Downloaded 10 times




![RecommenderIntro which is created by the above execution. Then set
mia/recommender/ch02 to Working directory in Arguments tab(see the below
figure). Click “Workspace…” button and select the directory.
Then it outputs a result like “RecommendedItem[item:104, value:4.257081]“.
If you want to make a project, repeat from Maven project creation.](https://image.slidesharecdn.com/vipuldivyanshumahoutdocumentation-130131133634-phpapp01/75/Vipul-divyanshu-mahout_documentation-7-2048.jpg)
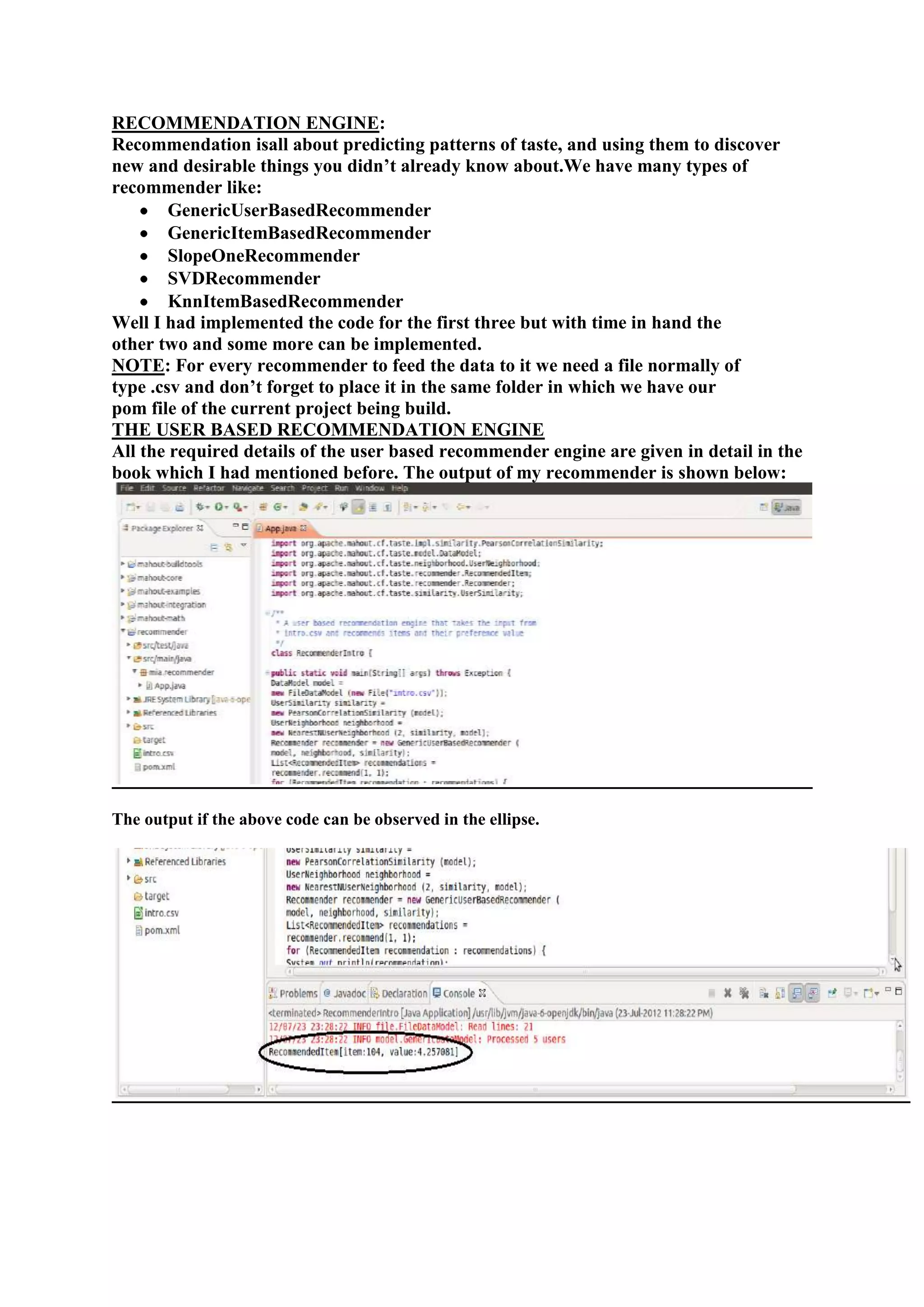
