Downloaded 367 times



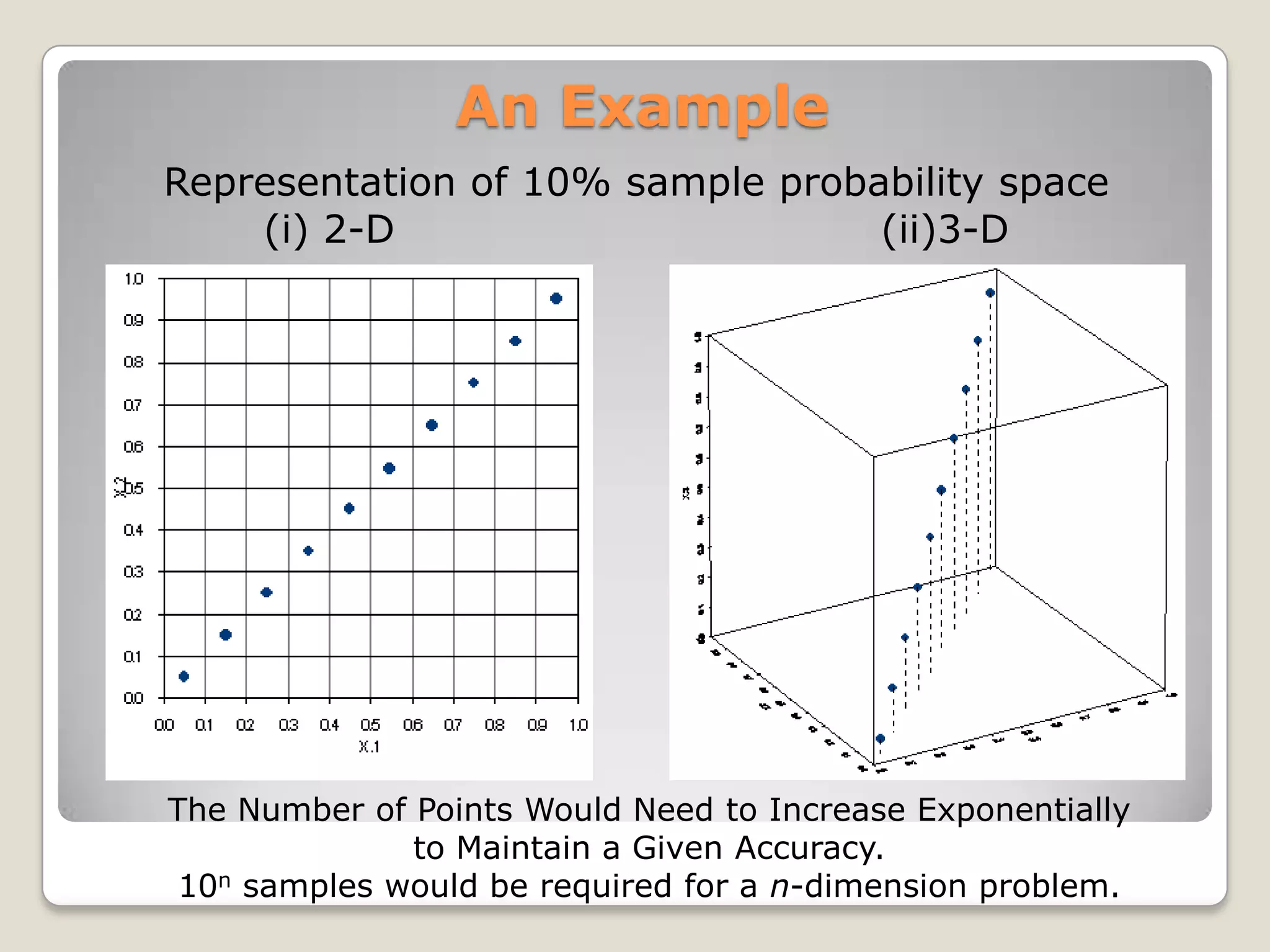













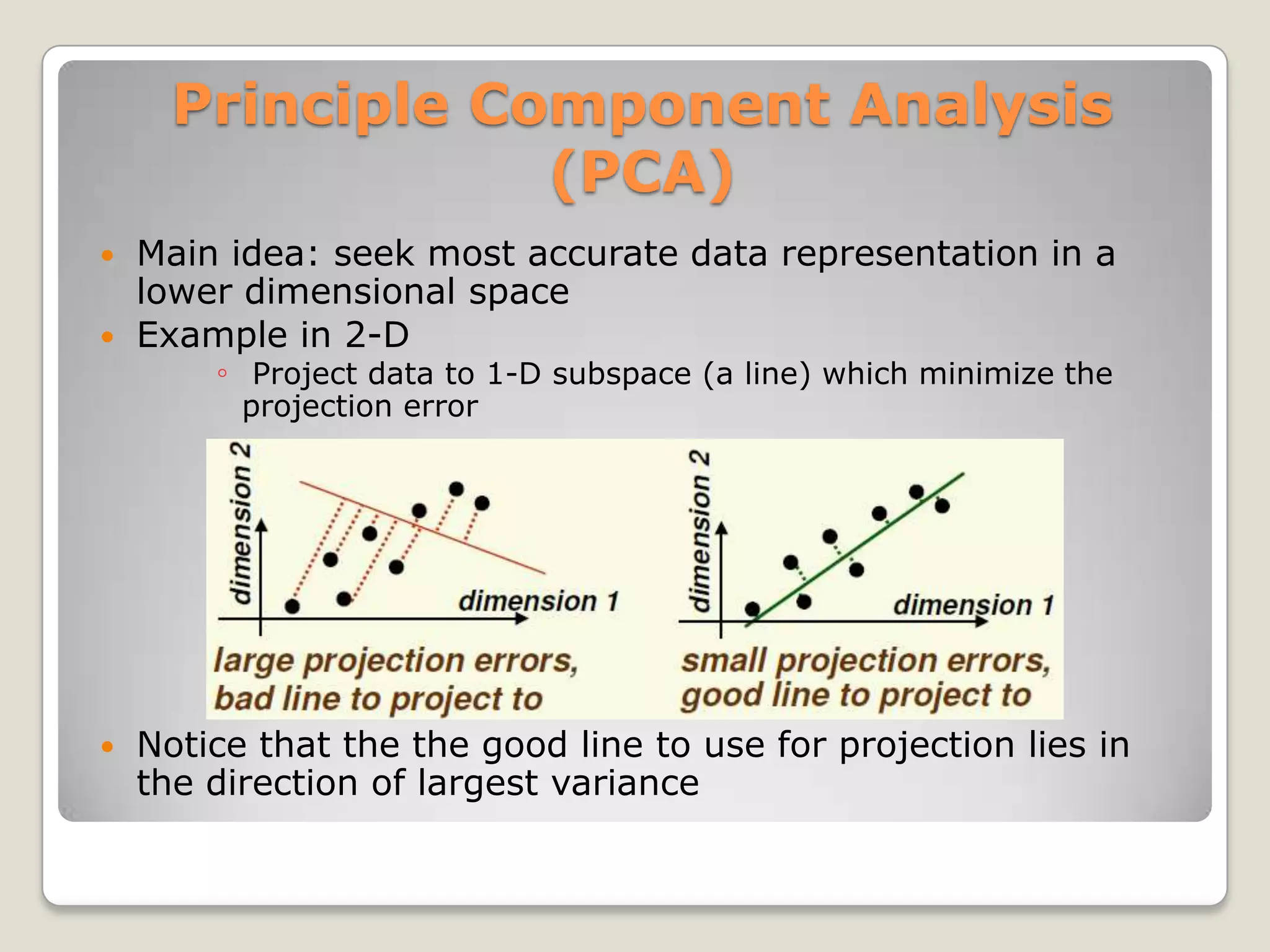
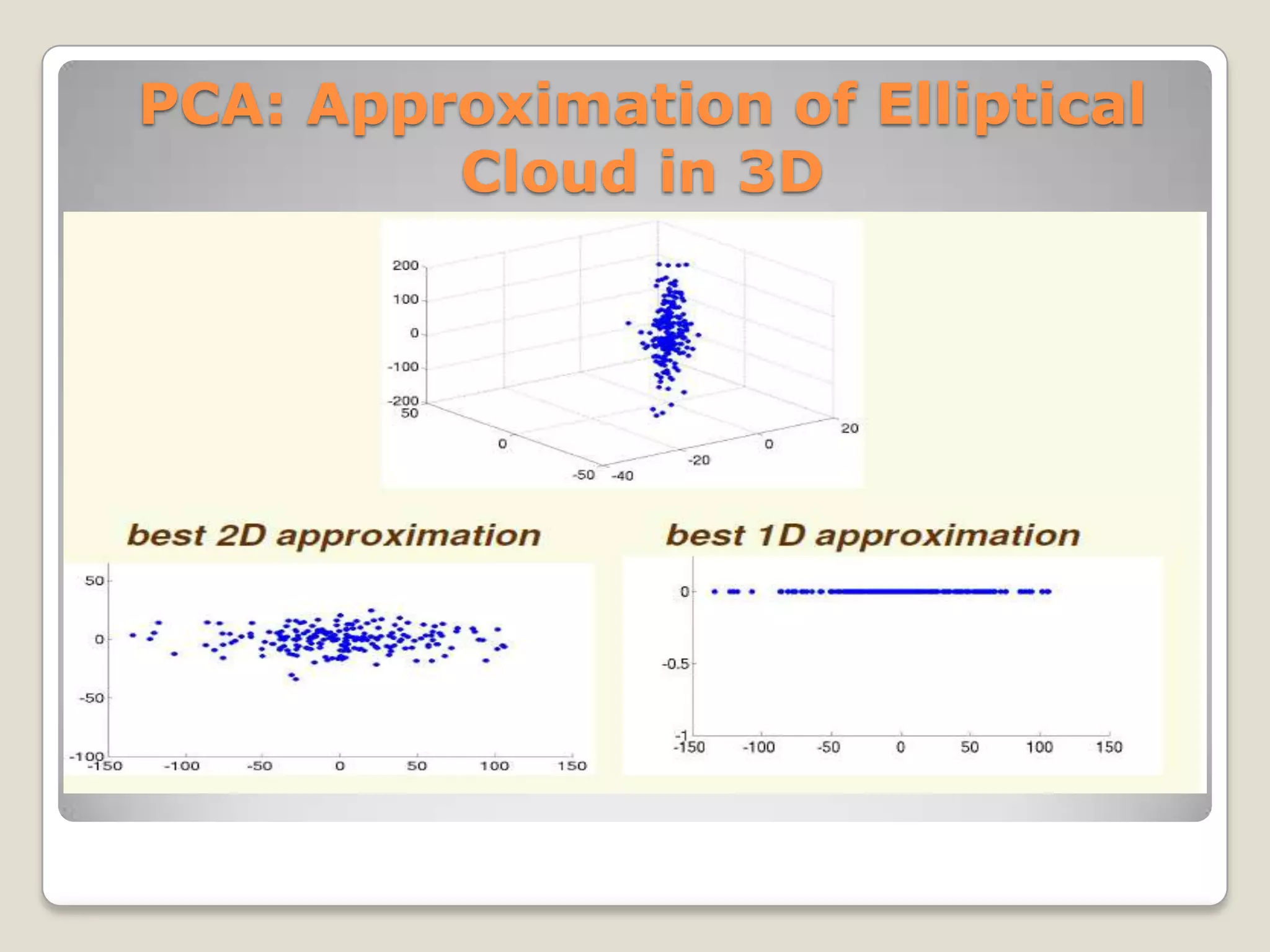


The document discusses the curse of dimensionality, which refers to the problem caused by an exponential increase in volume associated with adding extra dimensions to a mathematical space. This causes several issues, including an increase in running time and overfitting as the number of dimensions increases. It also requires exponentially more samples to maintain the same level of accuracy as more dimensions are added. Several methods are discussed to help address this problem, such as dimensionality reduction techniques like principal component analysis, which projects the data onto a lower dimensional space.








































































