
































The document discusses Facebook's use of HBase to store messaging data. It provides an overview of HBase, including its data model, performance characteristics, and how it was a good fit for Facebook's needs due to its ability to handle large volumes of data, high write throughput, and efficient random access. It also describes some enhancements Facebook made to HBase to improve availability, stability, and performance. Finally, it briefly mentions Facebook's migration of messaging data from MySQL to their HBase implementation.
Introduction to Nicolas Spiegelberg and presentation outline covering Facebook Messages and HBase.
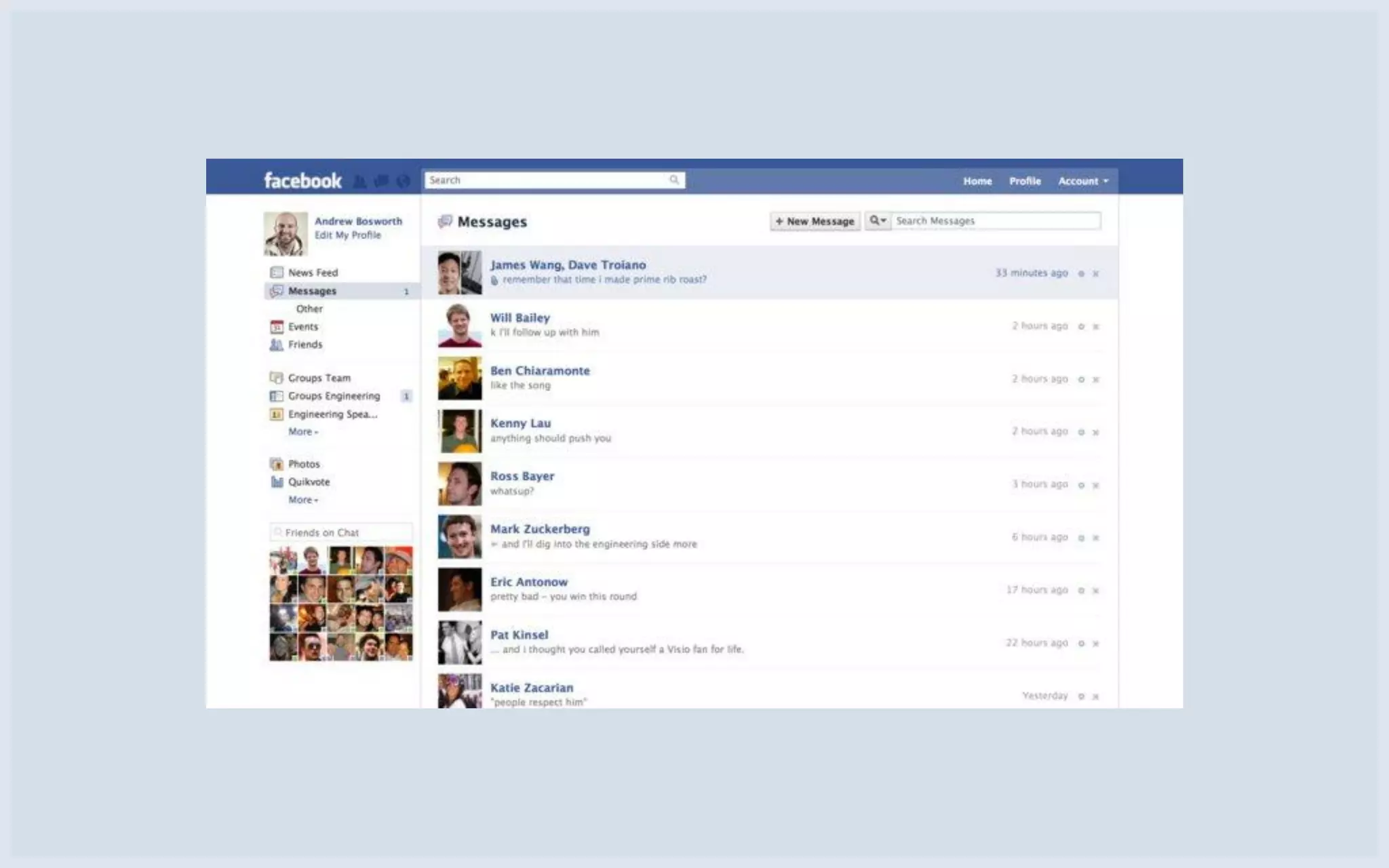
Presentation on the new Facebook Messages integrating chats, emails, and SMS features.
