Download as PDF, PPTX



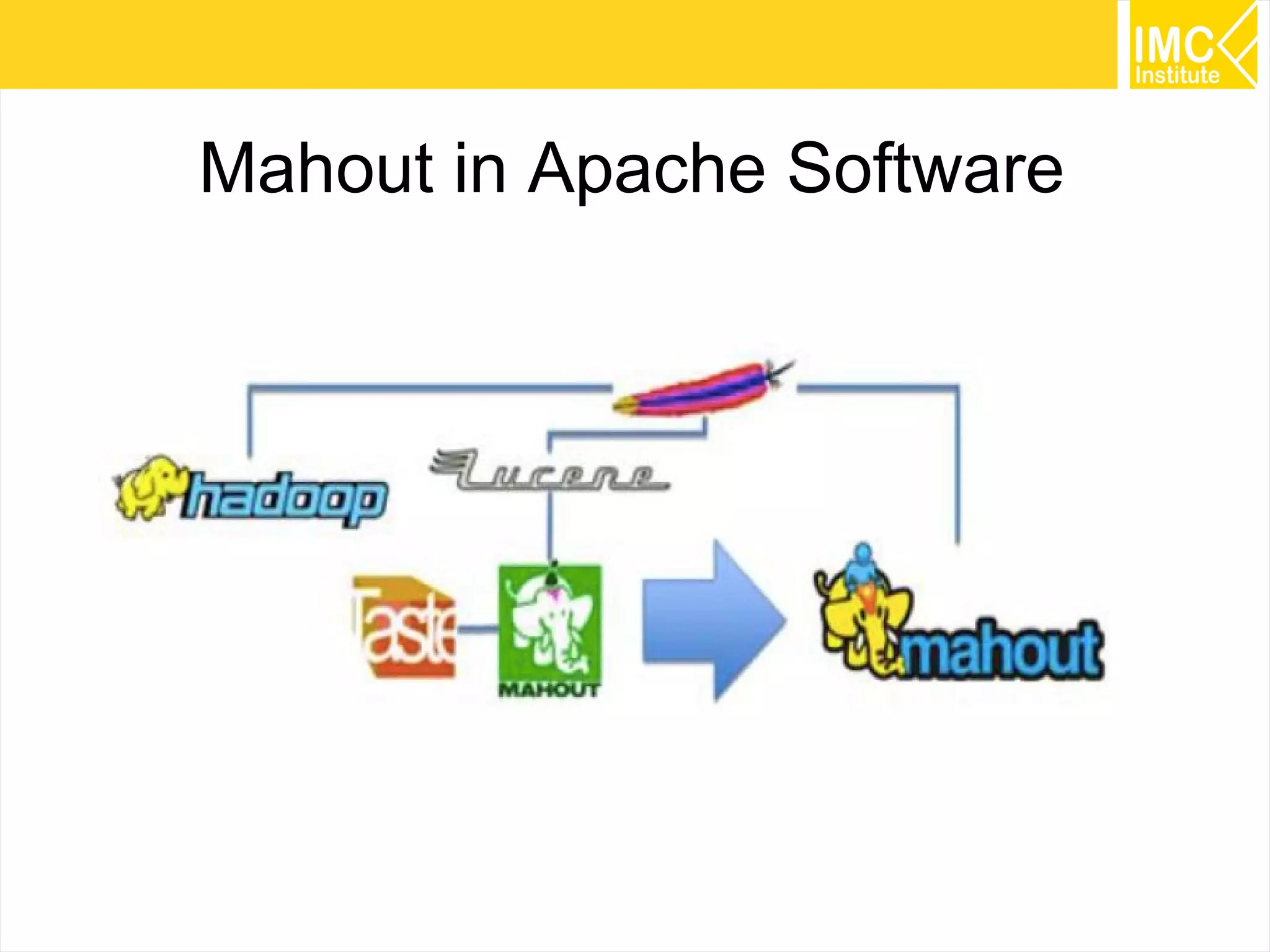




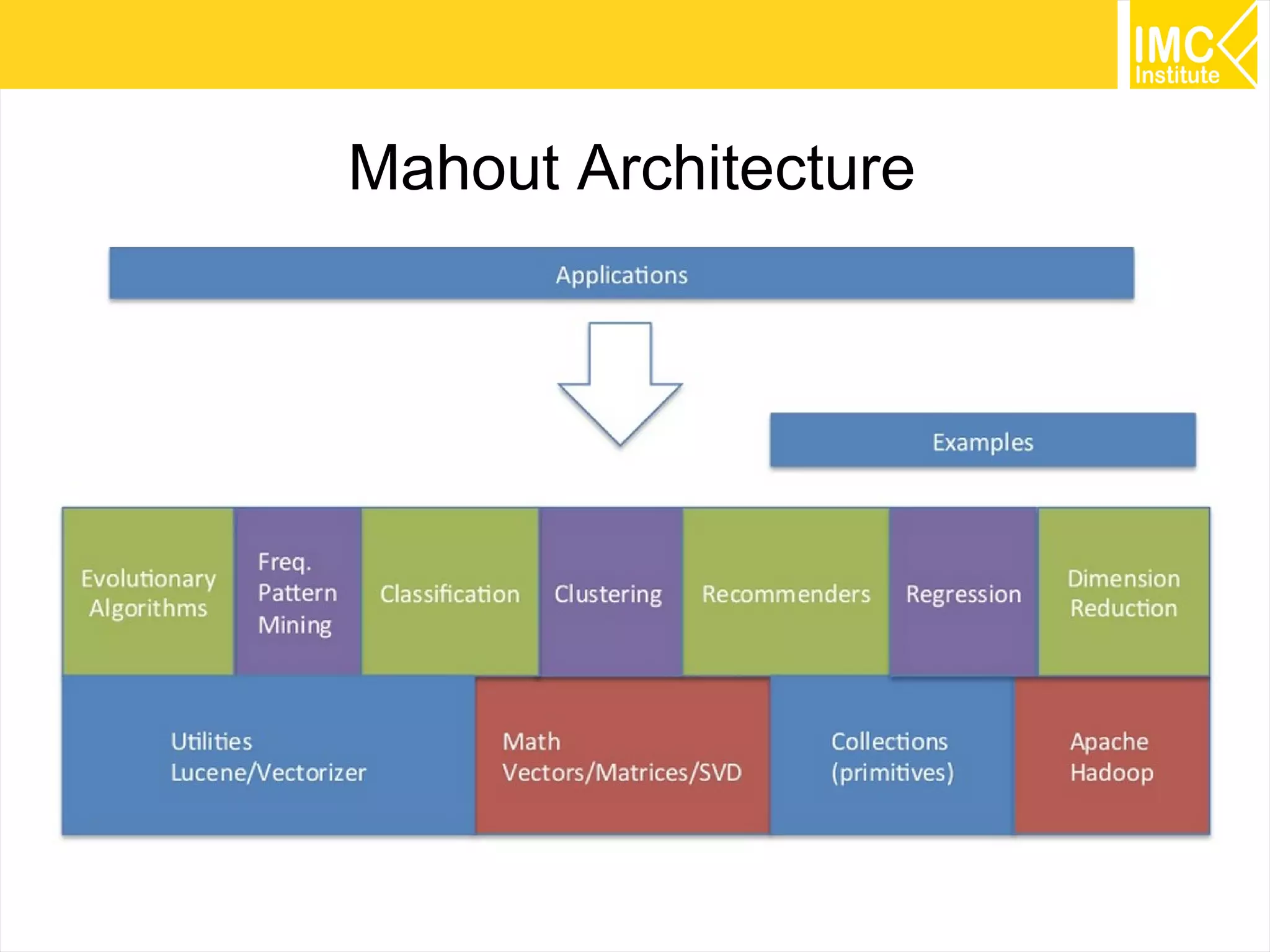




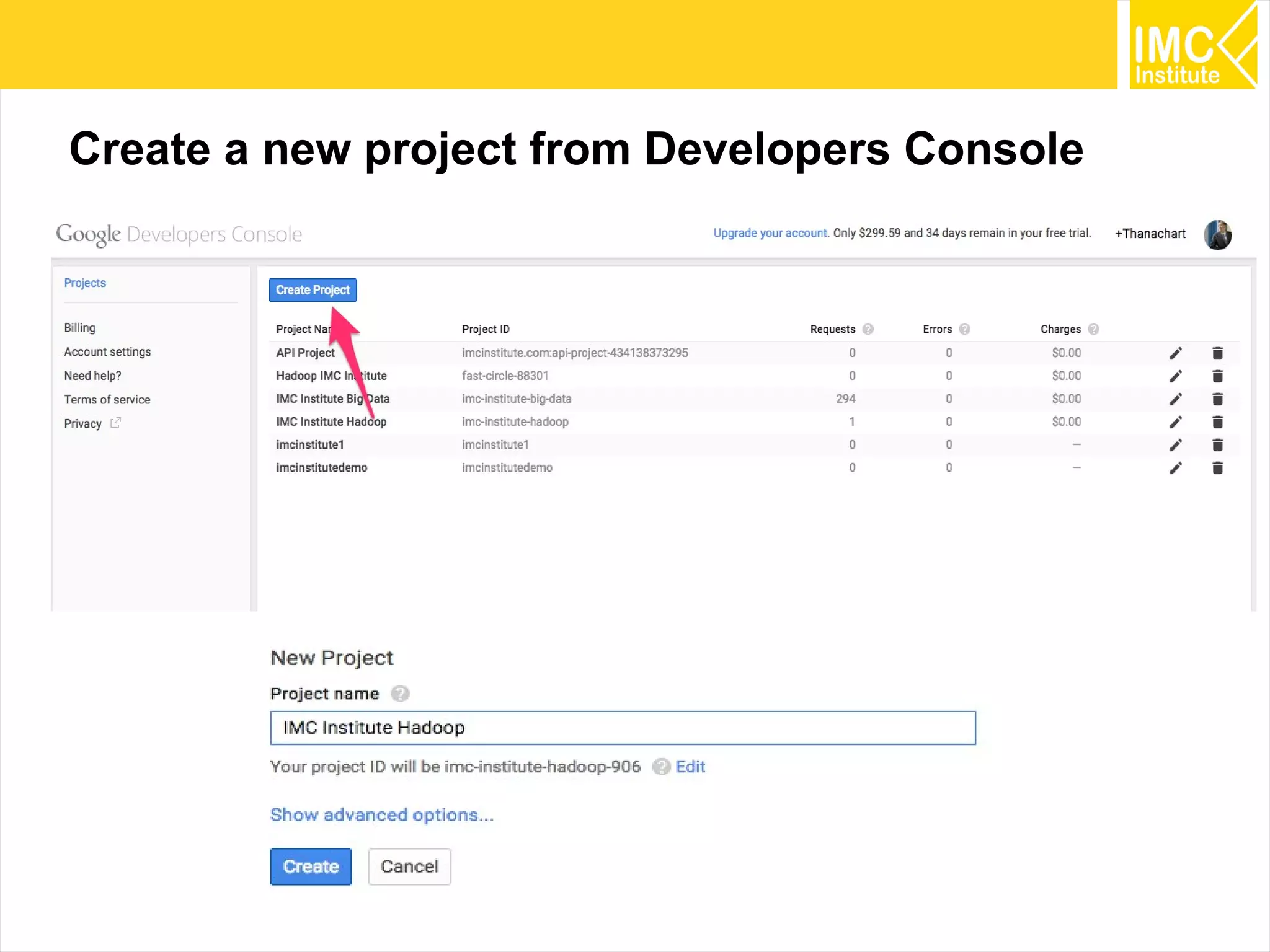
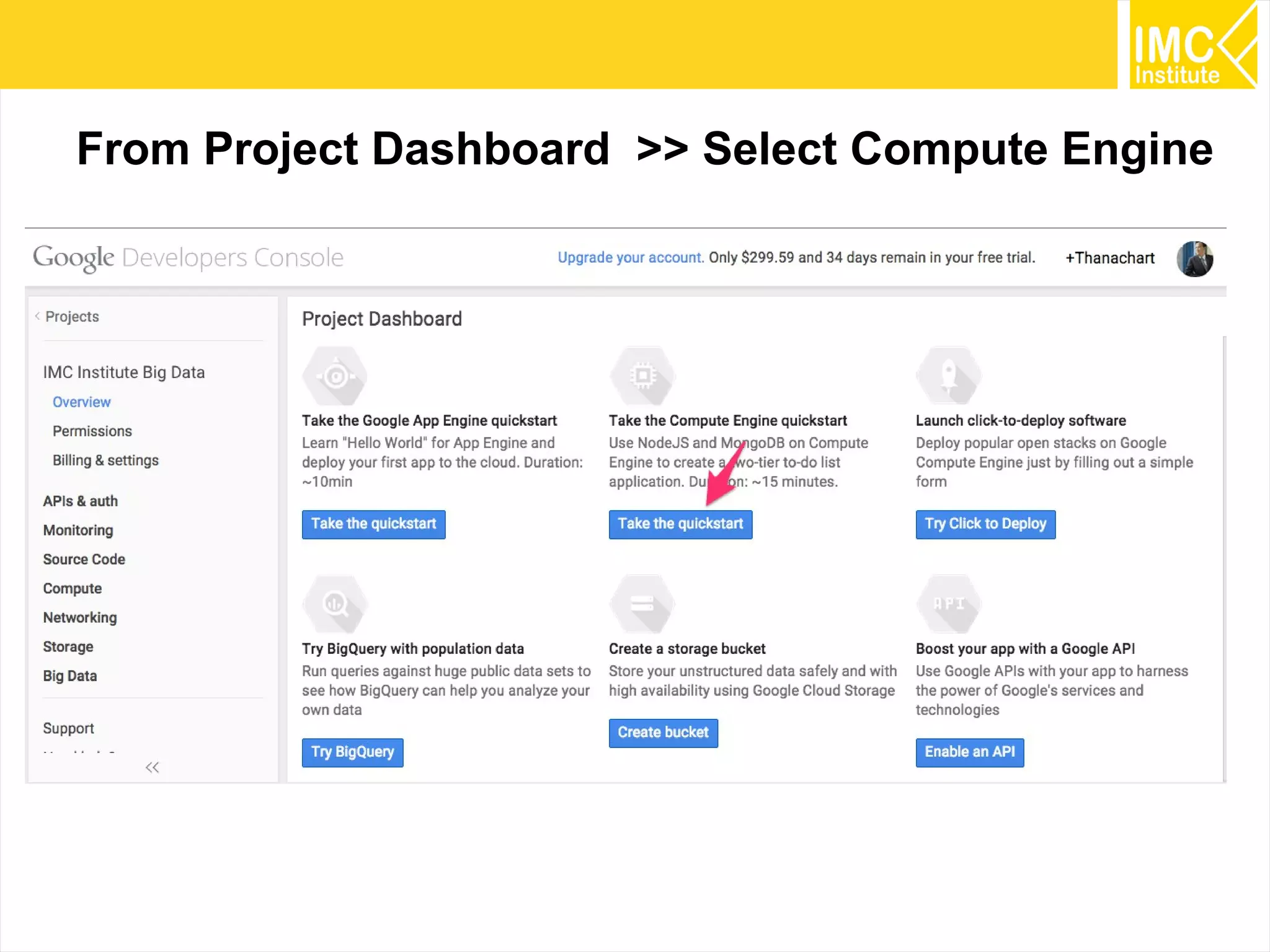
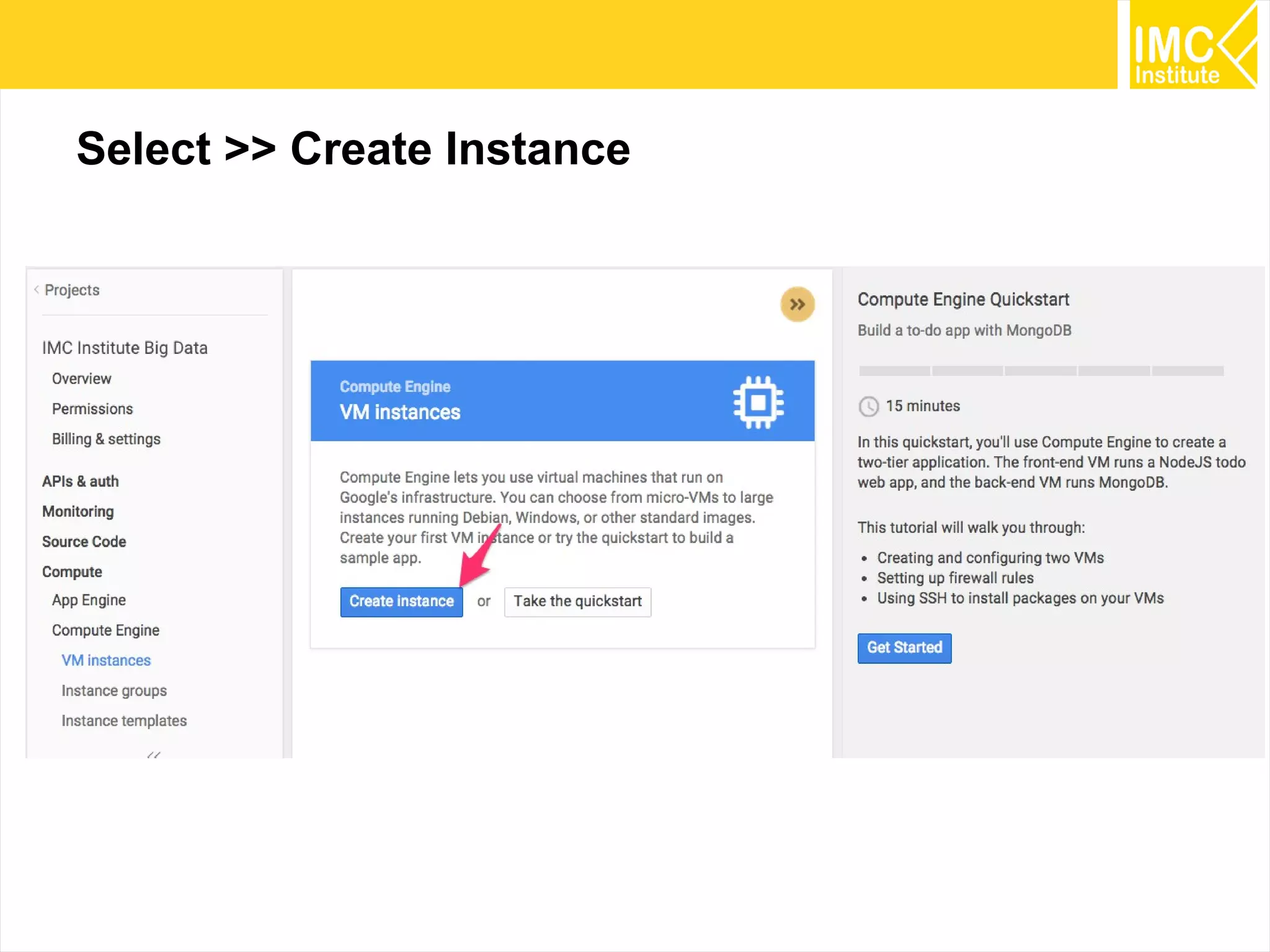