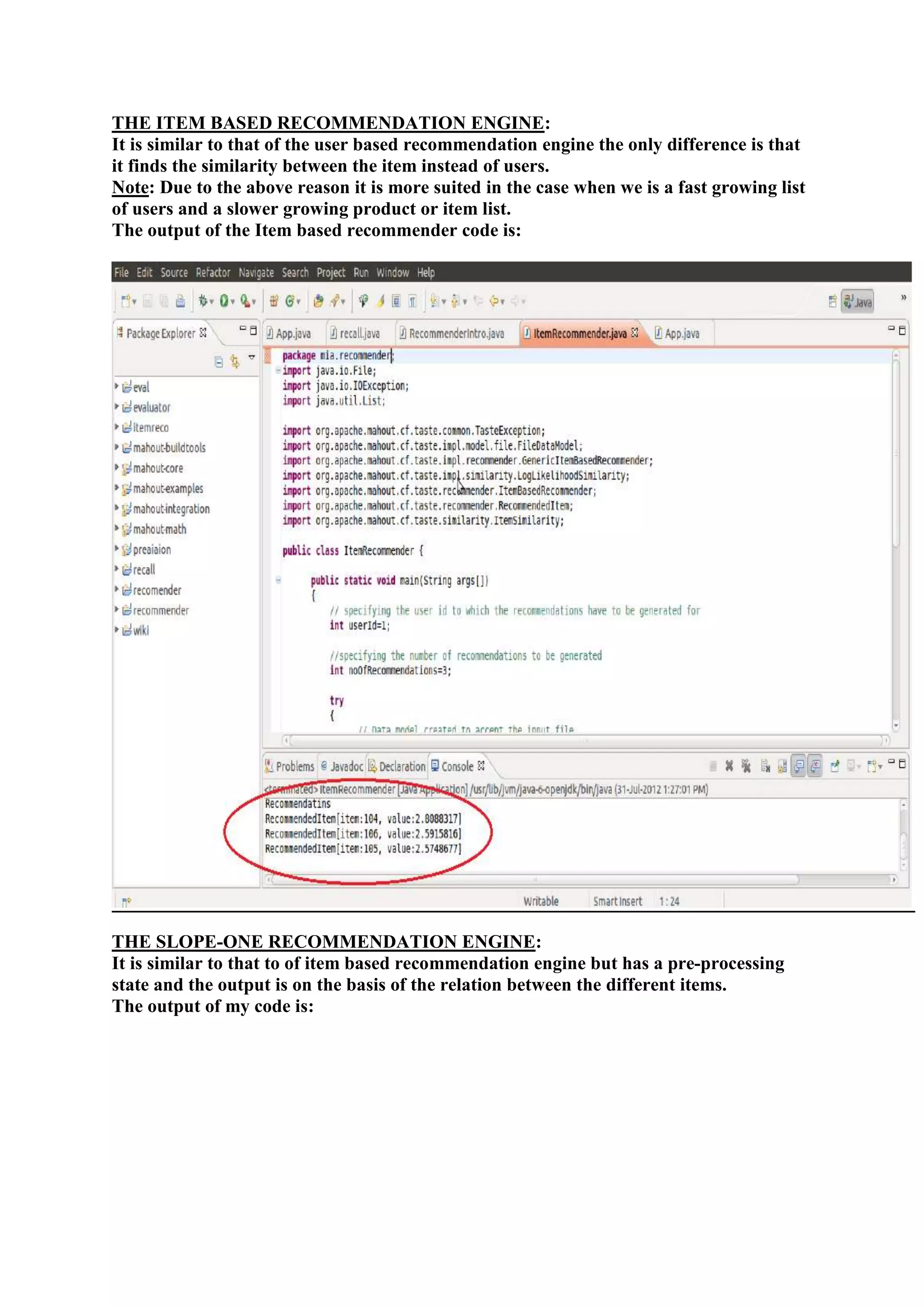
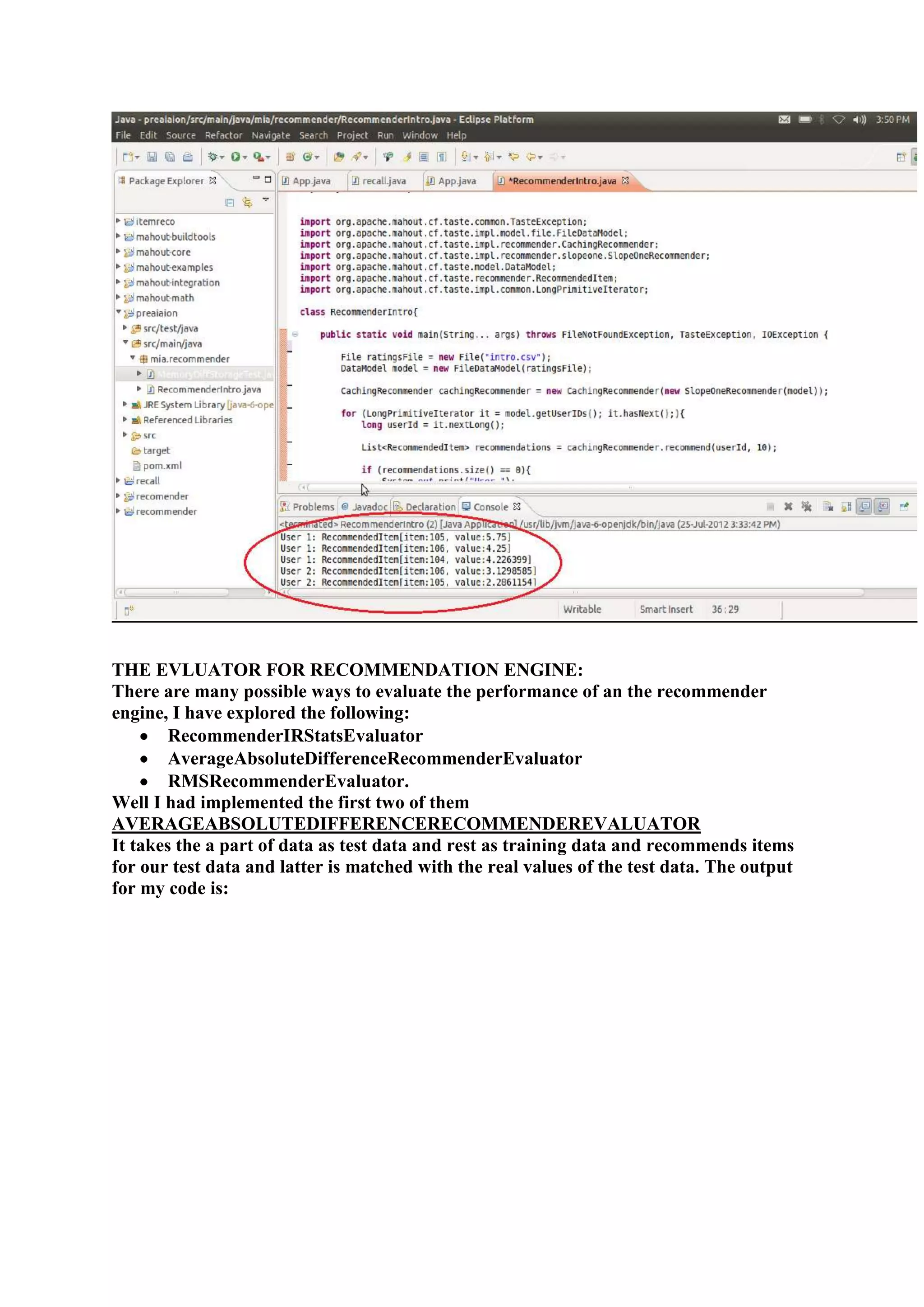
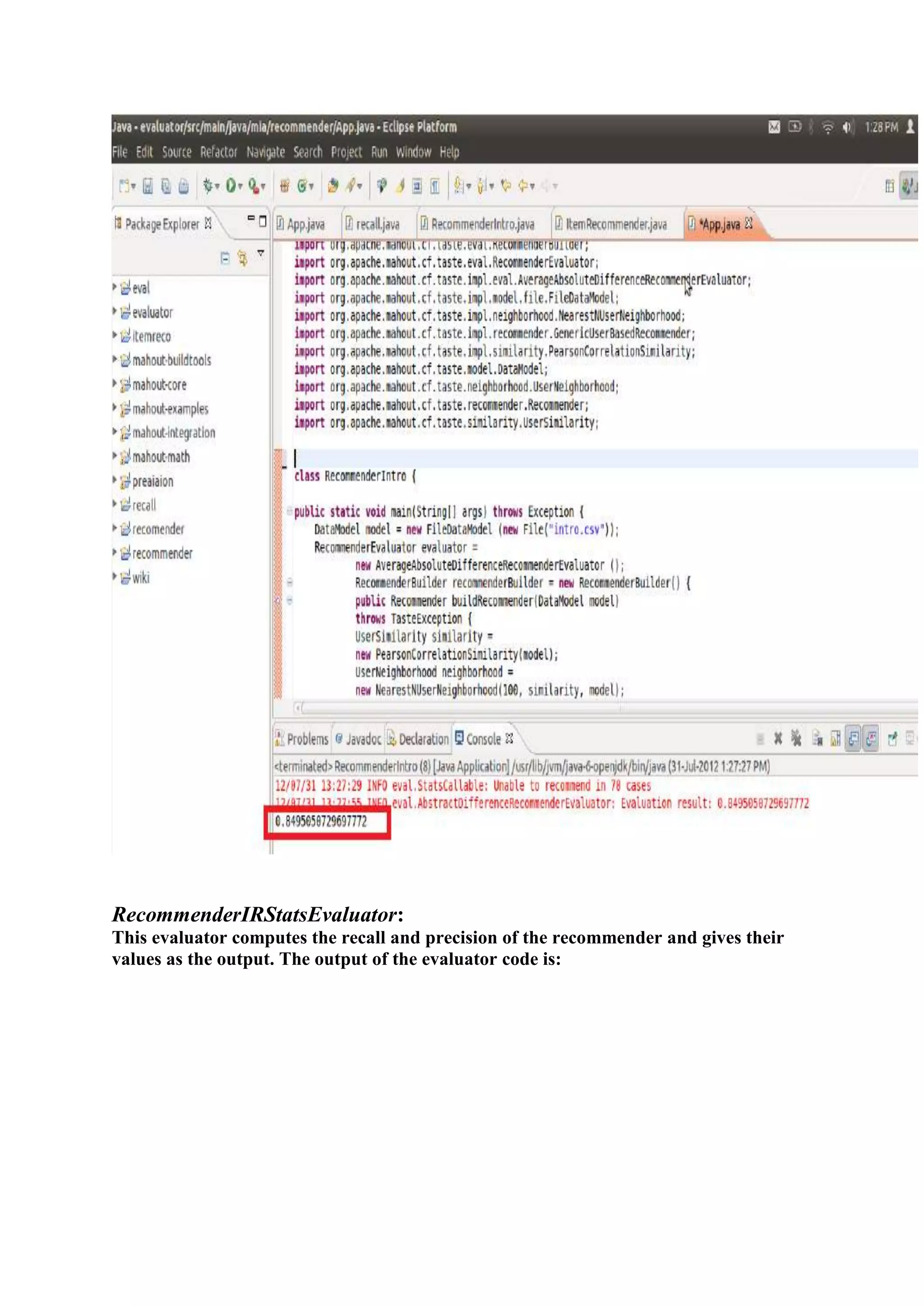
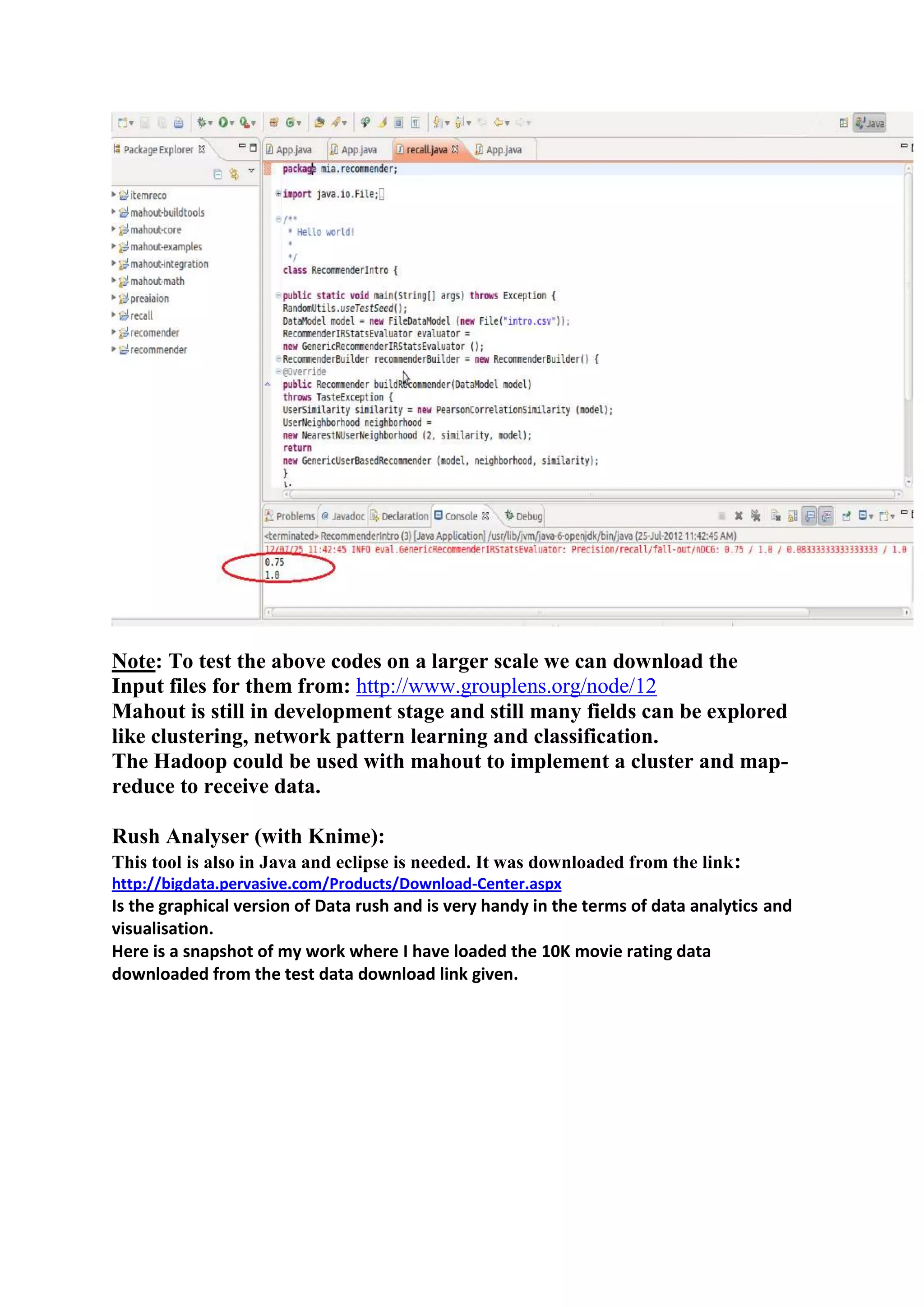
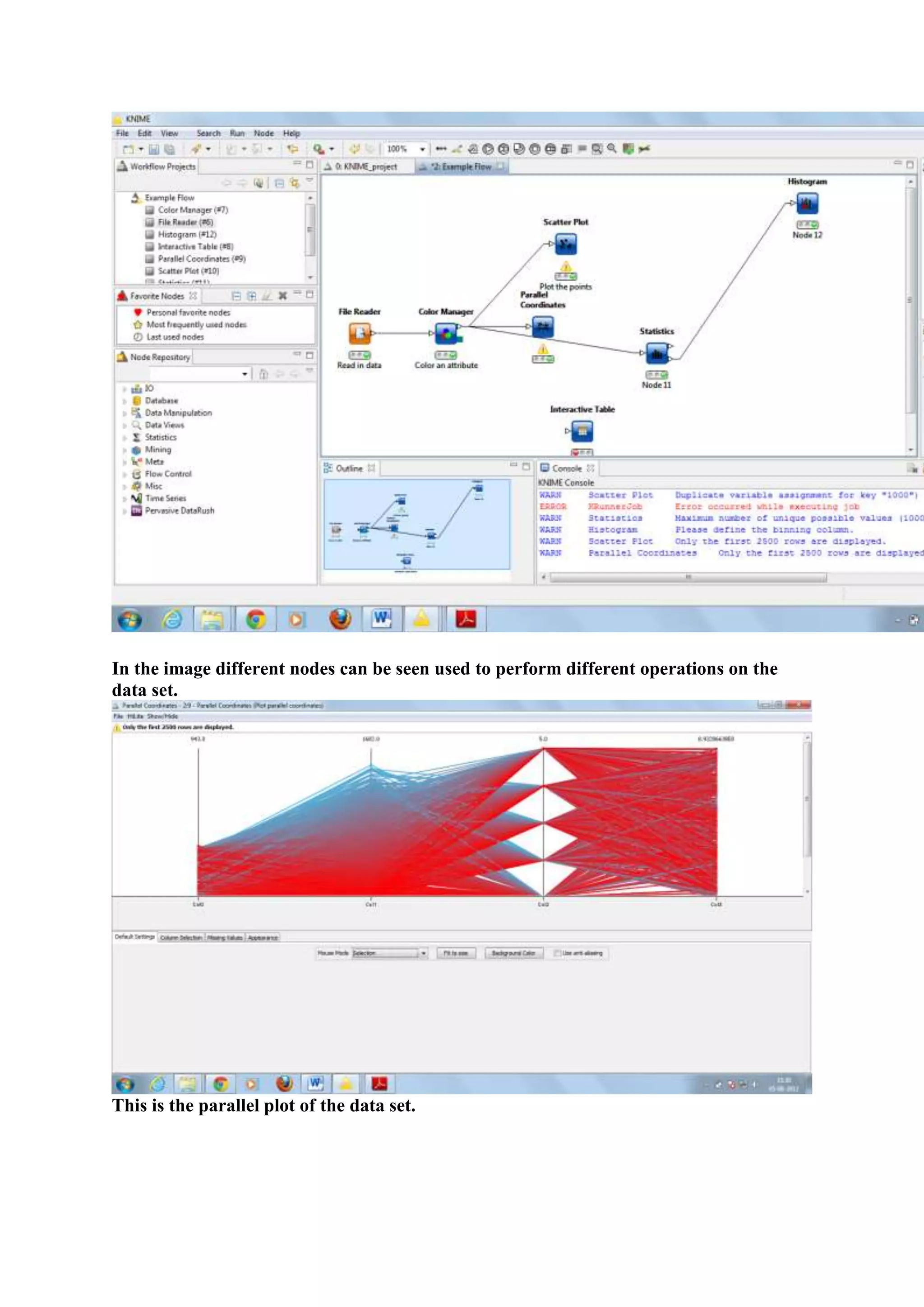