Data volume before launch: 14TB and 11TB; HBase for message metadata, search indices, and small message bodies.
Overview of the technology stack: Memcached, ZooKeeper, HBase, HDFS, and Hadoop.
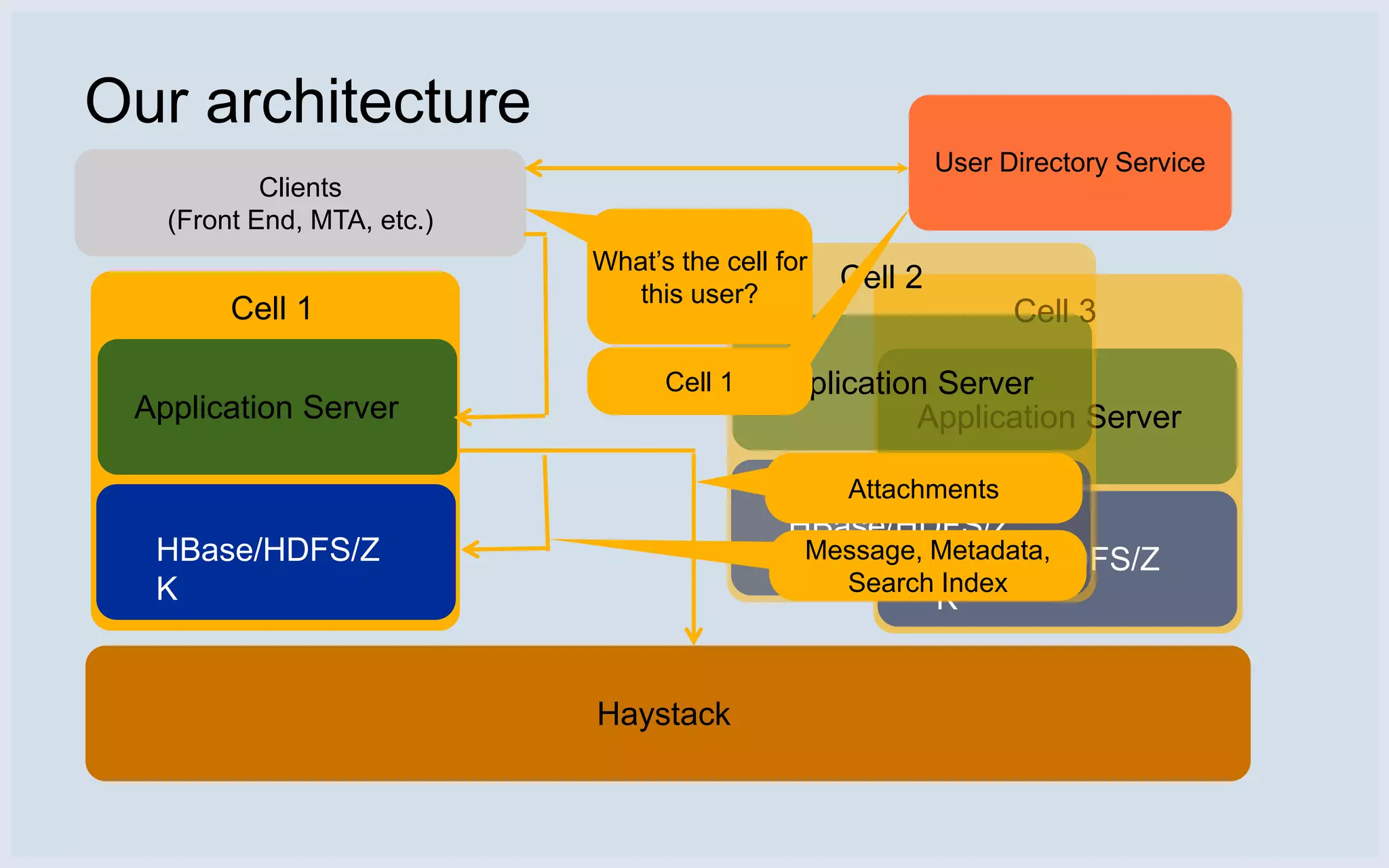
Architecture showing user services, application servers, and data storage across HBase and Haystack.