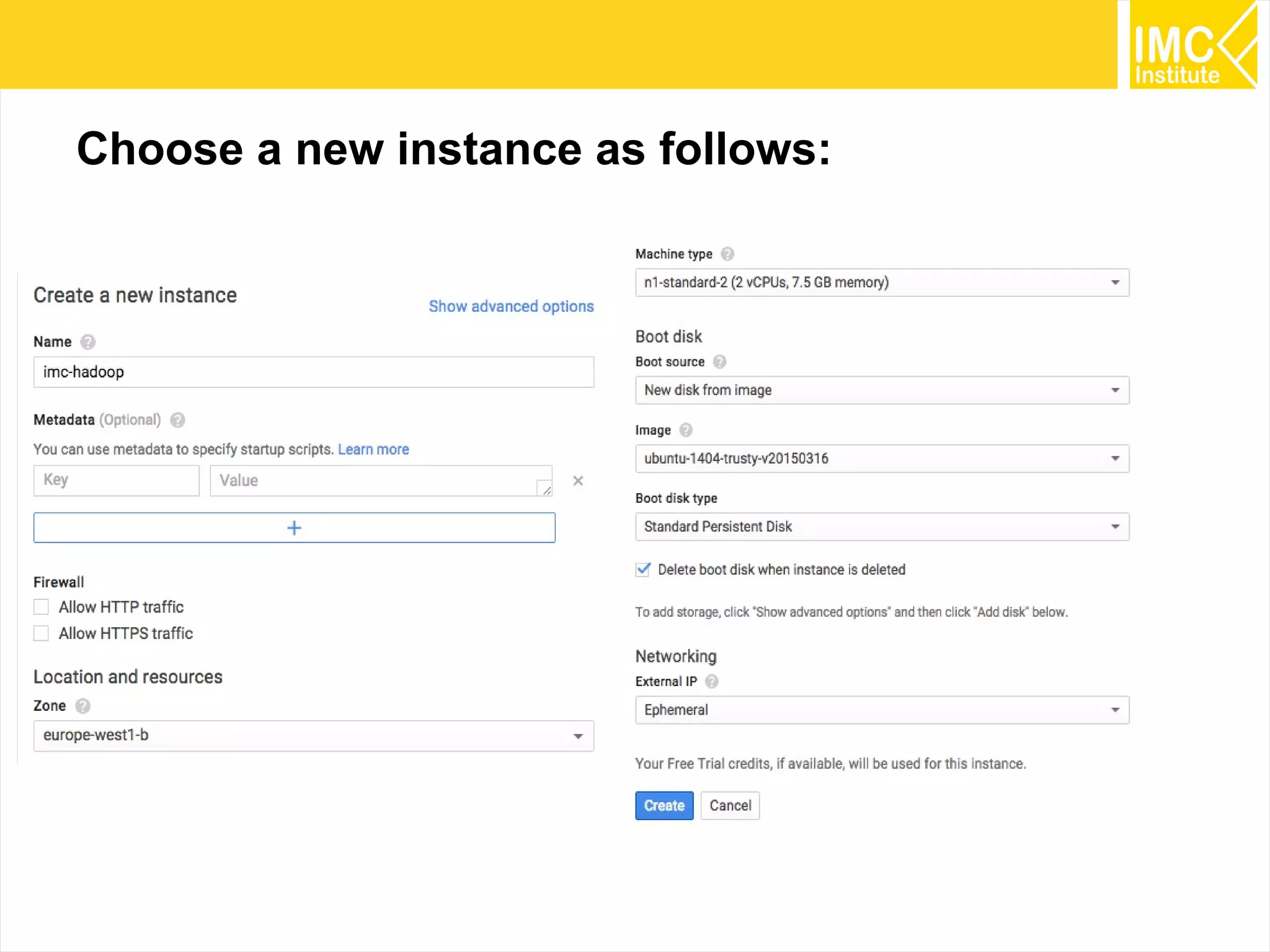
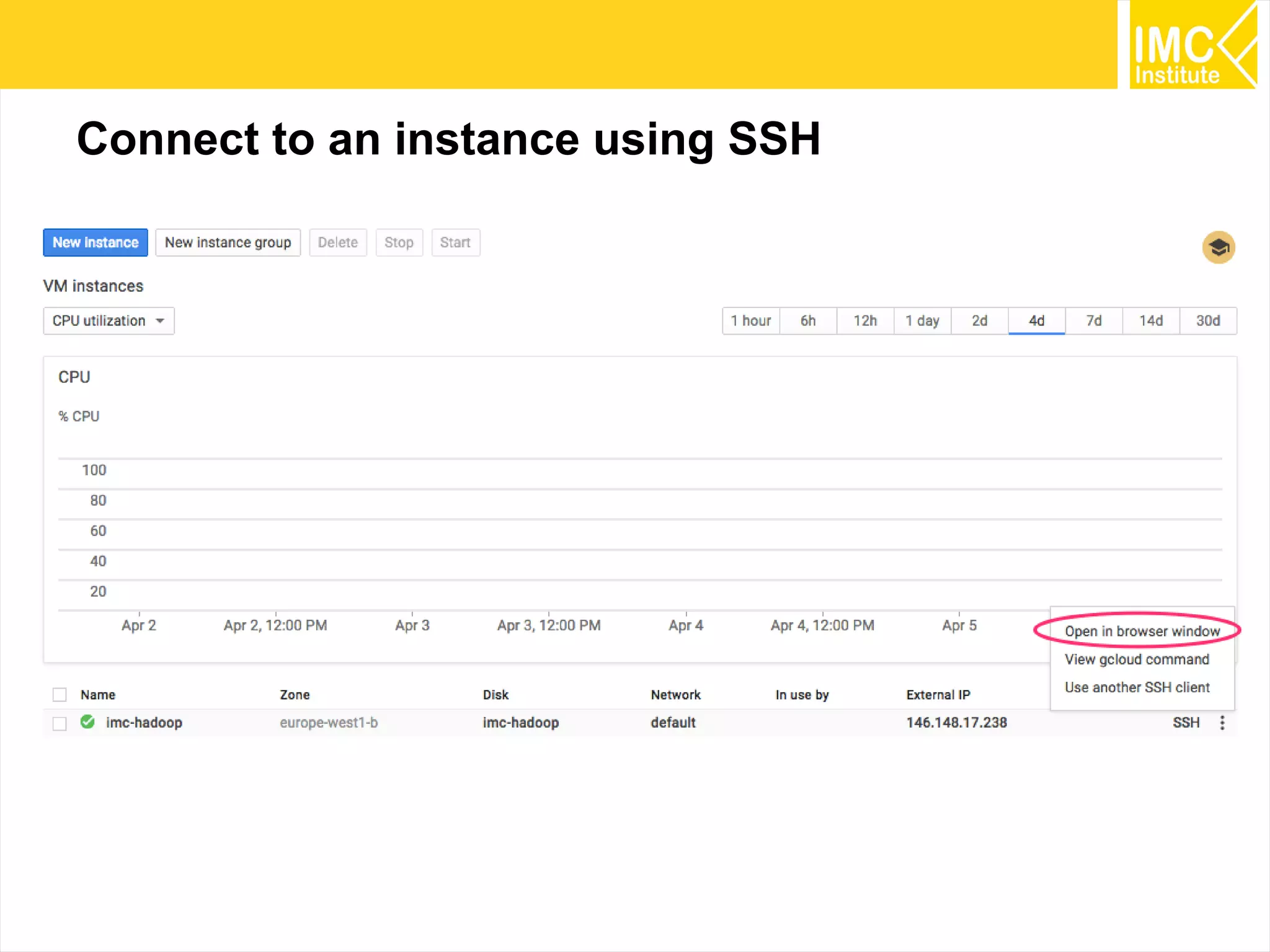
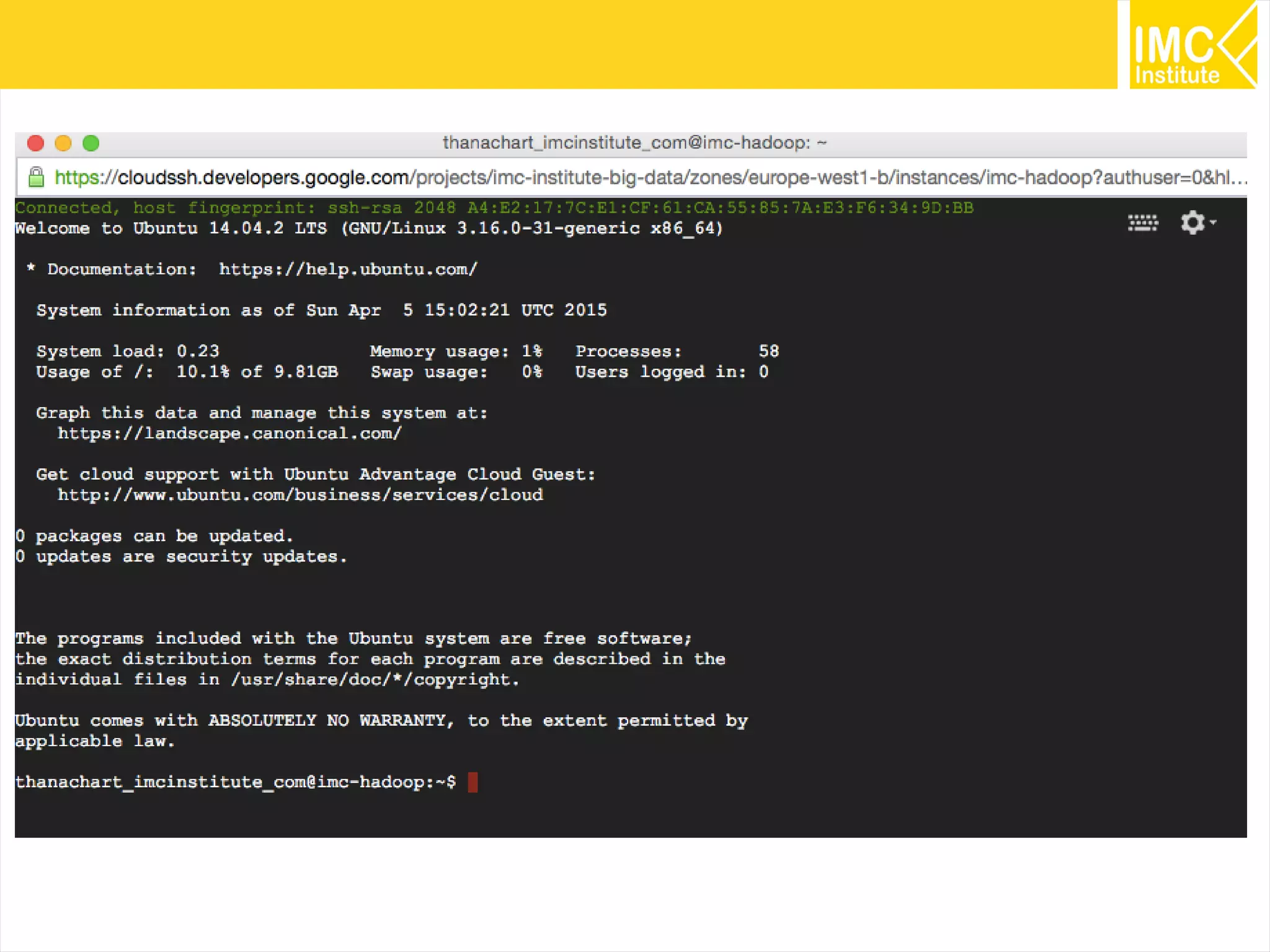


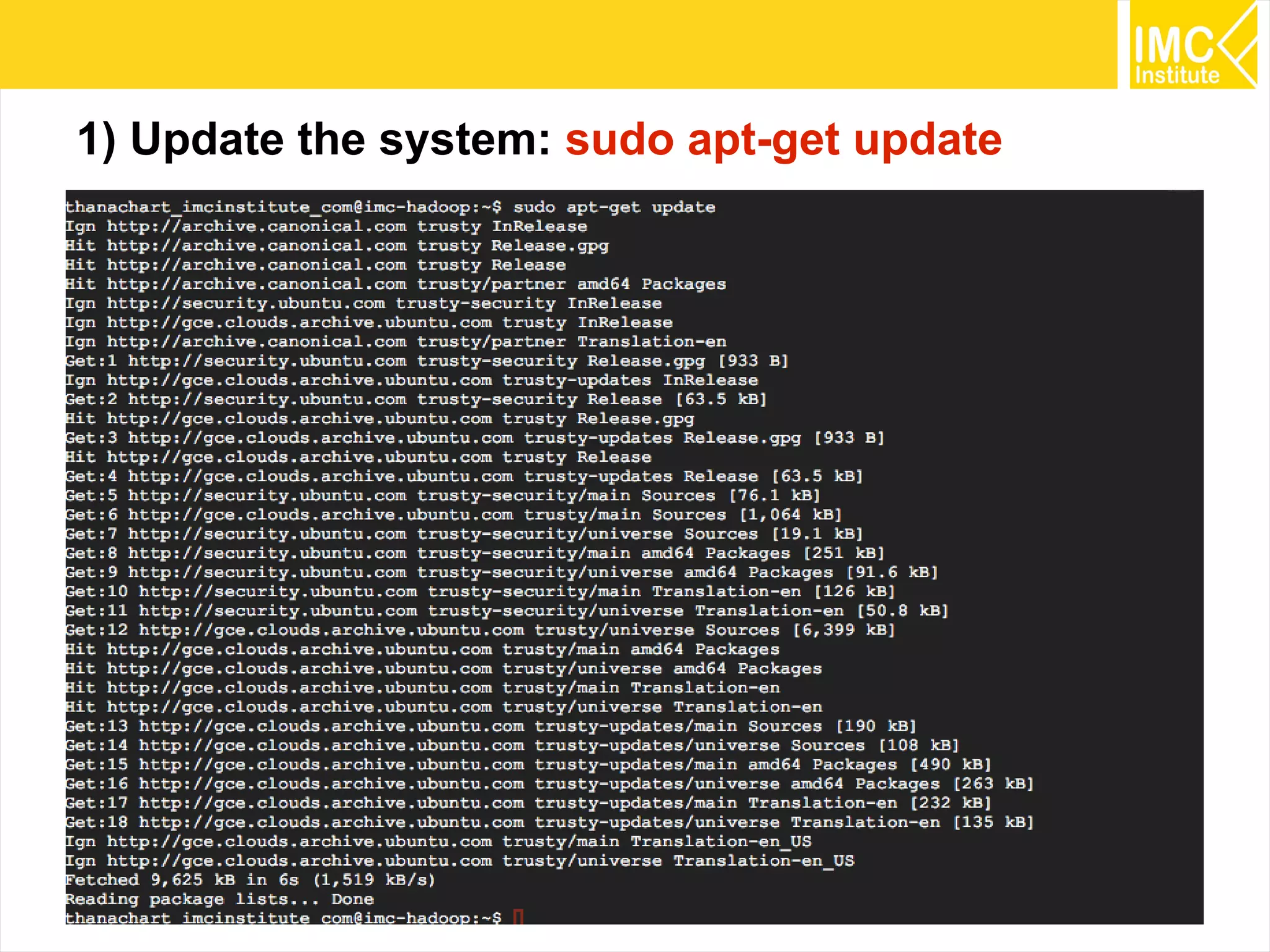
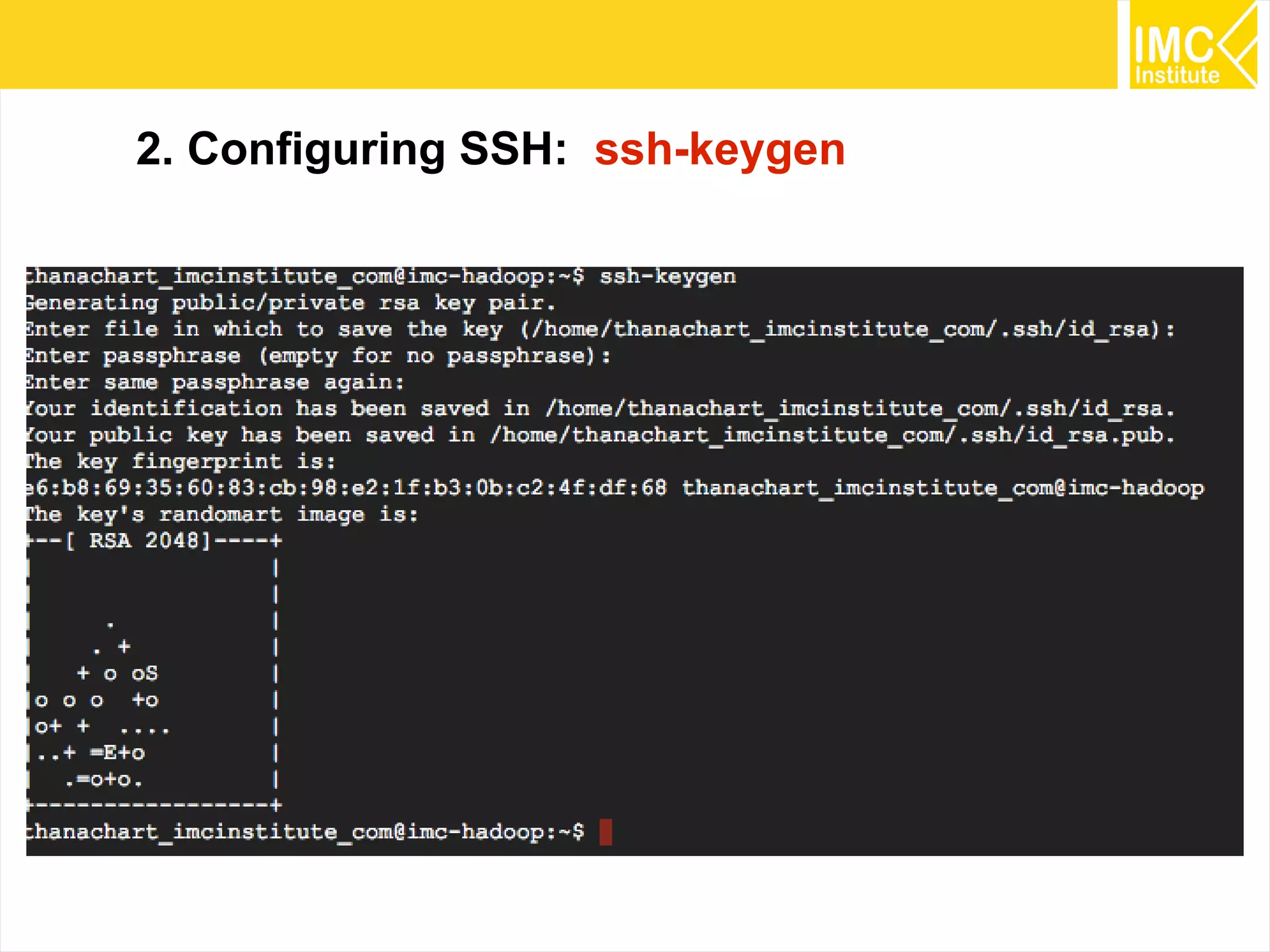