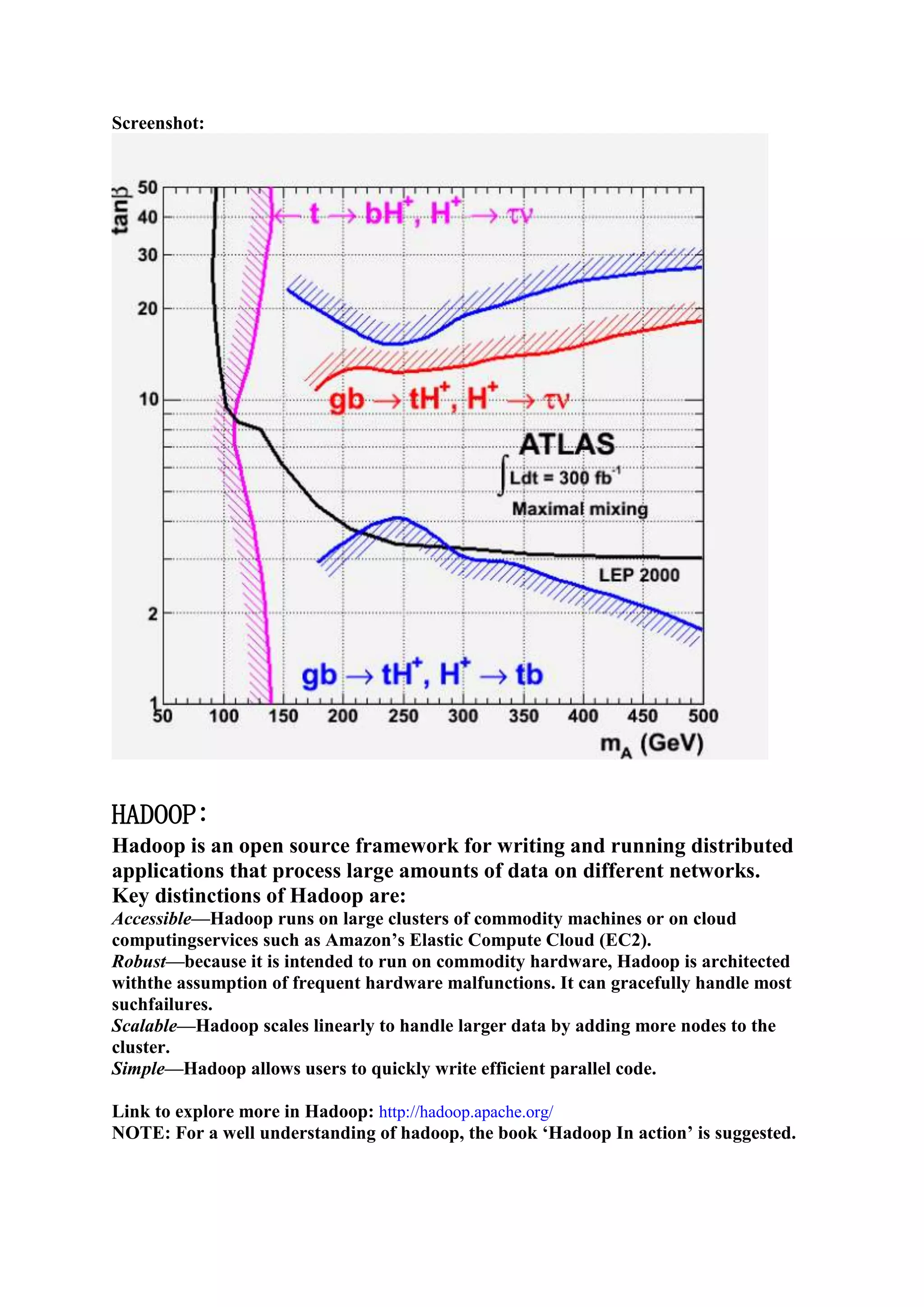
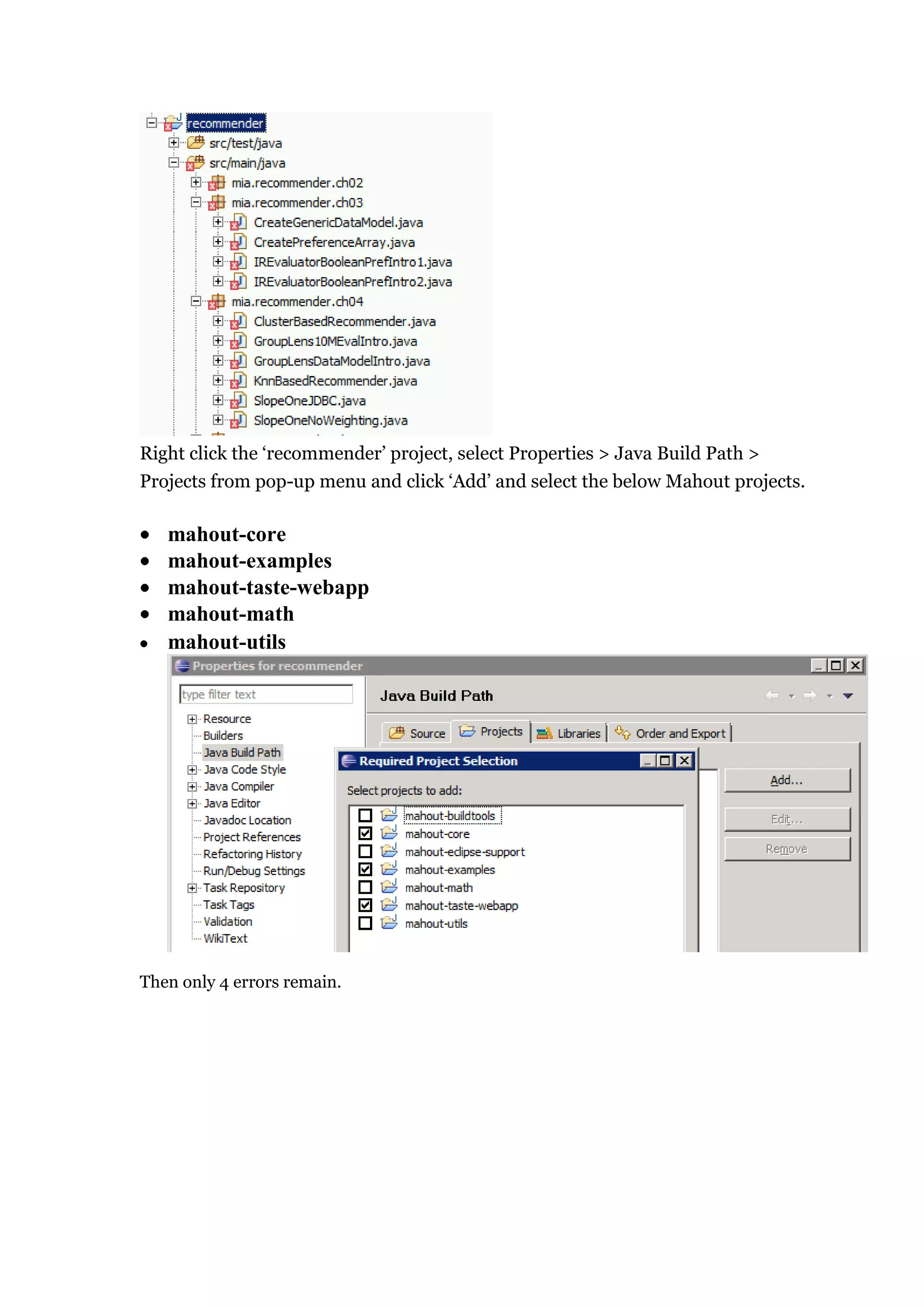
1) The document outlines the tasks, tools, and topics explored by Vipul Divyanshu during a summer internship at India Innovation Labs, including data analytics on a medium-sized database and building a recommender engine. 2) Key tools explored include Mahout for machine learning algorithms, Hadoop for distributed processing, and Rush Analyzer (with KNIME) for data visualization and analytics. 3) Vipul implemented recommendation engines including user-based, item-based, and SlopeOne recommenders and evaluated performance using recommender evaluators.




























![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