Definition of HBase as a large-scale distributed data store, uses, and application scenarios.
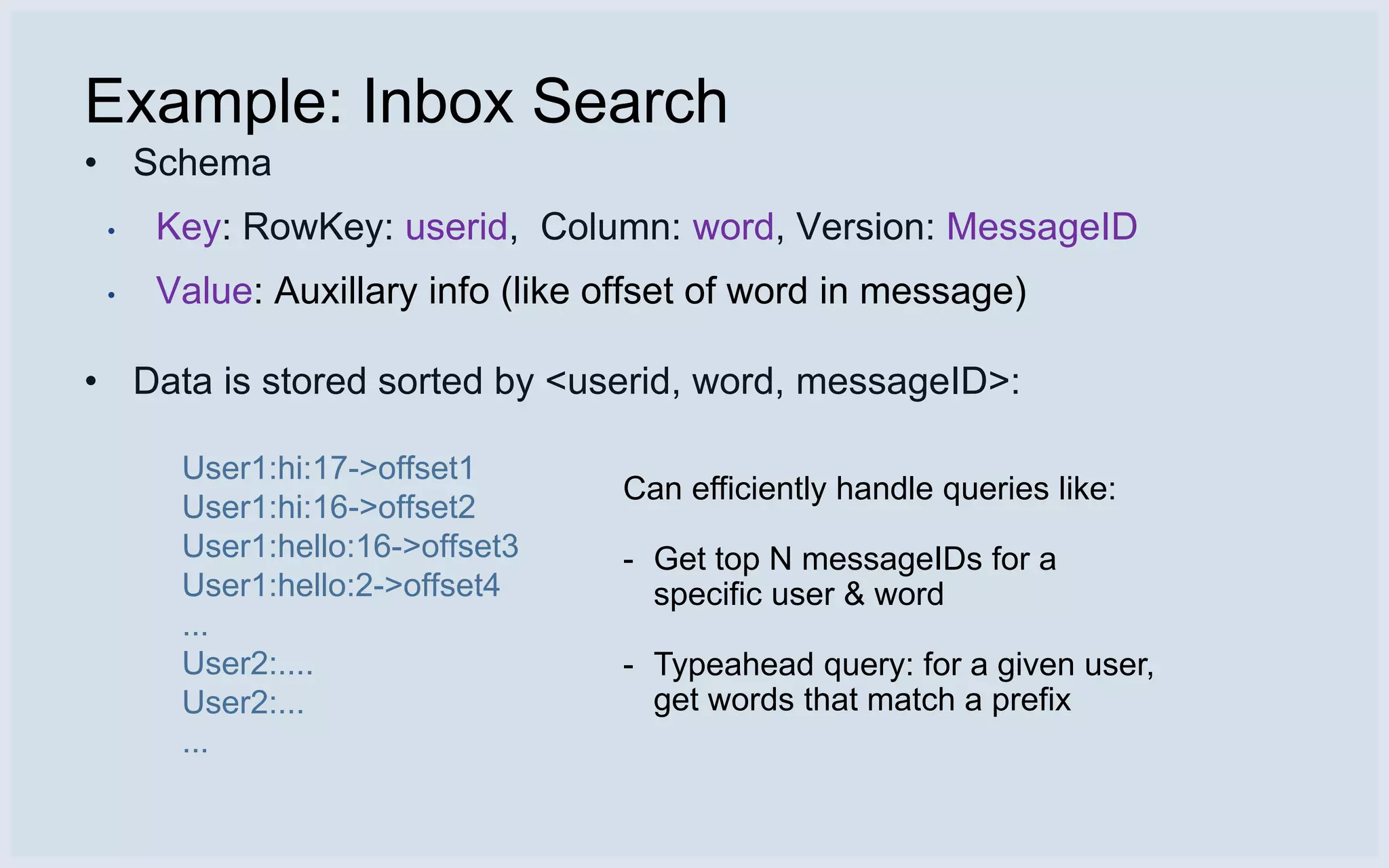
Description of HBase data model, schema for inbox search, and its efficient querying capabilities.