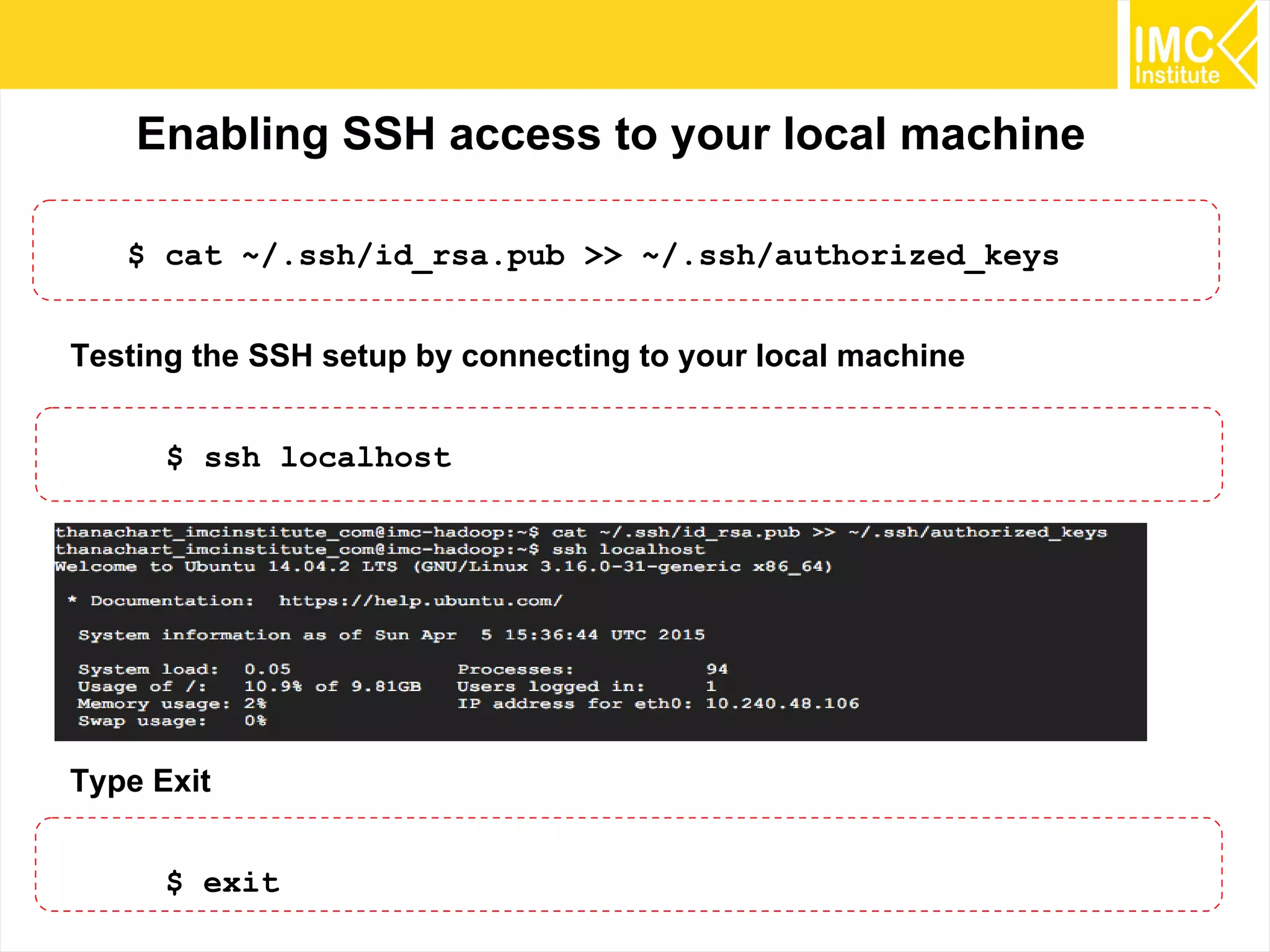
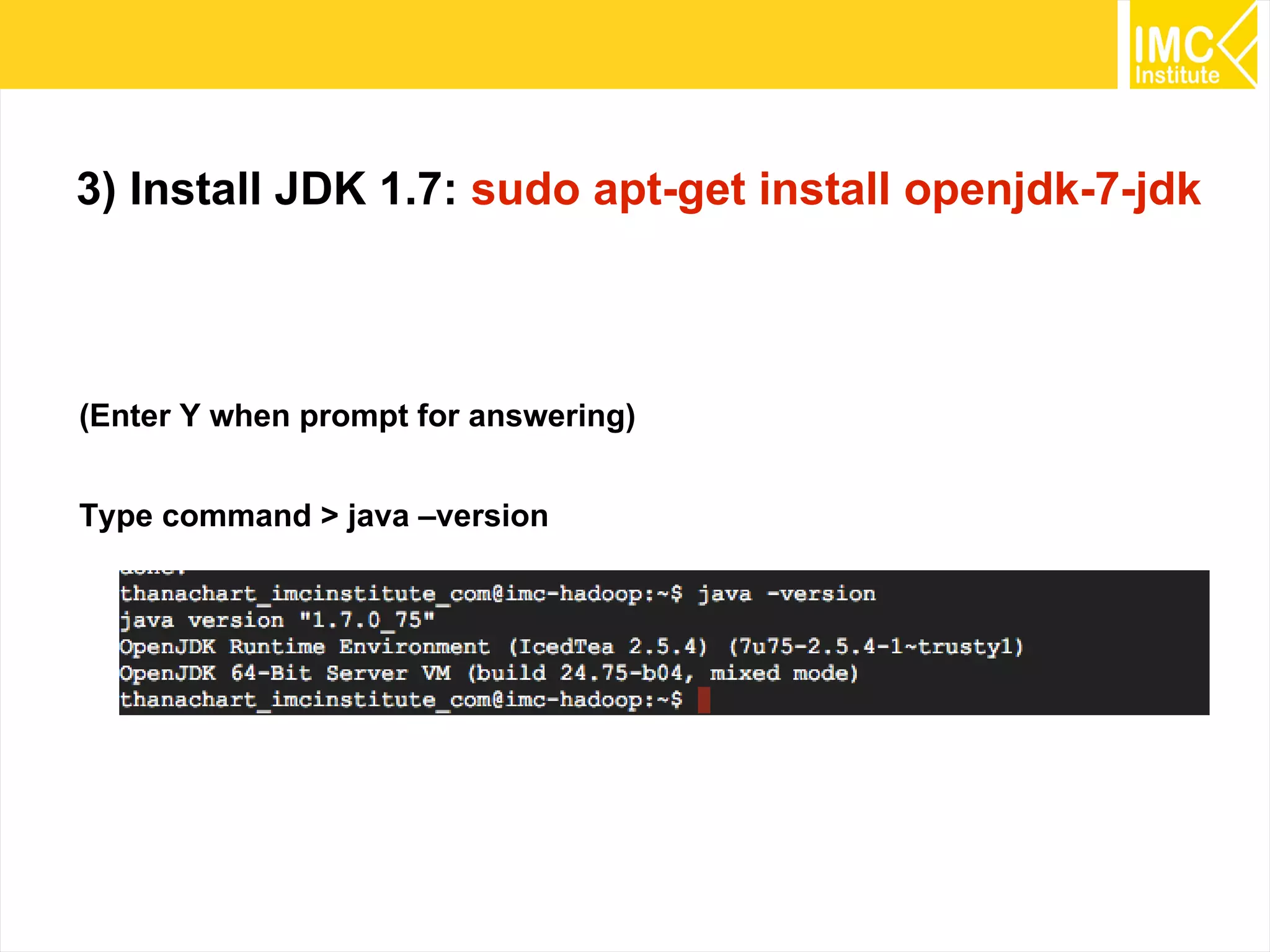
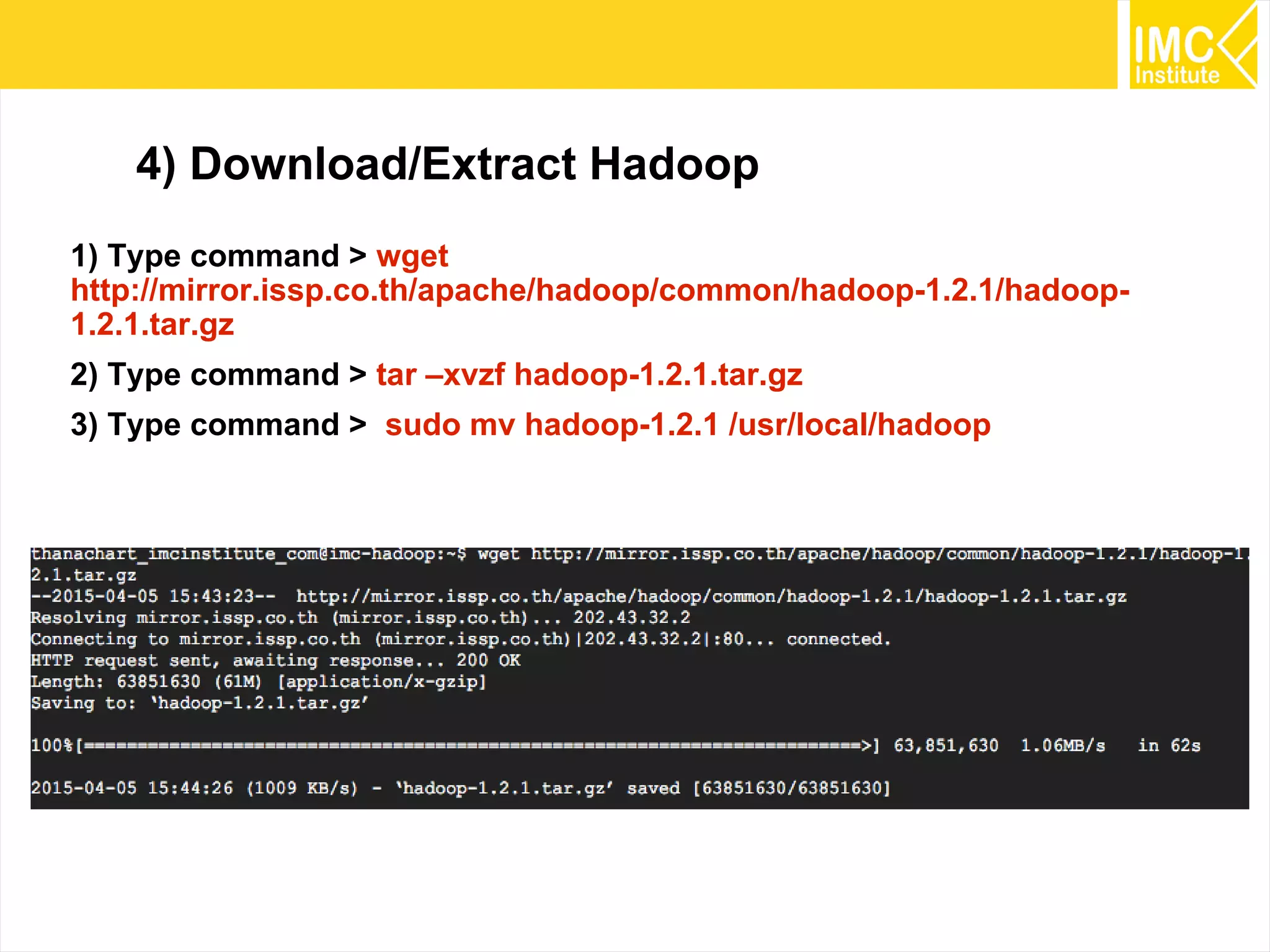
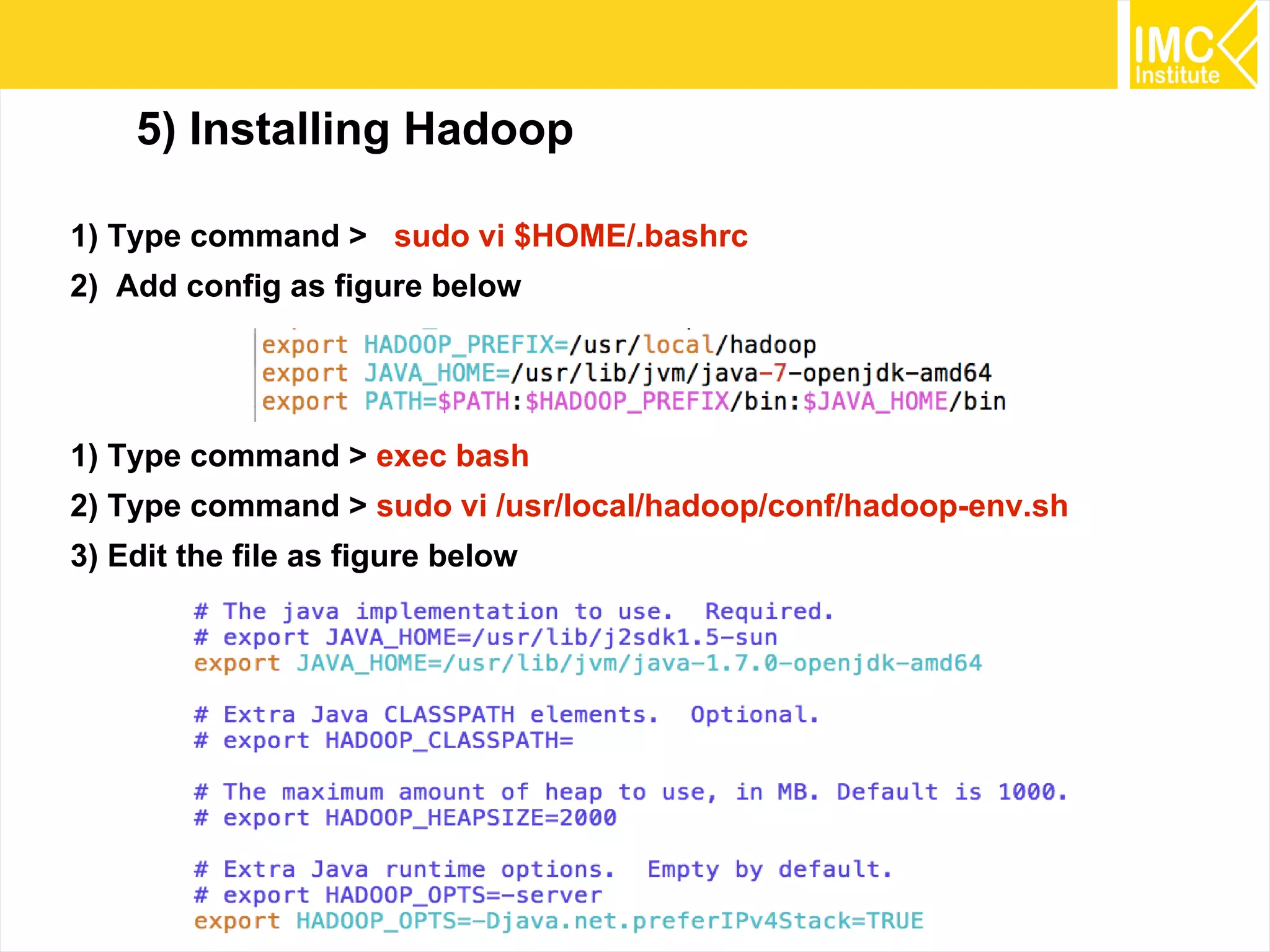

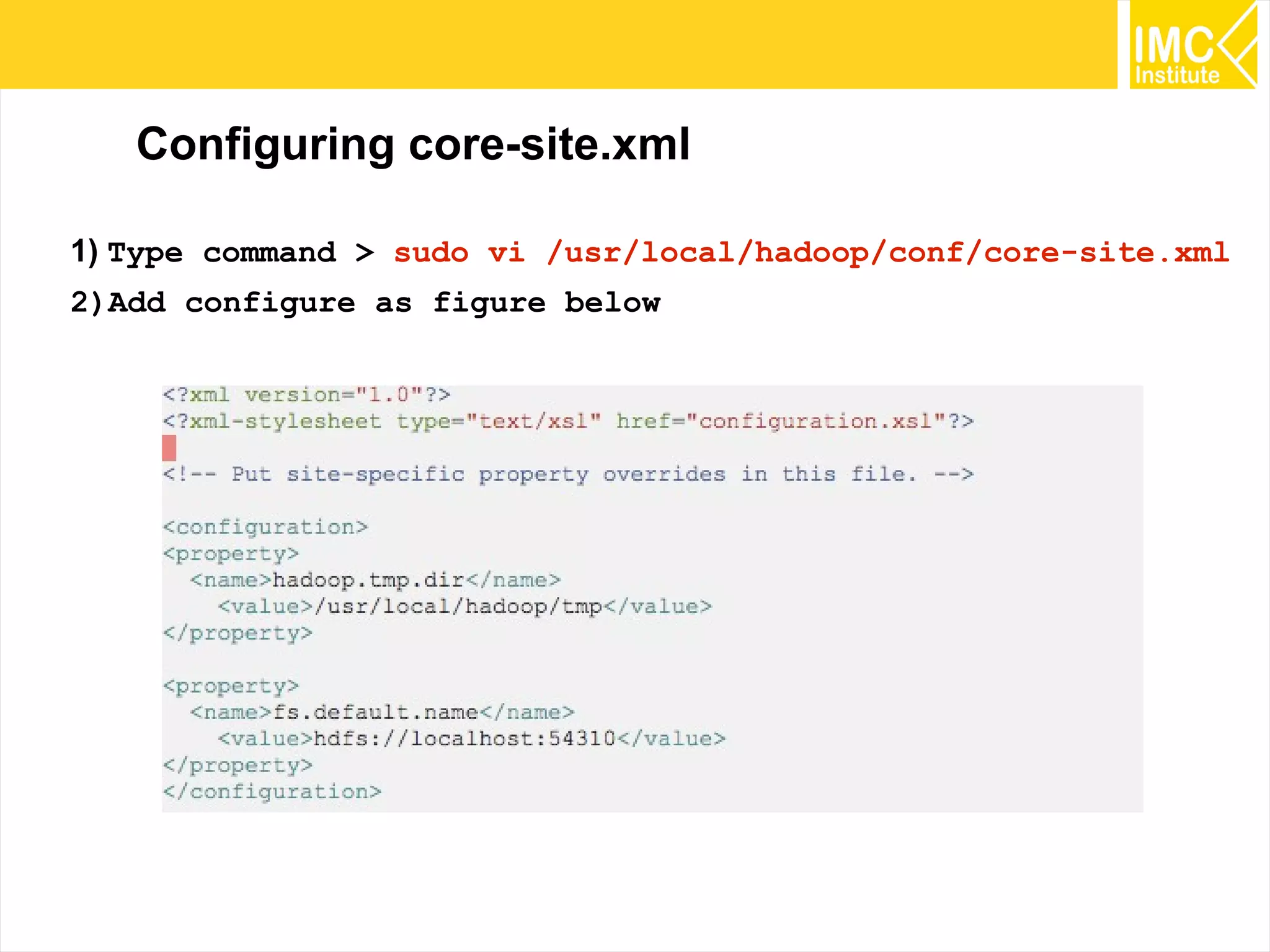
