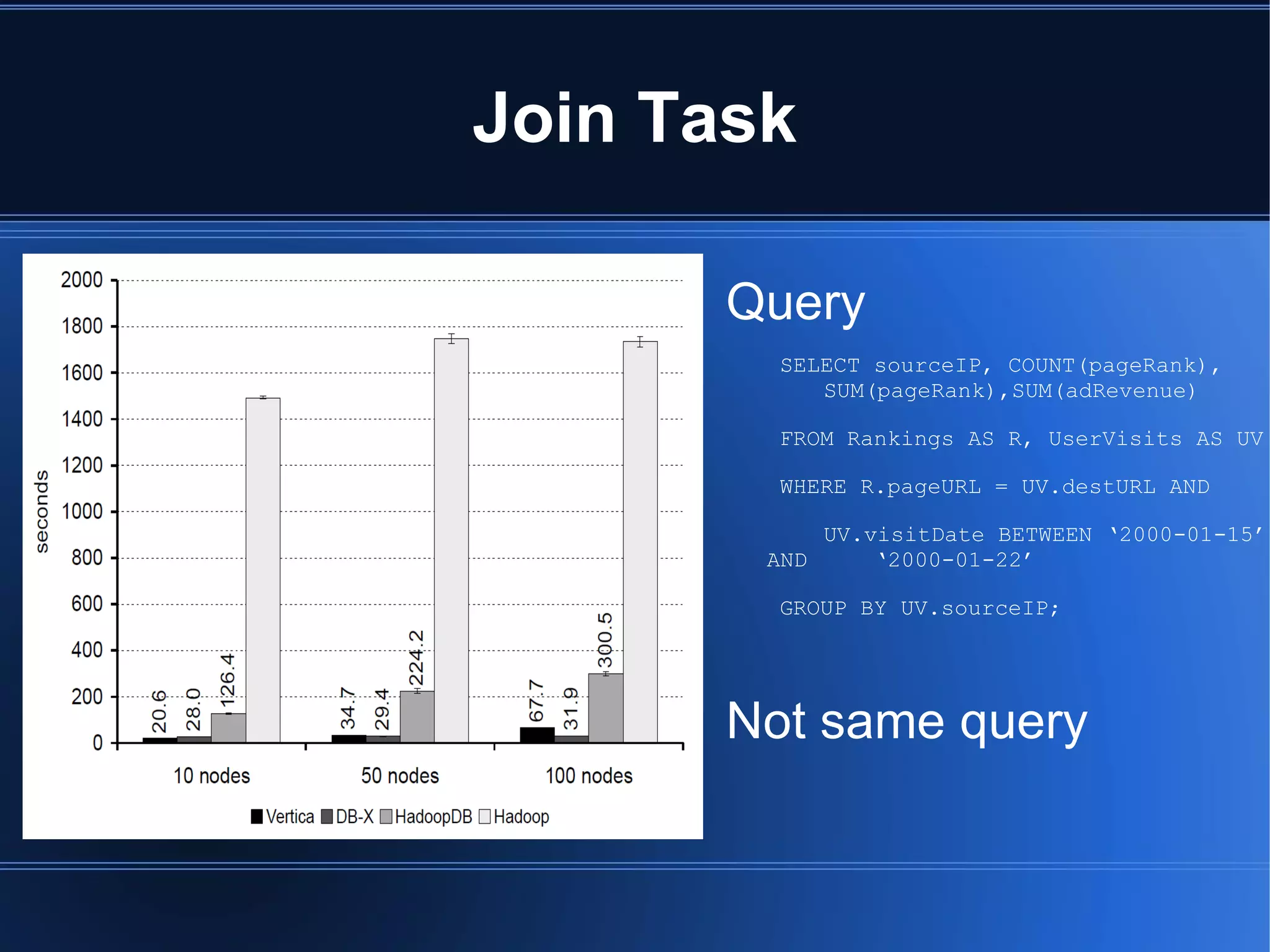
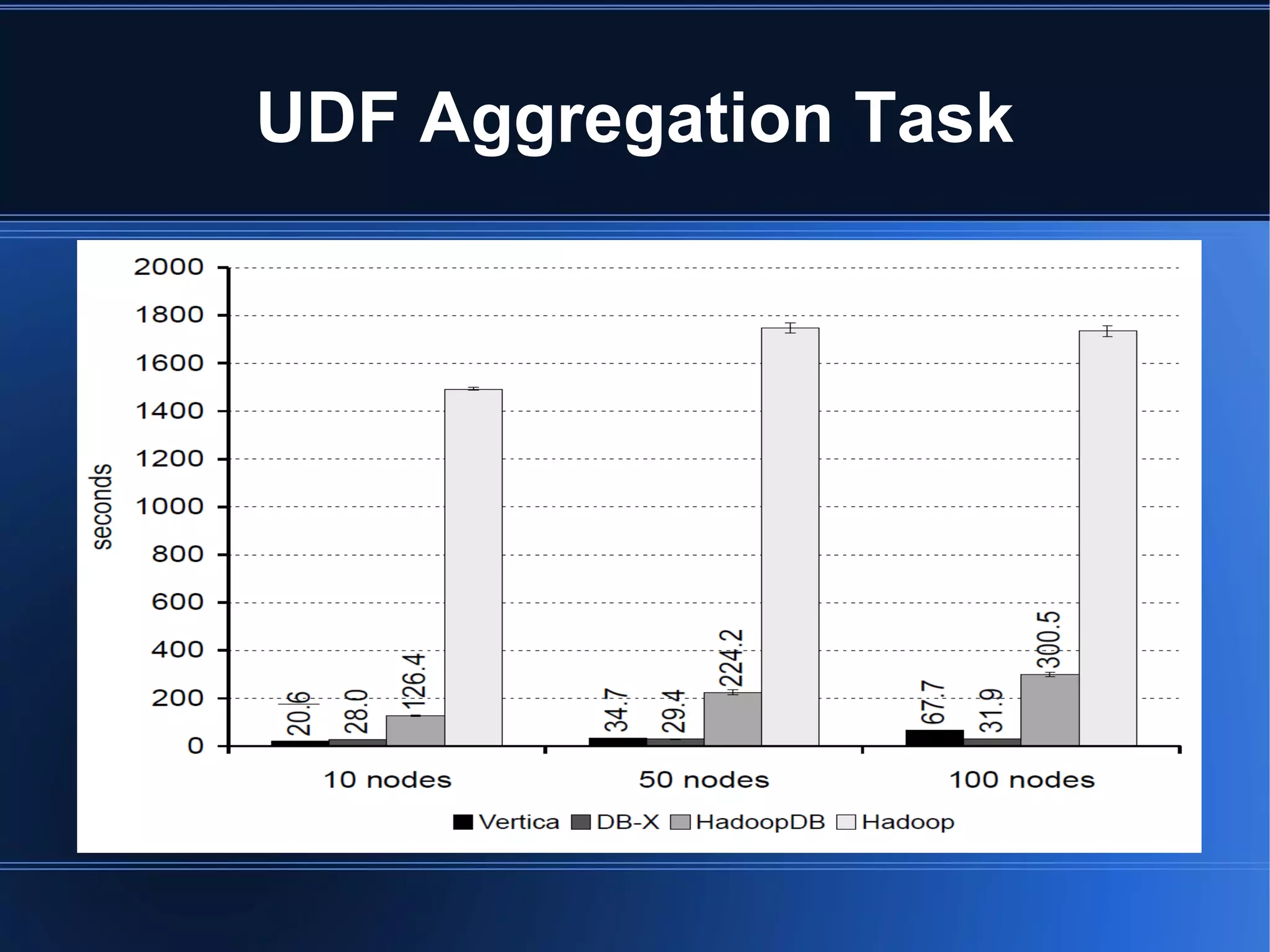


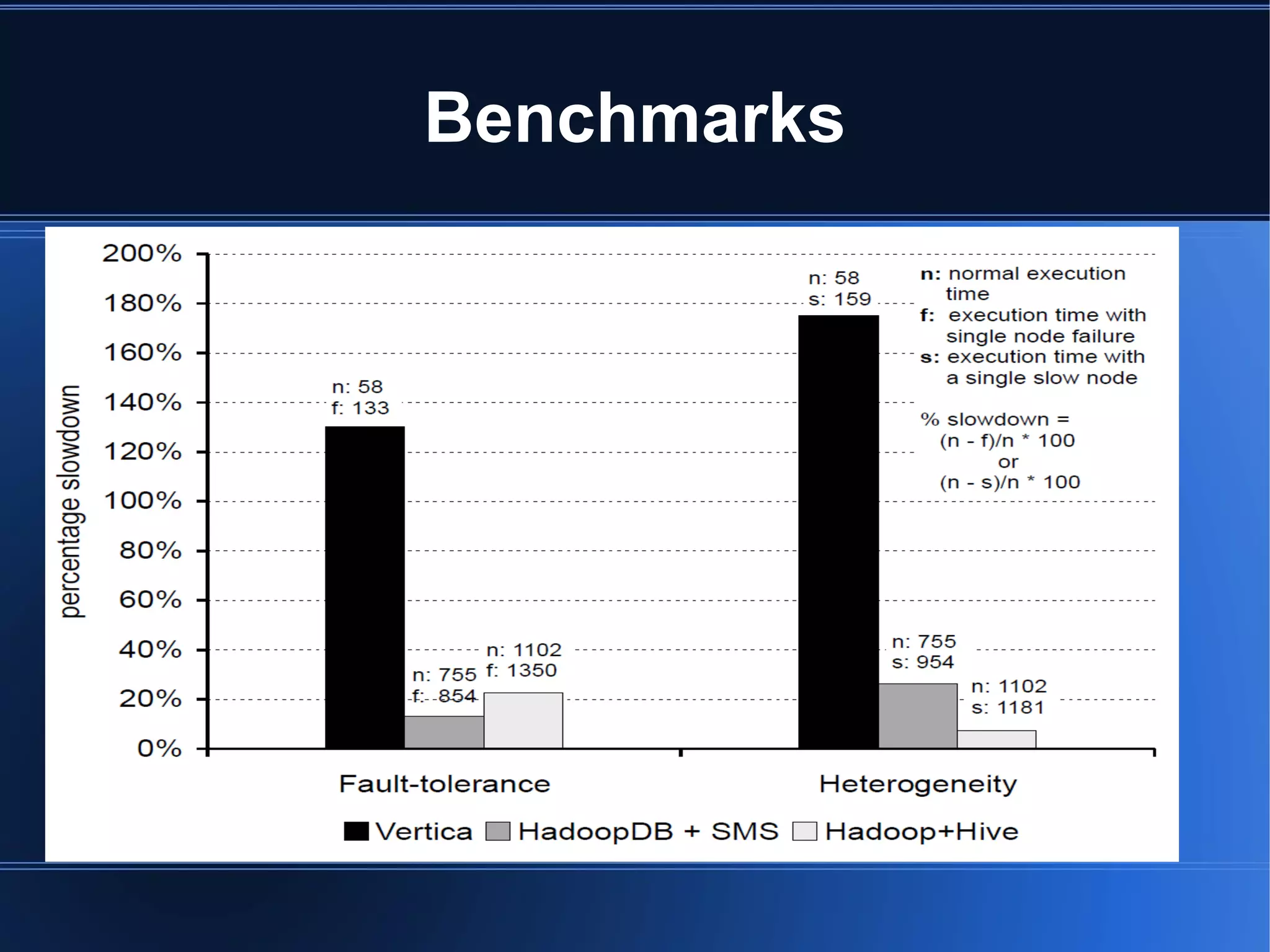







HadoopDB is a system that aims to achieve the performance of parallel databases while maintaining Hadoop's fault tolerance and ability to work in heterogeneous environments. It connects single-node database systems and uses Hadoop for coordination and networking. This allows queries to be parallelized across nodes for performance similar to parallel databases. The architecture includes components for interfacing databases, managing metadata, loading and partitioning data, and planning and optimizing SQL queries for MapReduce execution. Benchmarking showed HadoopDB outperformed Hadoop and PostgreSQL for queries on large datasets, though some commercial parallel databases were still faster by using techniques like columnar storage and compression that HadoopDB did not yet employ.





























































