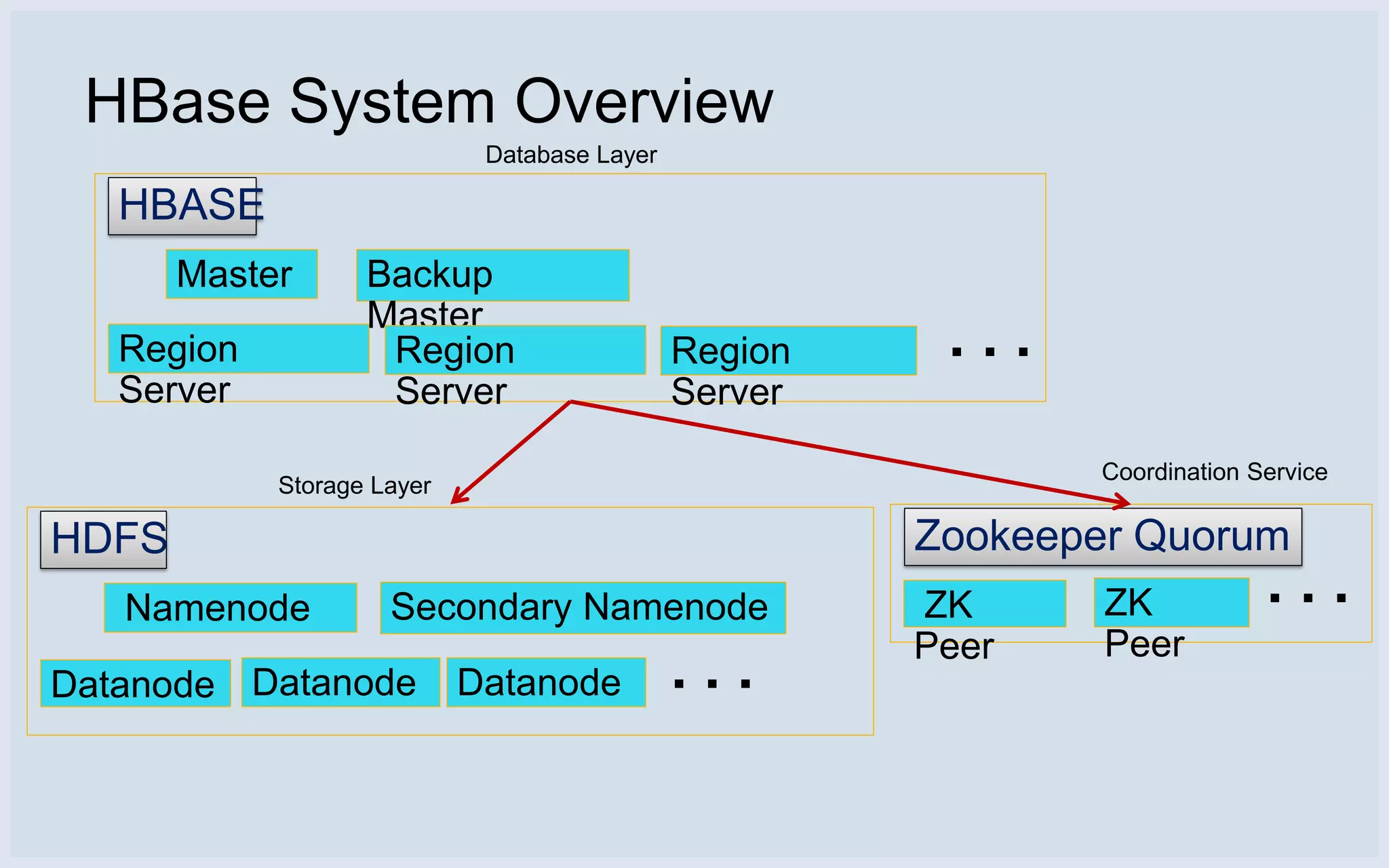
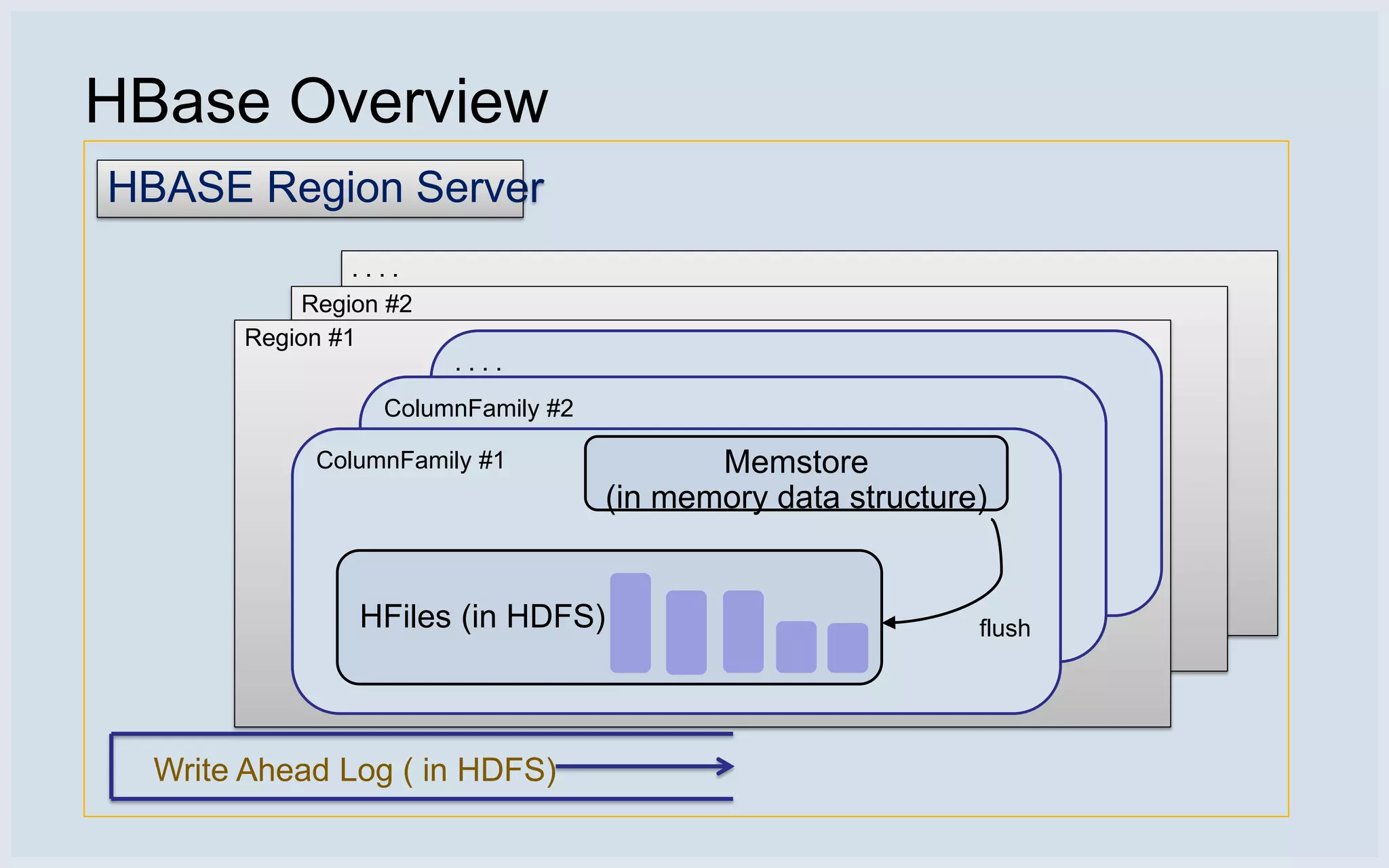
Overview of HBase architecture including region servers, read/write paths, and background operations.
Advantages of HBase including horizontal scalability, automatic failover, and consistency model.