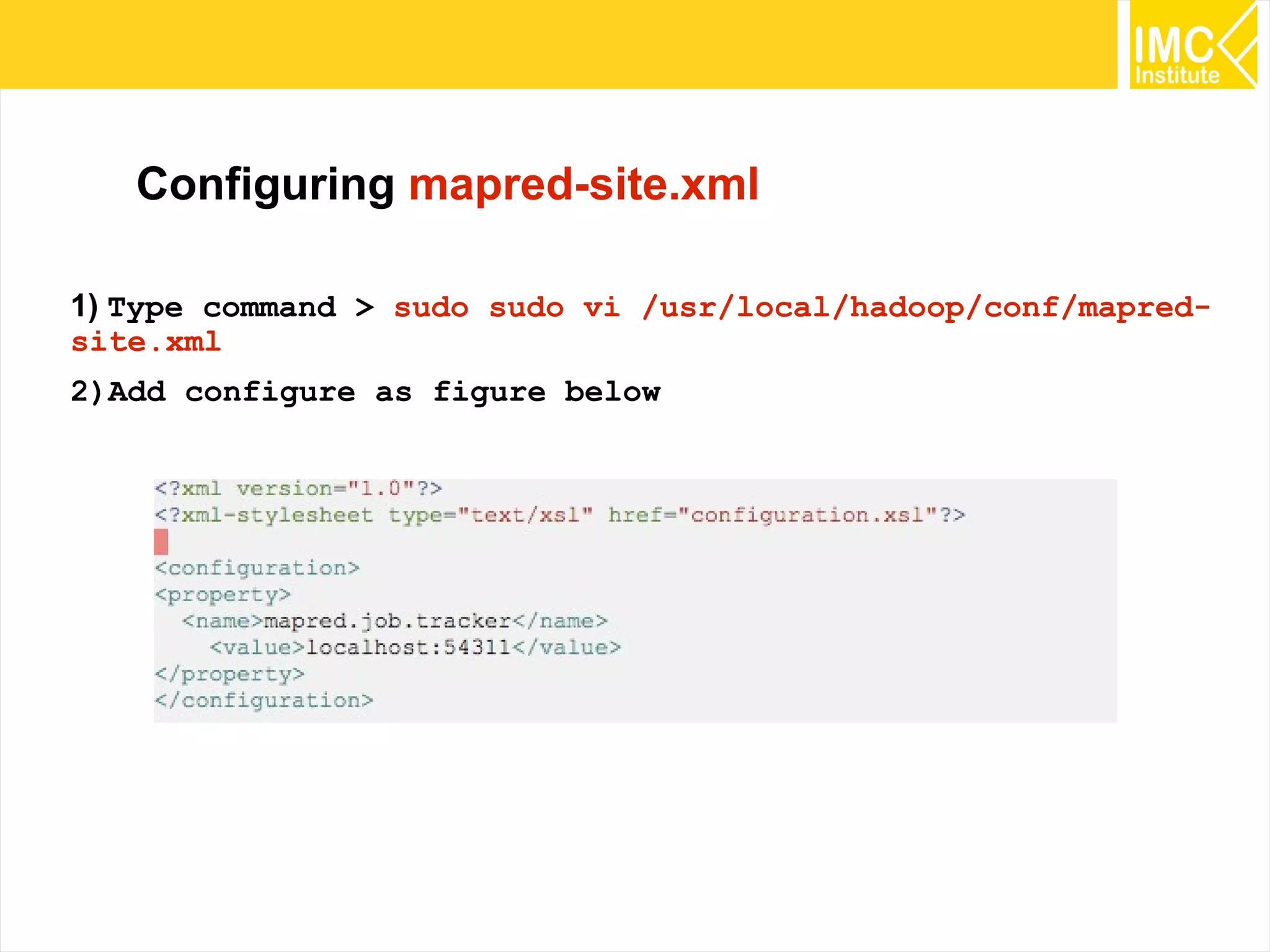



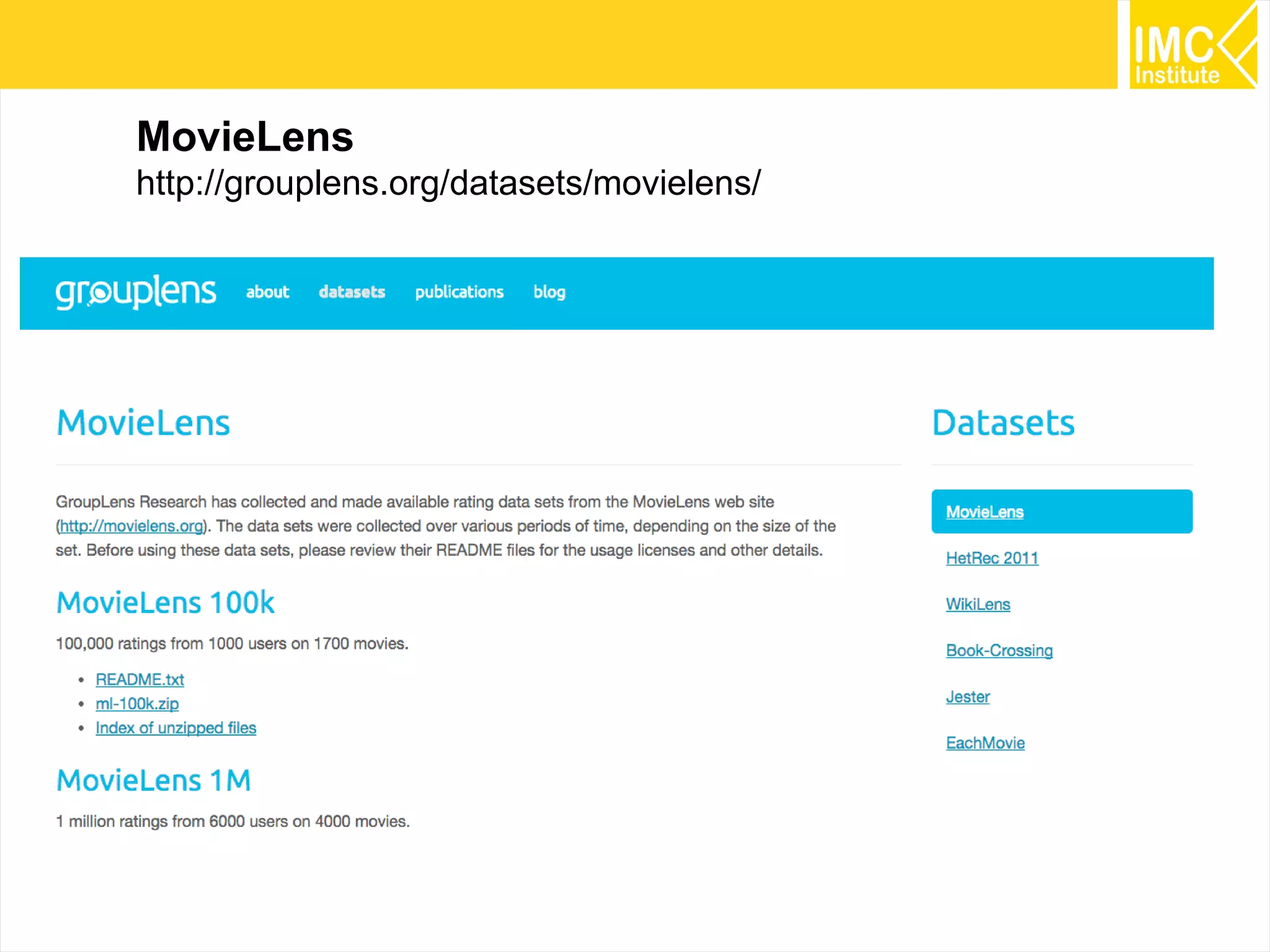
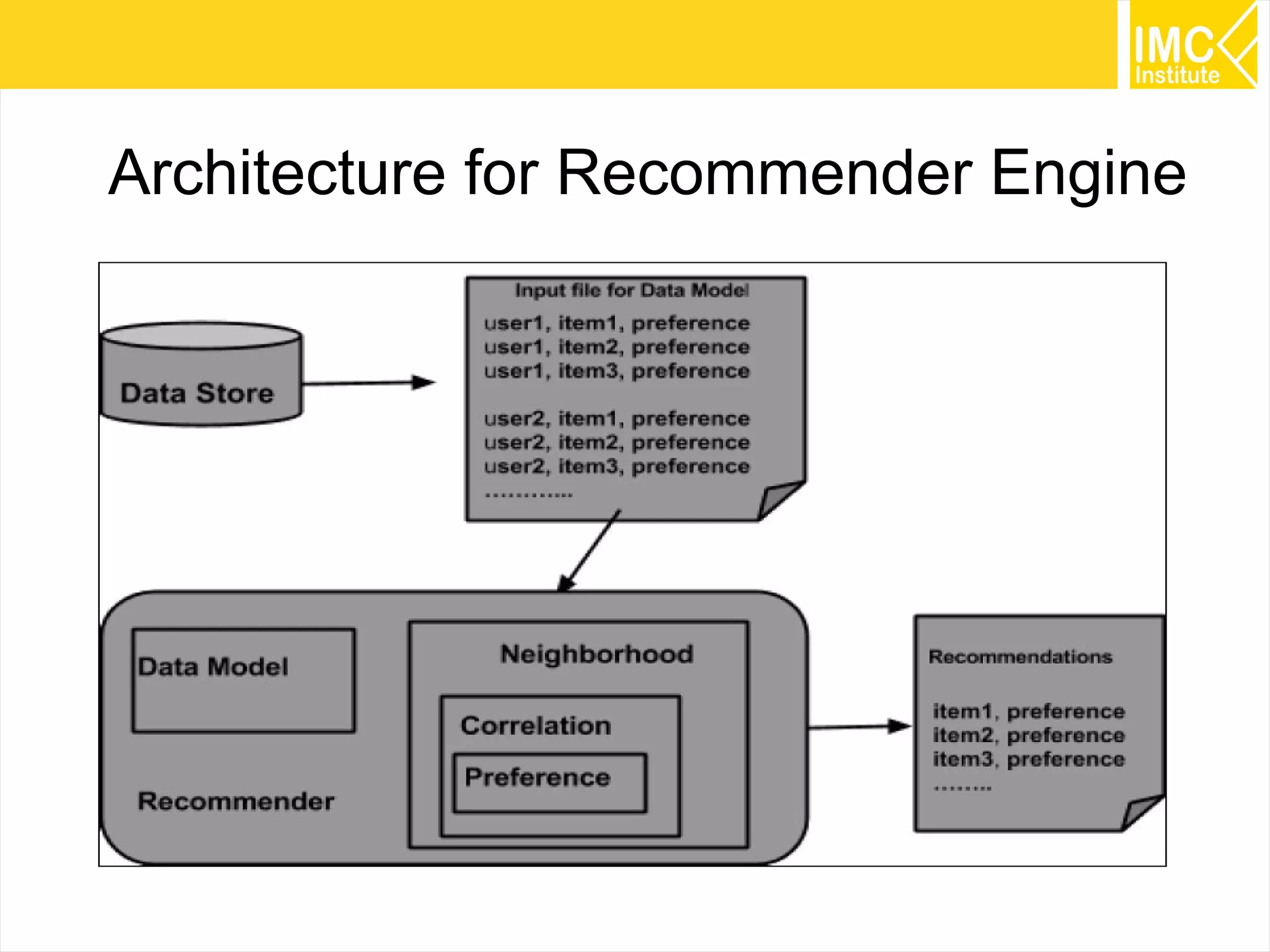


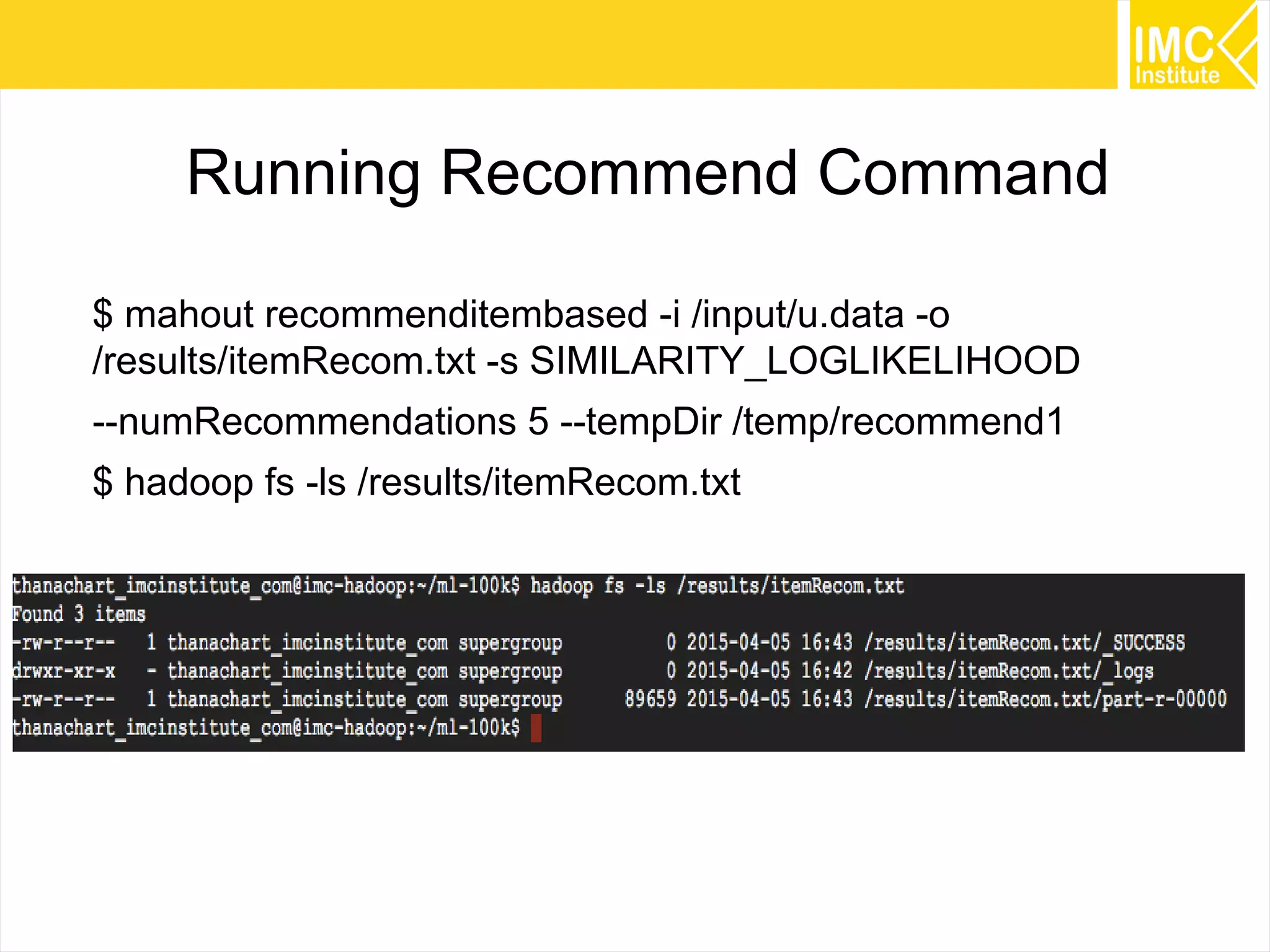
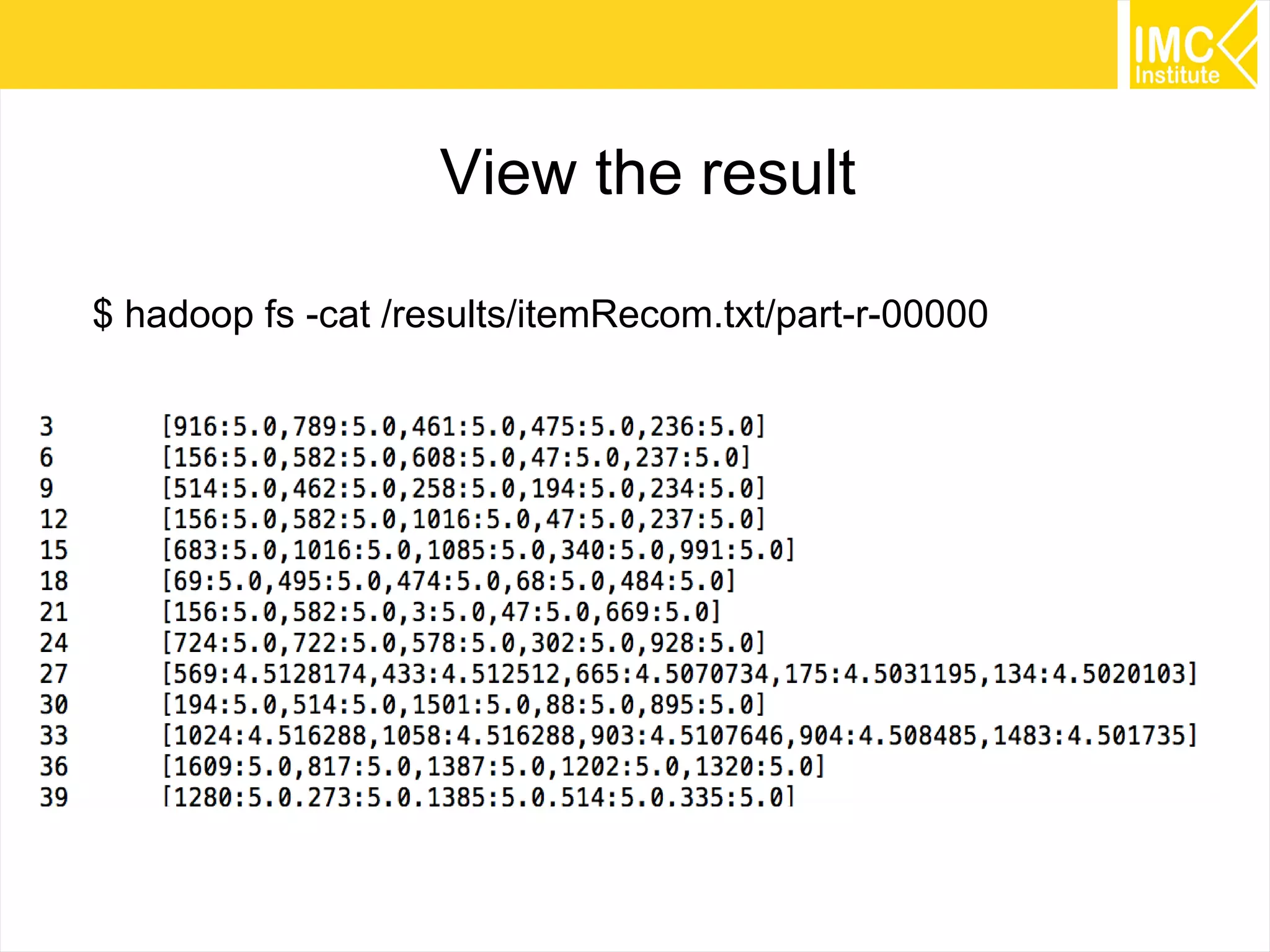



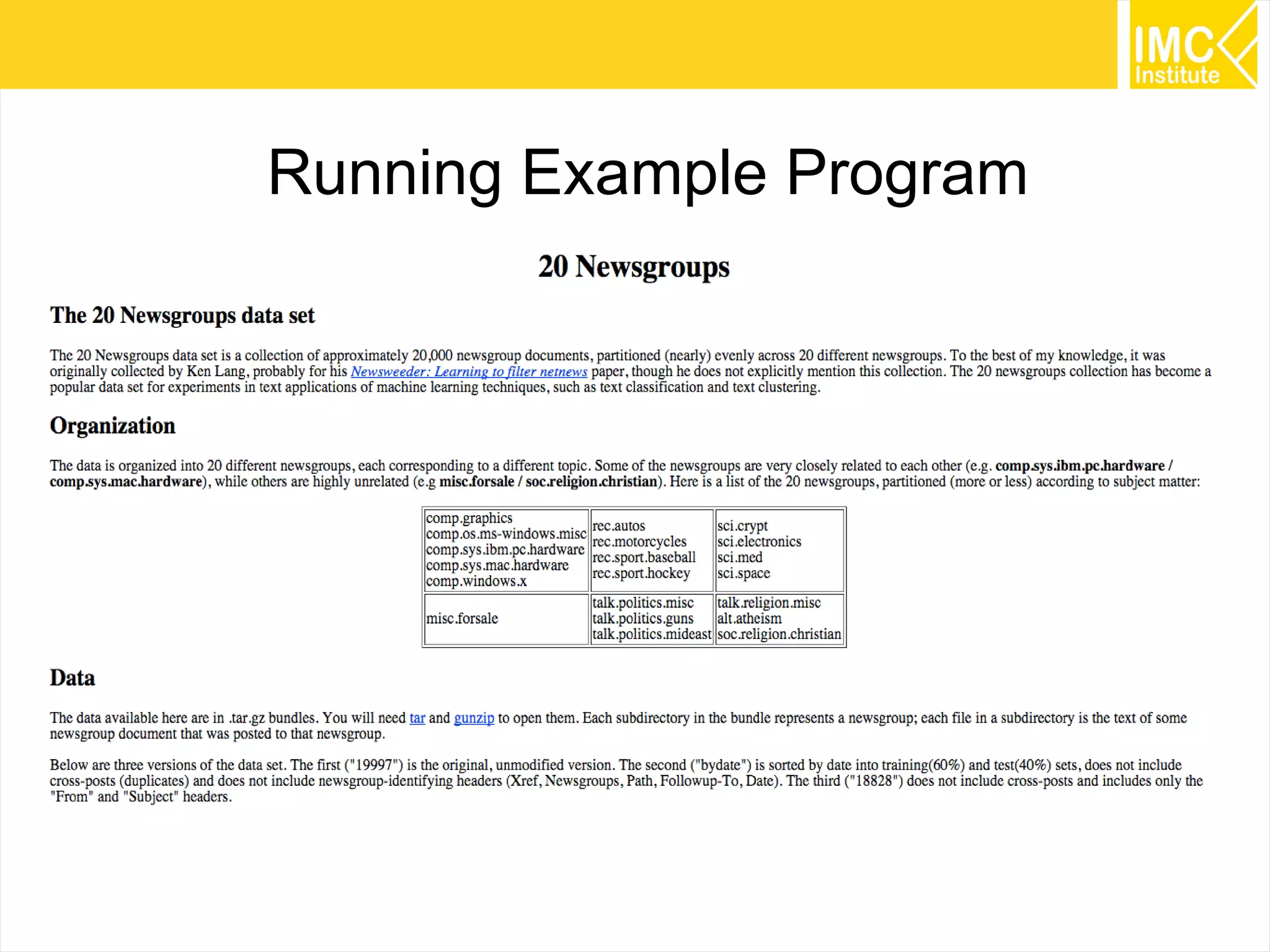







