Downloaded 39 times





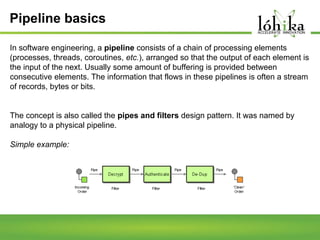
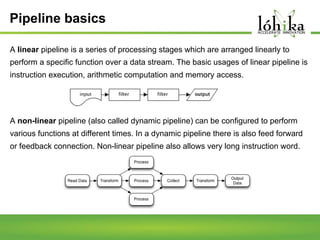

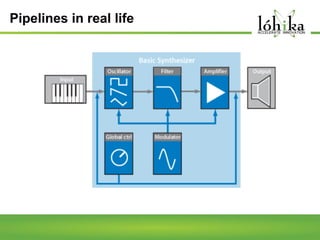


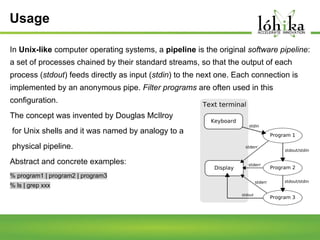
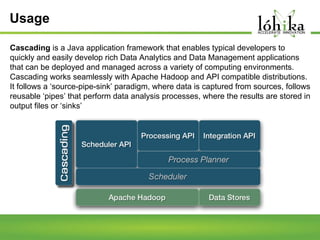
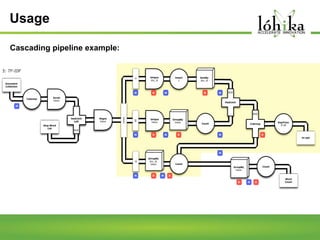

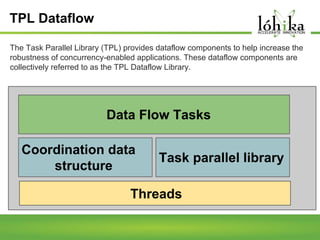


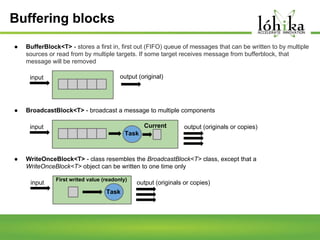
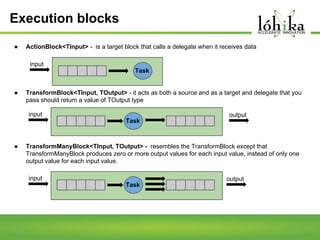
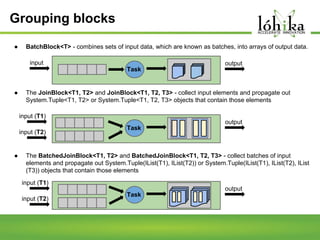








A pipeline consists of a chain of processing elements arranged so that the output of each element is the input of the next. The TPL Dataflow Library provides dataflow components that implement a dataflow model for message passing between operations. It includes source, target, and propagator blocks that process data and buffer it as it moves through the pipeline. Common usages include prototyping complex systems, asynchronous applications that process data like images or sound, and studying pipeline-based development.



































