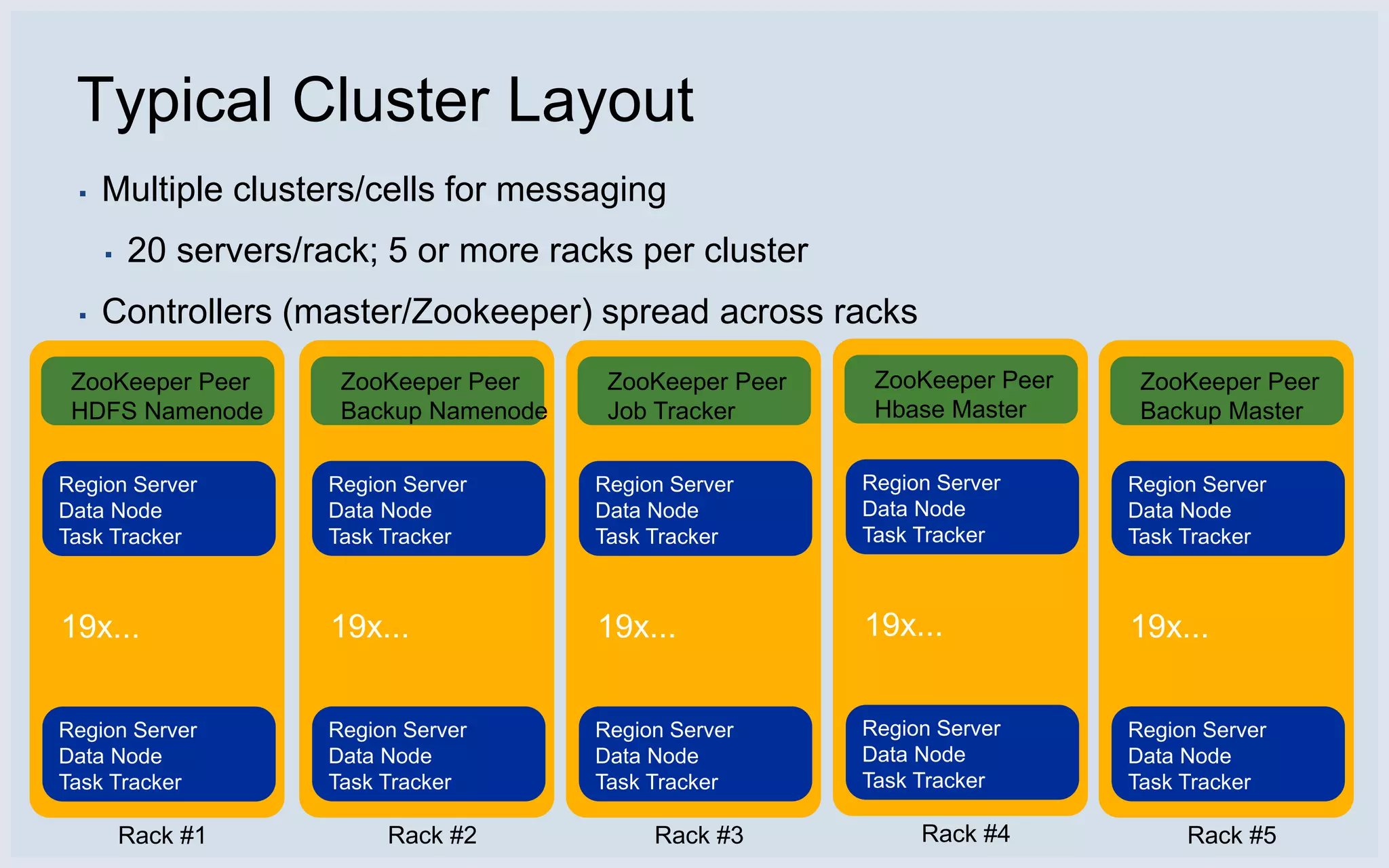
Typical cluster layout with multiple cells and recent enhancements to improve HBase performance.
Goals for ensuring zero data loss, including improvements to durability and transaction log integrity.
Various improvements made to HBase for better availability, performance, and compaction processes.
Insights from operational practices, administrative tools, and interactions with the Apache community.