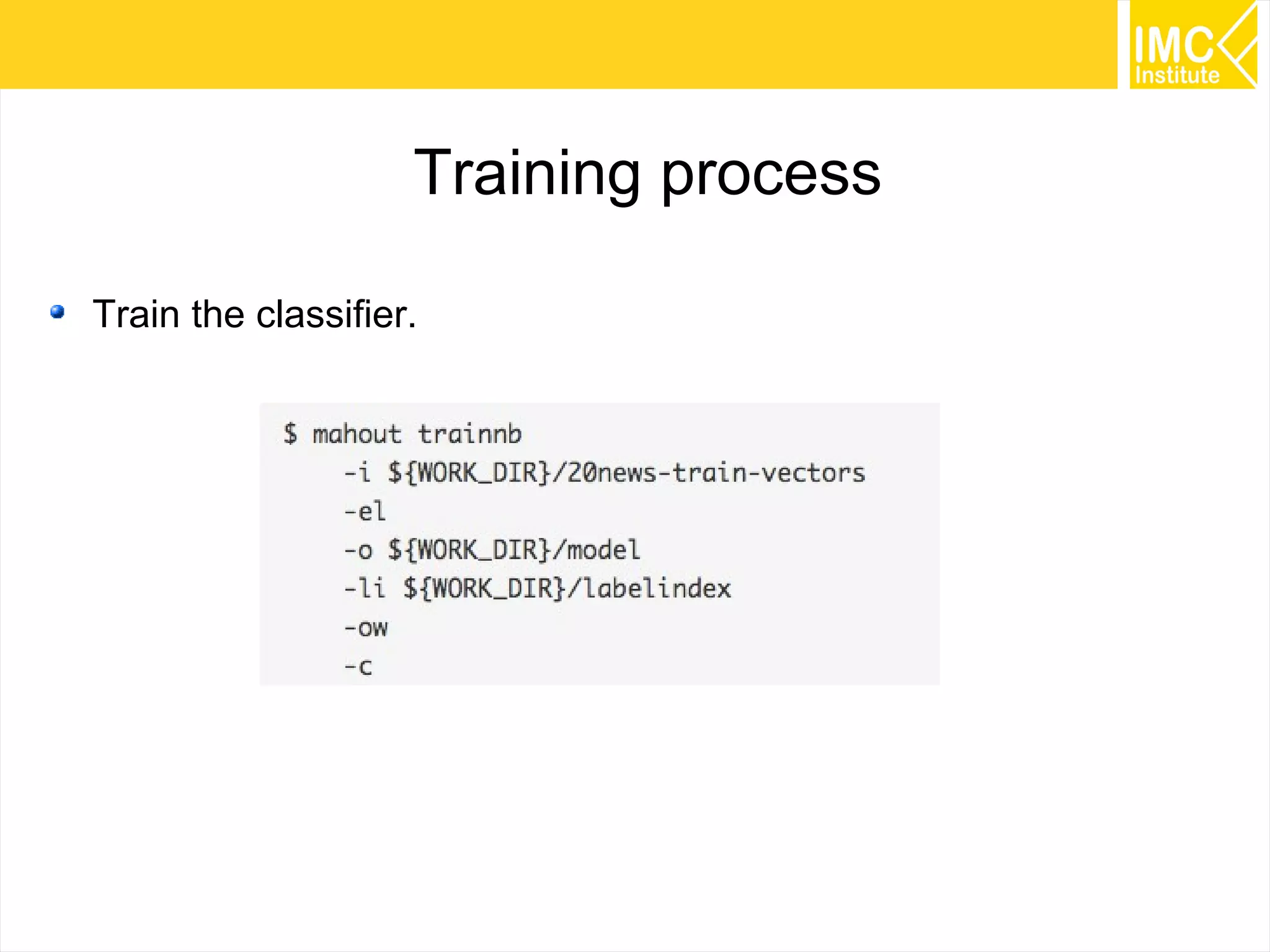







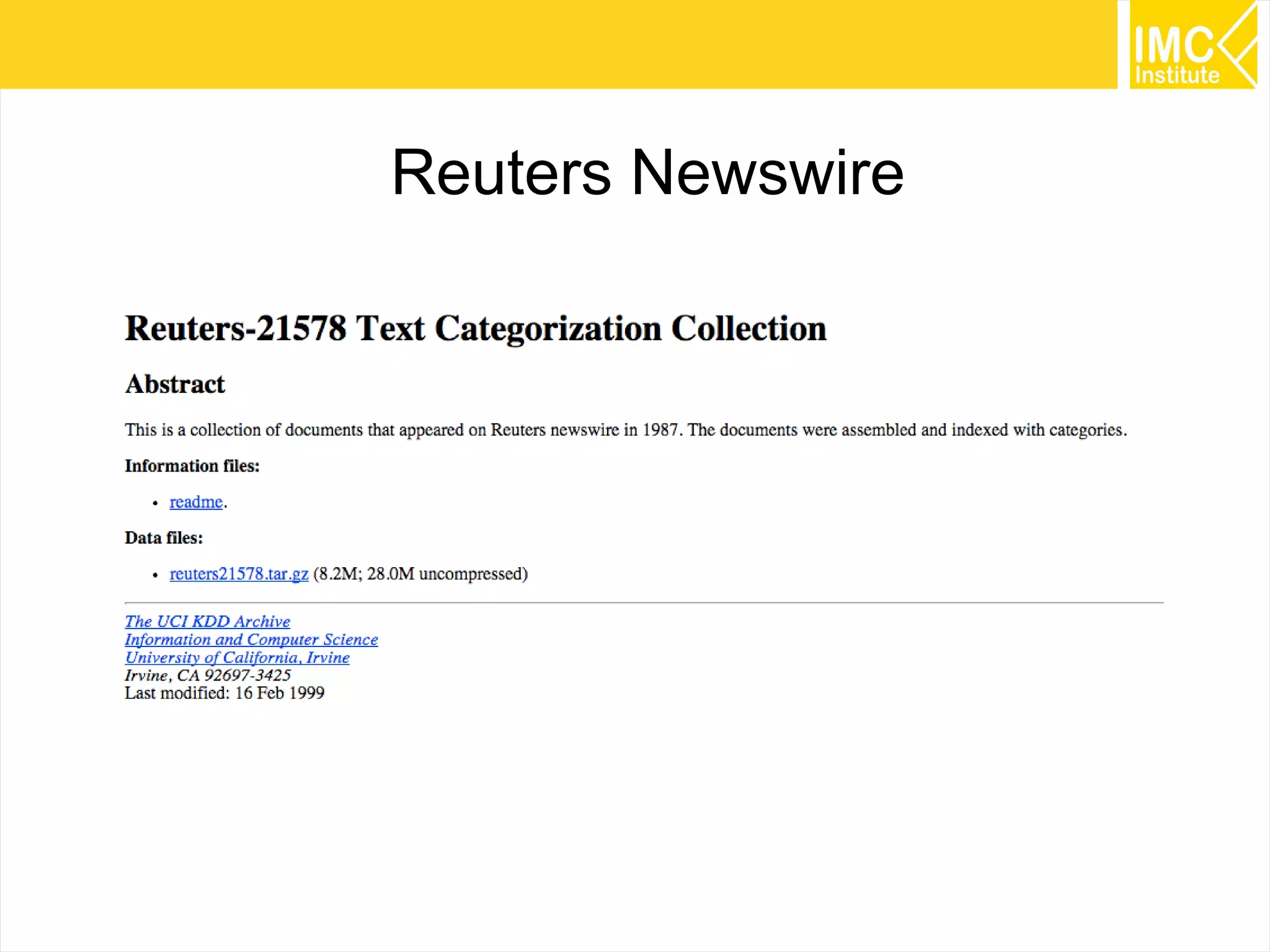

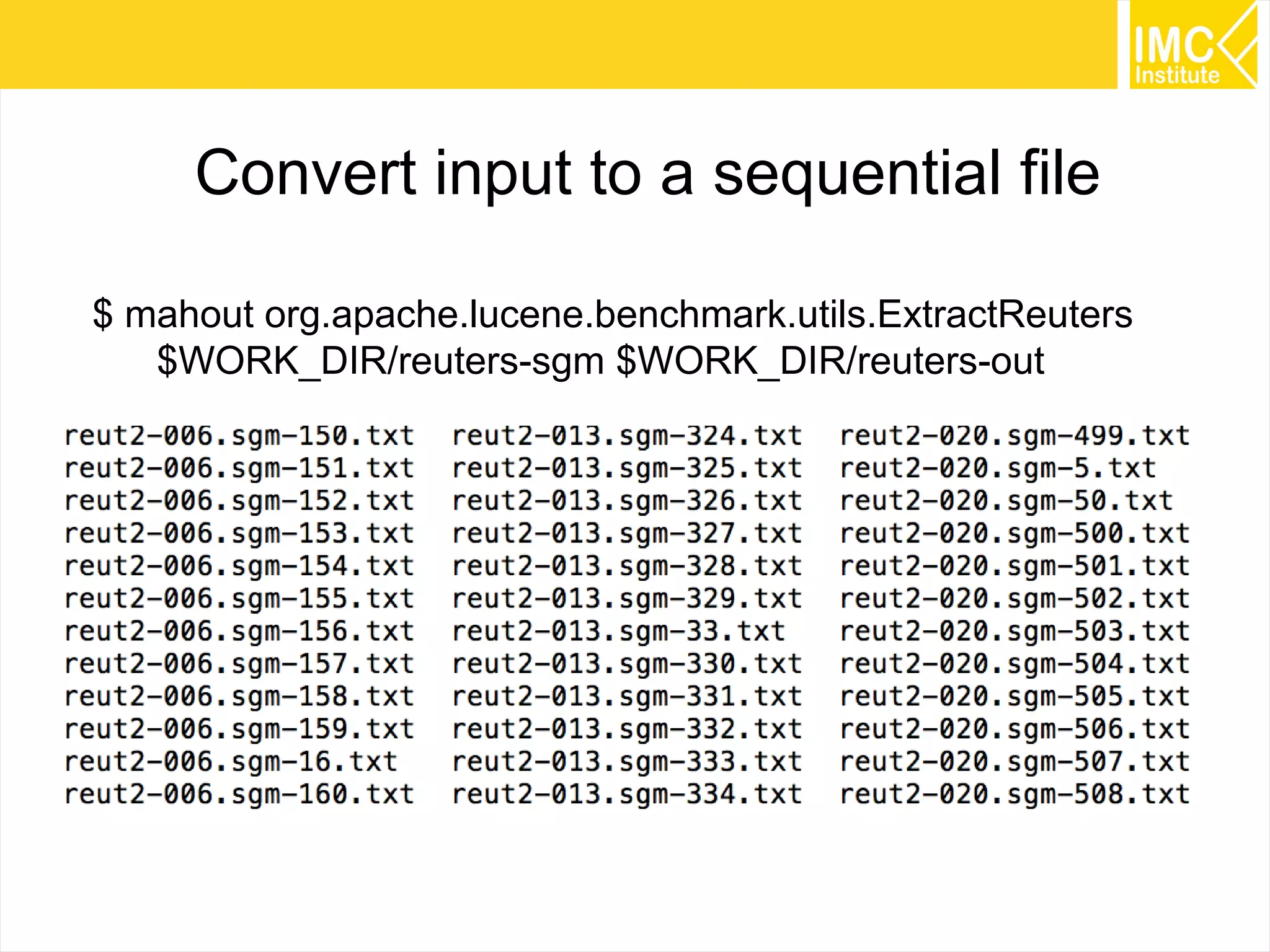
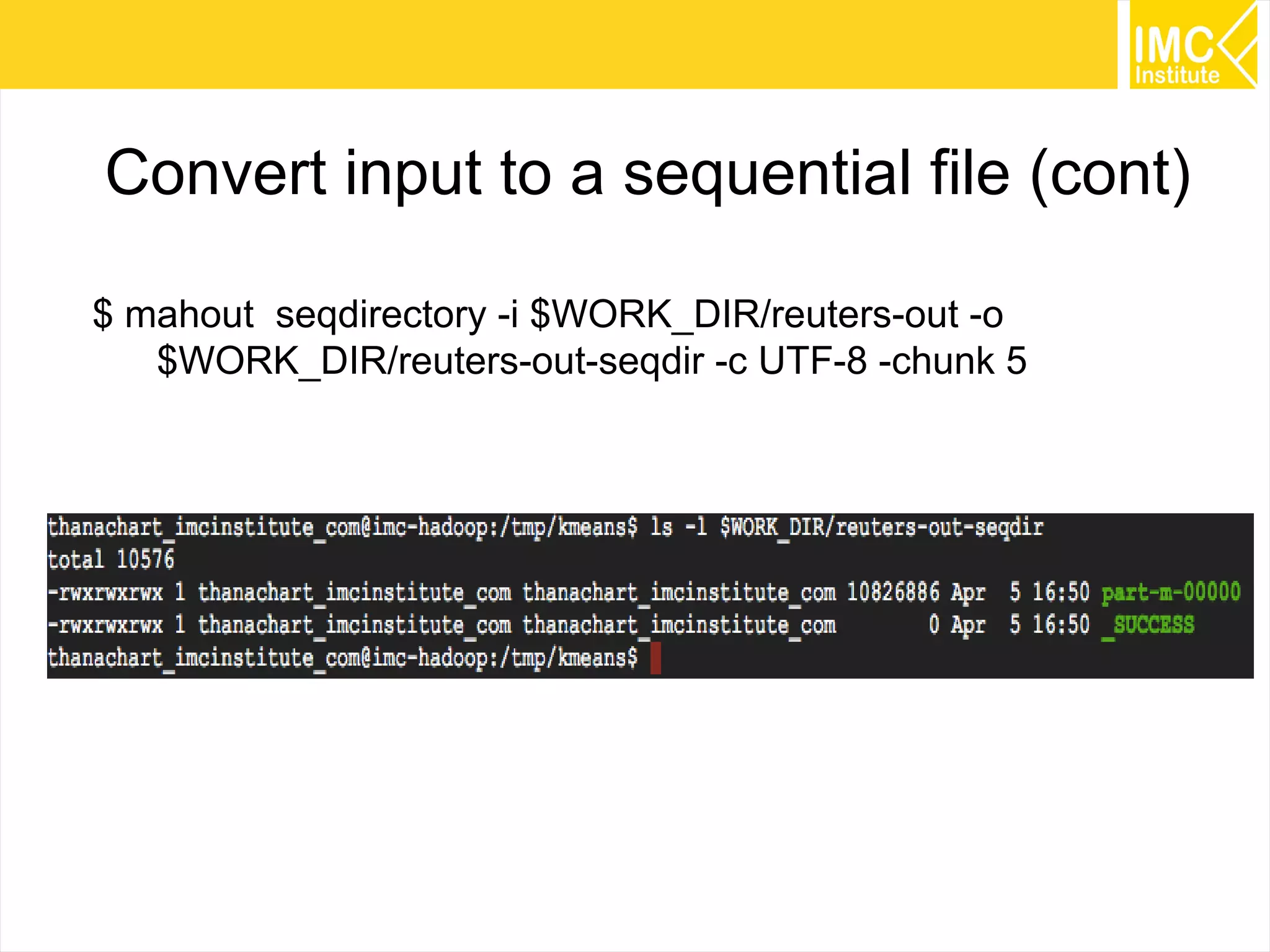
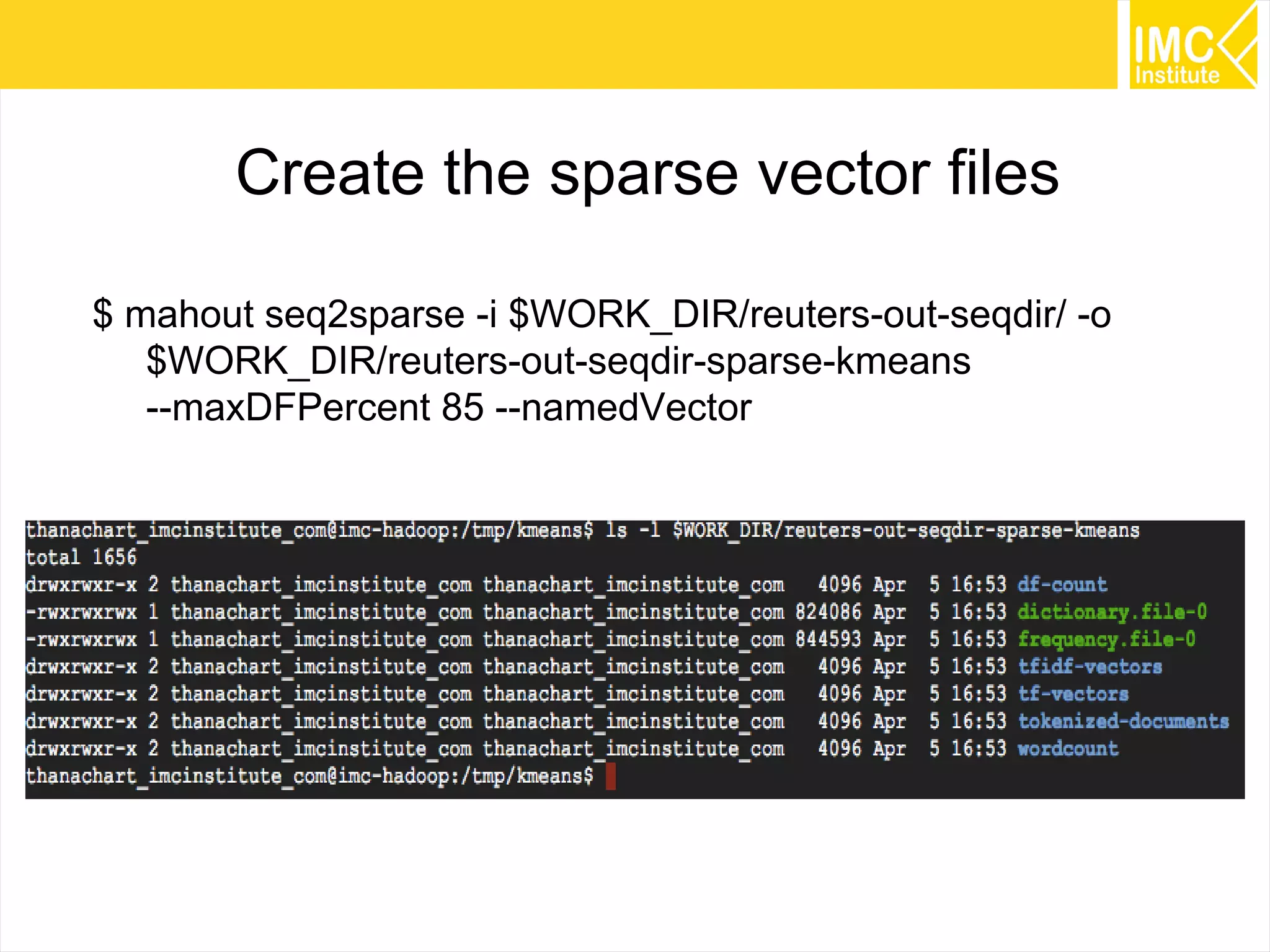



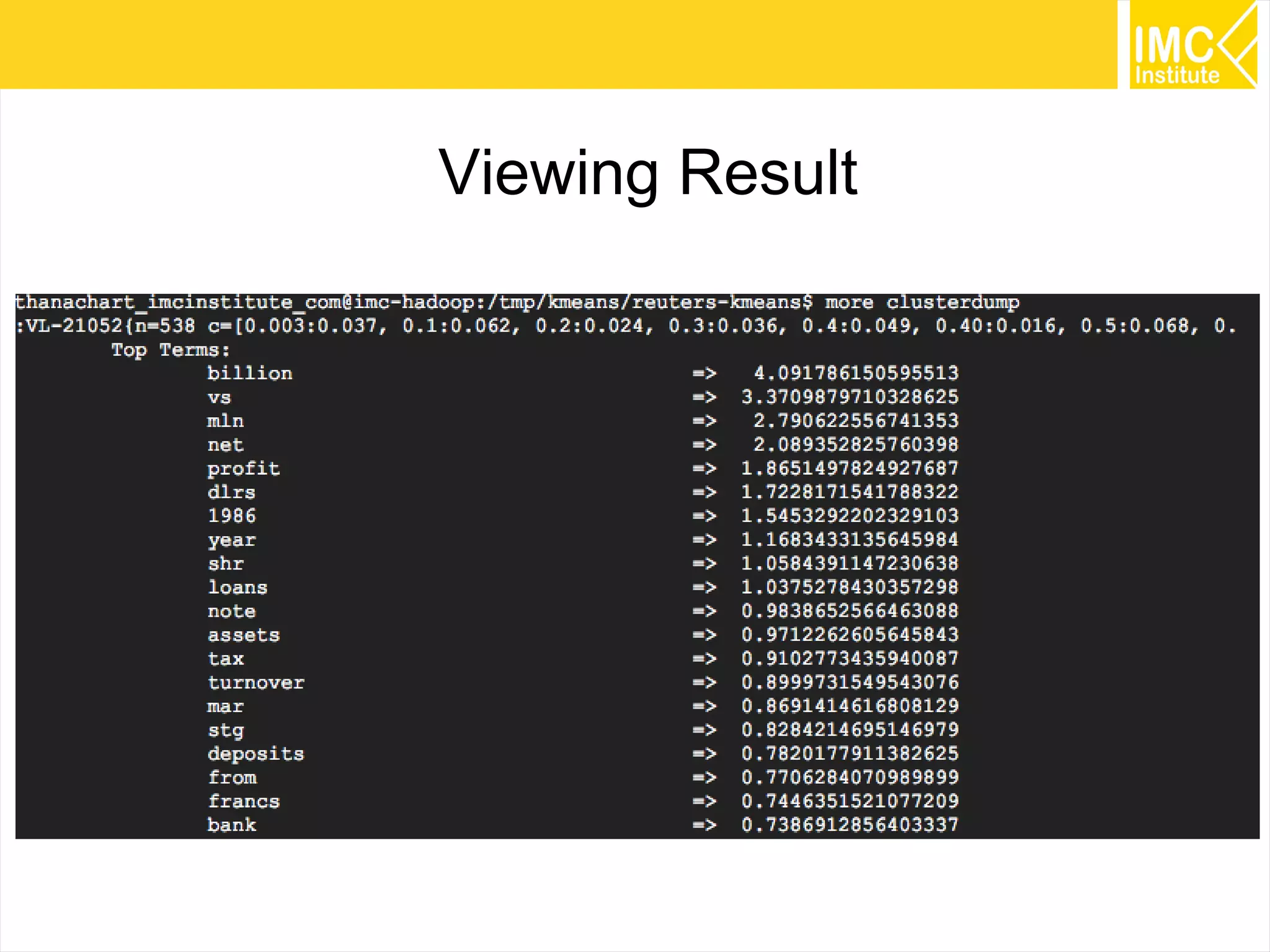

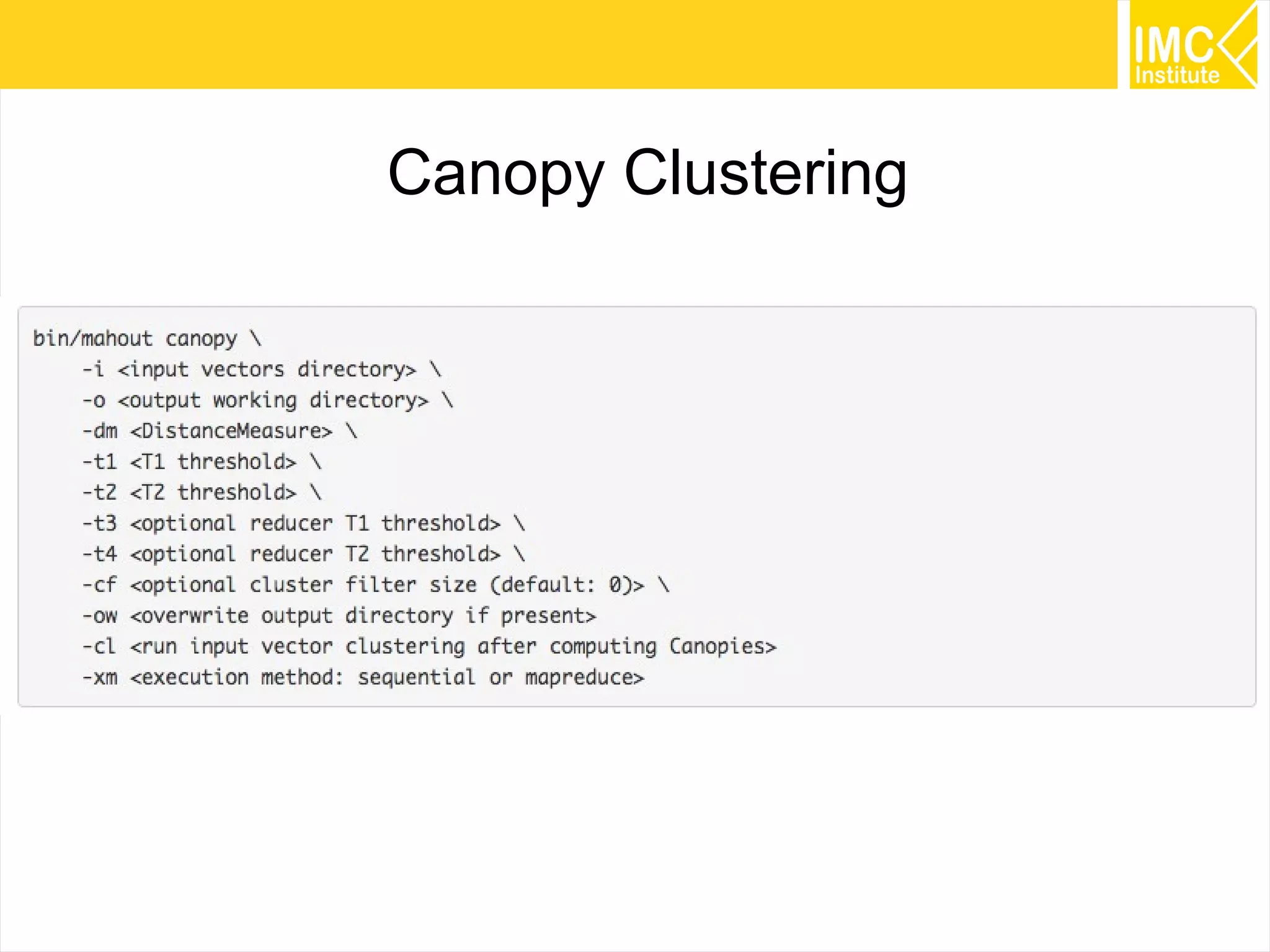






This document provides an overview and instructions for running machine learning algorithms using Mahout on Google Cloud Platform. It discusses setting up Hadoop on a virtual server instance and installing Mahout. Example algorithms covered include item-based recommendation using MovieLens data, naive Bayes classification using 20 Newsgroups data, and k-means clustering on Reuters newswire articles. Configuration steps and command lines for running each algorithm are outlined.























































