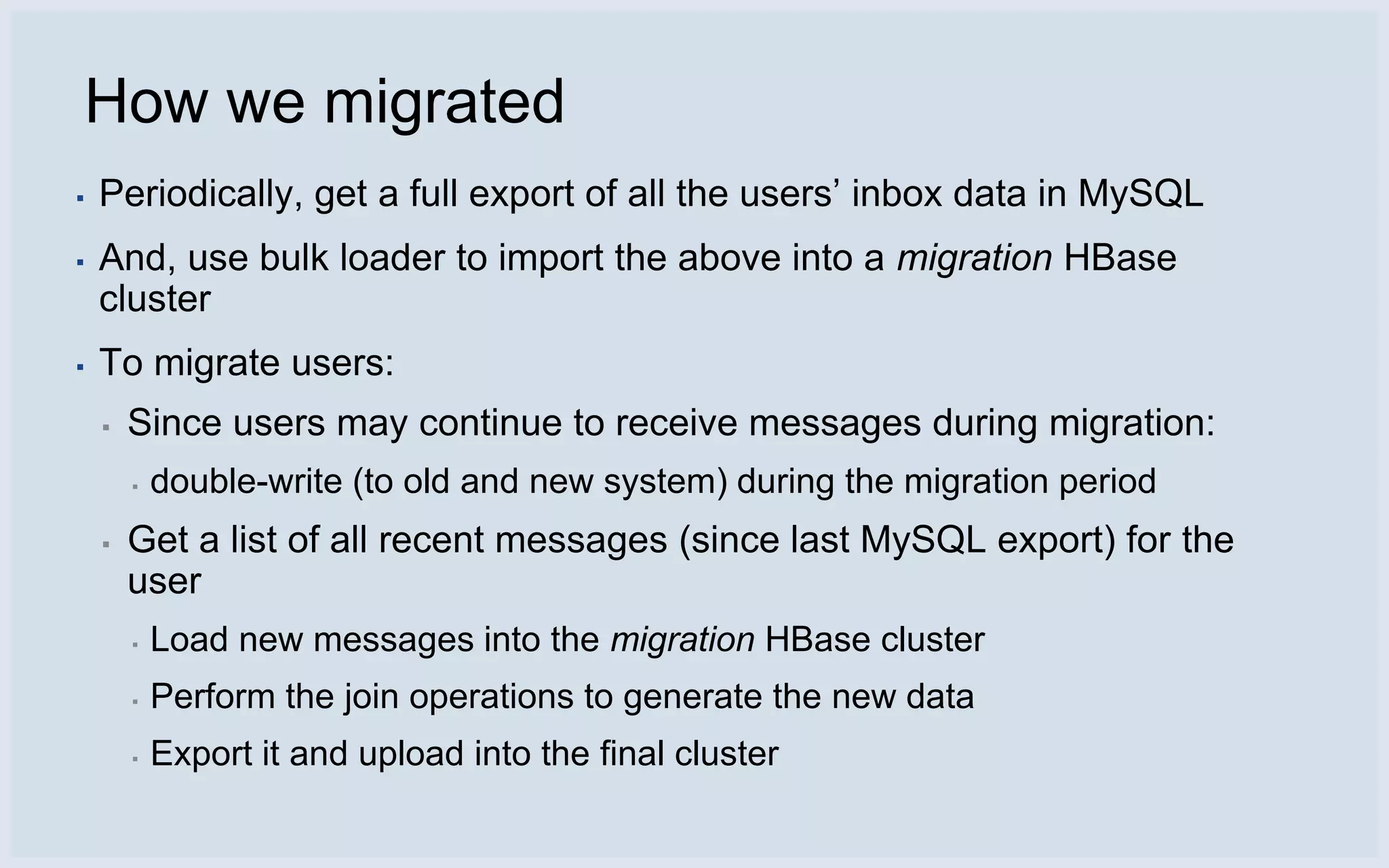
Migration challenges and methodologies for transferring large amounts of data from MySQL to HBase.
Vision for future enhancements including real-time analytics, high availability, and improved features.
Unrelated event information for QCon, not relevant to the main presentation.




































![[Hi c2011]building mission critical messaging system(guoqiang jerry)](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011buildingmissioncriticalmessagingsystemguoqiangjerry-111206111202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












